Миф о комбинаторике в тестировании
Неважно, какие методологии, процессы, языки и фреймворки вы используете. В любом тестировании программного обеспечения всегда присутствует тест-дизайн, сужающий генеральную совокупность всех возможных проверок до какой-то реалистичной выборки. Тест-дизайн можно разбить на несколько уровней сложности, и где-то в середине пути мы встретимся с комбинацией данных в элементах системы. Но не везде упоминают, что используемая в тестировании комбинаторика очень ограничена в применении, об этом мы и поговорим в статье. С примерами!

Что есть комбинаторное тестирование
Комбинаторное тестирование — это метод тестирования программного обеспечения, который позволяет эффективно обнаруживать ошибки, связанные со взаимодействием параметров. Самый популярный вариант — попарное тестирование (pairwise). Pairwise основан на принципе, который гласит, что 98% всех ошибок возникают в результате влияния одного или двух параметров. Попарное тестирование позволяет исследовать все возможные комбинации значений для каждой пары параметров, что обеспечивает более широкое покрытие тестирования, чем тестирование каждого параметра в отдельности. Это позволяет обнаружить большинство ошибок в программном обеспечении и снизить количество дефектов, которые могут возникнуть в процессе эксплуатации программы. Для попарного тестирования используются алгоритмы, основанные на построении ортогональных массивов или на all-pairs алгоритме, которые опираются на теоретические исследования в области комбинаторных алгоритмов, алгоритмов дискретной математики и, в частности, латинских квадратов.
Как зародился миф
Вся эта уверенность основана на исследовании IEEE [1] и [2], в которых авторы анализировали выявленные ошибки в медицинских устройствах на основе их описания. В ходе исследования авторы рассмотрели 109 из 342 ошибок с достаточным уровнем детализации, чтобы определить необходимый уровень тестирования для выявления ошибки. А вот уже из этих 109 хорошо описанных дефектов только 3 требовали больше двух условий для проявления. Но нестыковка тут в том, что никто не анализировал сами входные параметры на связность, а рассматривали только входные данные без анализа выходных данных. Если мы будем смотреть на «правильный» выходной параметр, вывод может быть совсем иным. Этот выходной параметр может быть связан со входными параметрами, а нам необходимо тестировать пары входных параметров с парами выходных параметров: не связанных вообще, либо слабо связанных с входными. Но мы этого не знаем, ведь перед нами черный ящик.
А как все на самом деле
В конце 80-х годов для фармацевтической отрасли была написана система анализа DMAS (Data Management Analysis System). Приложение изначально написали на FORTRAN, а в 90-х годах переписали на C++ для использования в академической среде в проектах исследований и программной инженерии. DMAS использовалась химиками-аналитиками для обработки файлов данных, собранных из экспериментов с использованием жидкостной и газовой хроматографии. Всего в программе можно комбинировать 18 различных входных переменных. В исследовании [3] эту программу использовали для оценки влияния количества входных переменных на выходные параметры и результат можно видеть на рисунке ниже:

График показывает, что в промышленных и сложных системах с высокой вариативностью все самое интересное находится при комбинации 3 и более переменных. Ричард Кун в [2] и более поздних работах использует диаграмму зависимости суммарной доли ошибок в разных типах программного обеспечения, откуда видно, что для многих случаев 1–2 факторов недостаточно. И чем сложнее система, тем меньше ошибок может быть найдено попарным тестированием.
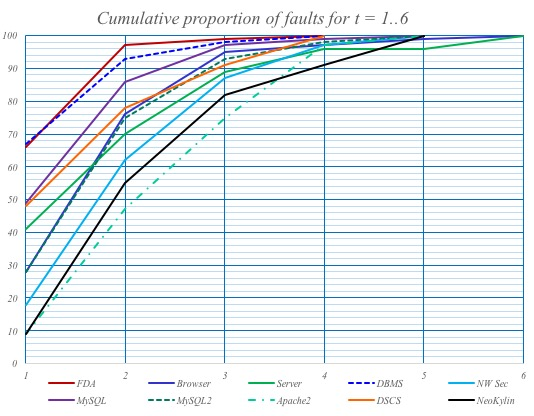
Сложность, как правило, означает и высокую цену ошибки. В исследовании [4] на примере проекта NASA более точно подсчитали, что для 3 и более факторов доля всех ошибок может составлять уже 50%. А 50% это не 98%, как в каноне.
