Задача для разработчика, или как мы без вендора ручные сканеры прошивали
Всем привет.
Мы, Виктор Антипов и Илья Алешин, сегодня расскажем о своем опыте работы с USB-девайсами через Python PyUSB и немного о реверс-инжиниринге.

Предыстория
В 2019 году вступило в силу Постановление Правительства РФ № 224 «Об утверждении Правил маркировки табачной продукции средствами идентификации и особенностях внедрения государственной информационной системы мониторинга за оборотом товаров, подлежащих обязательной маркировке средствами идентификации, в отношении табачной продукции».
Документ объясняет, что с 1 июля 2019 года производители обязаны маркировать каждую пачку табака. А прямые дистрибьюторы должны получать данную продукцию с оформлением универсального передаточного документа (УПД). Магазинам, в свою очередь, необходимо регистрировать продажу маркированной продукции через кассу.
Также с 1 июля 2020 года оборот немаркированной табачной продукции запрещен. Это означает, что все пачки сигарет должны маркироваться специальным штрихкодом Datamatrix. Причем — важный момент — выяснилось, что Datamatrix будет не обычный, а инверсный. То есть не черный код на белом, а наоборот.
Мы протестировали наши сканеры, и оказалось, что большую их часть нужно перепрошивать/переобучать, иначе они просто не в состоянии нормально работать с этим штрихкодом. Такой поворот событий гарантировал нам сильную головную боль, потому что у нашей компании очень много магазинов, которые разбросаны по огромной территории. Несколько десятков тысяч касс — и крайне мало времени.
Что было делать? Варианта два. Первый: инженеры на объекте вручную перепрошивают и донастраивают сканеры. Второй: работаем удаленно и, желательно, охватываем сразу много сканеров за одну итерацию.
Первый вариант нам, очевидно, не подходил: пришлось бы потратиться на выезды инженеров, да и контролировать и координировать процесс в таком случае сложно. Но самое главное — работали бы люди, то есть потенциально мы получали множество ошибок и, скорее всего, не укладывались в срок.
Второй вариант всем хорош, если бы не одно но. У некоторых вендоров не оказалось необходимых нам инструментов удаленной перепрошивки для всех требуемых ОС. А так как сроки поджимали, пришлось думать своей головой.
Дальше расскажем, как мы разрабатывали инструменты для ручных сканеров под ОС Debian 9.x (у нас все кассы на Debian).
Разгадать загадку: как прошить сканер
Рассказывает Виктор Антипов.
Официальная утилита, которую предоставил вендор, работает под Windows, причем только с IE. Утилита умеет прошивать и настраивать сканер.
Так как целевая система у нас Debian, то поставили на Debian usb-redirector server, на Windows usb-redirector client. При помощи утилит usb-redirector сделали проброс сканера с Linux машины, на Windows машину.
Утилита от вендора под Windows увидела сканер и даже его нормально прошила. Таким образом, сделали первый вывод: от ОС ничего не зависит, дело в протоколе перепрошивки.
Ок. На Windows-машине запустили перепрошивку, на Linux-машине сняли dump.
Запихнули dump в WireSharh и… взгрустнули (часть деталей dump я опущу, они никакого интереса не представляют).
Что нам показал dump:

Адреса 0000–0030, судя по Wireshark, — служебная информация USB.
Нас интересовала часть 0040–0070.
Из одного кадра передачи ничего не было понятно, за исключением символов MOCFT. Эти символы оказались символами из файла прошивки, как, впрочем, и остальные символы до окончания кадра (выделен файл прошивки):

Что означали символы fd 3e 02 01 fe, лично я, как и Илья, понятия не имел.
Посмотрел следующий кадр (служебная информация здесь удалена, выделен файл прошивки):

Что стало ясно? Что первые два байта — некая константа. Все последующие блоки это подтвердили, но до окончания блока передачи:

Этот кадр тоже ввел в ступор, так как сменилась константа (выделил) и, как ни странно, имелась часть файла. Размер переданных байт файла показывал, что было передано 1024 байта. Что значили остальные байты — я снова не знал.
Первым делом, как старый BBS-ник, я пересмотрел стандартные протоколы передачи. 1024 байта ни один протокол не передавал. Начал изучать матчасть и наткнулся на протокол 1К Xmodem. Он позволял передавать 1024, но c нюансом: поначалу лишь 128, и только при отсутствии ошибок протокол увеличивал количество передаваемых байт. У меня же сразу была передача 1024 байта. Решил изучать протоколы передачи, а конкретно Х-модем.
Вариаций модема было две.
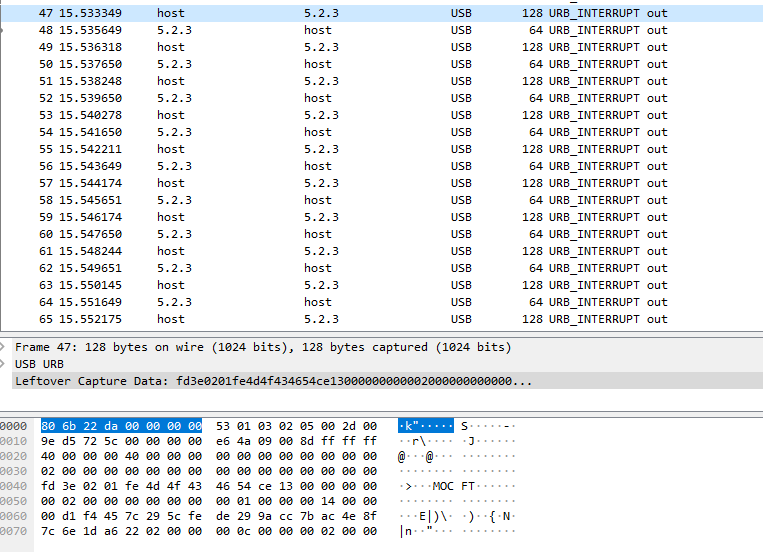
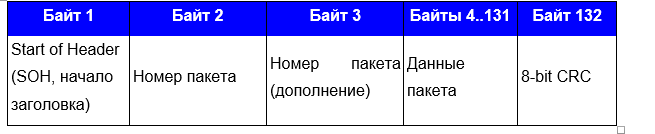
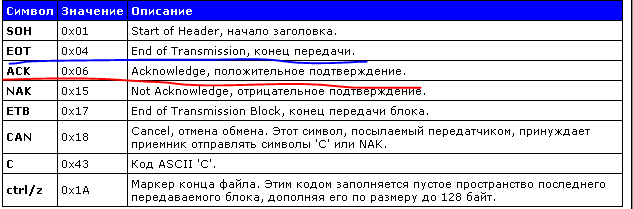
Во-первых, формат пакета XMODEM с поддержкой CRC8 (оригинальный XMODEM):
Во-вторых, формат пакета XMODEM с поддержкой CRC16 (XmodemCRC):
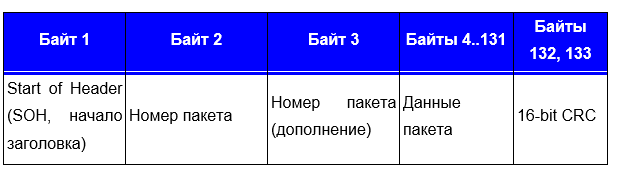
С виду похоже, за исключением SOH, номера пакета и CRC и длины посылки.
Посмотрел начало второго блока передачи (и снова увидел файл прошивки, но уже с отступом в 1024 байта):

