Мимо тёщиного дома я без метрик не хожу (обзор и видео доклада)
В этом докладе я расскажу о мониторинге — как собрать множество метрик из разных мест в одном, как разруливать права для разных частей этих метрик и как хранить большие объемы данных. А в конце рассмотрим пример выбора системы мониторинга на примере небольшого сериала о вымышленной компании, которая столкнулась с необходимостью эволюции системы мониторинга вместе с ростом их инфраструктуры.

Мониторинг и ИТ-инфраструктура — как выглядела раньше и что с ней стало сейчас
Одна из самых крутых и «старых» систем мониторинга — это Zabbix.
Я с ней познакомился около 15 лет назад, когда устроился на первое место работы. Уже тогда это было зрелое решение, первый релиз которого состоялся в 2001 году, то есть 21 год назад.
Какие основные задачи у системы мониторинга? Их две — мониторить наше приложение и мониторить инфраструктуру.
Как выглядела ИТ-инфраструктура 15–20 лет назад?

Тогда это были физические серверы, монолитные приложения, редкие релизы и сравнительно небольшое количество метрик на один проект — 10–20 тысяч. Обычно это были ОС и железа, метрики с баз данных, статус приложения (запущено или нет) и, если повезет, health check’и.
Современная инфраструктура сильно изменилась.

Теперь все приложения размещены в облаках, монолитные приложения разбиты на микросервисы, появился Kubernetes, количество релизов выросло до нескольких раз в неделю (есть компании, у которых это даже 100 раз в неделю), теперь нам стали важны «бизнес-метрики». Все это привело к тому, что количество метрик выросло до 10000–50000 метрик с одного хоста! Да, не с одного проекта, а именно с одного хоста.
Облака, Kubernetes и частые релизы привели к тому, что инфраструктура стала динамичной, что еще больше увеличивает количество метрик. Это в свою очередь привело к тому, что старые подходы к сбору метрик оказались нерабочими, и нам потребовалась новая система сбора метрик.

В современных условиях хотелось бы, чтобы система мониторинга умела следующие вещи:
Сама находить источники новых метрик. Если нам придется ручками заводить в нее каждый новый Под в кластере, то такая система просто не будет работать.
Собирать «бизнес метрики» как по мановению волшебной палочки.
Выполнять агрегацию данных. Так как их слишком много, то с сырыми данными оперировать уже практически невозможно.
Обрабатывать миллионы и миллионы метрик, т.к. их просто стало больше.
С учетом всех этих требований Zabbix теперь выглядит как Nokia 3310. Есть задачи, с которыми он отлично справляется, но увидеть человека с таким телефоном сейчас, наверное, не совсем… обычно.
Кажется, что нам нужна система мониторинга, которая будет удовлетворять всем нашим потребностям. И я считаю, что такая система мониторинга — это Prometheus.
Что из себя представляет Prometheus и насколько он нам подходит
Prometheus — это приложение (система мониторинга), которая была разработана компанией Sound Cloud. Как-то раз они услышали на одной из конференций про внутреннюю систему мониторинга компании Google Borgmon, и им захотелось сделать нечто похожее, но Open Source. В результате в 2014 году состоялся первый публичный релиз Prometheus.
Это приложение, написанное на языка Gо — один бинарничек, который вы запускаете. Но внутри этого бинарного файла есть несколько условно независимых процессов.
Рассмотрим их подробнее.
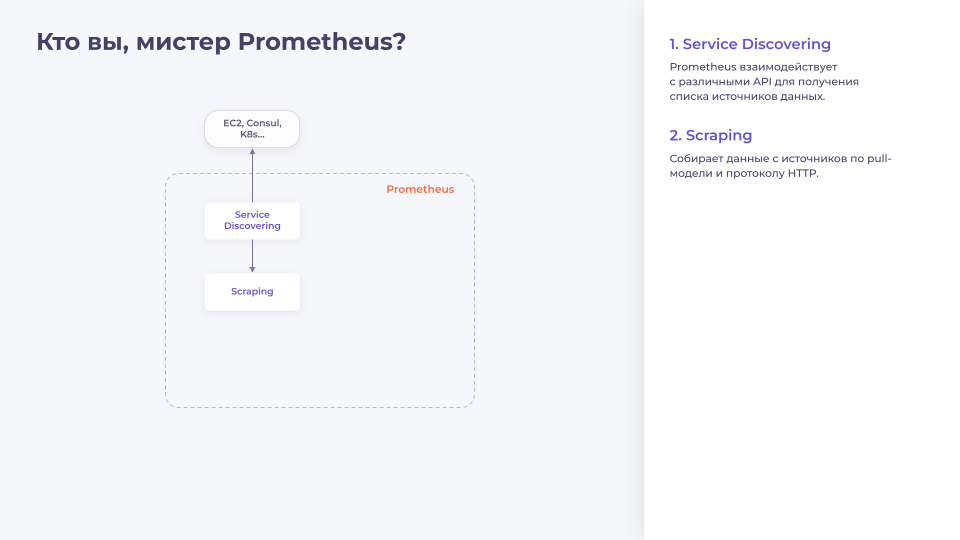
Service Discovering. Процесс, отвечающий за взаимодействие с внешними API-системами, такими как EC2, Consul, K8s и т.д. Он опрашивает эти системы и составляет список хостов, с которых он может получать метрики.

