Как настроить миграцию etcd между облачными кластерами Kubernetes и избежать простоев
Допустим, вам нужно перенести хранилище данных из одного кластера в другой. А выключать его нельзя, потому что это может вызвать незначительный (или значительный) коллапс сервисов, которые с ним работают. В статье мы расскажем о не самом очевидном и популярном способе переноса etcd из одного облачного кластера Kubernetes в другой. Такой способ поможет избежать простоя и связанных с ним последствий. Согласно стартовым условиям, оба кластера находятся в облаке, а потому нам предстоит столкнуться с некоторыми ограничениями и трудностями — им мы уделим особое внимание.

Существует два пути для миграции etcd между кластерами:
Наиболее очевидный — снять snapshot etcd и развернуть его на новом месте. Но этот способ трудно назвать беспростойным, поэтому мы поговорим не о нем.
Второй путь заключается в «растягивании» etcd на два кластера Kubernetes. То есть, мы создаем свои StatefulSet«ы в каждом из кластеров k8s, а уже из них — формируем единый кластер etcd. У этого способа есть риски: при ошибке есть шанс за«affect"ить существующий etcd, но зато с ним можно настроить миграцию etcd между кластерами и избежать простоев. Этот вариант мы и рассмотрим ниже.

Примечание: в статье мы используем Yandex Сloud, но процесс почти не будет отличаться для любого другого облачного провайдера. Кластеры k8s в примерах управляются при помощи Kubernetes-платформы Deckhouse. Это означает, что часть функциональности может быть специфична для этой платформы, но в таких местах предлагаются альтернативные пути решения задачи.
Статья пригодится тем, кто имеет базовые представления о etcd и работал с ним. Также рекомендуем ознакомиться с официальной документацией etcd.
Шаг 1. Подготовительный: уменьшаем размер базы etcd
Примечание: если в вашем кластере etcd предусмотрено хранение ограниченного числа ревизий каждого ключа — смело пропускайте этот раздел статьи.
Первое, о чем стоит подумать перед стартом миграции, — это размер базы etcd. Если база большая, это скажется на времени bootstrap«а новых нод и потенциально может привести к проблемам. Поэтому разберем, как уменьшить размер базы.
Сперва выясним текущую ревизию, для этого получим список ключей при помощи etcdctl:
# etcdctl get / --prefix --keys-only
/main_production/main/config
/main_production/main/failover
/main_production/main/history
…Посмотрим любой ключ в JSON-формате:
# etcdctl get /main_production/main/history -w=json
{"header":{"cluster_id":13812367153619139789,"member_id":7168735187350299418,"revision":5828757,..Собственно, тут мы видим текущую ревизию в кластере, в нашем примере это 5828757.
Из этого числа вычтем количество последних ревизий, которые хотим сохранить: по опыту, тысячи достаточно. Выполним etcdctl compactionдо указанного значения:
# etcdctl compaction 5827757Команда глобальна для всего кластера etcd, достаточно выполнить ее один раз на любой ноде.Подробнее про работу compaction(и любых других команд etcdctl)можно почитать в официальной документации.
Далее, чтобы освободить место, выполним defrag:
# etcdctl defrag --command-timeout=90sЭту команду придется запустить на каждой ноде последовательно. Рекомендуем сделать это на всех нодах кроме лидера, потом переключить его на ноду с уже очищенным местом при помощи etcdctl move-leader. И лишь потом завершить уменьшение размера базы на оставшейся ноде.
В нашем случае процедура сократила размер базы с 800 Мбайт до ~700 Кбайт, что ощутимо уменьшило затраты времени на последующие шаги.
Чарт etcd, который будем использовать
etcd работает под управлением StatefulSet«а. Ниже приведен пример StatefulSet«а, который используется в кластере:
Пример
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: etcd
labels:
app: etcd
spec:
serviceName: etcd
selector:
matchLabels:
app: etcd
replicas: 3
template:
metadata:
labels:
app: etcd
spec:
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- etcd
topologyKey: kubernetes.io/hostname
imagePullSecrets:
- name: registrysecret
containers:
- name: etcd
image: quay.io/coreos/etcd:v3.4.18
