[Перевод] Стоимость операций в тактах ЦП
Всем доброго! Вот мы и добрались до тематики С++ на наших курсах и по нашей старой доброй традиции делимся тем, что мы нашли достаточно интересным при подготовке программы и то, что будем затрагивать во время обучения.
Инфографика:
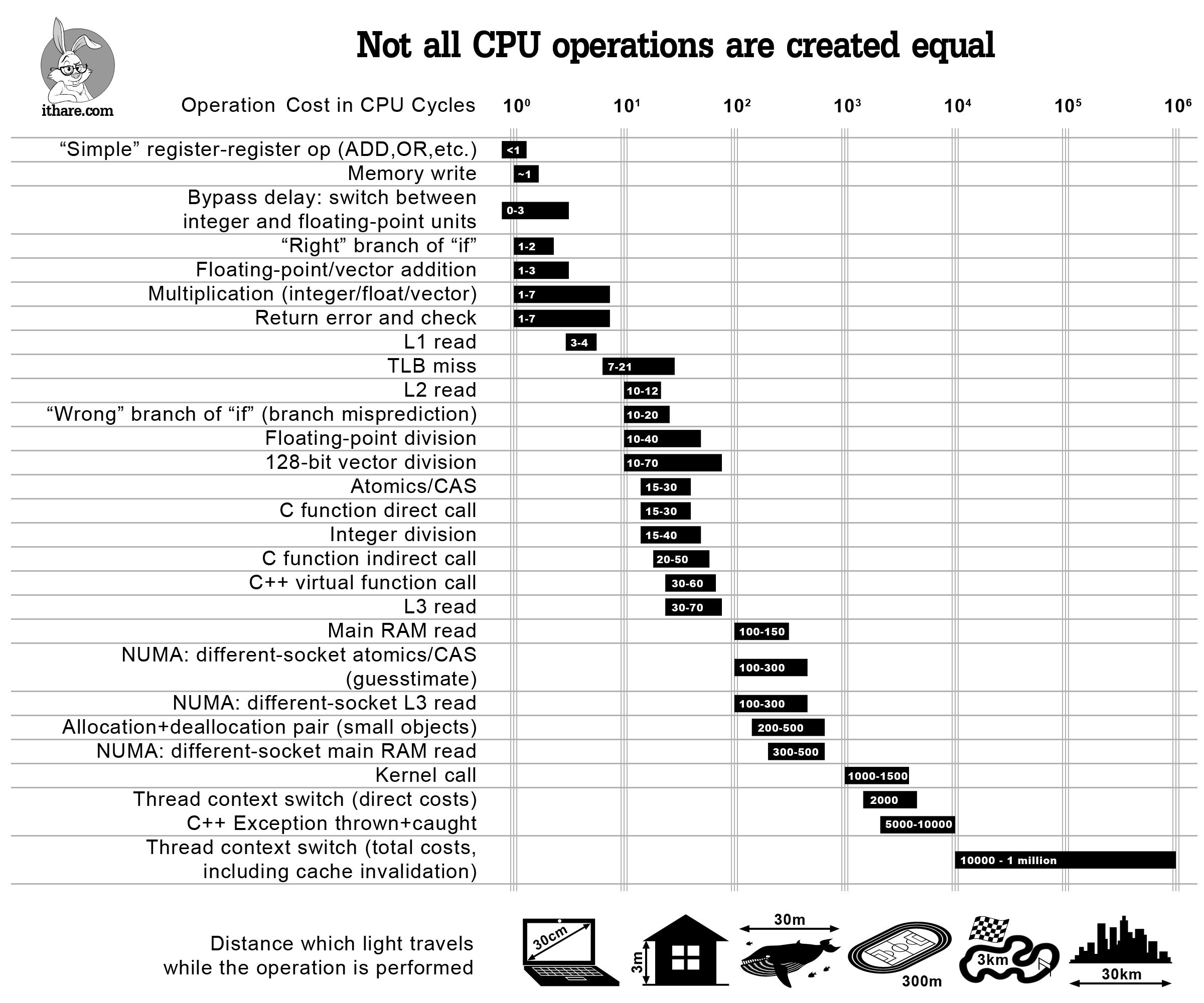
Когда нам нужно оптимизировать код, мы должны отпрофилировать его и упростить. Однако, иногда имеет смысл просто узнать приблизительную стоимость некоторых популярных операций, чтобы не делать с самого начала неэффективных вещей (и, надеюсь, не профилировать программу позже).
