Михаил Салосин. Golang Meetup. Использование Go в бэкенде приложения «Смотри+
Михаил Салосин (далее — МС): — Всем привет! Меня зовут Михаил. Я работаю бэкенд-разработчиком в компании MC2 Software, и я расскажу об использовании Go в бэкенде мобильного приложения «Смотри+».

Кто-нибудь из присутствующих любит хоккей?

Тогда это приложение для вас. Оно — для «Андроида» и iOS, служит для просмотра трансляций разных спортивных событий в онлайне и в записи. Также в приложении есть различная статистика, текстовые трансляции, таблицы по конференциям, по турнирам и прочая информация, полезная для болельщиков.
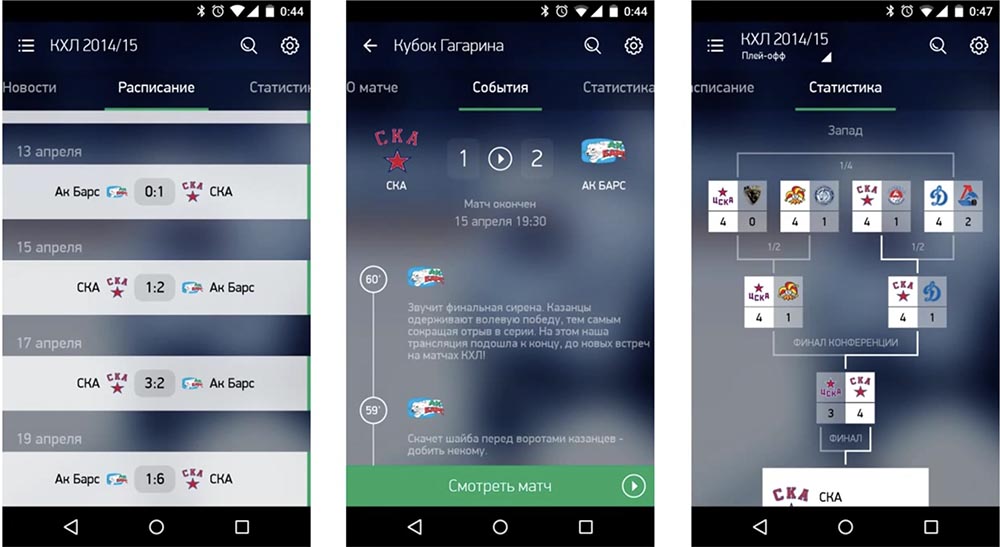
Также в приложении есть такая штука, как видеомоменты, т. е. можно посмотреть острые моменты матчей (голы, драки, буллиты и др.). Если вам не хочется смотреть всю трансляцию, можно посмотреть только самое интересное.
Что использовали в разработке?
Основная часть была написана на Go. Тот API, с которым общались мобильные клиенты, был написан на Go. Также на Go был написан сервис для отправки push-уведомлений на мобильные. Ещё нам пришлось написать своё ORM, о котором мы, возможно, когда-нибудь расскажем. Ну и написаны на Go кое-какие мелкие сервисы: ресайзинг и загрузка изображений для стороны редакторов…
В качестве базы данных мы использовали «Постгрес» (PostgreSQL). Интерфейс для редакторов был написан на Ruby on Rails с помощью гема (gem) ActiveAdmin. На «Руби» написан и импорт статистики из поставщика статистики.
Для системных тестов API мы использовали unittest «Питона» (Python). Memcached используется для троттлинга обращений API-оплаты, «Шеф» (Chef) — для контроля конфигурации, Zabbix — для сбора и мониторинга внутренних статистических данных системы. Graylog2 — для сбора логов, Slate — это документация API для клиентов.

Выбор протокола
Первая проблема, с которой мы столкнулись: нам нужно было выбрать протокол взаимодействия бэкенда с мобильными клиентами, исходя из следующих пунктов…
- Самое главное требование: данные на клиентах должны обновляться в реальном времени. То есть все, кто в данный момент смотрит трансляцию, должны получать обновления практически мгновенно.
- Для упрощения мы приняли, что данные, которые синхронизируются с клиентами, не удаляются, а скрываются с помощью специальных флагов.
- Всякие редкие запросы (вроде статистики, составов команд, статистики команд) получаются обычными GET-запросами.
- Плюс, система должна была спокойно выдержать 100 тысяч пользователей одновременно.
Исходя из этого, мы имели два варианта протокола:
- Websocket«ы. Но нам не нужны были каналы от клиента к серверу. Нам нужно было только отправлять обновления с сервера на клиент, поэтому веб-сокет — избыточный вариант.
- Server-Sent Events (SSE) подошёл в самый раз! Он достаточно простой и удовлетворяет в принципе всему, что нам нужно.