command:
- sh
args:
- -c
- |
stop_handler() {
>&2 echo "Caught SIGTERM signal!"
kill -TERM "$child"
}
trap stop_handler SIGTERM SIGINT
etcd \
--name=$HOSTNAME \
--initial-advertise-peer-urls=http://$HOSTNAME.etcd:2380 \
--initial-cluster-token=etcd-cortex-prod \
--initial-cluster etcd-0=http://etcd-0.etcd:2380,etcd-1=http://etcd-1.etcd:2380,etcd-2=http://etcd-2.etcd:2380 \
--advertise-client-urls=http://$HOSTNAME.etcd:2379 \
--listen-client-urls=http://0.0.0.0:2379 \
--listen-peer-urls=http://0.0.0.0:2380 \
--auto-compaction-mode=revision \
--auto-compaction-retention=1000 &
child=$!
wait "$child"
env:
- name: ETCD_DATA_DIR
value: /var/lib/etcd
- name: ETCD_HEARTBEAT_INTERVAL
value: 200
- name: ETCD_ELECTION_TIMEOUT
value: 2000
resources:
requests:
cpu: 50m
memory: 1Gi
limits:
memory: 1gi
volumeMounts:
- name: data
mountPath: /var/lib/etcd
ports:
- name: etcd-server
containerPort: 2380
- name: etcd-client
containerPort: 2379
readinessProbe:
exec:
command:
- /bin/bash
- -c
- /usr/local/bin/etcdctl endpoint health
initialDelaySeconds: 10
periodSeconds: 10
timeoutSeconds: 10
volumeClaimTemplates:
- metadata:
name: data
spec:
accessModes: [ "ReadWriteOnce" ]
resources:
requests:
storage: 2Gi
---
apiVersion: v1
kind: Service
metadata:
name: etcd
spec:
clusterIP: None
ports:
- name: etcd-server
port: 2380
- name: etcd-client
port: 2379
selector:
app: etcd
К важным элементам этого чарта мы вернемся по ходу статьи.
Шаг 2. Обеспечиваем доступность нод etcd снаружи
Если etcd используют клиенты вне кластера Kubernetes, с большой долей вероятности уже есть сущности для доставки трафика в поды. Но для bootstrap«а новых нод нужно, чтобы каждая нода кластера была доступна снаружи по заранее определенному IP. Это и есть основная сложность в использовании облачного кластера в нашем случае.
В статическом кластере Kubernetes доступность каждой etcd-ноды обеспечить несложно: поможет сервис типа NodePort в связке с жесткими NodeSelector«ами для подов. В облаке, где под в любой момент может переехать на новую ноду без заранее определенного статического IP, такой подход неприменим.
Как решить эту задачу: создадим три отдельных сервиса с типом LoadBalancer — они нам нужны, так как мы имеем дело с «трехголовым» etcd. При этом будут автоматически заказаны LB в нашем облачном провайдере. Вот пример чарта:
---
apiVersion: v1
kind: Service
metadata:
name: etcd-0
annotations:
yandex.cloud/load-balancer-type: Internal
yandex.cpi.flant.com/listener-subnet-id: e9b***ho7k
yandex.cpi.flant.com/target-group-network-id: enp***5q7
spec:
externalTrafficPolicy: Local
loadBalancerSourceRanges:
- 0.0.0.0/0
ports:
- name: etcd-server
port: 2380
- name: etcd-client
port: 2379
selector:
statefulset.kubernetes.io/pod-name: etcd-0
type: LoadBalancer
---
apiVersion: v1
kind: Service
metadata:
name: etcd-1
annotations:
yandex.cloud/load-balancer-type: Internal
yandex.cpi.flant.com/listener-subnet-id: e9b***ho7k
yandex.cpi.flant.com/target-group-network-id: enp***5q7
spec:
externalTrafficPolicy: Local
loadBalancerSourceRanges:
- 0.0.0.0/0
ports:
- name: etcd-server
port: 2380
- name: etcd-client
port: 2379
selector:
statefulset.kubernetes.io/pod-name: etcd-1
type: LoadBalancer
---
apiVersion: v1
kind: Service
metadata:
name: etcd-2
annotations:
yandex.cloud/load-balancer-type: Internal
yandex.cpi.flant.com/listener-subnet-id: e9b***ho7k
yandex.cpi.flant.com/target-group-network-id: enp***5q7
spec:
externalTrafficPolicy: Local
loadBalancerSourceRanges:
- 0.0.0.0/0
ports:
- name: etcd-server
port: 2380
- name: etcd-client
port: 2379
selector:
statefulset.kubernetes.io/pod-name: etcd-2
type: LoadBalancer
Аннотация yandex.cloud/load-balancer-type указывает, что будет заказан LB с приватным IP. Следующие две аннотации указывают, в какой сети должен размещаться LB. Такая функциональность есть у большинства облачных провайдеров, различаться будут только аннотации. Подробнее о работе с конкретным облачным провайдером можно почитать в официальной документации Deckhouse.
Посмотрим на получившиеся ресурсы.
В кластере:

В облаке (один из заказанных LB):