Увидел знакомый заголовок fd 3e 02, но следующие два байта уже изменились: было 01 fe, а стало 02 fd. Тут я заметил, что второй блок теперь нумеруется 02 и таким образом понял: передо мной нумерация блока передачи. Первая 1024 передача — 01, вторая — 02, третья — 03 и так далее (но в hex, естественно). Но что означает изменение с fe на fd? Глаза видели уменьшение на 1, мозг напоминал, что программисты считают с 0, а не с 1. Но тогда почему первый блок 1, а не 0? Ответа на этот вопрос я так и не нашел. Зато понял, как считается второй блок. Второй блок — это не что иное как FF –(минус) номер первого блока. Таким образом, второй блок обозначался как = 02 (FF-02) = 02 FD. Последующее чтение дампа подтвердило мою догадку.
Тогда стала вырисовываться следующая картина передачи:
Начало передачи
fd 3e 02 — Start
01 FE — счетчик передачи
Передача (34 блока, передается 1024 байта)
fd 3e 1024 байта данных (разбитые на блоки по 30 байт).
Окончание передачи
fd 25
Остатки данных для выравнивания до 1024 байта.
Как выглядит кадр окончания передачи блока:

fd 25 — сигнал к окончанию передачи блока. Далее 2f 52 — остатки файла до размера 1024 байта. 2f 52, судя по протоколу, — контрольная сумма 16-bit CRC.
По старой памяти сделал на С программу, которая дергала из файла 1024 байта и считала 16-bit CRC. Запуск программы показал, что это не 16-bit CRC. Снова ступор — примерно на три дня. Все это время я пытался понять, что это может быть такое, если не контрольная сумма. Изучая англоязычные сайты, я обнаружил, что для X-модем используется свой подсчет контрольной суммы — CRC-CCITT (XModem). Реализаций на C данного подсчета я не нашел, но нашел сайт, который в online считал данную контрольную сумму. Перекинув на веб-страничку 1024 байта своего файла, сайт показал мне контрольную сумму, которая полностью совпала с контрольной суммой из файла.
Ура! Последняя загадка решена, теперь нужно было сделать свою прошивалку. Далее я передал свои знания (а они остались только у меня в голове) Илье, который знаком с мощным инструментарием — Python.
Создание программы
Рассказывает Илья Алешин.
Получив соответствующие инструкции, я очень «обрадовался».
С чего начать? Правильно, с начала. Со снятия дампа с USB порта.
Запускаем USB-pcap https://desowin.org/usbpcap/tour.html
Выбираем порт, к которому подключено устройство, и файл, куда сохраним dump.
Подключаем сканер к машине, где установлено родное ПО EZConfigScanning для Windows.
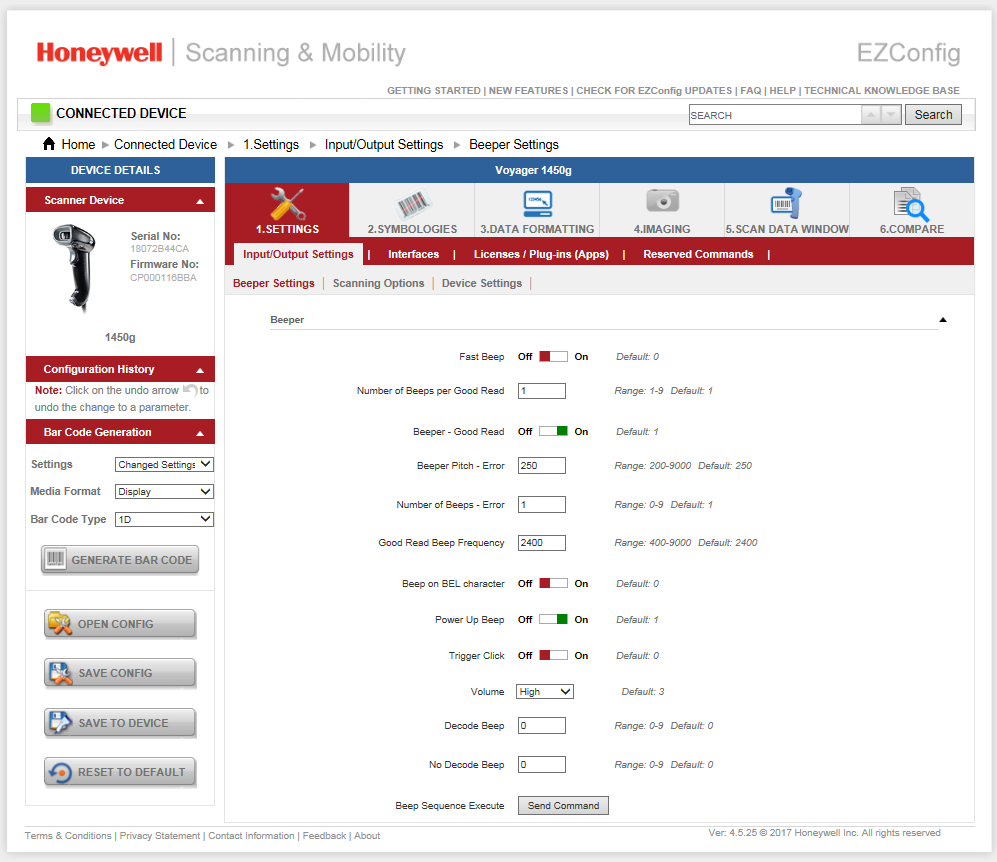
В нем находим пункт отправки команд на устройство. Но как быть с командами? Где их взять?
При старте программы оборудование опрашивается автоматически (это мы увидим чуть позже). И еще были обучающие штрихкоды из официальных документов оборудования. DEFALT. Это и есть наша команда.

Необходимые данные получены. Открываем dump.pcap через wireshark.
Блок при старте EZConfigScanning. Красным отмечены места, на которые надо обратить внимание.
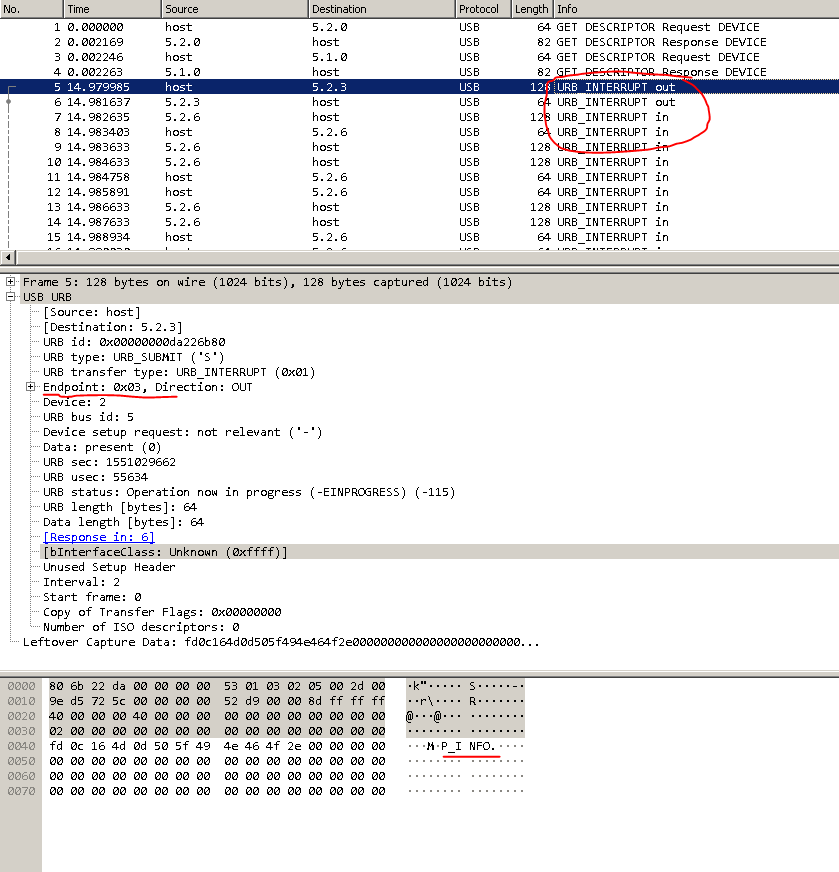
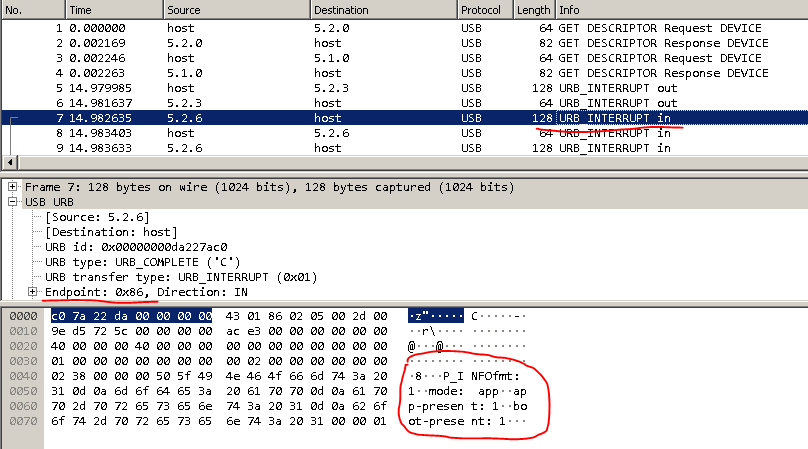
Увидев все это в первый раз, я упал духом. Куда копать дальше — непонятно.
Немного мозгового штурма и-и-и… Ага! В дампе out — это in, а in это out.
Погуглил, что такое URB_INTERRUPT. Выяснил, что это метод передачи данных. И таких методов 4: control, interrupt, isochronous, bulk. О них можно почитать отдельно.
А endpoint адреса в интерфейсе USB-девайса можно получить либо через команду «lsusb –v», либо средствами pyusb.
Теперь надо найти все устройства с таким VID. Можно искать конкретно по VID: PID.