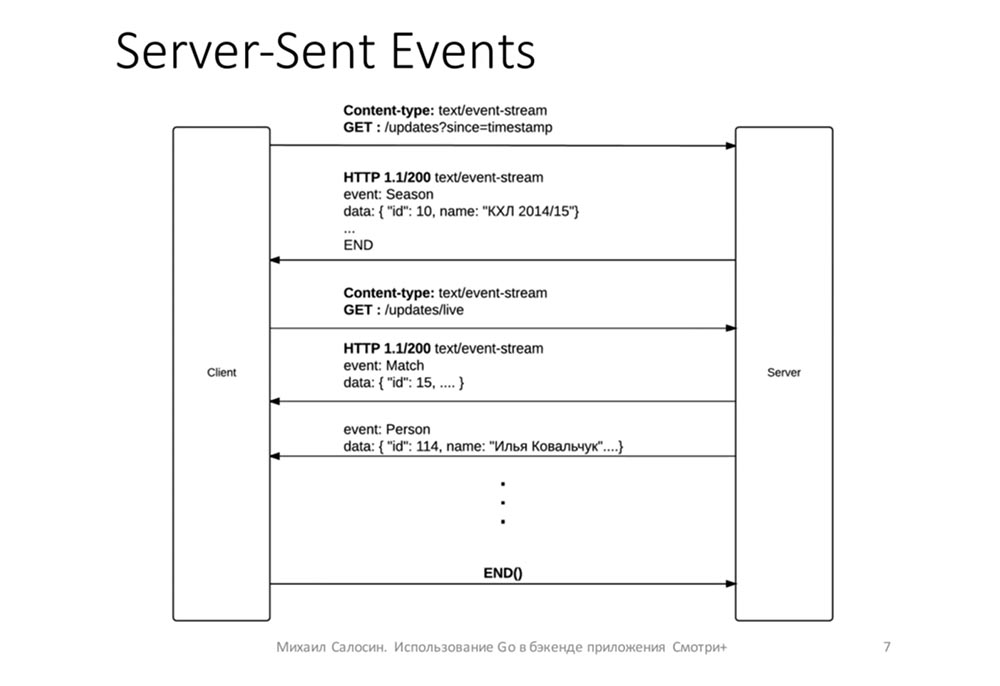
Server-Sent Events
Пару слов о том, как работает эта штука…
Она работает поверх http-соединения. Клиент отправляет запрос, на него сервер отвечает Content-Type: text/event-stream и не закрывает соединение с клиентом, а продолжает писать в соединение данные:

Данные можно отправлять в формате, согласованном с клиентами. В нашем случае мы отправляли в таком виде: в поле event отправлялось название изменившейся структуры (человек, игрок), а в поле data — JSON с новыми, изменёнными полями для игрока.
Теперь о том, как работает само взаимодействие.
- Первым делом клиент определяет, когда последний раз производилась синхронизация с сервисом: он смотрит в свою локальную БД и определяет дату последнего изменения, записанного у него.
- Он отправляет запрос с этой датой.
- В ответ мы отсылаем ему все обновления, которые произошли с этой датой.
- После этого он производит соединение с live-каналом и не закрывает до тех пор, пока ему нужны эти обновления:
Мы шлём ему список изменений: если кто-то забил гол — изменяем счёт матча, получил травму — тоже отправляется в реальном времени. Таким образом, в ленте событий матча клиенты моментально получают актуальные данные. Периодически, чтобы клиент понимал, что сервер не умер, что с ним ничего не случилось, мы отправляем раз в 15 секунд timestamp — чтобы он знал, что всё в порядке и переподключаться не нужно.
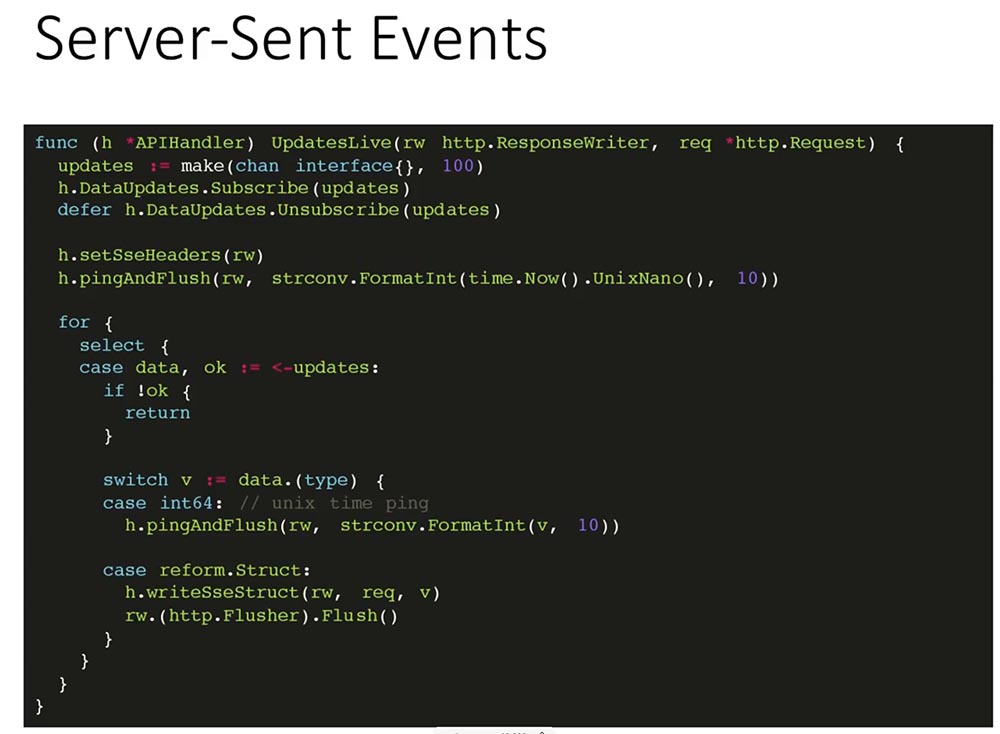
Как обслуживается live-соединение?