Scraping. Scraping забирает список хостов у Service Discovering и начинает собирать метрики. В Prometheus сбор метрик осуществляется по Pull-модели по протоколу HTTP. Получается, что Prometheus ходит на разные эндпоинты и говорит «Дай мне метрики!», а приложение ему отвечает «Держи!» и возвращает ему страничку, на которой plain text’ом описаны метрики и их текущее значение.
Откуда Prometheus может собирать метрики?
Есть целая группа приложений, которые называются «exporter». Это приложение, которое умеет доставать метрики из разных источников, таких как базы данных или операционная система, и отдавать их в понятном для Prometheus виде.
А также существует множество библиотек для всех возможных фреймворков, которые позволяют очень быстро доставать те самые «бизнес-метрики» из приложений.

Мы собрали метрики и теперь хотим их сохранить. Для этого в Prometheus есть своя собственная база данных Time Series Database (TSDB).

После того как мы сохранили метрики, нам захочется посмотреть на них. Для этого в Prometheus есть свой собственный UI. Но он очень ограничен по функциональности: в нем нельзя сохранять графики, у него есть только один тип графиков (график) и т.д. Поэтому им никто особо не пользуется, а используют Grafana.
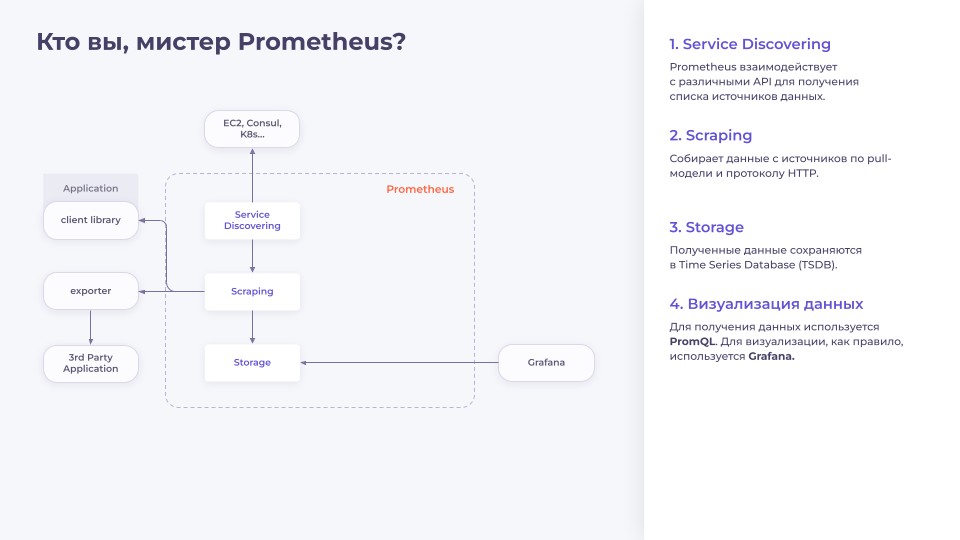
Для извлечения данных из Prometheus используется свой собственный язык запросов — PromQL, который в частности позволяет производить различные агрегации данных. Это могут быть простые операции, такие как сложение или вычитание нескольких метрик, так и достаточно сложные — перцентили, квантили, синусоиды, косинусоиды и вообще все, на что может хватить фантазии и еще немного сверху.
Помимо этого в Prometheus есть Prometheus Rules. Это еще один процесс, который позволяет делать две простые штуки: описать запрос и результат этого запроса сохранить в виде новой метрики.
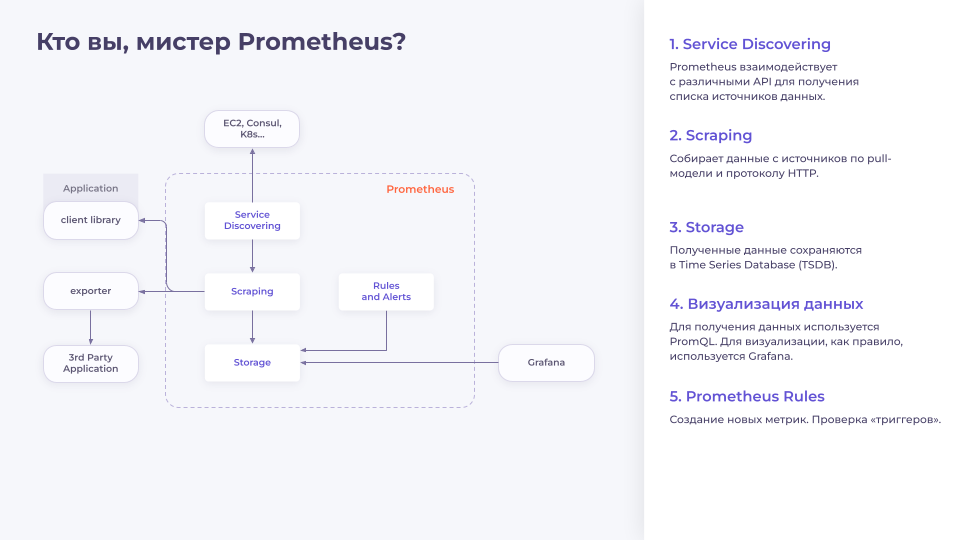
По сути там внутри есть простеньки cron, который каждые N секунд или минут выполняет запрос, а результат сохраняет как новую метрику. Это бывает очень удобно, когда у вас есть большие нагруженные дашборды со сложными вычислениями, и можно доставать сразу подсчитанные метрики, выполняя запросы. Это позволит ускорить отображение и ощутимо сэкономить на ресурсах.
Также PromQL позволяет описывать алерты (триггеры). В нем можно описать PromQL выражение и задать threshold (порог срабатывания), при пересечении которого сработает триггер, и уведомление отправляется. При этом Prometheus не шлет уведомления в каналы мессенджера или на емейл, он просто выполняет push-запрос к какой-то внешней системе.
В базовой системе такой системой является Alertmanager.