Проверим доступность:
# telnet 10.100.0.47 2379
Trying 10.100.0.47...
Connected to 10.100.0.47.
Escape character is '^]'.Отлично, наши ноды etcd теперь доступны извне.
Перейдем к созданию аналогичных сервисов в новом кластере.
Важный нюанс: На этом этапе мы создаем только сервисы в новом кластере k8s, StatefulSetсоздавать пока рано.
В новом кластере необходимо будет создать StatefulSetс именем, отличным от того, что существует в текущем. hostname внутри подов должны быть разными, так как мы используем их в качестве имен нод etcd.
StatefulSetв новом кластере будет называться etcd-main (можно использовать любое другое имя). Соответственно, немного изменим селекторы и имена сервисов:
…
name: etcd-main-0
…
selector:
statefulset.kubernetes.io/pod-name: etcd-main-0
…Также заменим значения в аннотациях yandex.cpi.flant.com/listener-subnet-idиyandex.cpi.flant.com/target-group-network-idна соответствующие ID сетей в новом кластере Kubernetes. Остальные ресурсы сервисов останутся без изменений.
Проверим результат:

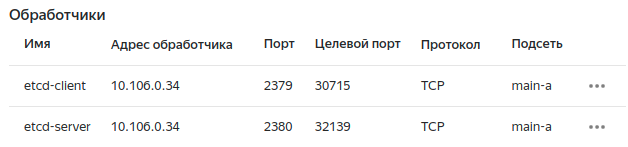
Проверять доступность пока не будем, так как еще нет подов, в которые эти сервисы ведут.
Шаг 3. Делаем магию с DNS
Мы обеспечили доступность на уровне IP-адресов, теперь стоит обратить внимание на идентификаторы нод внутри etcd. Посмотрим на параметры запуска:
--name=$HOSTNAME \
--initial-advertise-peer-urls=http://$HOSTNAME.etcd:2380 \
--advertise-client-urls=http://$HOSTNAME.etcd:2379 \Не будем подробно останавливаться на каждом параметре: про них можно почитать в официальной документации. Нам важно, что имя ноды — это hostname пода. А обращаются друг к другу ноды по FQDN в формате
Наиболее простой — добавить статические записи в /etc/hosts внутри подов, отредактировав StatefulSet. Минус способа: он потребует рестарта подов.
Альтернативный путь — разрешение имен на уровне kube-dns. Давайте используем этот способ. В примере статические записи добавлены при помощи модуля kube-dns:
spec:
settings:
hosts:
- domain: etcd-main-0
ip: 10.106.0.34
- domain: etcd-main-1
ip: 10.106.0.42
- domain: etcd-main-2
ip: 10.106.0.47
- domain: etcd-main-0.etcd-main
ip: 10.106.0.34
- domain: etcd-main-1.etcd-main
ip: 10.106.0.42
- domain: etcd-main-2.etcd-main
ip: 10.106.0.47Проверим resolve из пода:
# host etcd-main-0
etcd-main-0 has address 10.106.0.34
# host etcd-main-0.etcd-main
etcd-main-0.etcd-main has address 10.106.0.34Все работает. Теперь повторим процедуру в новом кластере, добавим статические записи для нод etcd из старого кластера:
spec:
settings:
hosts:
- domain: etcd-0
ip: 10.100.0.47
- domain: etcd-1
ip: 10.100.0.46
- domain: etcd-2
ip: 10.100.0.37
- domain: etcd-0.etcd
ip: 10.100.0.47
- domain: etcd-1.etcd
ip: 10.100.0.46
- domain: etcd-2.etcd
ip: 10.100.0.37Шаг 4. Добавляем новые ноды в кластер etcd
Пришло время добавить новые ноды в кластер etcd, «растянув» его поверх двух кластеров Kubernetes. Для этого в любом из существующих подов etcd выполним команду:
etcdctl member add etcdt-main-0 --peer-urls=http://etcd-main-0.etcd-main
:2380Так как мы оговорили, что StatefulSetбудет называться etcd-main, мы знаем имена новых подов.
Важное пояснение: может возникнуть вопрос: «Почему бы не добавить все новые ноды разом?». Особенность вот в чем: у нас кластер из 6 участников, его кворум — 4. Если сразу добавить 4 ноды, кворум потеряется. Это приведет к отказу существующих нод.
Теперь отредактируем чарт для деплоя в новый кластер:
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: etcd-main
labels:
app: etcd-main
spec:
serviceName: etcd
selector:
matchLabels:
app: etcd
replicas: 1
template:
metadata:
labels:
app: etcd
spec:
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- etcd
topologyKey: kubernetes.io/hostname
imagePullSecrets:
- name: registrysecret
containers:
- name: etcd
image: quay.io/coreos/etcd:v3.4.18
command:
- sh
args:
- -c
- |
stop_handler() {
>&2 echo "Caught SIGTERM signal!"
kill -TERM "$child"
}
trap stop_handler SIGTERM SIGINT
etcd \
--name=$HOSTNAME \
--initial-advertise-peer-urls=http://$HOSTNAME.etcd-main:2380 \
--initial-cluster-state existing \
--initial-cluster-token=etcd-cortex-prod \
--initial-cluster etcd-main-0=http://etcd-main-0.etcd-main:2380,etcd-0=http://etcd-0.etcd:2380,etcd-1=http://etcd-1.etcd:2380,etcd-2=http://etcd-2.etcd:2380 \
--advertise-client-urls=http://$HOSTNAME.etcd:2379 \
--listen-client-urls=http://0.0.0.0:2379 \
--listen-peer-urls=http://0.0.0.0:2380 \
--auto-compaction-mode=revision \
--auto-compaction-retention=1000 &
child=$!
wait "$child"
env:
- name: ETCD_DATA_DIR
value: /var/lib/etcd
- name: ETCD_HEARTBEAT_INTERVAL
value: 200
- name: ETCD_ELECTION_TIMEOUT
value: 2000
resources:
requests:
cpu: 50m
memory: 1Gi
limits:
memory: 1gi
volumeMounts:
- name: data
mountPath: /var/lib/etcd
ports:
- name: etcd-server
containerPort: 2380
- name: etcd-client
containerPort: 2379
readinessProbe:
exec:
command:
- /bin/bash
- -c
- /usr/local/bin/etcdctl endpoint health
initialDelaySeconds: 10
periodSeconds: 10
timeoutSeconds: 10
volumeClaimTemplates:
- metadata:
name: data
spec:
accessModes: [ "ReadWriteOnce" ]
resources:
requests:
storage: 2Gi
Изменилось не только имя, но и команда запуска. Давайте чуть подробнее поговорим о том, что именно в ней поменялось:
Добавился флаг
--initial-cluster-state existing: он указывает, что мы bootstrap’им участников существующего кластера, а не инициируем новый (подробнее читайте в документации).Изменился параметр
--initial-advertise-peer-urls, так как мы изменили имя StatefulSet«а.И главное: изменился флаг
--initial-cluster— в нем мы перечисляем всех существующих участников кластера, включая новую ноду etcd-main-0.
Ноды добавляются по одной, поэтому при первом деплое ключ replicasдолжен иметь значение 1.
Командой etcdctl endpoint statusпроверяем, что новая нода успешно присоединилась к кластеру:

Добавляем еще 2 ноды. Процедура абсолютно идентична той, что описана выше. Давайте зафиксируем шаги, которые нужно сделать:
Добавить новую ноду в кластер командой
etcdctl member add.Отредактировать новый StatefulSet: добавить одну реплику и изменить ключ
--initial-cluster, внеся туда новую ноду.Дождаться успешного присоединения ноды к кластеру etcd.
Важное пояснение: нельзя использовать kubectl scale statefulset, так как помимо изменения количества реплик нужно поменять и параметр в команде запуска в новом StatefulSet«е.
Проверим состояние кластера:

Если все прошло успешно, можно переключить лидера etcd на одну из новых нод. Сделать это можно с помощью etcdctl:
etcdctl move-leader 60ce6ed30863955f --endpoints=etcd-0:2379,etcd-1:2379,etcd-2:2379,etcd-main-0:2379,etcd-main-1:2379,etcd-main-2:2379Шаг 5. Переключаем клиентов etcd
Теперь нужно переключить пользователей etcd на новые endpoint«ы. В нашем случае пользователем являлся кластер PostgreSQL под управлением Patroni (подробное описание процесса выходит за рамки этой статьи).
Шаг 6. Удаляем старые ноды из кластера etcd
Пришел черед удалить старые ноды. Удалять их, как и добавлять, следует по одной, во избежание потери кворума кластера. Рассмотрим процесс пошагово:
kubectl scale sts etcd –replicas=2etcdctl member remove e93f626220dffb --endpoints=etcd-0:2379,etcd-1:2379,etcd-main-0:2379,etcd-main-1:2379,etcd-main-2:2379etcdctl endpoint healthВажный нюанс: на этом этапе не стоит удалять Persistent Volumes от старых подов, если это возможно. Они могут пригодиться, если потребуется откат к исходному состоянию.
После удаления всех старых нод поправим команду запуска etcd в StatefulSet«е в новом кластере Kubernetes (уберем оттуда эти ноды):
Шаг 7. Удаляем оставшиеся ресурсы etcd в старом кластере Kubernetes
После того как новый кластер etcd «отстоялся» и мы убедились в его работоспособности, удаляем ресурсы, оставшиеся от старого etcd (Persistent Volume, Service и др.). На этом миграция завершена.
Заключение
Способ миграции etcd между облачными кластерами Kubernetes, который мы описали в статье, не является самым очевидным. Но он поможет осуществить переключение между кластерами без простоя и сделать это весьма оперативно. А упростить управление кластерами k8s поможет наша Kubernetes-платформа Deckhouse.
P.S.
Читайте также в нашем блоге:
