Монолит для сотен версий клиентов: как мы пишем и поддерживаем тесты

Всем привет!
Я бэкенд-разработчик в серверной команде Badoo. На прошлогодней конференции HighLoad я выступал с докладом, текстовым вариантом которого и хочу поделиться с вами. Этот пост будет наиболее полезен тем, кто самостоятельно пишет тесты для бэкенда и испытывает проблемы с тестированием legacy-кода, а также тем, кто хочет тестировать сложную бизнес-логику.
О чём пойдёт речь? Сначала я коротко расскажу о нашем процессе разработки и о том, как он влияет на нашу потребность в тестах и желание эти тесты писать. Затем мы пройдёмся снизу вверх по пирамиде автоматизации тестирования, обсудим используемые нами виды тестов, поговорим об инструментах внутри каждого из них и о том, какие проблемы мы решаем с их помощью. В конце рассмотрим, как поддерживать и запускать всё это добро.
Наш процесс разработки
Мы проиллюстрировали наш процесс разработки:

Гольфист — это бэкенд-разработчик. В какой-то момент ему прилетает задача на разработку, обычно в виде двух документов: требования со стороны бизнеса и технический документ, описывающий изменения в нашем протоколе взаимодействия между бэкендом и клиентами (мобильными приложениями и сайтом).
Разработчик пишет код и запускает его в эксплуатацию, причём раньше всех клиентских приложений. Вся функциональность защищена какими-то фиче-флагами или А/В-тестами, это прописывается в техническом документе. После этого в соответствии с текущими приоритетами и продуктовым роадмапом выпускаются клиентские приложения. Для нас, бэкенд-разработчиков, совершенно непредсказуемо, когда та или иная фича будет имплементироваться на клиентах. Релизный цикл у клиентских приложений несколько сложнее и дольше, чем у нас, поэтому наши продакт-менеджеры буквально жонглируют приоритетами.
Большое значение имеет принятая в компании культура разработки: бэкенд-разработчик отвечает за фичу от момента её реализации на бэкенде до последней интеграции на последней платформе, на которой изначально планировалось реализовывать эту фичу.
Вполне возможна такая ситуация: полгода назад ты выкатил какую-то фичу, клиентские команды её долго не внедряли, потому что приоритеты у компании изменились, ты уже занят работой над другими задачами, у тебя новые сроки, приоритеты — и тут к тебе прибегают коллеги и говорят: «Помнишь вот эту штуку, которую ты полгода назад запилил? Она не работает». И вместо того чтобы заниматься новыми задачами, ты тушишь пожары.

Поэтому у наших разработчиков появляется несвойственная PHP-программистам мотивация — делать так, чтобы проблем на этапе интеграции возникало как можно меньше.
Что хочется сделать в первую очередь, чтобы удостовериться в том, что фича работает?
Конечно, первое, что приходит на ум, — провести ручное тестирование. Ты берёшь в руки приложение, а оно этого не умеет — ведь фича новая, клиенты займутся ею через полгода. Ну и ручное тестирование не даёт никакой гарантии, что за время, которое пройдёт с момента релиза бэкенда до начала интеграции, на клиентах никто ничего не сломает.
И вот тут нам на помощь приходят автоматические тесты.
Unit-тесты
Самые простые тесты, которые мы пишем, — Unit-тесты. В качестве основного языка для бэкенда мы используем PHP, а в качестве фреймворка для модульного тестирования — PHPUnit. Забегая вперёд, скажу, что все наши бэкенд-тесты написаны на базе этого фреймворка.
Unit-тестами мы чаще всего покрываем какие-то маленькие изолированные кусочки кода, проверяем работоспособность методов или функций, то есть речь идёт о крошечных единицах бизнес-логики. Наши модульные тесты не должны ни с чем взаимодействовать, обращаться к базам или сервисам.
SoftMocks
Главная трудность, с которой сталкиваются разработчики при написании модульных тестов, — нетестируемый код, и обычно это legacy-код.
Простой пример. Компании Badoo 12 лет, когда-то она была очень маленьким стартапом, который развивали несколько человек. Стартап вполне успешно существовал вообще безо всяких тестов. Потом мы стали достаточно большими и поняли, что без тестов жить нельзя. Но к этому времени было написано много кода, который работал. Не переписывать же его только ради покрытия тестами! Это было бы не очень разумно с точки зрения бизнеса.
Поэтому мы разработали маленькую open source-библиотеку SoftMocks, которая делает наш процесс написания тестов дешевле и быстрее. Она перехватывает все include/require PHP-файлов и на лету заменяет исходный файл на модифицированное содержимое, то есть на переписанный код. Это позволяет нам создавать заглушки для любого кода. Здесь подробно рассказано о том, как функционирует библиотека.
Примерно вот так это выглядит для разработчика:
//mock константы
\Badoo\SoftMocks::redefineConstant($constantName, $newValue);
//mock любых методов: статических, приватных, финальных
\Badoo\SoftMocks::redefineMethod(
$class,
$method,
$method_args,
$fake_code
);
//mock функций
\Badoo\SoftMocks::redefineFunction(
$function,
$function_args,
$fake_code
);
C помощью таких несложных конструкций мы можем глобально переопределять всё что хотим. В том числе они позволяют нам обходить ограничения стандартного мокера PHPUnit. То есть мы можем mock«ать статические и приватные методы, переопределять константы и делать многое другое, что невозможно в обычном PHPUnit.
Однако мы столкнулись с проблемой: разработчикам кажется, что при наличии SoftMocks нет нужды писать тестируемый код — всегда можно «причесать» код нашими глобальными mock«ами, и всё будет хорошо работать. Но такой подход ведёт к усложнению кода и накапливанию «костылей». Поэтому мы приняли несколько правил, которые позволяют нам держать ситуацию под контролем:
- Весь новый код должен легко тестироваться стандартными mock«ами PHPUnit. Если это условие соблюдено, значит, код тестируемый и можно легко выделить маленький кусочек и протестировать только его.
- SoftMocks допустимо применять со старым кодом, который написан не подходящим для unit-тестирования образом, а также в случаях, когда по-другому делать слишком дорого/долго/трудно (нужное подчеркнуть).
Соблюдение этих правил тщательно контролируется на этапе code review.
Мутационное тестирование
Отдельно хочу сказать о качестве юнит-тестов. Я думаю, что многие из вас используют такую метрику, как процент покрытия (code coverage). Но она, к сожалению, не отвечает на один вопрос: «Хороший ли юнит-тест я написал?». Вполне возможно, что вы написали такой тест, который на самом деле ничего не проверяет, не содержит ни одного assert«а, зато генерирует отличное покрытие кода. Конечно, пример утрирован, но ситуация не так уж далека от реальности.
С недавнего времени мы начали внедрять мутационное тестирование. Это довольно старая, но не очень известная концепция. Алгоритм такого тестирования довольно прост:
- берём код и code coverage;
- парсим и начинаем менять код: true на false, > на >=, + на — (в общем, всячески вредить);
- для каждого такого изменения-мутации прогоняем наборы тестов, которые покрывают изменённую строку;
- если тесты упали, то они хорошие и действительно не позволяют нам сломать код;
- если же тесты прошли, скорее всего, они недостаточно эффективны, несмотря на покрытие, и, возможно, стоит посмотреть на них более внимательно, докинуть какие-то assert«ы (или есть не покрытый тестом участок).
Для PHP есть несколько готовых фреймворков, например Humbug и Infection. К сожалению, нам они не подошли, потому что несовместимы с SoftMocks. Поэтому мы написали свою маленькую консольную утилиту, которая делает то же самое, но использует наш внутренний формат code coverage и дружит с SoftMocks. Сейчас разработчик запускает её вручную и анализирует написанные им тесты, но мы работаем над внедрением инструмента в наш процесс разработки.
Интеграционное тестирование
С помощью интеграционных тестов мы проверяем взаимодействие с различными сервисами и базами данных.
Чтобы дальнейший рассказ был более понятен, давайте разработаем вымышленное промо и покроем его тестами. Представим, что наши продакт-менеджеры решили раздать билеты на конференцию нашим самым преданным пользователям:

Промо должно быть показано, если:
- у пользователя в поле «Работа» указано «программист»,
- пользователь участвует в А/В-тесте HL18_promo,
- пользователь зарегистрирован более двух лет назад.
По нажатию на кнопку «Получить билет» мы должны сохранить данные этого пользователя в какой-то список, чтобы передать нашим менеджерам, которые раздают билеты.
Даже в этом довольно простом примере есть вещь, которую нельзя проверить с помощью юнит-тестов, — взаимодействие с базой данных. Для этого нам необходимо воспользоваться интеграционными тестами.
Рассмотрим стандартный способ тестирования взаимодействия с базой данных, предлагаемый PHPUnit:
- Поднимаем тестовую базу данных.
- Подготавливаем DataTables и DataSets.
- Запускаем тест.
- Очищаем тестовую базу данных.
Какие сложности нас подстерегают при таком подходе?
- Нужно поддерживать структуры DataTables и DataSets. Если мы изменили схему таблицы, то необходимо отразить эти изменения в тесте, что не всегда удобно и требует дополнительного времени.
- Необходимо время на подготовку базы данных. Каждый раз при настройке теста нам нужно что-то туда заливать, создавать какие-то таблицы, а это долго и хлопотно, если тестов много.
- И самый важный недостаток: параллельный запуск таких тестов делает их нестабильными. Мы запустили тест А, он начал писать в тестовую таблицу, которую сам создал. Одновременно мы запустили тест Б, который хочет работать с той же тестовой таблицей. Как следствие, возникают взаимные блокировки и прочие непредвиденные ситуации.
Чтобы избежать этих проблем, мы разработали свою маленькую библиотеку DBMocks.