Эффективность любого тестирования можно оценивать только на реальных данных с применением как альтернативных, так и разных комбинаторных техник. И проблема заключается в том, что данных мало и они всегда относятся к черному ящику. Недостаточно информации о характеристиках тестируемых систем, о профессионализме тестировщиков, о серьезности дефектов и требованиях, на основе которых их посчитали таковыми. Без знания о системе, без оценки сложности и трудоемкости тестирования нам остается сравнивать комбинаторные техники только со случайными выборками.
При комбинации 2 параметров уже после 10–40 попарных тестов на малых наборах данных покрытие случайной выборкой составляет в среднем 95% [5]. А при 160 попарных тестах с большими наборами данных эквивалентный набор случайных тестов оказывается всего на 30% больше [6]. К такому же выводу пришел и Джеймс Бах в [7], по сути назвав попарное тестирование «псевдоисчерпывающим». Из чего можно сделать вывод, что само количество комбинаций или тестовых наборов не является определяющим при выборе попарного тестирования. Бах явно указывает на это:
Попарное тестирование может обнаруживать некоторые ошибки при существенном сокращении числа тестов, по сравнению с тестированием всех возможных комбинаций, но не обязательно по сравнению с тестированием только тех комбинаций, которые имеют значение;
Попарные ошибки могут представлять собой большинство комбинаторных ошибок, а могут и не представлять, в зависимости от фактических зависимостей между переменными в продукте;
Некоторые попарные ошибки менее вероятны, чем те, которые происходят только при участии большего числа переменных, потому что входные данные не распределены случайно.
Как все-таки пользоваться комбинаторикой
Но если мы хотим комбинировать в тестах больше двух параметров, ситуация сильно меняется. Результаты экспериментов по сравнению адаптивного случайного и жадного комбинаторного тестирования в исследовании [8] для обнаружения ошибок в логике управления распределенной системы управления ядерной энергетикой показали:
Если количество наборов тестов относительно небольшое, то эффективность обнаружения ошибок при адаптивном случайном тестировании и жадном комбинаторном тестировании очень близка, хотя адаптивное случайное тестирование имеет преимущество;
При постепенном увеличении количества наборов тестов эффективность обнаружения ошибок при жадном комбинаторном тестировании улучшается;
Если тестовых ресурсов достаточно, эффективность обнаружения ошибок при жадном комбинаторном тестировании выше.
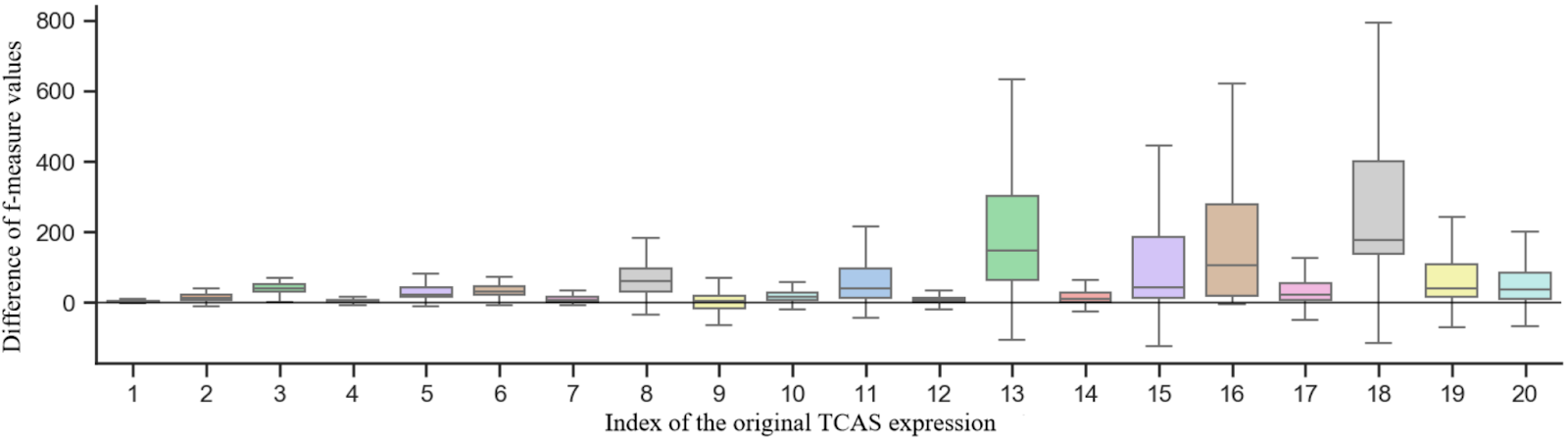
На этом графике показана разница значений F-меры между адаптивным случайным тестированием и комбинаторным тестированием со стратегией пошагового увеличения силы (числа параметров, которые могут взаимодействовать друг с другом) в системе предупреждения о трафике и избежания столкновений. F-мера (F-measure) — это метрика, которая используется в оценке качества алгоритмов классификации и информационного поиска. F-мера является гармоническим средним точности (precision) и полноты (recall).
Следовательно, выбор техники тестирования зависит преимущественно от наличия тестовых ресурсов:
Когда ресурсы для тестирования строго ограничены, и мы можем выполнить не все тест-кейсы, следует выбирать адаптивное случайное тестирование. Поскольку эффективность выявления ошибок у двух техник при небольшом количестве тест-кейсов сопоставима, а реализация адаптивного случайного тестирования проще;
Когда ресурсы для тестирования ограничены меньше и есть возможность использовать много тест-кейсов, мы выбираем технику комбинаторного тестирования, потому что эффективность обнаружения ошибок при большом количестве тест-кейсов оказывается выше.
Также можно использовать гибридную стратегию тестирования. Сначала используется техника адаптивного случайного тестирования для создания тестового набора, в котором количество тест-кейсов не превышает размера двухпараметрического тестового набора. Затем эти тест-кейсы используются для генерации комбинаторных тест-кейсов более высокого порядка до тех пор, пока тестовые ресурсы не будут исчерпаны. Стратегия тестирования, объединяющая сразу две техники, может улучшить эффективность обнаружения ошибок всего процесса тестирования.
И это возвращает нас к началу. Например, откуда мы знаем, связаны ли между собой все параметры или нет? Можно ли объединить какие-то параметры? Никакая комбинаторика не поможет, если мы забудем учесть неочевидные параметры, вроде сетевого соединения, настроек окружения или истории событий в качестве входных параметров функций. Более того, чтобы учесть все параметры, на которые мы можем повлиять, мы должны сначала исследовать программу и ее окружение. Так мы и приходим к исследовательскому тестированию. Иначе получится именно то, что и наблюдаем в жизни: программа вроде как протестирована, но ломается в неочевидных местах. А ведь существуют также и такие параметры, на которые повлиять сложно или вовсе невозможно.
