Многорукие бандиты в рекомендациях
Всем привет! Меня зовут Миша Каменщиков, я занимаюсь Data Science и разработкой микросервисов в команде рекомендаций Авито. В этой статье я расскажу про наши рекомендации похожих объявлений и о том, как мы улучшаем их при помощи многоруких бандитов. С докладом на эту тему я выступал на конференции Highload++ Siberia и на мероприятии «Data & Science: Маркетинг».

Сначала — небольшой обзор всех видов рекомендаций, которые есть на Авито.
Персонализированные User-Item рекомендации
User-Item рекомендации строятся на основе действий пользователя и призваны помочь ему быстрее найти интересующий товар, либо показать что-то потенциально интересное. Их можно увидеть на главной странице сайта и приложений или в почтовых рассылках. Для создания таких рекомендаций мы используем два типа моделей: оффлайн и онлайн.
В основе оффлайн модели используются алгоритмы матричной факторизации, которые обучаются на всех данных за несколько дней, и рекомендации складываются в быстрое хранилище для раздачи пользователям. Онлайн модели считают рекомендации на лету, используя контент объявлений из истории пользователя. Преимущество оффлайн моделей — они дают более точные и качественные рекомендации, но при этом они не учитывают самые последние действия пользователей, которые могли произойти во время обучения модели, когда обучающая выборка была зафиксирована. Онлайн модели сразу же реагируют на действия пользователей, и рекомендации могут меняться с каждый действием.
Cold-start рекомендации
Во всех рекомендательных системах есть так называемая проблема «холодного старта». Её смысл в том, что описанные выше модели не могут дать рекомендации новому пользователю без истории действий. В таких случаях лучше познакомить пользователя с тем, что есть на сайте, при этом выбрав не просто случайные объявления, а, например, объявления из категорий, которые популярны в регионе пользователя.
Рекомендации поисков
Для пользователей, которые часто пользуются поиском, мы делаем рекомендованные шорткаты для поиска — они отправляют пользователя в определенную категорию и выставляют фильтры. Такие рекомендации можно найти наверху главной страницы приложения.
Item-Item рекомендации
Item-Item рекомендации представлены на сайте в виде похожих объявлений на карточке товара. Их можно увидеть на всех платформах под описанием объявления. Модель рекомендаций на данный момент исключительно контентная и не использует информацию о действиях пользователей, поэтому к новому объявлению мы сразу можем подобрать похожие среди активных объявлений на сайте. Далее в статье я расскажу именно об этом виде рекомендаций.
Более подробно о всех видах рекомендаций на Авито мы уже писали в нашем блоге. Почитайте, если вам интересно.
Похожие объявления
Вот как выглядит блок с похожими объявлениями:

Этот вид рекомендаций появился на сайте раньше всего, и логика была реализована на поисковом движке Sphinx. Фактически, эта модель представляет собой линейную комбинацию различных факторов: совпадение слов, дистанция, разница цены и другие параметры.
На основе параметров целевого объявления генерируется запрос в Sphinx, а для ранжирования используются встроенные ранкеры.
Пример запроса:
SELECT
id,
weight as ranker_weight,
ranker_weight * 10 +
(metro_id=42) * 5 +
(location_id=2525) * 10 +
(110000 / (abs(price - 1100000) + 110000)) * 5 as rel
FROM items
WHERE MATCH('@title велосипед|scott|scale|700|premium') AND microcat_id=100
ORDER BY rel DESC, sort_time DESC
LIMIT 0,32 OPTION max_matches=32,
ranker=expr('sum(word_count)')
Если попытаться описать этот подход более формально, то можно представить ранкеры в виде некоторых весов  , а параметры объявлений
, а параметры объявлений  (source — исходное объявление) и
(source — исходное объявление) и  (целевое объявление). Для каждого из параметров введем функцию схожести
(целевое объявление). Для каждого из параметров введем функцию схожести  . Они могут быть бинарными (например, совпадение города объявления), могут быть дискретными (расстояние между объявлениями) и непрерывными (например, относительная разница в цене). Тогда для двух объявлений финальный счет будет выражаться формулой
. Они могут быть бинарными (например, совпадение города объявления), могут быть дискретными (расстояние между объявлениями) и непрерывными (например, относительная разница в цене). Тогда для двух объявлений финальный счет будет выражаться формулой

При помощи поискового движка можно быстро считать значение этой формулы для достаточного большого количества объявлений и ранжировать выдачу в режиме реального времени.