Итак, вот она — инфографика, которая должна помочь оценить стоимость конкретных операций в тактах ЦП — и ответить на такие вопросы, как «эй, сколько обычно стоит операция чтения L2?». Хотя ответы на все эти вопросы более или менее известны, я не знаю ни одного места, где все они перечислены и представлены в перспективе. Также отметим, что, хотя перечисленные стоимости, строго говоря, применяются только к современным процессорам x86/x64, ожидается, что аналогичное отношение стоимостей будут наблюдаться на других современных процессорах с большими многоуровневыми кэшами (такими как ARM Cortex A или SPARC); с другой стороны, MCU (включая ARM Cortex M) достаточно отличны, чтобы некоторые из закономерностей могли быть к ним не применимы.
И последнее, но не менее важное, предостережение: все оценки здесь лишь указывают на порядок; однако, учитывая масштаб различий между различными операциями, эти показания могут по-прежнему использоваться (по крайней мере, следует помнить, что нужно избегать «преждевременной пессимизации»).
С другой стороны, я все еще уверен, что такая диаграмма полезна, чтобы не говорить «эй, вызовы виртуальных функций ничего не стоят» — что может быть или не быть истинным в зависимости от того, как часто вы их вызываете. Вместо этого, используя инфографику выше, вы сможете увидеть, что если вы вызовете свою виртуальную функцию 100K раз в секунду на процессоре с частотой 3 ГГц — это, вероятно, не будет стоить вам более 0,2% от общего объема вашего процессора; однако, если вы вызываете одну и ту же виртуальную функцию 10M раз в секунду, это легко может означать, что виртуализация поглощает двузначные проценты ядра вашего процессора.
Другой способ приблизиться к тому же вопросу — сказать «эй, я вызываю виртуальную функцию один раз за кусок кода, который составляет 10000 тактов, поэтому виртуализация не будет потреблять более 1% от времени программы», —, но вам все равно нужен какой-то способ увидеть порядок величины связанных затрат — и приведенная выше диаграмма по-прежнему будет полезна.
Теперь давайте более подробно рассмотрим пункты в нашей инфографике выше.
Операции ALU и FPU
Для наших целей, говоря об операциях ALU, мы будем рассматривать только операции типа регистр-регистр. Если задействована память, затраты могут быть ОЧЕНЬ разными — это будет зависеть от того, «насколько велик был промах кэша» при доступе к памяти, как описано ниже.
«Простые» операции
В наши дни (и на современных процессорах), «простые» операции, такие как ADD/MOV/OR/…, могут легко выполняться быстрее одного такта ЦП. Это не означает, что операция будет выполняться буквально в течение половины такта. Напротив — в то время, как все операции все еще выполняются за целое число тактов, некоторые из них могут выполняться параллельно.
В [Agner4] (который, кстати, ИМХО является лучшим справочным руководством по оценке операций процессора) эта особенность отражается в наличии двух величин характеризующих каждую операцию: одна — это задержка (которая всегда представлена целым числом тактов), а другая — производительность. Следует отметить, однако, что в реальном мире, когда выходят за рамки оценок порядка, точное время будет сильно зависеть от характера вашей программы и от порядка, в котором компилятор поставил, казалось бы, несвязанные инструкции; вкратце — если вам нужно что-то лучше, чем порядок ожидания, вам нужно профилировать свою конкретную программу, скомпилированную вашим конкретным компилятором (и в идеале — на конкретном целевом процессоре тоже).
Дальнейшее обсуждение таких методов (известных как «внеочередное исполнение»), будучи Действительно Интересным, будет слишком аппаратно-ориентированным (как насчет «именования регистра», которое происходит под капотом процессора, чтобы уменьшить количество зависимостей, которые снижают эффективность работы внеочередного порядка?), и явно не входит в область нашего внимания в настоящий момент.
Целочисленное умножение/деление
Целочисленное умножение/деление достаточно дорогое по сравнению с «простыми» операциями выше. [Agner4] оценивает стоимость 32/64-битного умножения (MUL/IMUL в мире x86/x64) в 1–7 тактов (на практике я наблюдал более узкий диапазон значений, например 3–6 тактов), и стоимость 32/64-разрядного деления (известного как DIV/IDIV на x86/64) — около 12–44 тактов.
Операции с плавающей запятой
Стоимость операций с плавающей запятой взята из [Agner4] и варьируется от 1–3 тактов ЦП для сложения (FADD/FSUB) и 2–5 тактов для умножения (FMUL) до 37–39 тактов для деления (FDIV).