DBMocks
Принцип работы таков:
- С помощью SoftMocks мы перехватываем все обёртки, через которые работаем с базами данных.
- Когда
запрос проходит через mock, парсим SQL-запрос и вытаскиваем из него DB + TableName, а из connection достаём хост. - На том же хосте в tmpfs мы создаём временную таблицу с такой же структурой, как у оригинальной (структуру копируем с помощью SHOW CREATE TABLE).
- После этого все запросы, которые будут приходить через mock«и к этой таблице, мы переадресуем в свежесозданную временную.
Что нам это даёт:
- не надо постоянно заботиться о структурах;
- тесты теперь не могут повредить данные в исходных таблицах, потому что мы на лету переадресуем их во временные таблицы;
- мы по-прежнему тестируем совместимость с версией MySQL, с которой работаем, и если запрос вдруг перестанет быть совместимым с новой версией, то наш тест это увидит и упадёт.
- и главное — тесты теперь изолированы, и, даже если запустить их параллельно, потоки разойдутся по разным временным таблицам, так как в названия тестовых таблиц мы добавляем уникальный для каждого теста ключ.
API-тестирование
Разница между юнит- и API-тестами хорошо иллюстрируется этой гифкой:

Замок работает отлично, но вот прикреплён он не к той двери.
Наши тесты имитируют клиентскую сессию, умеют отправлять запросы к бэкенду, соблюдая наш протокол, и бэкенд отвечает им как реальному клиенту.
Пул тестовых пользователей
Что нам нужно для успешного написания таких тестов? Вернёмся к условиям показа нашего промо:
- у пользователя в поле «Работа» указано «программист»,
- пользователь участвует в А/В-тесте HL18_promo,
- пользователь зарегистрирован более двух лет назад.
Как видно, здесь всё про пользователя. Да и в реальности 99% API-тестов требуют наличия авторизованного зарегистрированного пользователя, который присутствует во всех сервисах и базах данных.
Где его взять? Можно попробовать зарегистрировать его в момент тестирования, но:
- это долго и ресурсозатратно;
- после завершения теста этого пользователя нужно как-то удалить, что довольно нетривиальная задача, если мы говорим о больших проектах;
- наконец, как и во многих других высоконагруженных проектах, мы много операций выполняем в фоновом режиме (добавление пользователя в различные сервисы, репликация в другие дата-центры и т. д.); тесты ничего не знают о таких процессах, но, если они неявно полагаются на результаты их выполнения — возникает риск нестабильности.
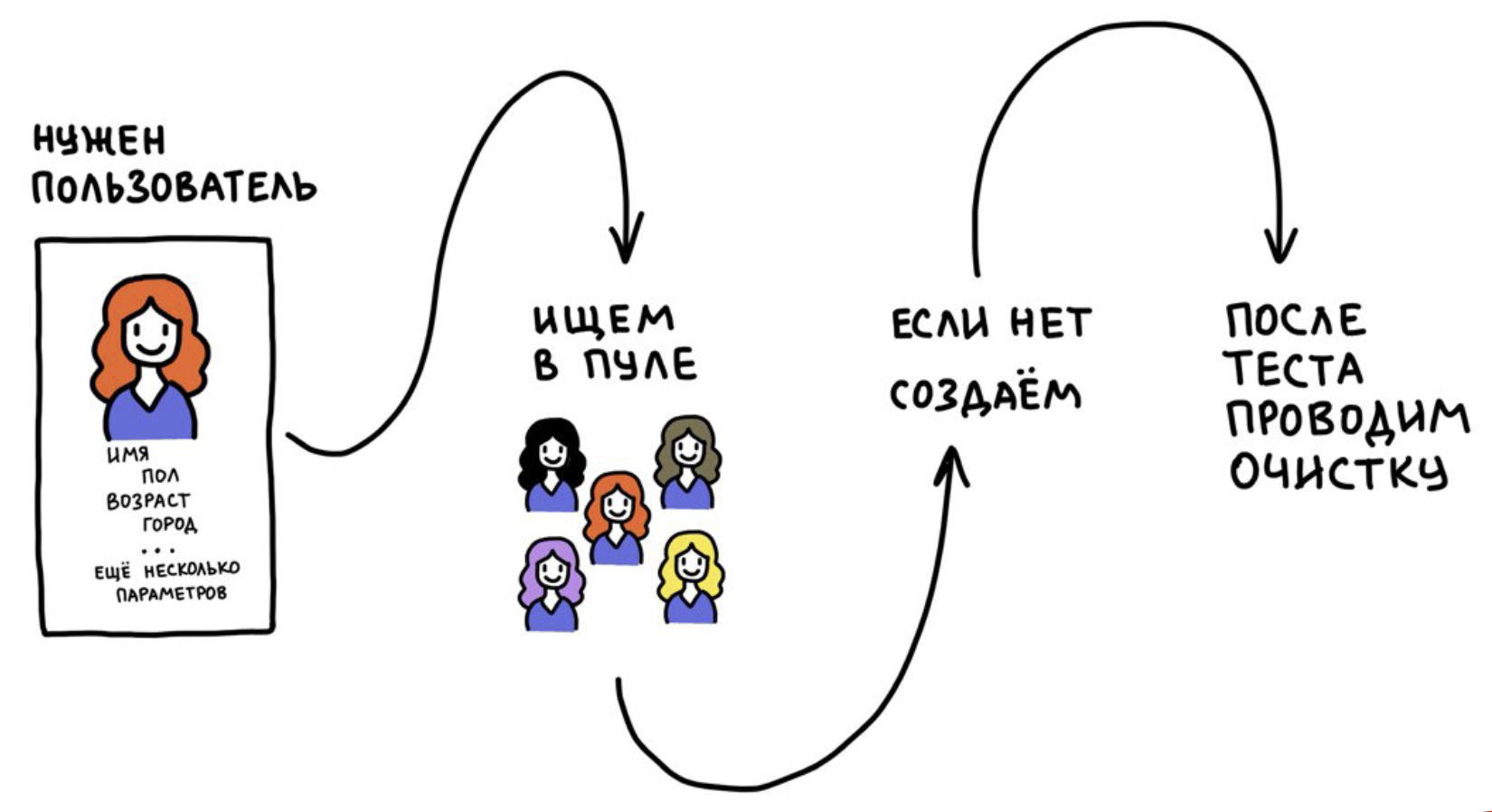
Мы разработали инструмент, который называется «Пул тестовых пользователей». В его основе лежат две идеи:
- Пользователей мы не регистрируем каждый раз, а используем многократно.
- После теста сбрасываем данные пользователя до первоначального состояния (на момент регистрации). Если этого не делать, тесты со временем станут нестабильными, потому что пользователи окажутся «загрязнены» информацией из других тестов.
Работает это примерно так:
В какой-то момент мы захотели запускать наши API-тесты в production-окружении. Почему мы вообще захотели этого? Потому что devel-инфраструктура не то же самое, что production.
Хотя мы и пытаемся постоянно повторять production-инфраструктуру в уменьшенном размере, devel никогда не будет её полноценной копией. Чтобы быть абсолютно уверенными в том, что новый билд соответствует ожиданиям и нет никаких проблем, мы выкладываем новый код на preproduction-кластер, который работает с production-данными и сервисами, и уже там прогоняем наши API-тесты.
В этом случае очень важно подумать о том, как изолировать тестовых пользователей от реальных.

Как осуществить изоляцию? У каждого нашего пользователя есть флаг is_test_user. На этапе регистрации он становится yes или no, и больше уже не меняется. По этому флагу мы изолируем пользователей во всех сервисах. Также важно, что мы исключаем тестовых пользователей из бизнес-аналитики и результатов А/В-тестирования, чтобы не искажать статистику.
Можно пойти и более простым путём: мы начинали с того, что всех тестовых пользователей «переселяли» в Антарктиду. Если у вас геосервис, это вполне рабочий способ.
QA API
Нам не просто нужен пользователь — он нам нужен с определёнными параметрами: чтобы работал программистом, участвовал в определённом А/В-тесте и был зарегистрирован более двух лет назад. Тестовым пользователям мы легко можем назначить профессию с помощью нашего бэкенд-API, а вот попадание в А/В-тесты носит вероятностный характер. А условие о регистрации более двух лет назад вообще сложно выполнить, потому что мы не знаем, когда пользователь появился в пуле.
Для решения этих проблем у нас есть QA API. Это, по сути, бэкдор для тестирования, представляющий собой хорошо документированные API-методы, которые позволяют быстро и легко управлять данными пользователя и менять их состояние в обход основного протокола нашего общения с клиентами. Методы пишут бэкенд-разработчики для QA-инженеров и для использования в UI и API-тестах.