Он производит предобработку алертов, в которой можно строить достаточно сложный пайплайны, позволяющие группировать алерты, заглушить ненужное, маршрутизировать их и так далее. И уже после этого доставлять их по соответствующим каналам.
Как устроена TSDB
На мой взгляд, одним из самых важных элементов любой системы мониторинга является база данных. Если она медленная, неэффективная и ненадежная, то и вся система будет такой же. Давайте разберемся, как работает база данных в Prometheus, и насколько он подходит для нашей задачи.
Давайте начнем с простого абстрактного примера: у нас есть градусник, с которого мы каждый 60 секунд собираем данные. В данные входят текущее значение температуры и timestamp (временная метка, когда были получены эти данные).

Данные имеют определённые форматы. Для обоих параметров это float64. Суммарный объем данных будет 16 байт — по 8 на каждый параметр.

Теперь полученные 16 байт данных записываются в файл.
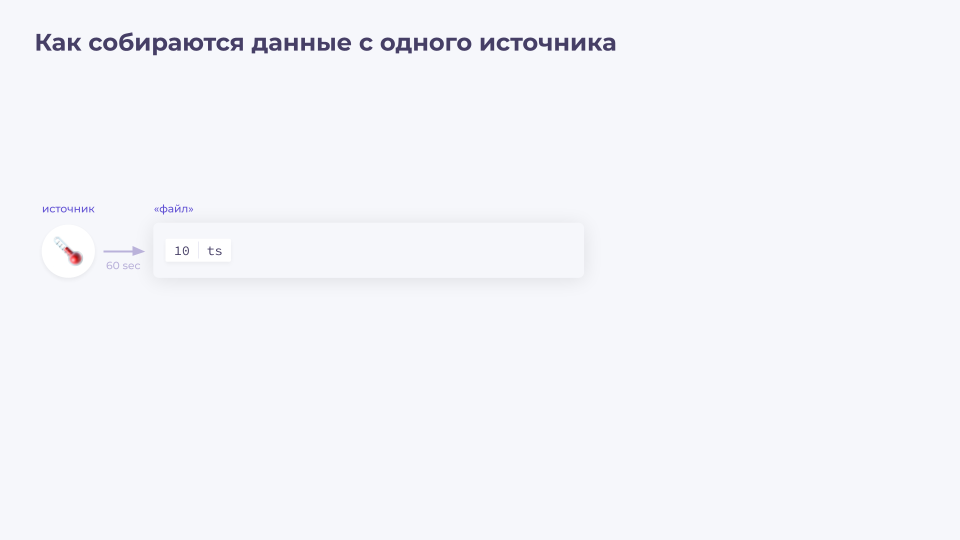
После записи приходит минута, и нам приходят следующие данные, которые мы также записываем в файл.