- В первую очередь мы создаём канал, в который будут приходить обновления с буфером.
- После этого подписываем этот канал на получение обновлений.
- Устанавливаем правильный заголовок, для того чтобы клиент знал, что всё ok.
- Отправляем первый ping. Просто записываем текущий timestamp соединения.
- После этого в цикле читаем из канала до тех пор, пока канал обновлений не закрыт. В канал периодически приходит либо текущий timestamp, либо изменения, которые мы уже записываем в открытые соединения.
Первая проблема, с которой мы столкнулись, заключалась в следующем: на каждое открытое с клиентом соединение мы создавали таймер, который тикал раз в 15 секунд — получается, если у нас было открыто 6 тысяч соединений с одной машиной (с одним API-сервером), создавалось 6 тысяч таймеров. Это приводило к тому, что машина не держала необходимой нагрузки. Проблема была не такой очевидной для нас, но нам немного помогли, и мы её устранили.
В итоге теперь у нас ping приходит из того же канала, из которого приходит update.
Соответственно, имеется всего один таймер, который тикает раз в 15 секунд.
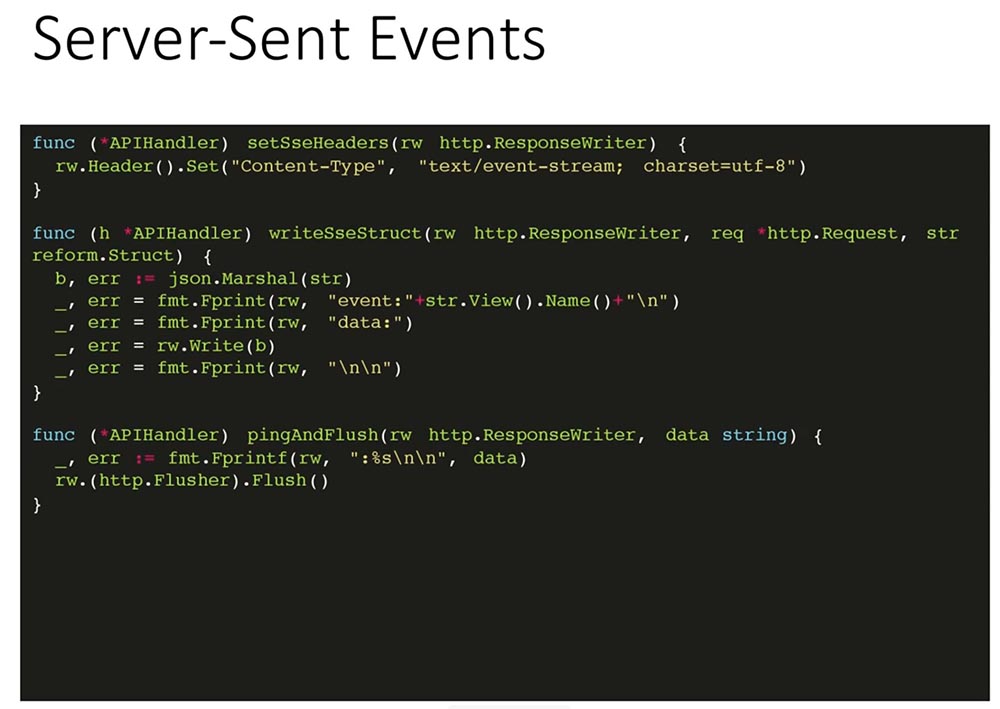
Здесь несколько вспомогательных функций — отправка заголовка, пинга и самой структуры. То есть здесь передаётся название таблицы (person, match, season) и сама информация об этой записи:
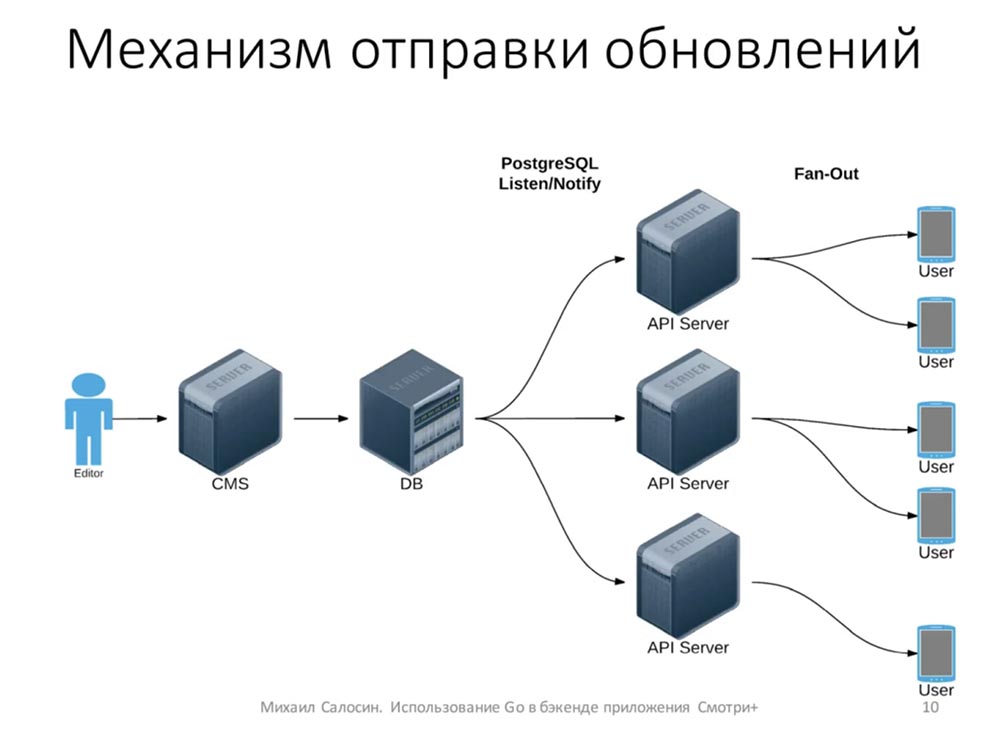
Механизм отправки обновлений
Теперь немного о том, откуда берутся изменения. У нас есть несколько человек, редакторов, которые в реальном времени смотрят трансляцию. Они создают все события: кого-то удалили, кто-то получил травму, какая-то замена…
С помощью CMS данные попадают в базу. После этого база с помощью механизма Listen/Notify уведомляет об этом API-серверы. API-серверы уже рассылают эту информацию клиентам. Таким образом, у нас по сути к базе подключено всего несколько серверов и никакой особой нагрузки на базу нет, потому что клиент никаким образом напрямую с базой не взаимодействует:
PostgreSQL: Listen/Notify
Механизм Listen/Notify в «Постгресе» позволяет уведомлять подписчиков на события о том, что изменилось какое-то событие — была создана какая-то запись в базе. Для этого мы написали простой триггер и функцию:
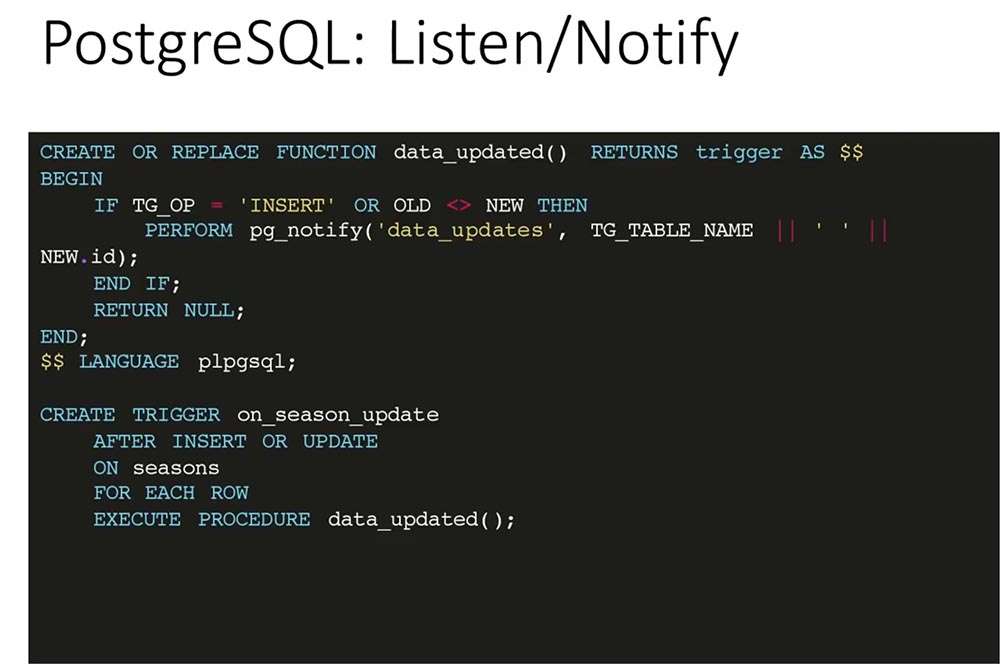
При insert«е или изменении записи мы вызываем функцию notify на канале data_updates, передаём туда название таблицы и идентификатор записи, которая была изменена или вставлена.
На все таблицы, которые должны быть синхронизированы с клиентом, мы определяем триггер, который после изменения / обновления записи вызывает функцию, указанную на слайде внизу.
Как API подписывается на эти изменения?
Создаётся механизм Fanout — он рассылает сообщения клиентом. Он собирает все каналы клиентов и рассылает обновления, которые он получил по этим каналам:
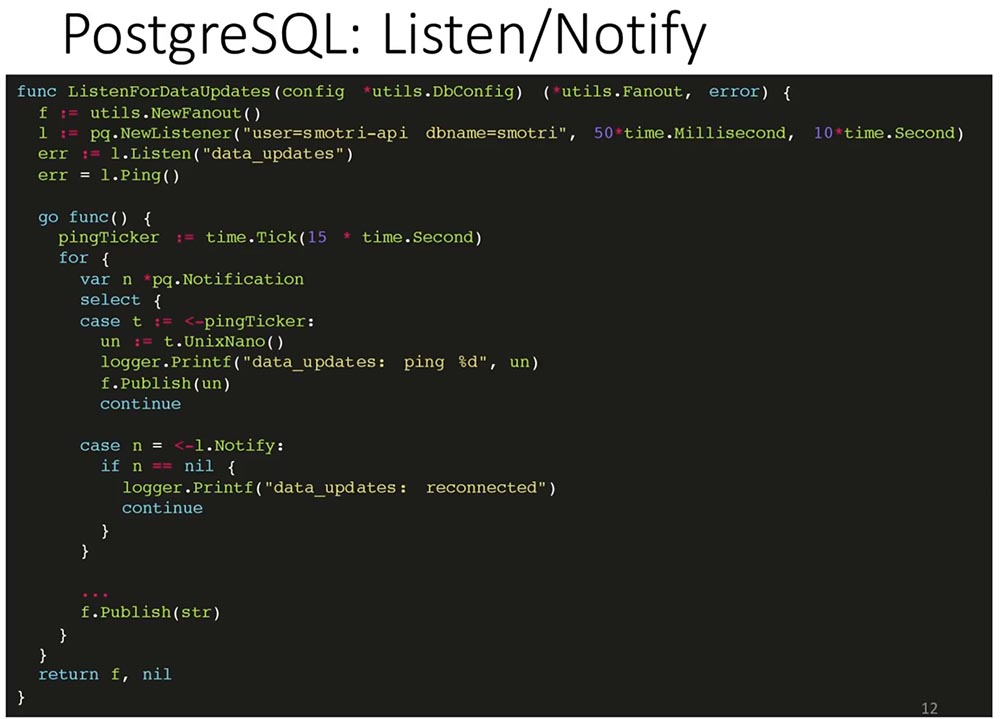
Здесь стандартная библиотека pq, которая подключается к базе и говорит о том, что хочет слушать канал (data_updates), проверяет, что соединение открыто и всё нормально. Я опускаю проверку ошибок, чтобы сэкономить место (не проверять чревато).
Далее мы асинхронно задаём Ticker, который будет отсылать ping раз в 15 секунд, и начинаем слушать канал, на который подписались. Если нам пришёл пинг, мы публикуем этот пинг. Если нам пришла какая-то запись, то мы публикуем эту запись всем подписчикам этого Fanout«a.
Как работает Fan-out?
По-русски это переводится как «разветвитель». У нас есть один объект, который регистрирует подписчиков, которые хотят получать какие-то обновления. И как только апдейт к этому объекту приходит, он раскладывает это обновление всем имеющимся у него подписчикам. Достаточно просто:
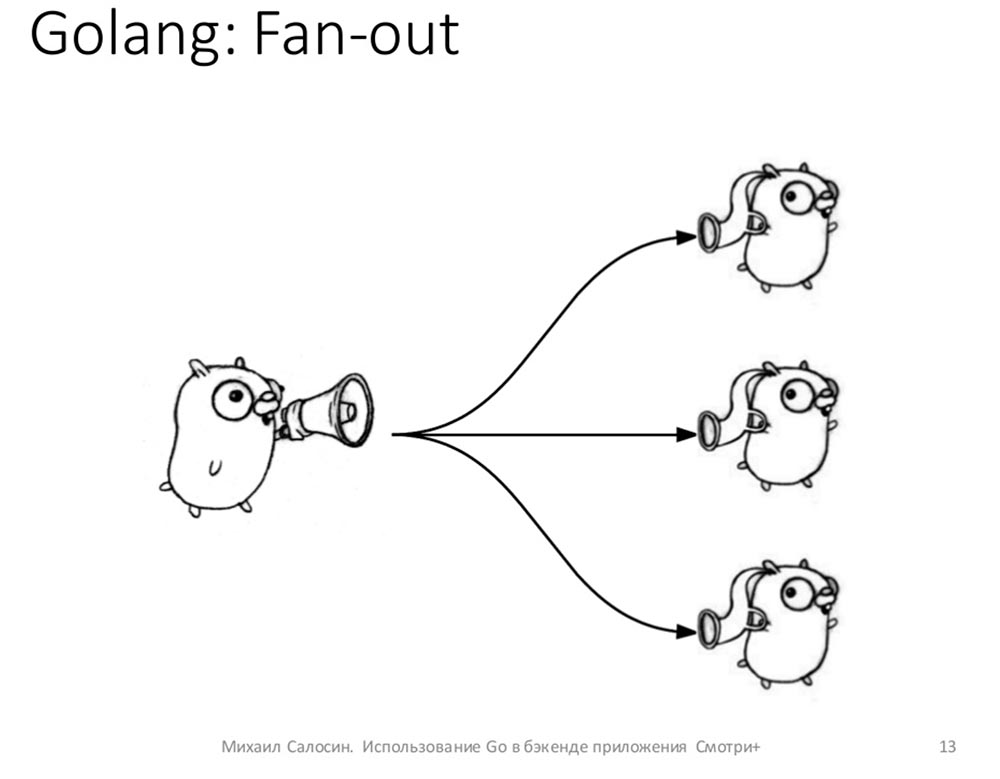
Как это реализовано на Go:
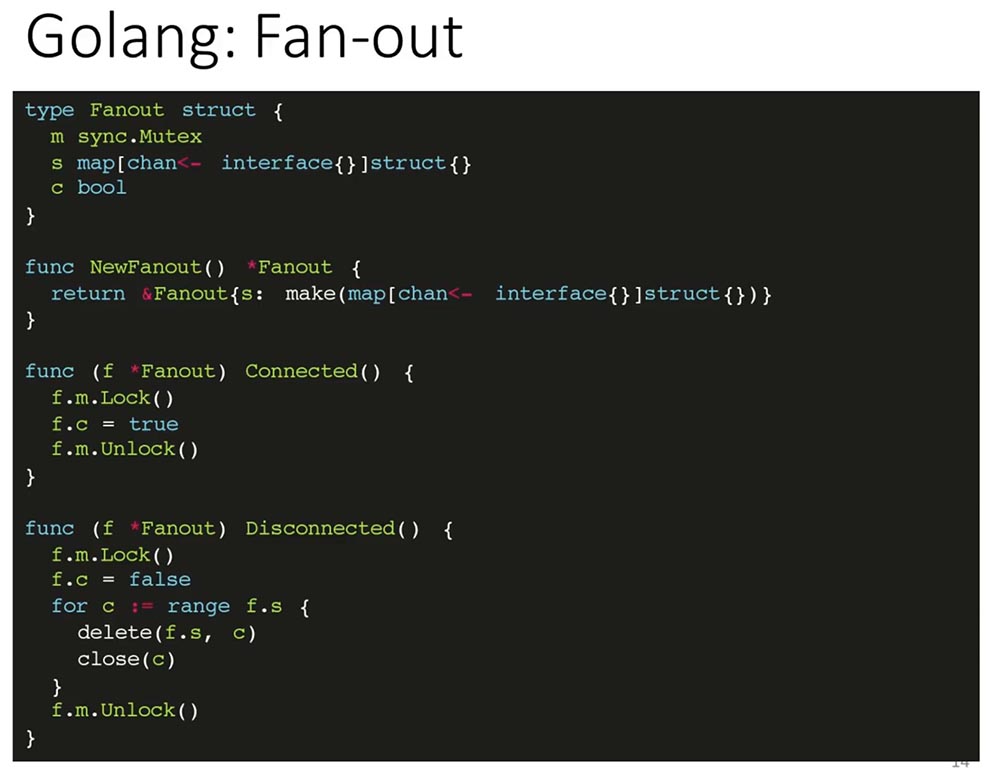
Есть структура, она синхронизируется с помощью Mutex«ов. У неё есть поле, которое сохраняет состояние подключения Fanout к базе, т. е. в данный момент он слушает и будет получать обновления, а также список всех имеющихся каналов — map, ключом, которого является канал и struct в виде значений (по сути оно не используется никак).
Два метода — Connected и Disconnected — позволяют сказать Fanout«у, что у нас есть соединение с базой, оно появилось и что соединение с базой оборвано. Во втором случае нужно всех клиентов отключить и сообщить им, что они больше не могут ничего слушать и чтобы они переподключились, поскольку соединение с ними закрылось.
Также есть метод Subscribe, который добавляет канал в «слушатели»:
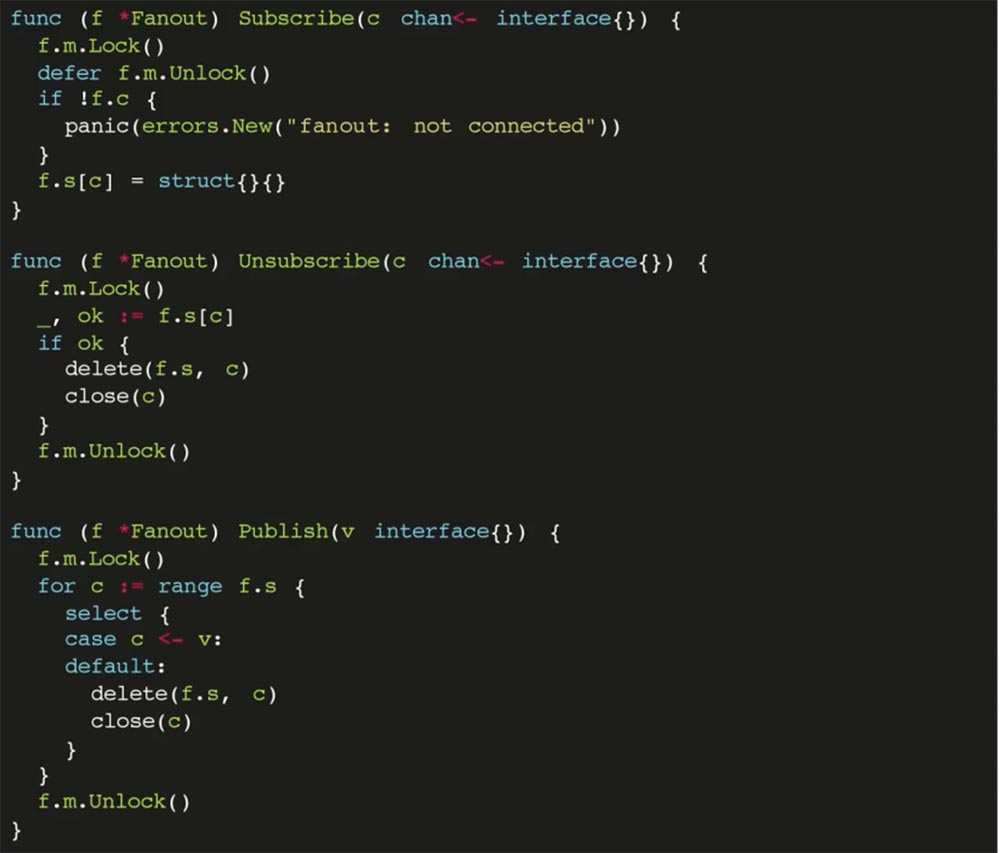
Есть метод Unsubscribe, который убирает канал из слушающих, если клиент отключился, а также метод Publish, позволяющий разослать сообщение всем подписчикам.