С подобными ситуациями я неоднократно сталкивался в своей работе. У нас есть сервисы с довольно сложной логикой и внешними интеграциями. Особенность тестирования внешних интеграций заключается в том, что начинается как будто с белого ящика, но после хождения по граблям становится очевидно, что цвет ящика на самом деле был серым, а иногда и вовсе — черным. В одном из таких проектов, мы использовали API рекламной сети, и на первый взгляд там присутствовало множество параметров, которые можно было скомбинировать. Но в реальности все дефекты, как критичные, так и просто повлиявшие на time-to-market, оказались в такой плоскости, которую в простые тест-кейсы не поместишь. Вот некоторые из них:
Невозможность проверить все комбинации в dev-окружении. Возможности песочниц сильно ограничивают вариативность сложных переменных, а в проде мы уже ограничены общим ресурсом тестирования;
Нестабильность и непредсказуемость внешней системы обесценивает результат скриптового тестирования;
Юридические или персональные данные могут отдельно валидироваться внешней системой;
Многие технические детали отсутствуют в документации, а выяснение их через живых людей значительно увеличивает сроки и меняет любой предварительно созданный тестовый набор.
Заключение
Таким образом, комбинаторное тестирование может дать ожидаемый эффект только при комбинации трех и более независимых параметров в условиях избытка тестовых ресурсов, а попарное тестирование и вовсе неэффективно. В качестве итога я изобразил возможности применения комбинаторных техник в виде квадрантов в зависимости от сложности системы, количества возможных тестов и проверяемых в них комбинаций.

I квадрант. Сложная система, много параметров и тестов. Можно использовать n-way комбинаторику, если полно времени. Сначала придется анализировать и исследовать продукт, осознанно подбирать параметры, осознанно конфигурировать тесты. Скорее всего, количество тестов здесь будет обусловлено высокой вариативностью, можно использовать комбинаторику в качестве фильтра для более изысканных тестов. Но не рассчитывайте на высокую эффективность, вы все равно упустите какие-то параметры.
II квадрант. Простая система, много параметров и тестов. Кажется, что комбинаторика тут будет на своем месте. Только зачем? Если система такая простая, то и цена ошибки невелика, случайные или атомарные тесты могут оказаться проще и дешевле, чем 2-way. Если работаете с белым ящиком, то вы знаете о системе достаточно для использования более эффективных техник тест-дизайна В противном случае мы возвращаемся в I квадрант. Попробуйте автоматизировать все, что получится, а комбинаторные тесты можно использовать как фильтр.
III квадрант. Сложный продукт, мало параметров и тестов. Комбинаторика не сильно нужна, но ее можно использовать для дымового или приемочного тестирования. Вероятно, атомарные тесты будут удобнее.
IV квадрант.Простой продукт, мало параметров и тестов. Комбинаторику не используем.
В заключении напомню, что любая техника тест-дизайна может быть применима, но комбинаторика по сравнению с альтернативами имеет крайне узкую область применимости
Источники
Dolores R. Wallace, Richard Kuhn. Failure modes in medical device software: an analysis of 15 years of recall data // International Journal of Reliability Quality and Safety Engineering, 2001.
D. Richard Kuhn, Dolores R. Wallace, Albert M. Gallo Jr. Software Fault Interactions and Implications for Software Testing // IEEE Transactions on Software Engineering, 2004.
Patrick J. Schroeder, Pankaj Bolaki, Vijayram Gopu. Comparing the Fault Detection Effectiveness of N-way and Random Test Suites // International Symposium on Empirical Software Engineering, 2004.
B. Smith, M.S. Feather, and N. Muscettola. Challenges and Methods in Testing the Remote Agent Planner. // Proc. 5th Int’l Conf. on Artificial Intelligence Planning and Scheduling (AIPS 2000), 2000, pp. 254–263.
Siddhartha R. Dalal, Colin L. Mallows. Factor-Covering Designs for Testing Software, 1998.
Lee J. White. Regression Testing of GUI Event Interactions, 1996
James Bach, Patrick J. Schroeder. Pairwise Testing: A Best Practice That Isn«t, 2006.
Cheng Zong, Yanliang Zhang, Yao Yongming… A Comparison of Fault Detection Efficiency Between Adaptive Random Testing and Greedy Combinatorial Testing for Control Logics in Nuclear Industrial Distributed Control Systems // IEEE Access, 2017.