Через какое-то время у нас собираются данные за целый час, и теперь нам нужно вывести эти данные на график, если мы хотим их посмотреть. Мы читаем файл (либо его часть), содержащий нужные нам данные, и отображаем их на графике — по оси Х временные метки, по Y — значения температуры.

Все выглядит простым, но становится гораздо интереснее, если источников данных у нас не один, а, допустим, миллион. Как поступить в таком случае?
Попробуем решить проблему «в лоб» — мы убедились, что запись данных в один файл работает хорошо, поэтому давайте писать данные от каждого источника в свой отдельный файл. Итого у нас получится миллион файлов.

Если мы захотим посмотреть данные от одного из источников, то здесь тоже все просто: берем нужный нам файл, читаем данные и отображаем их на графике.

Кажется, что этот вариант нам отлично подходит, и в Prometheus первой версии использовалась примерно такая же схема.
Но есть нюансы — куда же без них?
У нас есть миллион источников, и нам нужно раз в минуту записать в миллион файлов миллион значений. Это требует миллиона input-операций в течение одной минуты, то есть около 16500 IOPS.
Это количество не выглядит огромным, с ним справится любой современный SSD-накопитель. Но давайте копнем еще глубже!
Как мы помним, данные от одного источника у нас занимают 16 байт. Если посчитать, то при 16500 IOPS у нас получится примерно 22 Гб данных в день. Это число тоже не кажется большим. Копнем еще глубже…

Что нужно, чтобы записать 16 байт на SSD? Кажется, просто взять и записать 16 байт. Но нет, современные SSD пишут данные блоками. Как правило, это блоки по 16 Кб (могут быть и по 32 Кб, но сути это не меняет). Для того чтобы записать 16 байт в SSD нам нужно прочитать 16 Кб, изменить в них 16 байт и затем записать обратно 16Кб.
С учетом этого пересчитаем объем данных, и получим уже не 22 Гб, а 22 Тб в день.

Если каждый день перезаписывать на SSD по 22 Тб, то это быстро приведет к тому, что диск умрет, т.к. все SSD имеют определенное допустимое количество циклов перезаписи.
И это только при миллионе источников. А что, если их будет 10 миллионов? 220 Тб в день, и SSD умрет еще быстрее.
Если, кажется, что миллион метрик — это много, то на самом деле нет. Пустой кластер Kubernetes выдает где-то 200–300 тысяч метрик. А если добавить туда приложения и начать скейлить кластер… В большом кластере количество метрик может достигать и 10–15 миллионов. Плюс они собираются намного чаще, чем раз в минуту.
Все это делает такой вариант сбора нерабочим.
Второй вариант — писать все данные в один файл.

При этом данные пишутся блоками в один файл, поэтому проблемы с производительностью и умиранием SSD у нас нет. Через какое-то время мы дописываем еще данные, затем еще… и в итоге получаем набор данных в одном файле.

При этом получается, что при миллионе записей в минуту мы получим около 15 Мб данных суммарно, и всего 23 Гб данных в день.

Теперь встает вопрос — как отобразить данные из этого файла на графике.
Для этого нам нужно просканировать весь файл, найти в нем нужные точки и затем отобразить их на графике.

Такой метод более или менее работает на файлах в 23 Гб, но если источников будет не миллион, а 10 миллионов, то файл уже будет 230 Гб. А если мы хотим посмотреть данные не за сутки, а за месяц — это будет еще больший объем.
Такой подход имеет очевидные проблемы с масштабированием и производительностью. И это Проблема.
Заключается она в том, что данные мы всегда читаем горизонтально: нам нужны последовательные данные от какого-либо источника;, а пишем — вертикально: нам приходят срезы сразу от большого количества источников данных.

Как решать эту проблему? Мы уже знаем, что можно записывать данные от всех источников в один файл. Но еще мы можем записывать их в оперативную память (RAM), но уже сгруппировав по временным рядам.

Оперативная память рассчитана на существенное больше количество циклов перезаписи, а также она «Random Access Memory», и запись в произвольные места там происходит существенно быстрее. При этом хранение данных в ней не предусмотрено — RAM штука ненадежная, после перезагрузки она может быть очищена и так далее. Поэтому данные все равно нужно хранить в постоянной памяти, откуда подгружать их в случае необходимости в RAM.
Получается следующая схема: полученные данные мы пишем в оперативную память, структурируем там, формируем блок (например, за час) и сохраняем его на SSD.