Вопрос: — Что по этому каналу передаётся?
МС: — Передаётся модель, которая изменилась или пинг (по сути просто число, integer).
МС: — Можно что угодно, любую структуру пересылать, опубликовать — она просто превращается в JSON и всё.
МС: — Мы получаем нотификацию из «Постгреса» — в ней содержится название таблицы и идентификатор. По названию таблицы мы получаем и идентификатору мы получаем нужную нам запись, а уже эту структуру отправляем на публикацию.
Инфраструктура
Как это выглядит с точки зрения инфраструктуры? У нас 7 железных серверов: один из них полностью выделен под базу, на остальных шести крутятся виртуалки. Имеются 6 копий API: каждая виртуалка с API крутится на отдельном железном сервере — это для надёжности.
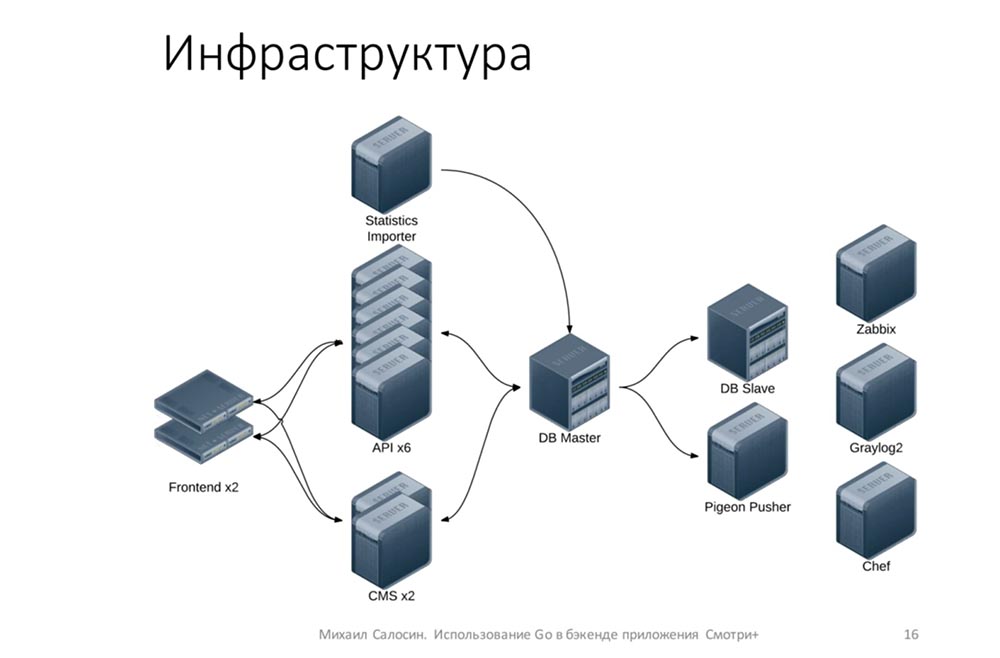
У нас есть два фронтенда, на которых установлен Keepalived для улучшения доступности, чтобы в случае чего один frontend мог заменить другой. Ещё — две копии CMS.
Также имеется импортёр статистики. Есть DB Slave, с которого периодически делаются бэкапы. Есть Pigeon Pusher — то приложение, которое рассылает пуши клиентам, а также инфраструктурная вещи: Zabbix, Graylog2 и Chef.
На самом деле эта инфраструктура избыточна, потому что 100 тысяч можно обслуживать и с меньшим количеством серверов. Но железо было — мы его использовали (нам сказали, что можно — почему бы и нет).
Плюсы Go
После того как мы поработали над этим приложением, выявились такие очевидные плюсы Go.
- Классная http-библиотека. С помощью неё можно достаточно много создать уже «из коробки».
- Плюс, каналы, которые позволили нам очень легко реализовать механизм отправки уведомлений клиентам.
- Замечательная штука Race detector позволила нам устранить несколько критических багов (staging-овая инфраструктура). Всё, что работает на staging«е — запущено, скомпилировано с ключом Race; и мы, соответственно, можем на staging-овой инфраструктуре посмотреть, какие у нас есть потенциальные проблемы.
- Минимализм и простота языка.

Мы ищем разработчиков! Если кто-то хочет — пожалуйста.
Вопросы
Вопрос из аудитории (далее — В): — Мне кажется, вы пропустили один важный момент относительно Fan-out. Я правильно понимаю, что когда вы отправляете клиенту ответ, вы блокируетесь, если клиент не захочет читать?
МС: — Нет, мы не блокируемся. Во-первых, у нас это всё находится за nginx«ом, то есть с медленными клиентами никаких проблем нет. Во-вторых, у клиента канал с буфером — по сути мы можем положить туда до ста апдейтов… Если мы не можем записать в канал, то он его удаляет. Если мы видим, что канал заблокировался, то мы просто закроем канал, и всё — клиент переподключится, если возникнет какая-то проблема. Поэтому здесь в принципе блокировки не возникает.
В: — Нельзя ли было сразу отправлять в Listen/Notify запись, а не таблицу-идентификатор?