Этот подход весьма неплохо показывал себя и в первоначальном виде, но у него были существенные недостатки.
Проблемы подхода
Во-первых, веса изначально были выбраны экспертным образом и не подвергались сомнениям. Иногда происходили изменения в весах, но они были сделаны на основе точечного фидбека, а не на основе анализа поведения пользователей в целом.
Во-вторых, веса были захардкожены в сайте, и вносить в них изменения было очень неудобно.
Первым шагом в сторону улучшения модели рекомендаций был вынос всей логики в отдельный микросервис на Python. Этот сервис уже полностью принадлежал нашей команде рекомендаций, и мы могли проводить эксперименты достаточно часто.
Каждый эксперимент можно охарактеризовать так называемым «конфигом» — набором весов для ранкеров. Мы хотим генерировать конфиги и выбирать из них лучший на основе действий пользователей. Как можно генерировать эти конфиги?
Первый вариант, который был с самого начала, — экспертная генерация конфигов. То есть, используя знания из предметной области, мы предполагаем, что, например, при поиске автомобиля людям интересны варианты близкие по цене к просматриваемой, а не только похожие модели, которые могут стоить значительно дороже.
Второй вариант — случайные конфиги. Мы задаем какое-то распределение для каждого из параметров и затем просто берем сэмпл из этого распределения. Этот способ более быстрый, поскольку не надо думать над каждым из параметров для всех категорий.
Более сложный вариант — использовать генетические алгоритмы. Мы знаем, какие из конфигов дают нам наилучший эффект с точки зрения действий пользователей, поэтому на каждой итерации можем оставлять их и добавлять новые: случайные или экспертные.
Еще более сложный вариант, для которого требуется довольная долгая история экспериментов, — использование машинного обучения. Мы можем представить набор параметров в качестве вектора признаков, а целевую метрику — в качестве целевой переменной. Тогда мы найдем такой набор параметров, который по оценке модели будет максимизировать нашу целевую метрику.
В нашем случае мы остановились на первых двух подходах, а также генетических алгоритмах в самой простой форме: оставляем лучших, убираем худших.
Теперь мы подобрались к самой интересной части статьи: мы умеем генерировать конфиги, но как проводить эксперименты, чтобы это было быстро и эффективно?
Проведение экспериментов
Эксперимент можно провести в формате A/B/… теста. Для этого нам нужно сгенерировать N конфигов, дождаться статистически значимых результатов и, наконец, выбрать лучший конфиг. Это может занять достаточно длительное время, и на протяжении всего теста фиксированная группа пользователей может получать рекомендации плохого качества — при случайной генерации конфигов это вполне возможно. Также если нам захочется добавить какой-то новый конфиг в эксперимент, то придется перезапускать тест заново. Но нам хочется проводить эксперименты быстро, иметь возможность изменять условия эксперимента. И чтобы пользователи не страдали от заведомо плохих конфигов. В этом нам помогут многорукие бандиты.
Названия метода пошло от «одноруких бандитов» — игровых автоматов в казино с рычагом, за который можно потянуть и получить выигрыш. Представьте, что вы находитесь в зале с десятком таких автоматов, и у вас есть N бесплатных попыток для игры на любом из них. Вы, конечно же, хотите выиграть побольше денег, но заранее не знаете, какой автомат дает самый большой выигрыш. Проблема многоруких бандитов как раз заключается в том, чтобы найти самый выгодный автомат с минимальными потерями (игрой на невыгодных автоматах).
