Метрики команды разработки
Введение
Заказчику задачи в конечном счёте всё равно, какой методологией управления разработкой пользуется команда исполнителей — точная дата получения результата для него важнее.
Чтобы называть эту дату более обоснованно, необходимо понимать, как на самом деле работает команда: сколько поставляет задач, как долго проходит процесс анализа задачи перед взятием в работу, на каких этапах в целом происходит «застревание» задачи.
TL; DR — Вот ссылка на репозиторий с python-кодом, который считает метрики из статьи по jira и рисует графики для наглядности (merge requests are very welcome).
Ниже — описание метрик и способы их расчёта.
Disclaimer: для расчёта использовались обезличенные данные нескольких компаний с примесью синтетики.
Предлагаемый подход
Прежде всего надо выделить то множество задач, для которого будут рассчитаны метрики.
Также следует определить множество статусов, которые мы будет считать «финальными». Например, задача может быть как выполнена, так и отклонена — оба статуса в определённом смысле «финальные».
Для каждой задачи из выделенного множества нам будут интересны следующие свойства:
Текущий статус
Дата создания
Дата первого изменения статуса (считаем датой начала работы над задачей)
Дата последнего перехода в финальный статус (считаем датой окончания работы над задачей)
Время нахождения в каждом статусе
Время нахождения на каждом из исполнителей
@dataclass
class Issue:
key: str
status: str
created_at: datetime
first_status_change_at: datetime = None
last_finish_status_at: datetime = None
doers_x_periods: dict[str, timedelta] = None
statuses_x_periods: dict[str, timedelta] = None
@property
def is_done(self) -> bool:
return self.last_finish_status_at is not None
@property
def lead_time(self) -> timedelta | None:
if not self.last_finish_status_at:
return None
return self.last_finish_status_at - self.created_at
@property
def cycle_time(self) -> timedelta | None:
if self.first_status_change_at and self.last_finish_status_at:
return self.last_finish_status_at - self.first_status_change_at
return None
Метрики
Throughput
Сколько задач делает команда разработки за определённый период времени?
Пример кода с разбивкой результатов по календарным неделям:
from collections import defaultdict
from metrics.entity import Issue
def get_throughput(list_of_issues: list[Issue]) -> dict[str, int]:
tmp = defaultdict(int)
for issue in list_of_issues:
if issue.is_done:
key = issue.last_finish_status_at.strftime("%YW%V") # example: 2024W03
tmp[key] += 1
return dict(tmp)Пример вывода:
{
...
'2022W08': 2,
'2022W09': 8,
'2022W10': 5,
'2022W11': 4,
'2022W12': 9,
'2022W13': 12
...
}Визуализация с линейной регрессией:

Видно, что delivery rate команды снижается
Lead Time
Сколько времени требуется, что довести задачу до конца?
Пример кода с установленной гранулярностью расчёта в один день и лимитом в 30 дней:
import typing as t
from metrics.entity import Issue
ONE_HOUR: Final[int] = 60 * 60
ONE_DAY: Final[int] = 24 * ONE_HOUR
CALC_LIMIT: Final[int] = 30
def get_lead_time(
list_of_issues: list[Issue],
timeslot: int = ONE_DAY,
limit: int = CALC_LIMIT,
) -> list[float]:
res = []
for issue in list_of_issues:
if issue.lead_time:
lead_time = max(1, issue.lead_time.total_seconds() // timeslot)
lead_time = min(lead_time, limit)
res.append(lead_time)
return res
Визуализация без лимита:

Cycle Time
Сколько времени проходит между началом работы над задачей и её завершением?
Пример кода:
import typing as t
from metrics.entity import Issue
ONE_HOUR: Final[int] = 60 * 60
ONE_DAY: Final[int] = 24 * ONE_HOUR
CALC_LIMIT: Final[int] = 30
def get_cycle_time(
self,
list_of_issues: list[Issue],
timeslot: int = ONE_DAY,
limit: int = CALC_LIMIT,
) -> list[float]:
res = []
for issue in self.repo.all():
if issue.cycle_time:
cycle_time = max(1, issue.cycle_time.total_seconds() // timeslot)
cycle_time = min(cycle_time, limit)
res.append(cycle_time)
return resВизуализация с лимитом:

Queues
Сколько времени задачи проводят на каждом этапе работы?
На мой взгляд — наиболее важная метрика, потому что позволяет определить узкие места процесса разработки.
import typing as t
from metrics.entity import Issue
ONE_HOUR: Final[int] = 60 * 60
ONE_DAY: Final[int] = 24 * ONE_HOUR
CALC_LIMIT: Final[int] = 30
def get_queue_time(
list_of_issues: list[Issue],
timeslot: int = ONE_DAY,
limit: int = CALC_LIMIT,
) -> dict[str, list[float]]:
tmp = defaultdict(list)
for issue in list_of_issues:
for status, td in issue.statuses_x_periods.items():
period_in_status = max(1, td.total_seconds() // timeslot)
period_in_status = min(period_in_status, limit)
tmp[status].append(period_in_status)
return dict(tmp)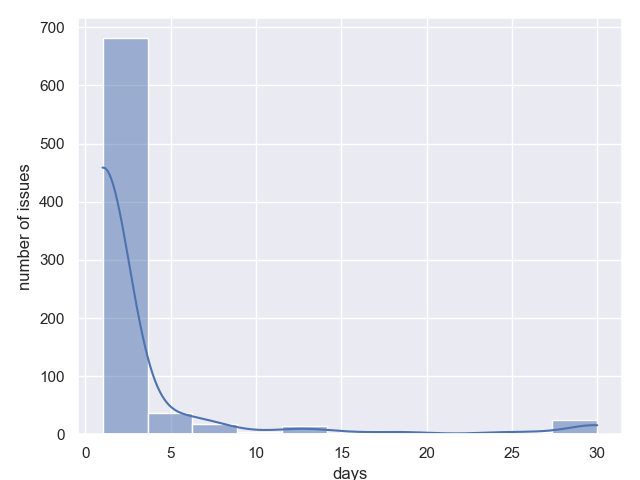
Статус «Анализ задачи»

Статус «Разработка»

Статус «Ожидает тестирования»

Статус «В тестировании»
Если наивно подходить к данным, то для цикла «анализ → разработка → ожидание тестирования → тестирование» наиболее ожидаемое затраченное время 2+2+1+2 = 7 рабочих дней.
Оффтоп: смешно, но конкретно для данной компании этот расчёт оказался верен в ~80% случаев. После этого были приняты меры, чтобы уменьшить время в очередях «Анализ» и «Ожидание тестирования». Теперь укладываются в 5 дней.
Наполнение данными
Теперь, когда готовы все структуры данных и алгоритмы их обработки, можно начать наполнять систему данными. Для примера будем использовать Jira как источник сырых данных.
Общий подход такой — для каждого источника сырых надо определить две составляющие:
Откуда брать сырые данные (api, filesystem, db, etc)?
Как приводить сырые данные в класс
Issue?
Примеры для решения обоих задач есть в репозитории, приводить их здесь, наверное, незачем.
Заключение
После получение статистики и метрик не самой дурной идеей кажется попытка собрать простую ML-модель, чтобы попытаться ответить на два главных (с точки зрения заказчика) вопроса:
Этим и займёмся в следующей статье.