После этого данные из оперативной памяти можно удалять. Повторяем этот цикл мы n-ное количество раз.
Спустя какое-то время у нас получается множество блоков с информацией, сохраненных на SSD.

Допустим, у нас за месяц получилось 720 файлов. И мы хотим посмотреть данные с метриками по CPU на узле. По CPU у нас не одна метрика, а целых пять: System, user, iowait и т.д. И при запросе такого количества метрик из разных блоков быстродействие системы снова может оказаться недостаточным.
Для решения этой проблемы можно, например, померджить часовые блоки в блоки по 4 часа.

Затем в блоки по 16 часов…

… и так далее.
Глубина такого слияния очень сильно зависит от реализации TSDB. Они бывают разные: как на приведенной выше схеме, формирующие одноуровневые блоки в памяти с последующей записью на SSD или даже с еще более глубоким уровнем слияния.
Такой подход полностью решает проблему горизонтального чтения и вертикальной записи.

Но есть еще один важный момент, который я целенаправленно опустил в начале. Как понять — к какой из миллиона датчиков относятся те или иные данные?

Как правило, в TSDB для этого используются лейблсеты (LableSet). Это набор пар «ключ — значение».

Для каждого датчика есть свои лейблсеты, позволяющие уникально идентифицировать этот датчик.

При этом хранить их рядом с каждым временным рядом значений очень неэффективно и приводит к существенному расходованию ресурсов. Поэтому с каждым лейблсетом ассоциируется соответствующий ID, который затем присваивается временному ряду.

Как это будет выглядеть в нашей схеме?
У нас есть все тот же миллион датчиков, у каждого датчика есть свой лейблсет, а в памяти его специальный массив. После поступления данных мы присваиваем каждому лейблсету ID, после чего его записываем на диск и записываем данные от этого источника, добавляя к нему соответствующий ID. И затем то же самое записываем в память.

Затем все то же самое мы проделываем для остальных источников.

Список источников, как правило, не очень сильно меняется, поэтому выполнять постоянно маппинг данных нет необходимости. Мы можем просто продолжить дописывать новые данные.
После окончания формирования блока данных мы записываем его на диск уже вместе с этим маппингом.
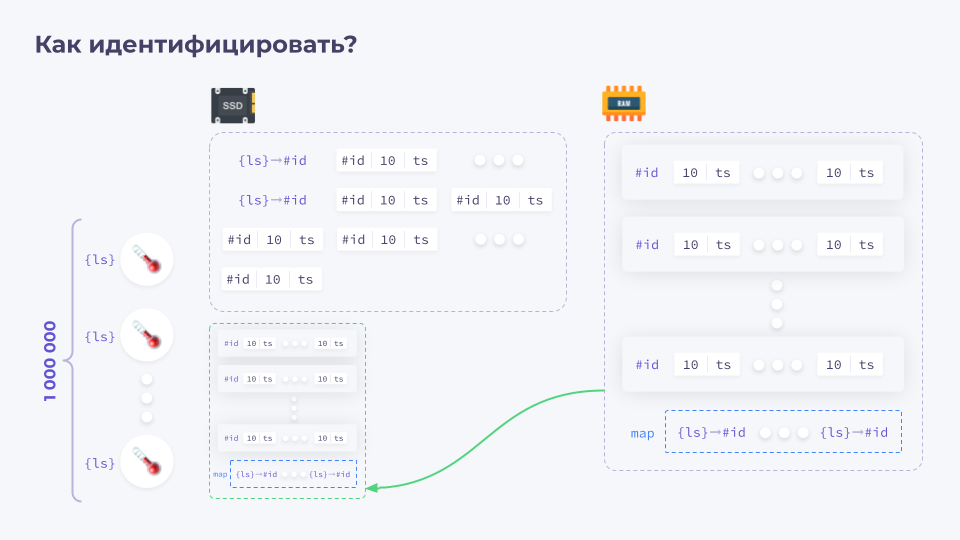
При этом в зависимости от реализации TSDB есть разные варианты: где-то используется сквозная нумерация лейблсетов независимо от блока, а где-то для каждого блока ID лейблсетов уникальные.
Как теперь построить график по данным?
Нам приходит запрос на отображение данных по лейблсету. Первое, что нам нужно сделать — определить к какому ID относится данный лейблсет каждого блока.

Затем мы находим необходимые нам ID в блоках.

… и получаем по ним данные. Затем по этим данных мы можем сформировать график.

Подведем промежуточный итог:
мы решили проблему горизонтального чтения и вертикальной записи, использовав разворот на 90 градусов;
для идентификации источников мы используем лейблсеты
у нас есть журнал, в который мы пишем данные последовательно;
в памяти хранится активный блок с данными, разгруппированный по временным рядам;
завершенные блоки записываются на диск.
Такой подход называется Log Structured Merge Tree (LSMT).