Если сформулировать это в терминах нашей задачи рекомендаций, то получится, что автоматы — это конфиги, каждая попытка — это выбор конфига для генерации рекомендаций, а выигрыш — некоторая целевая метрика, зависящая от фидбека пользователей.
Преимущество бандитов над A/B/… тестами
Их основное преимущество — они позволяют нам изменять количество трафика в зависимости от успешности того или иного конфига. Это как раз решает проблему того, что люди будут получать плохие рекомендации на протяжении всего эксперимента. Если они не будут кликать на рекомендации, то бандит достаточно быстро это поймет, и не будет выбирать этот конфиг. Кроме того, мы всегда можем добавить новый конфиг в эксперимент или просто удалить один из текущих. Все вместе дает нам гибкость при проведении экспериментов и решает проблемы подхода с A/B/… тестированием.

Бандитские стратегии
Стратегий для решения задачи о многоруких бандитах очень много. Далее я опишу несколько классов простых в реализации стратегий, которые мы пробовали применять в своей задаче. Но сначала надо понять, как сравнивать эффективность стратегий. Если мы заранее знаем, какая ручка дает максимальный выигрыш, то оптимальной стратегией будет всегда дергать эту ручку. Зафиксируем число шагов и посчитаем оптимальную награду  . Для стратегии также посчитаем награду
. Для стратегии также посчитаем награду  и введем понятие
и введем понятие  :
:

Далее стратегии можно сравнивать как раз этой величине. Отмечу, что у стратегий характер изменения может быть разный, и одна стратегия может быть лучше для маленького количества шагов, а другая — для большого.
Жадные стратегии
Как можно догадаться из названия, жадные стратегии основываются на одном простом принципе — всегда выбираем ручку, которая в среднем дает наибольшую награду. Стратегии этого класса различаются в том, как мы исследуем среду, чтобы определить эту самую ручку. Есть, например,  стратегия. У нее есть единственный параметр —
стратегия. У нее есть единственный параметр —  , определяющий вероятность, с которой мы выбираем не самую лучшую ручку, а случайную, таким образом исследуя нашу среду. Можно также уменьшать вероятность исследования со временем. Эта стратегия называется
, определяющий вероятность, с которой мы выбираем не самую лучшую ручку, а случайную, таким образом исследуя нашу среду. Можно также уменьшать вероятность исследования со временем. Эта стратегия называется  . Жадные стратегии очень просты в реализации и понятны, но не всегда эффективны.
. Жадные стратегии очень просты в реализации и понятны, но не всегда эффективны.
UCB1
Эта стратегия полностью детерминированная — ручка однозначно определяется из имеющейся на данный момент информации. Вот формула:

Часть формулы с  означает среднее j-ой ручки и отвечает за exploitation, прямо как в жадных стратегиях. Вторая часть формулы отвечает как раз за exploration,
означает среднее j-ой ручки и отвечает за exploitation, прямо как в жадных стратегиях. Вторая часть формулы отвечает как раз за exploration,  — это суммарное количество действий,
— это суммарное количество действий,  — количество действий j-ой ручки. Для этой стратегии есть доказанная оценка на . Про нее можно прочитать здесь.
— количество действий j-ой ручки. Для этой стратегии есть доказанная оценка на . Про нее можно прочитать здесь.
Сэмплирование Томпсона
В этой стратегии мы ставим каждой ручке в соответствие некоторое случайное распределение и на каждом шаге сэмплируем из этого распределения числа, выбирая ручку согласно максимуму. На основе фидбека обновляем параметры распределения так, чтобы лучшим ручкам соответствовало распределение с большим средним, и его дисперсия уменьшалась с количеством действий. Более подробно про эту стратегию можно прочитать в отличной статье.
Сравнение стратегий
Проведем симуляцию описанных выше стратегий на искусственной среде с тремя ручками, каждой из которых соответствует распределение Бернулли с параметром  соответственно. Наши стратегии:
соответственно. Наши стратегии:
- с
 ;
; - UCB1;
- сэмплирование Томпсона с
 -распределением.
