MSA и не только: как мы создаем высоконагруженные сервисы для банка
Проектирование высоконагруженных сервисов уже не является таинственным мастерством, которым владеют лишь просвещенные сэнсеи. Сегодня для этого существуют вполне устоявшиеся практики, которые комбинируются и видоизменяются в зависимости от особенностей компании и ее бизнеса. Мы хотим рассказать о наших лучших методиках и инструментах создания высоконагруженных сервисов.

Сразу оговоримся, что речь пойдет о заказной разработке. Как завещал нам здравый смысл, проектирование мы начинаем с постановки бизнес-задач. И в том числе определяем, будет ли система высоконагруженной. Понятно, что со временем она будет меняться (например, изменится профиль нагрузки), поэтому при описании бизнес-логики мы закладываем вероятные пути развития там, где это возможно. Скажем, если это какой-то сервис по обслуживанию клиентов, то можно спрогнозировать изменение размера аудитории. Иногда бывает сразу понятно, как система будет меняться со временем, а некоторые контрольные точки трудно поддаются прогнозу.
На начальном этапе мы можем посчитать объемы данных, которые нам нужны для хранения, посчитать начальную нагрузку на наш абстрактный сервис и скорость ее роста. Также можно классифицировать данные по виду работы с ними: хранение, запись или чтение, и в зависимости от этого оптимизировать процессы.
У нас есть KPI по работе системы, на основании которых определяется допустимая степень ее деградации. Для большинства систем критичным является время отклика. В некоторых случаях оно может достигать нескольких секунд, а в других счёт идёт на миллисекунды. Также на этом этапе определяется степень доступности системы. Как правило, мы разрабатываем высокодоступные системы или системы непрерывного режима работы: с уровнем доступности от 99,9% до 99,999%.
Определившись с бизнес-логикой, допустимыми объемами данных и поведением системы, начинаем строить диаграммы движения данных. Это необходимо для того, чтобы понять, какой шаблон проектирования лучше всего выбрать. И после построения диаграмм приступаем к самому проектированию.
Микросервисы — buzzword нашего времени
В последнее время при создании высоконагруженных систем мы предпочитаем сервис-ориентированную архитектуру. В частности, столь модную в последние годы микросервисную: берем функциональность системы и разбиваем её на небольшие кусочки — сервисы, каждый из которых выполняет какую-то маленькую задачу. Сервисов может быть очень много, сотни или тысячи. Такая архитектура облегчает поддержку системы, а вносимые в отдельные сервисы изменения гораздо меньше влияют на систему в целом.
Также ещё одна важная плюшка микросервисной архитектуры — хорошая масштабируемость.
Но кроме весомых достоинств у микросервисной архитектуры есть и существенный недостаток: не всегда возможно разделить бизнес-логику на достаточно маленькие функциональные кусочки.
Задача эта сложная, и, как правило, решается на этапе проектирования. Обратной стороной медали является межсервисное взаимодействие. Необходимо следить за тем, чтобы накладные расходы на обмен сообщениями были не слишком большими. Достигается это в основном за счёт выбора эффективных методов сериализации/десериализации данных (об этом чуть ниже), перемещения взаимодействующих сервисов «поближе» друг к другу или объединения их в один микросервис. Зато если удается успешно разделить логику на мелкие задачи, то к вашим услугам будут все преимущества микросервисной архитектуры.
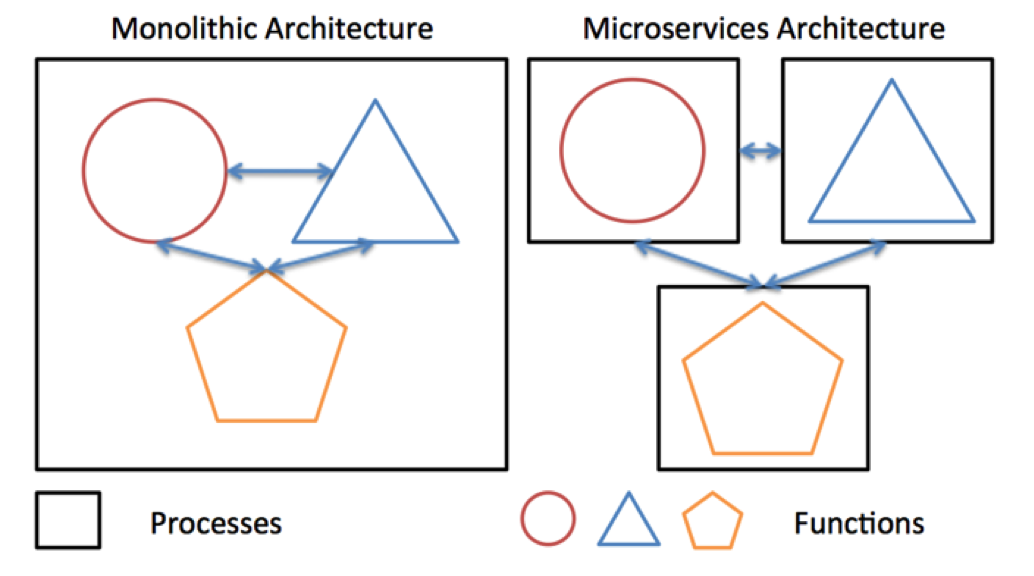
Микросервисная архитектура позволяет разместить сервисы на большом количестве узлов и заложить необходимое резервирование на случай выхода каких-то узлов из строя (тьфу-тьфу-тьфу). Схема резервирования во многом зависит от исходных задач. Где-то нельзя допускать пауз и требуется моментальное восстановление сервиса — в этом случае используется схема Active/Active, когда балансировщик мгновенно отключает вышедший из строя узел. В других случаях допустим небольшой простой на время восстановления сервиса, и тогда используется схема Active/Standby, когда резервный узел становится доступен не сразу, а через небольшой промежуток времени, пока сервис автоматически переносится на резервный узел.
Очевидными примерами необходимости использования вариантов схем Active/Active могут служить сервисы удаленного банковского обслуживания — интернет- и мобильный банкинг.
Традиционно в банке ВТБ ведется достаточно большой объем заказной разработки ПО. До недавнего времени для этих целей в основном использовались технологии .NET и Java Enterprise. Сейчас эти средства уже рассматриваются нами как legacy. Для новых проектов мы начали использовать подходы на основе микросервисной архитектуры (MSA — Microservice Architecture).
Если говорить точнее, то новые системы в банке проектируются как набор микросервисов на платформе Spring Boot. Основные причины выбора Spring Framework были ее широкое распространенность на рынке ИТ-услуг, а также относительная простота ее использования при разработке сервисов и микросервисов.
Для взаимодействия с пользователем, как правило, используется веб-интерфейс, разработанный с использованием React или Angular, взаимодействующий с серверными компонентами через Rest API.
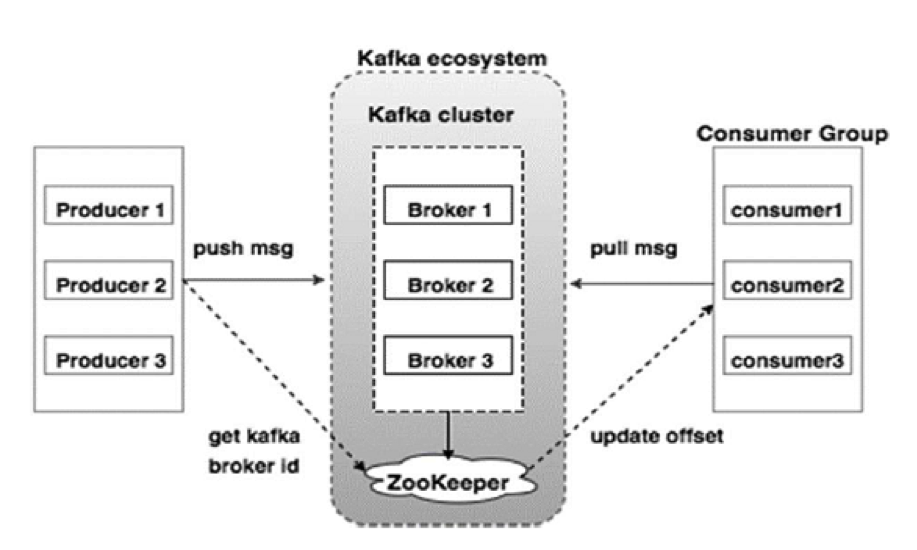
Отдельная тема — взаимодействие компонентов MSA между собой, а также их интеграция с существующей ИТ-экосистемой. Наряду с традиционными подходами, такими как очереди MQ, мы активно внедряем новые паттерны взаимодействия на основе слабой связанности и платформы Apache Kafka.
Языки и фреймворки
Сейчас достаточно много технологий, позволяющих строить высоконагруженные системы с небольшим временем отклика. Но их состав постоянно меняется: постоянно приходит что-то из мира Open Source, разрабатываются новые внутренние проекты, часть из которых тоже переходят в стан открытого исходного кода. Однако мы предпочитаем проверенные решения известных вендоров. Наша задача — наращивать компетенции в использовании подобного рода систем.
Трудно представить себе высоконагруженную систему, не использующую кэширование данных. Хотя здесь на рынке большой выбор инструментов, обычно мы придерживаемся проверенной «классики» — Memcached и Redis. Но в последнее время стали поглядывать в сторону Apache Ignite, на некоторых проектах он хорошо зарекомендовал себя в роли распределённого кэша.
Что касается выбора языков программирования, то многое зависит от задачи. Как правило, выбор падает на Java — тут и большое количество фреймворков, позволяющих быстро и качественно реализовывать необходимую функциональность, и большое количество настроек самой JVM, позволяющих добиться необходимых показателей производительности.
При проектировании MSA мы тоже придерживаемся стека технологий Java. Помимо унификации это позволяет нам легко интегрироваться с уже работающими в банке приложениями через традиционные механизмы интеграции — очереди MQ, веб-сервисы, многочисленные API на основе Java. Также это позволяет использовать имеющийся на данной платформе развитый инструментарий разработки и управления микросервисами.
Немаловажно и то, что на российском рынке уже довольно много специалистов по разработке MSA-приложений с использованием технологического стека на основе JVM.
Хранение данных
Что касается хранения данных, то в первую очередь при проектировании возникает вопрос: какую модель данных должна использовать СУБД — реляционную или какую-то другую? От выбора зависят дальнейшие методики повышения эффективности обработки запросов к базе данных, ведь высоконагруженные сервисы априори должны обладать маленьким временем отклика. Если мы говорим о реляционных СУБД, то их использование в высоконагруженных проектах требует решать задачи повышения эффективности запросов. Начинается всё с анализа плана запросов.
Как правило, по его результатам мы меняем сами запросы, добавляем индексы. Можно применять партиционирование к таблицам, сокращая объемы данных при выборках с помощью ограничения их рамками одной или нескольких партиций. Также часто приходится использовать денормализацию данных, внося некую избыточность — так можно повысить эффективность запросов.
А с нереляционными СУБД приходится использовать практически индивидуальные подходы в зависимости от конкретного продукта, от бизнес-сценариев. Из общих подходов можно выделить разве что отложенную обработку трудоёмких вычислений.
Безусловно, всё зависит от конкретной задачи, но если есть возможность, то мы используем Oracle, потому что написание эффективных запросов и настройка занимает у наших инженеров меньше времени. Также в последнее время мы часто смотрим в сторону Apache Ignite.
Масштабирование
Как говорилось выше, мы не всегда можем предсказать, какую нагрузку будет испытывать создаваемая система через полгода или год. И если не заложить возможность масштабирования, то система очень быстро перестанет справляться с растущей нагрузкой. В зависимости от конкретного проекта применяется вертикальное или горизонтальное масштабирование. Вертикальное — увеличение производительности отдельных компонентов за счёт добавления ресурсов в рамках одного компонента/узла; горизонтальное — увеличение количества компонентов/узлов, чтобы распределить по ним нагрузку.