Именно этот подход используется в большинстве современных систем мониторинга:

Причем у influxdb и VictoriaMetrics это прямо написано в документации — «мы используем TSDB на основе LSMT». У Prometheus это не указано, но большая часть того, что я вам рассказывал, была именно про него.
Подходит ли Prometheus под требования, озвученные в самом начале?
В нем есть Service Discovery, который позволяет подстраиваться под динамичность нашей инфраструктуры.
В нем есть инструменты для сбора метрик с приложений
В нем собственный язык запросов, который позволяет быстро и удобно агрегировать метрики.
В нем есть база данных, заточенная под хранение метрик.
Также у него сейчас огромное комьюнити, что позволяет довольно быстро находить ответы на любые вопросы.
Для него существует огромное количество экспортеров, которые позволяют быстро начать мониторить все что угодно — даже воду в бутылке, если это требуется.
Получается, что Prometheus соответствует всем требованиям, предъявляемым к современной системе мониторинга, и он отлично подходит на главную роль.
А теперь давайте посмотрим наш сериальчик.
Сериал о компания ПРОМЕТЕЙ
Серия 1

Компания ПРОМЕТЕЙ — это небольшой стартап, у которого еще нет внешних клиентов. У них есть классная идея, и сейчас они ищут инвесторов, клиентов и так далее.
Сейчас в ней есть три человека: два разработчика и СТО.

Основная задача Василия — искать инвесторов. Он ходит по разным людям, показывает свою идею и рассказывает о проекте. И вот как-то раз презентация прошла не очень успешно: приложение тормозило и даже один раз упало. После презентации Вася пришел к разработчикам и спросил: «Ребята, а что это было? Давайте попробуем разобраться».

Разработчик Петя ответил, что у них нет никакой системы мониторинга, и поэтому он не знает, что произошло. И тут появляется первая задача для компании: сбор метрик.
В случае с Prometheus схема будет выглядеть очень просто.

Есть Prometheus, который собирает какие-то данные, и к нему подключена Grafana. У Васи возникает логичный вопрос — что будет, если Prometheus упадет?

Очевидно, что в такой схеме не будет ничего — нет Prometheus, нет данных. Т.к. он работает по Pull-модели, в случае если он не работал, то и метрики собирать будет некому.

И это один из первых минусов такой схемы — нет отказоустойчивости.
Второй — Prometheus сильно ограничен теми ресурсами, которые есть на машине, т.к. он не приспособлен к масштабированию.
Серия 2

Компания подросла, ей уже больше года, у нее появились внешние клиенты, инвесторы, комьюнити. Штат компании также увеличился, инфраструктура тоже подросла.

И вот как-то раз в пятницу в половину второго ночи (как это часто бывает) Вася получает сообщение от клиента, что что-то не работает.

Он звонит Пете и просит посмотреть, что случилось. Ведь это важно — страдают клиенты. Петя в ответ говорит, что у них один Prometheus, виртуалка с ним упала, и он не знает, что происходит.
И тут появляется следующая задача для компании — отказоустойчивость.
Как можно решить эту задачу? Поставить второй Prometheus!

Поскольку он работает по Pull-модели, мы просто копируем конфигурационные файлы из одного в другой, и они оба начинают собирать данные из одних и тех же источников данных.
Давайте рассмотрим, как это работает, чуть подробнее.

У нас есть один Prometheus, у нас есть второй Prometheus, перед ними поднят Load Balancer, который балансирует между ними трафик.

Если запрос приходит на первый Prometheus — данные отдаются с него. Если на второй — то со второго.
Но что будет, если один Prometheus упадет?

На первый взгляд все должно быть хорошо. LB выкинет его из балансировки, запросы на него перестанут приходить, но второй продолжит работать, собирать метрики и отображать графики. И вроде все хорошо, но затем первый Prometheus запускается, и тут возникает проблема в той самой Pull-модели, поскольку в данных появляется пропуск.

Если при этом запрос будет направлен на Prometheus, который временно не работал, то мы увидим дырку на графике.

Что с этим можно сделать?
Первый и самый просто вариант — сделать в Grafana два дополнительных data source, которые в случае дырок на графиках позволяют нам посмотреть данные в каком-то конкретном Prometheus, в котором этих дырок нет.

Мы приходим в рабочий Prometheus, получаем от него данные и живем счастливо. Но на этом вопросы не заканчиваются.

В этом случае они будут последовательно перезапускаться, и мы увидим примерно следующую картину, когда в одном Prometheus есть часть данные, в другом Prometheus есть другая часть данных, и куда бы ни пришли, мы в любом случае увидим дырки на графиках.