Выглядит это так:
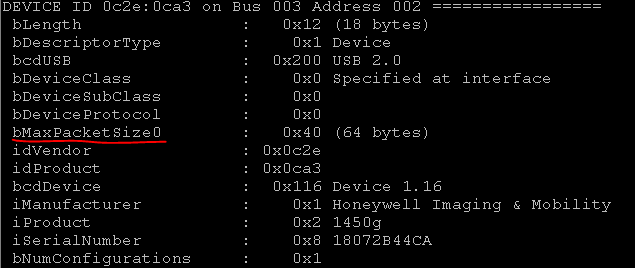
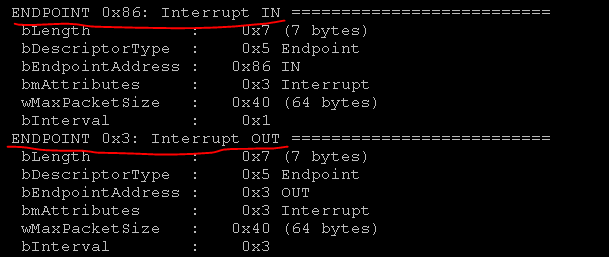
Итак, у нас появилась нужная информация: команды P_INFO. или DEFALT, адреса, куда записать команды endpoint=03 и откуда получить ответ endpoint=86. Осталось только перевести команды в hex.


Так как устройство у нас уже найдено, отключим его от ядра…
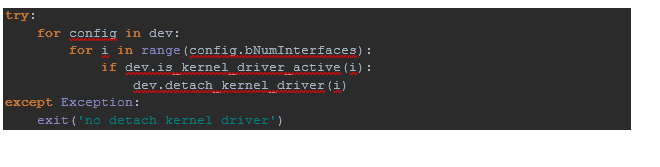
…и выполним запись в endpoint c адресом 0×03,

…, а затем зачитаем ответ из endpoint с адресом 0×86.

Структурированный ответ:
P_INFOfmt: 1
mode: app
app-present: 1
boot-present: 1
hw-sn: 18072B44CA
hw-rev: 0x20
cbl: 4
app-sw-rev: CP000116BBA
boot-sw-rev: CP000014BAD
flash: 3
app-m_name: Voyager 1450g
boot-m_name: Voyager 1450g
app-p_name: 1450g
boot-p_name: 1450g
boot-time: 16:56:02
boot-date: Oct 16 2014
app-time: 08:49:30
app-date: Mar 25 2019
app-compat: 289
boot-compat: 288
csum: 0x6986
Эти данные мы видим в dump.pcap.