Масштабировать сервис или компонент гораздо проще, если он использует stateless-парадигму, то есть не хранит в себе контекст между запросами. В таком случае мы можем запросто развернуть в системе несколько копий этого компонента или сервиса, сбалансировав нагрузку между ними. В случае stateful-парадигмы нужно позаботиться о том, чтобы балансировка учитывала наличие состояний у компонентов/сервисов.
Физический мир
Тесты, тесты, и ещё раз тесты
Запуск высоконагруженной системы немыслим без нагрузочного тестирования. Под нагрузочным тестированием понимается проверка достижения определённых KPI на входе. Из нашего опыта, большая длительность обработки запросов чаще всего связана с неэффективностью алгоритма. Также росту производительности способствует кэширование данных при большом количестве однотипных запросов.
Тесты позволяют выявить узкие места, которые мы могли упустить из виду при проектировании. Веб-сервис, реализованный в рамках одного из проектов, при нагрузочном тестировании работал с низкой производительностью, несмотря на свою простоту. Профилирование показало, что большую часть времени занимала сериализация-десериализация данных, то есть в основном мы перегоняли структуры данных в битовое представление и обратно. Решение нашлось достаточно быстро — характер данных был таков, что они изменялись крайне редко. Мы смогли реализовать предсериализацию данных (заранее подготовив сериализованное представление), и сильно сократили время отклика.
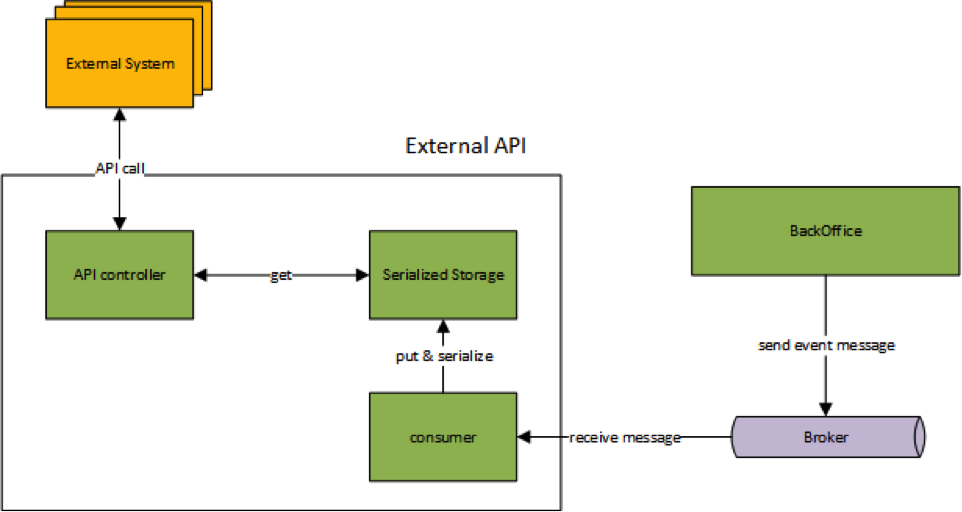
Оптимизация сериализации для внешнего API (предсериализация)
Наряду с нагрузочным тестированием, в рамках которого мы проверяем систему на соответствие предъявляемым требованиям, мы также проводим нагрузочные испытания. Цель таких тестов — узнать предельную возможную нагрузку, которую способна выдерживать система.
Мониторинг
Метрики выполняют роль датчиков, ими густо усыпана любая серьезная система, в особенности высоконагруженная. Без метрик любая программа превращается в черный ящик со входами и выходами, непонятно как работающая внутри. При проектировании в архитектуру закладываются измерители, генерирующие информацию для системы мониторинга.
В некоторых проектах для визуализации активности системы и ее мониторинга использовался ELK (Elastick Search Kibana). У этого фреймворка гибкий интерфейс, позволяющий просто и быстро настроить необходимую форму отчетности.
Мониторинг Kibana
Заключение
При построении отказоустойчивых высоконагруженных систем нет серебряной пули. Справиться с нагрузками мы можем не за счет технологий, а за счет правильно выбранной архитектуры системы. Это всегда поиск некоторых компромиссов. В каких-то случаях мы можем взять уже существующие подходы и паттерны, а в каких-то приходится проектировать и реализовывать свои архитектурные решения.