МС: — У Listen/Notify есть ограничение в 8 тысяч байт на preload, который он отправляет. В принципе можно было бы отправлять, если бы мы имели дело с малым количеством данных, но мне кажется, что так [как делаем мы] просто надёжнее. Ограничения — в самом «Постгресе».
В: — Получают ли клиенты обновления по матчам, которые их не интересуют?
МС: — В общем-то, да. Как правило, там идёт 2–3 матча параллельно, и то достаточно редко. Если клиент смотрит что-то, то обычно он смотрит тот матч, который идёт. Потом, на клиенте есть локальная база, в которую все эти обновления складываются, и даже без подключения к интернету клиент может посмотреть все прошедшие матч, по которым у него есть апдейты. По сути мы свою базу на сервере синхронизируем с локальной базой клиента, чтобы он мог работать и в офлайне.
В: — Почему вы сделали свою ORM?
Алексей (один из разработчиков «Смотри+»): — На тот момент (это было год назад) ORM было меньше, чем сейчас, когда их довольно много. Из большинства существующих ORM мне больше всего не нравится то, что большинство из них работает на пустых интерфейсах. То есть методы, которые в этих ORM, готовы принять на себя всё что угодно: структуру, указатель структуры, число, что-то вообще не относящееся к делу…
Наш ORM генерирует структуры на основе модели данных. Сам. И поэтому все методы конкретны, не используют рефлексию и т. д. Они принимают структуры и ожидают использовать те структуры, которые придут.
В: — Сколько человек участвовало?
МС: — На начальном этапе участвовало два человека. Где-то в июне мы начали, в августе основная часть была готова (первая версия). В сентябре был релиз.
В: — Там, где вы описываете SSE, вы не используете timeout. Почему так?
МС: — Если говорить начистоту, то SSE — это всё-таки html5-протокол: стандарт SSE предназначен для общения с браузерами, насколько я понимаю. У него есть дополнительные фичи, чтобы браузеры могли переподключаться (и прочее), но они нам не нужны, потому что у нас были клиенты, которые могли реализовать любую логику подключения и получения информации. Мы сделали скорее не SSE, а что-то похожее на SSE. Это не сам протокол.
Не было необходимости. Насколько я понимаю, клиенты реализовывали механизм подключения практически с нуля. Им было в принципе всё равно.
В: — Какие дополнительные утилиты вы использовали?
МС: — Наиболее активно мы использовали govet и golint, чтобы стиль был единым, а также gofmt. Больше ничего не использовали.
В: — С помощью чего производили отладку?
МС: — Отладка по большому счёту шла с помощью тестов. Никакого дебаггера, GOP мы не использовали.
В: — Можете вернуть слайд, где реализована функция Publish? Однобуквенные названия переменных вас не смущают?
МС: — Нет. У них достаточно «узкая» область видимости. Они нигде, кроме как здесь, больше не используются (кроме внутренностей этого класса), и он очень компактный — занимает всего 7 строк.
В: — Как-то всё равно не интуитивно…
МС: — Нет-нет, это настоящий код! Дело не в стиле. Просто это такой утилитарный, совсем маленький класс — всего 3 поля внутри класса…

МС: — По большому счёту, все те данные, которые синхронизируются с клиентами (сезонные матчи, игроки), не изменяются. Грубо говоря, если мы будем делать ещё какой-то вид спорта, в котором нужно будет изменять матч, мы просто в новой версии клиента всё учтём, а старые версии клиента будут забанены.
В: — Есть ли какие-то сторонние пакеты для управления зависимостями?
МС: — Мы использовали go dep.
В: — В теме доклада что-то было про видео, а в докладе про видео нет.
МС: — Нет, у меня в теме про видео ничего нет. Называется «Смотри+» — это так приложение называется.
В: — Вы говорили, что стримится на клиенты?…
МС: — Стриминговым видео мы не занимались. Это полностью делал «Мегафон». Да, я не сказал, что приложение мегафоновское.
МС: — Go — для рассылки всех данных — по счёту, по событиям матча, статистике… Go — это целиком бэкенд для приложения. Клиент откуда-то должен узнать, какую ссылку использовать для плеера, чтобы пользователь мог посмотреть матч. У нас есть ссылки на видео и на стримы, которые подготовлены.
Немного рекламы :)
Спасибо, что остаётесь с нами. Вам нравятся наши статьи? Хотите видеть больше интересных материалов? Поддержите нас, оформив заказ или порекомендовав знакомым, облачные VPS для разработчиков от $4.99, уникальный аналог entry-level серверов, который был придуман нами для Вас: Вся правда о VPS (KVM) E5–2697 v3 (6 Cores) 10GB DDR4 480GB SSD 1Gbps от $19 или как правильно делить сервер? (доступны варианты с RAID1 и RAID10, до 24 ядер и до 40GB DDR4).
Dell R730xd в 2 раза дешевле в дата-центре Equinix Tier IV в Амстердаме? Только у нас 2 х Intel TetraDeca-Core Xeon 2x E5–2697v3 2.6GHz 14C 64GB DDR4 4×960GB SSD 1Gbps 100 ТВ от $199 в Нидерландах! Dell R420 — 2x E5–2430 2.2Ghz 6C 128GB DDR3 2×960GB SSD 1Gbps 100TB — от $99! Читайте о том Как построить инфраструктуру корп. класса c применением серверов Dell R730xd Е5–2650 v4 стоимостью 9000 евро за копейки?