На самом деле такая схема с двумя Data Source в большинстве случаев бывает достаточна. Но если ее не хватает, то есть решение!

Суть его заключается в том, что мы ставим Proxy перед Prometheus.

Это не какой-то обычный прокси вроде nginx, это специализированный прокси для Prometheus.
В этом случае, когда прокси получает запрос, он получает данные со всех Prometheus, производит мердж этих данных, уже на них он выполняет запрос PromQL и возвращает результат.

Какие минусы у такого решения? От разработчиков Prometheus нет никаких решений по реализации таких прокси, есть только сторонние разработки, и мы становимся зависимыми от них, т.к. нам необходимо, чтобы версия PromQL соответствовала тому, какие у нас Prometheus. Это не всегда бывает так.
Мы тестировали разные версии — в целом есть рабочие решения, но в продакшене мы это не используем, поэтому какое-то конкретное решение я не могу вам порекомендовать.
Также у Prometheus есть еще один нюанс. Изначально он не задумывался как система, которая может хранить данные долго.

Об этом написано в его документации.
То есть 14 дней, 30 дней — все отлично хранится. Но если нам необходимо хранить данные 5 лет, то это уже проблема.
Серия 3

Компания превратилась в большую корпорацию, количество сотрудников тоже увеличилось — появилась службе технической поддержки, инфраструктура увеличилась, поэтому появилась команда эксплуатации, плюс появились несколько команд разработки.

Изначально у них был один кластер, и все было хорошо. Теперь кластеров стало больше, они были в разных датацентрах, но приведенная выше схема мониторинга все еще работала.

И вот как-то раз Вася получает эскалацию о том, что часть сервисов не работает. И он, как хороший СТО, начинает разбираться.

Команда эксплуатации объясняет, что у них 10 датацентров, они бегают между разными Grafana’ми и пытаются разобраться, что происходит.
И тут выясняется, что такая схема с локальными Prometheus’ами уже не работает, если кластеров много, и расположены они в разных местах.
Немного можно исправить ситуацию, поставив одну общую Grafana, которая будет ходить сразу во все датацентры, но это все равно не даст возможность увидеть картину целиком.

И теперь становится актуальной централизация метрик — нам нужно собрать метрики от разных источников в одном месте.
Такими решениям являются Thanos, Cortex или Mimir. Это целая группа приложений, но суть у них плюс-минус одна и та же: у нас есть какая-то «коробка», куда мы можем писать из наших Prometheus’ов, и к ней мы можем подключить Grafana.
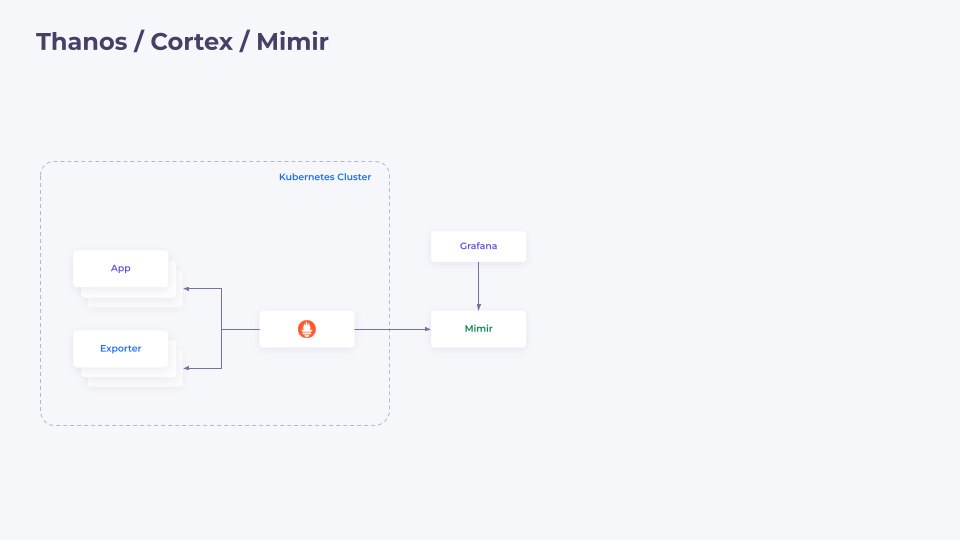
Логичный вопрос от СТО, которые часто хотят сэкономить деньги —, а можем ли мы теперь отказаться от локальных Prometheus, установленных в кластере?