Если использовать скалярные SSE-операции (которыми, по-видимому, пользуется «каждая собака» в наши дни), показатели уменьшаться до 0,5–5 тактов для умножения (MULSS/MULSD) и до 1–40 тактов для деления (DIVSS/DIVSD); на практике, однако, вы должны ожидать скорее 10–40 тактов для деления (1 такт — это «взаимная пропускная способность», что на практике редко реализуется).
128-битные векторные операции
В течении уже нескольких лет ЦП поддерживают «векторные» операции (точнее — операции множественных данных Single Instruction Multiple Data или SIMD); в мире Intel они известны как SSE и AVX и в мире ARM — как ARM Neon. Забавно, что они работают с «векторами» данных, причем данные имеют одинаковый размер (128 бит для SSE2-SSE4, 256 бит для AVX и AVX2 и 512 бит для предстоящего AVX-512), но интерпретировать их можно по-разному. Например, 128-битный регистр SSE2 может быть интерпретирован как (a) два double, (b) четыре float, © два 64-битных integer, (d) четыре 32-битных integer, (e) восемь 16-битных integer, (f) шестнадцать 8-битных integer.
[Agner4] оценивает целочисленное сложение над 128-битным вектором в < 1 такт, если вектор интерпретируется как 4 × 32-битных целых числа и в 4 такта, если это 2 × 64-битных целых числа; умножение (4 × 32 бита) оценивается в 1-5 тактов — и в последний раз, когда я проверял, не было операций целочисленного векторного деления в наборе команд x86/x64. Операций с плавающей запятой над 128-битными векторами оцениваются от 1-3 тактов ЦП для сложения и 1-7 тактов ЦП для умножения, для деления до 17-69 тактов.
Задержки перехода
Не такая очевидная вещь, связанная с затратами на вычисления, заключается в том, что переключение между целыми и плавающими инструкциями не бесплатно. [Agner3] оценивает эту стоимость (известную как «задержка перехода») в 0–3 такта в зависимости от процессора. На самом деле проблема более общая, и (в зависимости от ЦП) также могут быть штрафы за переключение между векторными (SSE) целочисленными инструкциями и обычными (скалярными) целочисленными инструкциями.
Совет по оптимизации: в коде, для которого критична производительность, избегайте комбинирования вычислений с плавающей запятой и целыми числами.
Ветвление
Следующее, что мы будем обсуждать, — это ветвление кода. Переход (if внутри вашей программы), по сути, является сравнением и изменением в счетчике команд. В то время как обе эти вещи просты, ветвление может быть достаточно затратным. Обсуждение, почему это так, опять получится слишком аппаратно-ориентированным (в частности, это затрагивает конвейерную обработку и спекулятивное исполнение), но с точки зрения разработчика программного обеспечения это выглядит так:
- если процессор правильно угадывает, куда будет направлено выполнение (это до фактического вычисления условия if), тогда стоимость перехода составляет около 1–2 тактов ЦП
- однако, если процессор делает неправильное предположение — это приводит к тому, что ЦП «глохнет»
Продолжительность этой задержки оценивается в 10–20 тактов процессора, для последних процессоров Intel — около 15–20 тактов [Agner3].
Отметим, что в то время как макрос GCC __builtin_expect (), как полагают, влияет на предсказание ветвления — и он работал таким образом всего 15 лет назад, он больше не актуален, по крайней мере, для процессоров Intel (начиная с Core 2 или около того).
Как описано в [Agner3], на современных Intel-процессорах предсказание перехода всегда динамично (или, по крайней мере, доминируют динамические решения); это, в свою очередь, подразумевает, что ожидаемые отклонения от кода __builtin_expect () не будут влиять на предсказание переходов (на современных процессорах Intel). Однако __builtin_expect () все еще влияет на способ генерации кода, как описано в разделе «Доступ к памяти» ниже.
Доступ к памяти
В 80-е годы скорость процессора была сопоставима с задержкой памяти (например, процессор Z80, работающий на частоте 4 МГц, тратил 4 такта на команду типа регистр-регистр и 6 тактов на команду типа регистр-память). В то время можно было вычислить скорость программы, просто посмотрев на сборку.
С тех пор скорости процессоров выросли на 3 порядка, а задержки памяти улучшились только в 10–30 раз или около того. Чтобы справиться с оставшимся более чем тридцати кратным несоответствием, были введены все эти виды кэшей. Современный процессор обычно имеет 3 уровня кэшей. В результате скорость доступа к памяти очень сильно зависит от ответа на вопрос «где хранятся данные, которые мы пытаемся прочитать?». Чем ниже уровень кэша, где был найден ваш запрос, тем быстрее вы можете его получить.