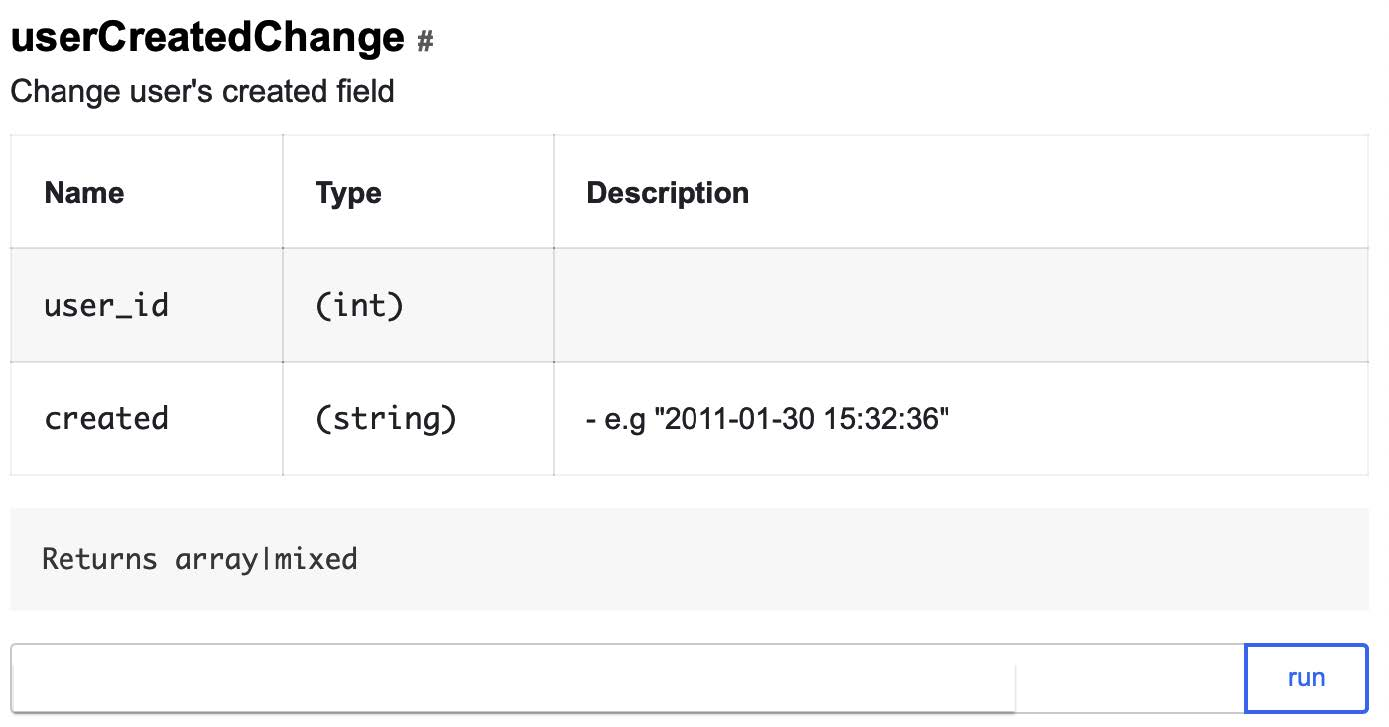
QA API можно применять только в случае с тестовыми пользователями: если соответствующего флага нет, тест сразу же упадёт. Вот так выглядит один из наших QA API-методов, который позволяет изменить дату регистрации пользователя на произвольную:
А так будут выглядеть три вызова, которые позволят быстро изменить данные тестового пользователя так, чтобы они удовлетворяли условиям отображения промо:
- В поле «Работа» указано «программист»:
addUserWorkEducation?user_id=ID&works[]=Badoo,
программист - Пользователь участвует в A/B-тесте HL18_promo:
forceSplitTest?user_id=ID&test=HL18_promo - Зарегистрирован более двух лет назад:
userCreatedChange?user_id=ID&created=2016-09-01
Поскольку это бэкдор, крайне важно подумать о безопасности. Мы защитили наш сервис несколькими способами:
- изолировали на уровне сети: к сервисам можно обратиться только из офисной сети;
- с каждым запросом мы передаём secret, без которого нельзя получить доступ к QA API даже из офисной сети;
- методы работают только с тестовыми пользователями.
RemoteMocks
Для работы с удалённым бэкендом API-тестов нам могут требоваться mock«и. Для чего? К примеру, если API-тест в production-окружении начнёт обращаться к базе данных, нам нужно позаботиться о том, чтобы данные в ней были очищены от тестовых. Кроме того, mock«и помогают сделать ответ теста более пригодным для тестирования.
У нас есть три текста:
Badoo — многоязычное приложение, у нас есть сложный компонент локализации, который позволяет быстро переводить и получать переводы для текущего местоположения пользователя. Наши локализаторы постоянно работают над улучшением переводов, проводят А/В-тесты с лексемами, ищут более удачные формулировки. И, проводя тест, мы не можем знать, какой текст будет возвращён сервером, — он может измениться в любой момент. Зато мы можем с помощью RemoteMocks проверить, правильно ли обратились к компоненту локализации.
Как работают RemoteMocks? Тест просит бэкенд инициализировать их для своей сессии, и при получении всех последующих запросов бэкенд проверяет наличие mock«ов для текущей сессии. Если они есть, он просто инициализирует их с помощью SoftMocks.
Если мы хотим создать удалённый mock, то указываем, какой класс или метод нужно заменить и на что. Все последующие запросы к бэкенду будут выполняться с учётом этого mock«а:
$this->remoteInterceptMethod(
\Promo\HighLoadConference::class,
'saveUserEmailToDb',
true
);
Ну, а теперь соберём наш API-тест:
//получаем эмулятор клиента с уже авторизованным пользователем
$app_startup = [
'supported_promo_blocks' => [\Mobile\Proto\Enum\PromoBlockType::GENERIC_PROMO]
];
$Client = $this->getLoginedConnection(BmaFunctionalConfig::USER_TYPE_NEW, $app_startup);
//подстраиваем пользователя
$Client->getQaApiClient()->addUserWorkEducation(['Badoo, программист']);
$Client->getQaApiClient()->forceSplitTest('HL18_promo');
$Client->getQaApiClient()->userCreatedChange('2016-09-01');
//мокаем запись в базу данных
$this->remoteInterceptMethod(\Promo\HighLoadConference::class, 'saveUserEmail', true);
//проверяем, что вернулся промоблок, согласно протоколу
$Resp = $Client->ServerGetPromoBlocks([]);
$this->assertTrue($Resp->hasMessageType('CLIENT_NEXT_PROMO_BLOCKS'));
$PromoBlock = $Resp->CLIENT_NEXT_PROMO_BLOCKS;
…
//пользователь жмёт на CTA, проверяем, что вернулся ответ, согласно протоколу
$Resp = $Client->ServerPromoAccepted($PromoBlock->getPromoId());
$this->assertTrue($Resp->hasMessageType('CLIENT_ACKNOWLEDGE_COMMAND'));
Таким нехитрым способом мы можем тестировать любую функциональность, которая приходит на разработку в бэкенд и требует изменений в мобильном протоколе.
Правила использования API-тестов
Вроде бы всё хорошо, но мы снова столкнулись с проблемой: API-тесты получились слишком удобными для разработки и появился соблазн использовать их везде. В результате однажды мы осознали, что начинаем решать с помощью API-тестов задачи, для решения которых они не предназначены.
Почему это плохо? Потому что API-тесты очень медленные. Они ходят по сети, обращаются к бэкенду, который поднимает сессию, ходит в базу и кучу сервисов. Поэтому мы разработали набор правил использования API-тестов:
- цель API-тестов — проверять протокол взаимодействия между клиентом и сервером, а также правильность интеграции нового кода;
- допустимо покрывать ими сложные процессы, например цепочки действий;
- нельзя с их помощью тестировать мелкую вариативность ответа сервера — это задача модульных тестов;
- в ходе code review мы проверяем в том числе и тесты.
UI-тесты
Раз уж мы рассматриваем пирамиду автоматизации, расскажу немного и о UI-тестах.
Бэкенд-разработчики в Badoo не пишут UI-тесты — для этого у нас есть специальная команда в департаменте QA. Мы покрываем UI-тестами фичу, когда она уже доведена до ума и стабилизирована, потому что считаем, что неразумно тратить ресурсы на достаточно дорогую автоматизацию фичи, которая, возможно, дальше А/В-теста не пойдёт.