-распределением.
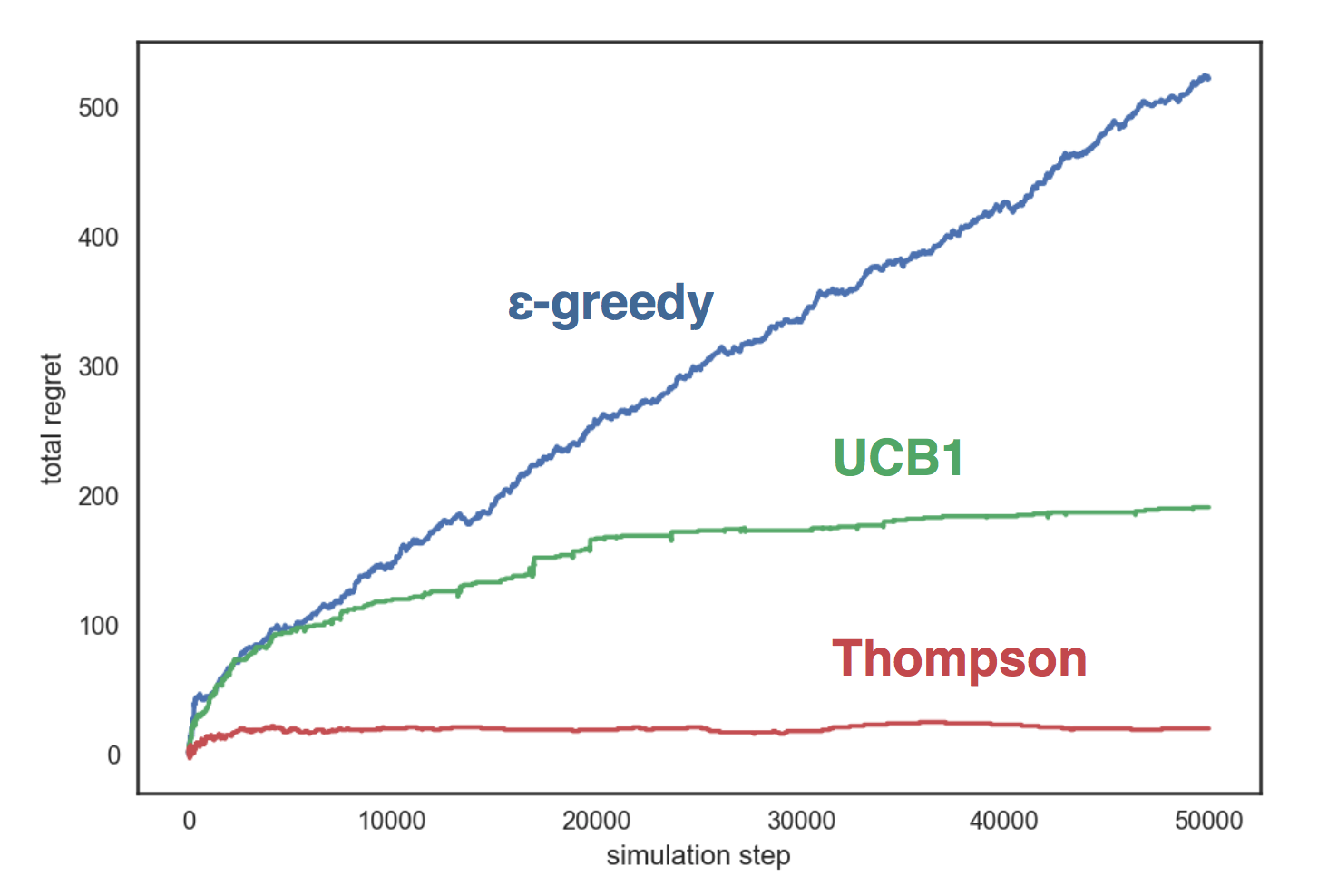
На графике видно, что у жадной стратегии растет линейно, а у двух других стратегий — логарифмически, причем сэпмлирование Томпсона показывает себя значительно лучше остальных и её почти не растет с количеством шагов.
Я познакомил вас с многорукими бандитами и теперь могу рассказать, как мы их применяли.
Многорукие бандиты в Авито
Итак, у нас есть несколько конфигов (наборов параметров), и мы хотим выбрать из них лучший при помощи многоруких бандитов. Чтобы бандиты учились, нам нужна одна важная деталь — пользовательский фидбек. При этом выбор действий, на которых мы обучаемся, должен соответствовать нашим целям — хочется, чтобы при помощи более качественных рекомендаций пользователи совершали больше сделок.
Выбираем целевые действия
Первый подход к выбору целевых действий был достаточно прост и наивен. В качестве целевой метрики мы выбрали количество просмотров, и бандиты хорошо научились оптимизировать эту метрику. Но возникла проблема: больше просмотров — не всегда хорошо. Например, в категории «Авто» нам удалось увеличить количество просмотров на 15%, но при этом количество запросов контакта наоборот упало примерно на такую же величину. При более детальном рассмотрении оказалось, что бандиты выбирали ручку, в которой был выключен фильтр по региону. Поэтому в блоке показывались объявления со всей России, где выбор похожих объявлений, естественно, больше. Это и вызывало увеличение количества просмотров: внешне рекомендации казались более качественными, но при заходе на карточку товара люди понимали, что машина очень далеко от них, и не совершали запрос контакта.
Второй подход — обучаться на конверсии из просмотра блока в запрос контакта. Этот подход казался лучше предыдущего хотя бы потому, что эта метрика почти напрямую отвечает за качество рекомендаций. Но появилась другая проблема — суточная сезонность. В зависимости от времени суток значения конверсии могут отличаться в четыре (!) раза (это зачастую больше, чем эффект от более хорошего конфига), и ручка, которой повезло быть выбранной в первый промежуток с высокой конверсией, продолжала выбираться чаще остальных.
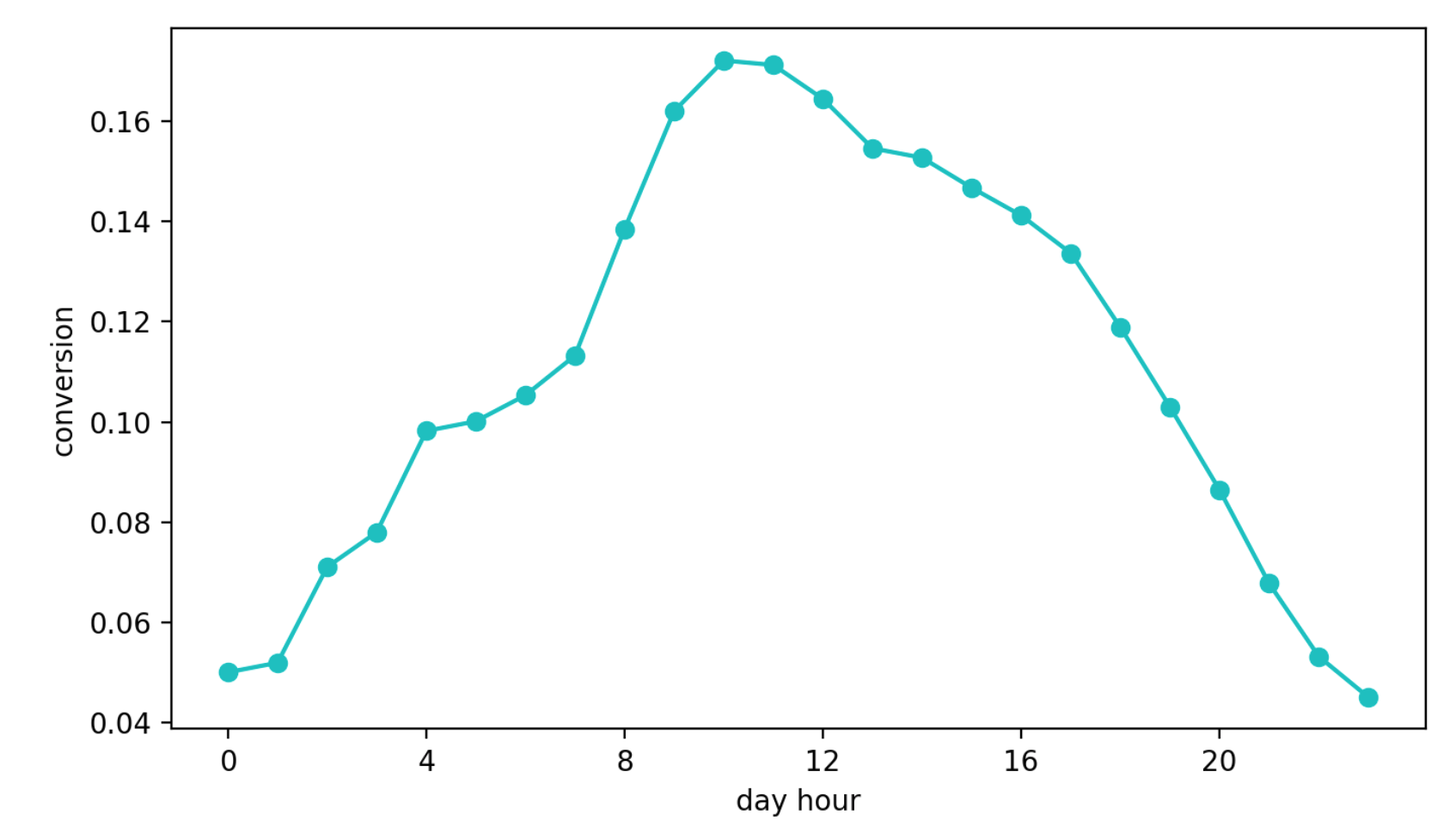
Суточная динамика конверсии (значения по оси Y изменены)
Наконец, третий подход. Его мы используем сейчас. Выделяем референсную группу, которая всегда получает рекомендации по одинаковому алгоритму и не подвержена влиянию бандитов. Далее мы смотрим абсолютное количество контактов в нашей целевой группе и референсной. Их отношение не подвержено сезонности, так как мы выделяем референсную группу случайно, и этот подход удобно ложится на сэмплирование Томпсона.
Наша стратегия
Выделяем референсную и целевую группы, как описано выше. Затем инициализируем N ручек (каждая из них соответствует конфигу) распределением 
На каждом шаге:
- сэмплируем для каждой ручки число из соответствующего ей распределения и выбираем ручку согласно максимуму;
- подсчитываем количество действий в группах
 и
и  за определенный квант времени (в нашем случае это 10 секунд) и обновляем параметры распределения для выбранной ручки:
за определенный квант времени (в нашем случае это 10 секунд) и обновляем параметры распределения для выбранной ручки:

При использовании такой стратегии мы оптимизируем нужную нам метрику, число запросов контакта в целевой группе и избегаем проблем, описанных мною выше. Кроме того, в глобальном A/B тесте этот подход показал наилучшие результаты.
Глобальный A/B тест был устроен следующим образом: все объявления случайно разбиваются на две группы. К объявлениям одной из них мы показываем рекомендации при помощи бандитов, а к другой — старым экспертным алгоритмом. Затем измеряем количество конверсионных запросов контакта в каждой из групп (запросов, совершенных после перехода на объявления из блока похожих). В среднем по всем категориям группа с бандитами получает примерно на 10% больше целевых действий, чем контрольная, но в некоторых категориях эта разница может достигать и 30%.
А еще созданная платформа позволяет быстро менять логику, добавляя конфиги бандитам, и валидировать гипотезы.
Если у вас есть вопросы про наш сервис рекомендаций или про многорукие бандиты, задавайте их в комментариях. С радостью отвечу.