Отлично! Переводим системные штрихкоды в hex. Все, функционал обучения готов.
Как быть с прошивкой? Вроде, все то же самое, но есть нюанс.
Сняв полный дамп процесса перепрошивки, мы примерно поняли, с чем имеем дело. Вот статья про XMODEM, которая очень помогла понять, как это общение происходит, пусть и в общих чертах: http://microsin.net/adminstuff/others/xmodem-protocol-overview.html Рекомендую прочесть.
Посмотрев в дамп, можно увидеть, что размер кадра — 1024, а размер URB-data — 64.
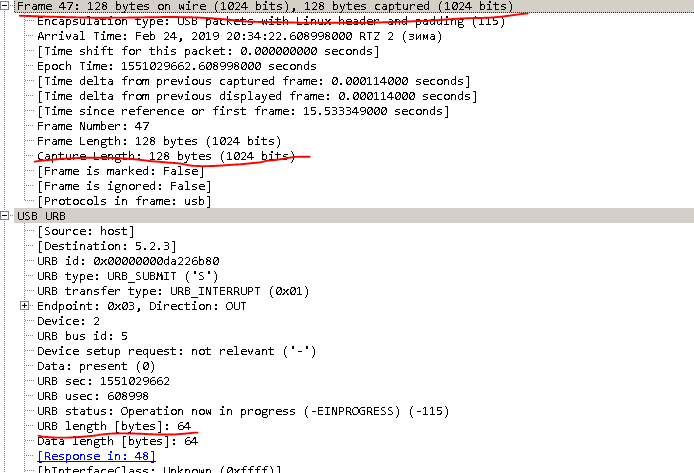
Следовательно — 1024/64 — получаем 16 строк в блоке, читаем файл прошивки по 1 символу и формируем блок. Дополняя 1 строку в блоке спецсимволами fd3e02 + номер блока.
14 следующих строк дополняем fd25 +, с помощью XMODEM.calc_crc () вычисляем контрольную сумму всего блока (потребовалось немало времени, чтобы понять, что «FF — 1» — это CSUM) и последнюю, 16-ю, строку дополняем fd3e.
Казалось бы, все, читай файл прошивки, бей на блоки, отключай сканер от ядра и засылай в девайс. Но не все так просто. Сканер нужно перевести в режим прошивки,
отправив ему NEWAPP = '\\xfd\\x0a\\x16\\x4e\\x2c\\x4e\\x45\\x57\\x41\\x50\\x50\\x0d'.
Откуда эта команда? Из дампа.

Но мы не можем отправить в сканер целый блок из-за ограничения в 64:

Ну и сканер в режиме перепрошивки NEWAPP не принимает hex. Поэтому придется каждую строку переводить bytes_array
[253, 10, 22, 78, 44, 78, 69, 87, 65, 80, 80, 13, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
И уже эти данные отправлять в сканер.
Получаем ответ:
[2, 1, 0, 0, 0, 6, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
Если свериться со статьей про XMODEM, станет понятно: данные приняты.
После того как все блоки переданы, завершаем передачу END_TRANSFER = '\xfd\x01\x04'.
Ну, а так как эти блоки для обычных людей никакой информации не несут, сделаем по умолчанию прошивку в скрытом режиме. И на всякий случай через tqdm организуем прогресбар.

Собственно, дальше дело за малым. Остается только обернуть решение в скрипты для массового тиражирования в четко заданное время, чтобы не тормозить процесс работы на кассах, и добавить логирование.
Итог
Потратив кучу времени и сил и волос на голове, мы сумели разработать нужные нам решения, к тому же уложились в срок. При этом сканеры перепрошиваются и переобучаются теперь централизованно, мы четко контролируем весь процесс. Компания сэкономила время и средства, а мы получили бесценный опыт реверс-инжиниринга оборудования такого типа.