Для мобильных автотестов мы используем Calabash, а для веба — Selenium. Здесь рассказывается про нашу платформу для автоматизации и тестирования.
Прогон тестов
У нас сейчас 100 000 модульных тестов, 6000 — интеграционных и 14 000 API-тестов. Если попробовать запустить их в один поток, то даже на самой мощной нашей машине полный прогон всех займёт: модульных — 40 минут, интеграционных — 90 минут, API-тестов — десять часов. Это слишком долго.
Параллелизация
О нашем опыте параллелизации unit-тестов мы рассказывали в этой статье.
Первое решение, которое кажется очевидным, — запускать тесты в несколько потоков. Но мы пошли дальше и сделали облако для параллельного запуска, чтобы иметь возможность масштабирования аппаратных ресурсов. Упрощённо его работа выглядит так:
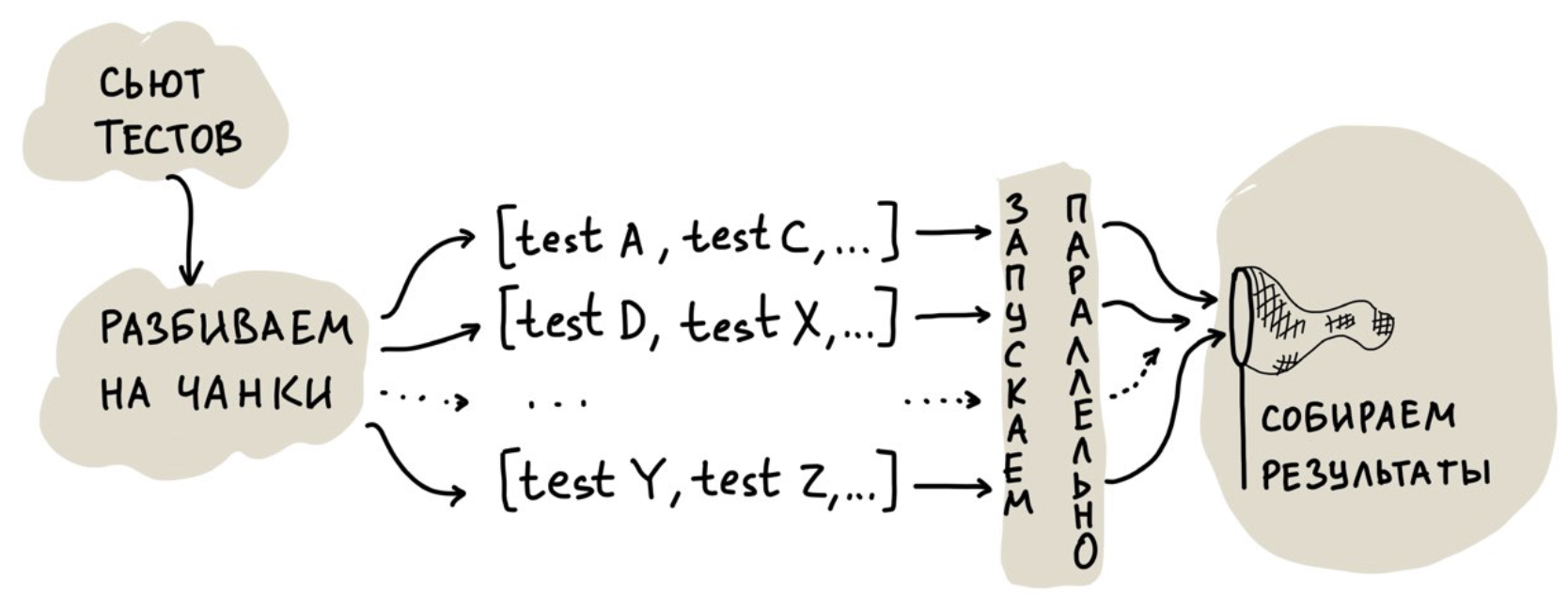
Самая интересная задача здесь — распределение тестов между потоками, то есть их разбивка на чанки.
Можно поделить их поровну, но все тесты разные, поэтому может возникнуть сильный перекос по времени выполнения какого-то потока: все потоки уже добежали, а один висит полчаса, так как ему «повезло» с очень медленными тестами.
Можно запустить несколько потоков и «скармливать» им тесты по одному. В этом случае недостаток менее очевиден: на инициализацию окружения есть накладные расходы, которые при большом количестве тестов и таком подходе начинают играть важную роль.
Что сделали мы? Начали собирать статистику по времени прогона каждого теста, а затем стали компоновать чанки таким образом, чтобы один поток согласно статистики выполнялся не дольше 30 секунд. При этом мы довольно плотно упаковываем тесты в чанки, чтобы их получилось меньше.
Однако у нашего подхода тоже есть недостаток. Он связан с API-тестами: они очень медленные и занимают много ресурсов, не давая выполняться быстрым тестам.
Поэтому мы разделили облако на две части: в первой запускаются только быстрые тесты, а во второй могут запускаться как быстрые, так и медленные. При таком подходе у нас всегда есть кусочек облака, который способен обработать быстрые тесты.
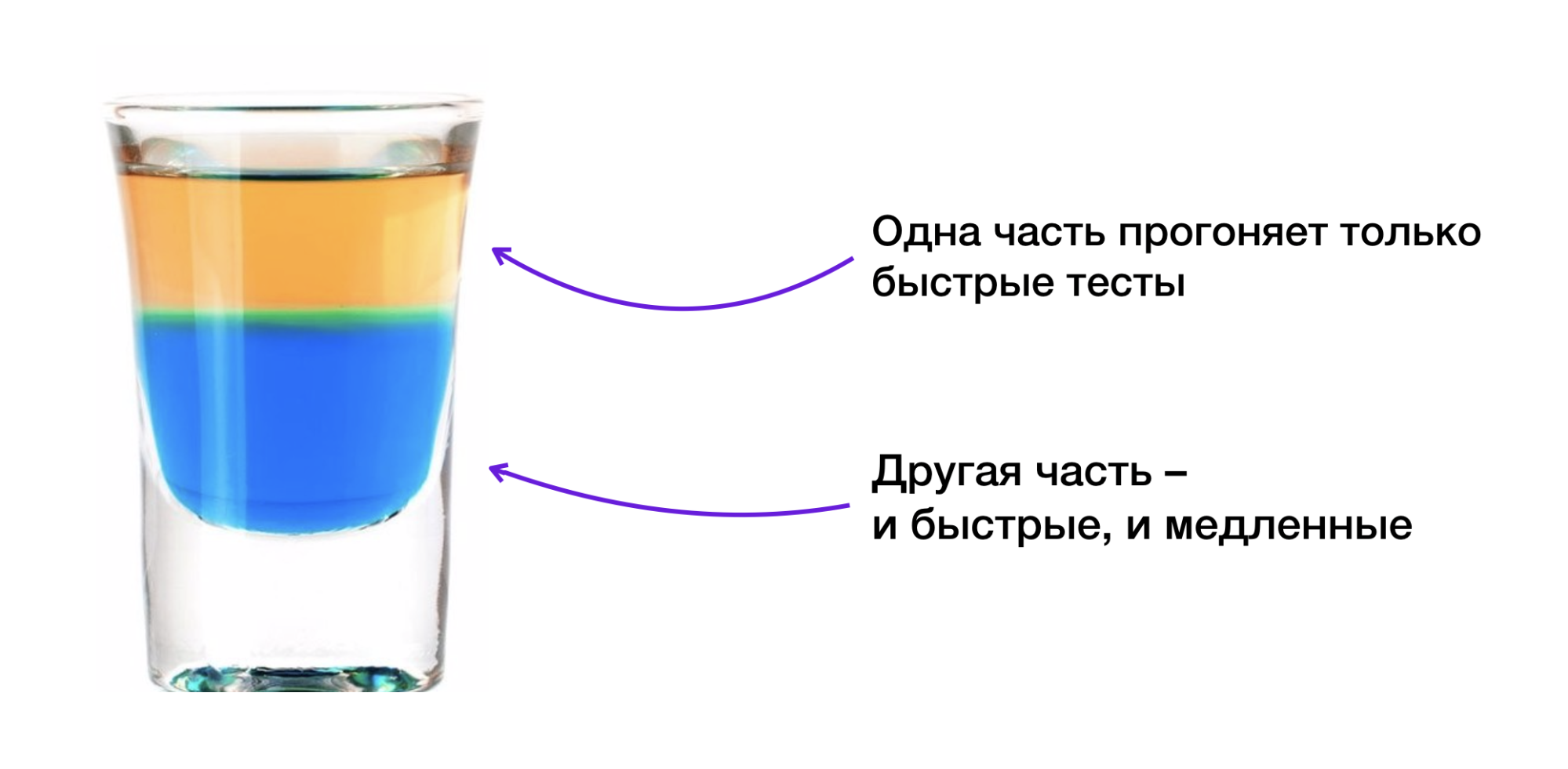
В результате модульные тесты стали прогоняться за минуту, интеграционные — за пять минут, а API-тесты — за 15 минут. То есть на полный прогон вместо 12 часов уходит не больше 22 минут.
Прогон тестов на основе покрытия кода
У нас большой сложный монолит, и, по-хорошему, нам надо постоянно гонять все тесты, поскольку изменение в одном месте может что-то сломать в другом. Это один из основных недостатков монолитной архитектуры.
В какой-то момент мы пришли к выводу, что не нужно каждый раз прогонять все тесты — можно делать прогоны, основанные на code coverage:
- Берём наш branch diff.
- Формируем список изменённых файлов.
- По каждому файлу получаем список тестов,
которые его покрывают. - Из этих тестов создаём набор и запускаем его в тестовом облаке.
Где взять coverage? Мы собираем данные раз в сутки, когда простаивает инфраструктура среды разработки. Количество прогоняемых тестов заметно уменьшилось, скорость получения обратной связи от них, напротив, увеличилась в разы. Профит!
Дополнительным бонусом стала возможность прогонять тесты для патчей. Несмотря на то, что Badoo уже давно не стартап, мы всё ещё можем быстро внедрять изменения в production, быстро выливать hot fix, раскатывать фичи, менять конфигурацию. Как правило, нам очень важна скорость выкатывания патчей. Новый подход дал большой прирост в скорости обратной связи от тестов, потому что нам теперь не нужно долго ждать полного прогона.
Но без недостатков никуда. Мы релизим бэкенд два раза в день, и покрытие актуально только для первого релиза, до первого билда, после чего начинает отставать на один билд. Поэтому для билдов мы прогоняем полный тестовый набор. Для нас это гарантия того, что code coverage нигде не отстал и выполнены все необходимые тесты. Худшее, что может случиться, — это то, что какие-то упавшие тесты мы поймаем на этапе сборки билда, а не на предыдущих этапах. Но такое бывает очень редко.
Однако подход не очень эффективен в случае с API-тестами, поскольку они генерируют очень обширный code coverage. По ходу тестирования логики они поднимают кучу разных файлов, ходят в сессии, базы и так далее. Если в одном из затрагиваемых файлов что-то поменять, все API-тесты попадут в тестовый набор и преимущества подхода будут нивелированы.
Заключение
- Вам нужны все уровни пирамиды автоматизации тестирования, чтобы быть уверенными в корректной работе функциональности. Если вы пропустили какой-то уровень, вероятно, какая-то из проблем остаётся непокрытой.
- Количество тестов ≠ качество. Выделяйте время на code review тестов и мутационное тестирование, это полезный инструмент.
- Если вы планируете работать с тестовыми пользователями, подумайте, как их изолировать от реальных. И не забудьте исключить их из статистики и аналитики.
- Не бойтесь бэкдоров. Они действительно упрощают и ускоряют написание тестов и очень сильно помогают в ручном тестировании.
- Статистика, и ещё раз статистика! Имея статистические данные по тестам, можно улучшать распараллеливание прогонов и уменьшать количество прогоняемых тестов.
Пользуясь случаем, напомню про второй Badoo PHP Meetup 16 марта. Он целиком и полностью будет посвящён автотестам для PHP-разработчика. Места в зале закончились, но будет трансляция. Приглашаю поучаствовать онлайн! Стартуем в 12:00, стрим — на нашем YouTube-канале.