Да, но нет.
Можно заменить Prometheus на несколько маленьких приложений, таких как Prometheus Agent, VM Agent и Grafana Agent. Это такие маленькие приложения, которые умеют собирать метрики и отправлять их во внешнее хранилище.

Но здесь есть некоторые нюансы.
Поскольку у нас пропадает штука, которая отвечает на запросы, у нас не будет работать в кластере HPA/VPA. Также могут быть проблемы с предпосчитанными метриками, поскольку у нас нет штуки, которая это делает. И также могут быть проблемы с алертами — если порвалась связь между нашим Prometheus и централизованным хранилищем, то максимум, что мы получим, это уведомление о том, что порвалась связь, без конкретики.
Как вариант решения — можно использовать Prometheus с retention 1d. Это позволит сократить размеры Prometheus, он не будет занимать столько ресурсов, но все три описанных проблемы не будут нас беспокоить.
В итоге у нас получается следующая схема.

У нас есть некоторое количество кластеров, которые пишут метрики в централизованное хранилище метрик, и есть Grafana, в которой можно посмотреть все метрики.
Что представляет из себя централизованное хранилище метрик?
Рассмотрим это на примере Mimir’а.
Основные проблемы Prometheus заключаются в том, что это, монолитное приложение. Чтобы решить эти проблемы разработчики Mimir’а сделали одну простую штуку — они взяли Prometheus и разделили его на отдельные микросервисы. Буквально — порезали его на кусочки, и получился Mimir, который является микросервисным вариантом Prometheus.
Также они добавили разделение данных между различными тенантами, что позволяет хранить данные от различных кластеров или датацентров отдельно друг от друга. Но при этом возможно производить мультитенантные запросы, извлекая все данные.
Как это работает?
Схема централизованного хранилища выглядит так:

На первый взгляд кажется сложным, но давайте рассмотрим по частям.
Запись метрик
Все метрики изначально поступают в Distributor. Основная его задача — проверить, что к нам пришли правильные метрики, и выбрать Ingester, в который отправить их дальше.
Затем данные поступают в Ingester, который формирует у себя в памяти блоки данных (те самые блоки, о которые мы говорили ранее, и фактически это Prometheus блоки). После того как блок сформирован, он финализируется, сохраняется на диск и отправляется в S3-хранилище для долгосрочного размещения.
После того как метрики записаны в S3, в работу вступает Compactor, который оптимизирует хранение блоков (делает тот самый мердж блоков из часовых в двухчасовые и так далее).

Чтение метрик
Здесь все немного посложнее.
Все запросы изначально поступают в Query Frontend, который:
проверяет кеш на наличие готового ответа на полученные запрос и возвращает ответ, если данные найдены;
если данные не найдены, запрос передается дальше в Querier.
Querier забирает запрос от Query Frontend и начинает подготавливать данные, которые необходимы для выполнения этого запроса. Для этого он запрашивает их сначала у Ingester, а затем у Store Gateway, являющийся интерфейсом доступа к данным в S3.

Для чего нужен Store Gateway и почему бы сразу не пойти за метриками в S3? Разберем чуть подробнее.
Store Gateway
Блоки данных хранятся в S3. При запуске Store Gateway выкачивает части блоков, содержащие маппинги лейблсетов в ID.

Как правило это 5–10% от общего объема данных.
После этого, когда приходит запрос на получение данных, Store Gateway, имея локальные данные о соответствии лейблесов и ID, выкачивает из S3 только конкретные данные из конкретных блоков.

Далее он собирает нужные метрики воедино и отдает их в Querier.

Затем данные приходят к Query Frontend, который производить вычисления по PromQL и отдает их пользователю.
А для чего вообще сделали такую сложную схему?
Для этого есть несколько причин:
Надежность. Все компоненты Mimir масштабируются независимо друг от друга. Это позволяет обеспечить отказоустойчивость системы и подстраиваться под тот профиль нагрузок, который нам нужен.
Все компоненты, в которые пишутся или читаются данные, поддерживают репликацию данных. Например, Distributor отправляет данные не в один, а сразу в несколько Ingester’ов — это позволяет спокойно обновлять систему или переживать падения отдельные ВМ, на которых развернута система.
Решается вопрос с масштабированием. Все компоненты поддерживают шардирование данных, и каждый из них содержить не весь комплект данных, а только одну их часть.
Оптимизация хранения благодаря Compactor’у.
Общие плюсы и минусы использования Mimir приведены на рисунке ниже:

Итоги
В качестве общего вывода можно посмотреть на небольшую табличку, на которой сведены все плюс и минусы всех описанных ранее решений, применительно к вашим задачам.

Видео и слайды
Видеозапись выступления (~50 минут):
Презентация:
P.S.
Читайте также в нашем блоге:
