Массивно-параллельная база данных Greenplum — короткий ликбез
Для Hadoop и Greenplum есть возможность получить готовый SaaS. И если Хадуп — известная штука, то Greenplum (он лежит в основе продукта АrenadataDB, про который далее пойдёт речь) — интересная, но уже менее «на слуху».
Arenadata DB — это распределённая СУБД на базе опенсорсного Greenplum. Как и у других решений MPP (параллельной обработки данных), для массивно-параллельных систем архитектура облака далека от оптимальной. Это может снижать производительность аж до 30% (обычно меньше). Но, тем не менее, эту проблему можно нивелировать (о чём речь пойдёт ниже). Кроме того, стоит покупать такую услугу из облака, часто это удобно и выгодно в сравнении с развёртыванием собственного кластера.
В гайдах явно указывается on-premise, но сейчас многие осознают масштаб удобства облака. Все понимают, что некая деградация производительности будет, но это настолько всё равно супер по удобству и скорости, что уже есть проекты, где этим жертвуют на каких-то этапах вроде проверки гипотез.
Если у вас есть хранилище данных больше 1 ТБ и транзакционные системы — не ваш профиль по нагрузке, то ниже — рассказ, что можно сделать как вариант. Почему 1 ТБ? Начиная с этого объёма использование MPP эффективнее по соотношению производительность/стоимость, если сравнивать с классическими СУБД.
Когда использовать?
Когда классическая single-node СУБД по архитектуре не подходит для ваших объёмов. Частый случай — новое хранилище данных объёмом больше 1 ТБ. MPP СУБД сейчас в тренде, и Greenplum — один из лучших на рынке по соответствию современным задачам. Особенно с учётом его опенсорсности. Есть ещё куча проприетарных систем с большим количеством фич из коробки: Террадата, Сап Хана, Экзадата, Вертика. Поэтому, если вы не можете позволить себе ананасов и рябчиков, то берите сливу.
Второй случай — когда у вас есть уже существующее хранилище данных на чём-то универсальном типа Оракла или Постгресса, но пользователи регулярно жалуются на медленные отчёты. И когда стоят новые задачи типа Big Data — когда пользователи хотят все данные и сразу, а что они с ними будут делать, они предсказать не могут. Есть много ситуаций, когда на действующем бизнесе нужны отчёты, которые актуальны только один день, а за сутки они не успевают рассчитаться. То есть нужных данных в принципе нет. В этом случае тоже удобно брать базы MPP и пробовать с SaaS в облаке.
Третий случай — когда у вас кто-то следует моде на Хадуп и решает стандартные задачи пакетной обработки структурированных данных, но не очень хорошо собрал кластер. Мы часто видим, что технология применяется немного и даже совсем не так, как должна. Например, на Хадупе не надо строить реляционную базу данных. Тем не менее, если в вашем Хадупе вдруг нет обработки в реальном времени либо она предполагалась, но админ и разработчик в ужасе сбежали, то тоже можно смотреть в сторону Greenplum в облаке: поддержка будет очень простой при сохранении возможности обработки огромных массивов данных.
Почему мало кто пробует?
Любые MPP СУБД требуют много мощностей. То есть много железа. По факту люди боятся пробовать до уровня proof of concept просто из-за цены входа. Не могут этого физически сделать. Одна из основных идей нашего SaaS — дать возможность поиграть со всем этим, не покупая кластер железа.
И регулярно встречаем заказчиков, которые говорят, что самостоятельно сопровождать, эксплуатировать и так далее не хотелось бы. А хотелось бы аутсорс. Это система аналитическая, и чаще всего она business-critical, но не mission-critical. Многие на Западе аутсорсят, у нас тоже началось недавно.
Что лучше всего делать на MPP?
Классическое корпоративное хранилище данных: по всем источникам данных вы получаете инкрементальные данные, а дальше из этого строятся витрины пользователям. Пользователи над этими витринами строят свои отчёты. «Я каждый день хочу видеть, как идут дела в бизнесе» — это оно.
Ещё пара слов про облачное решение
Раньше считалось, что инфраструктуры подобного плана слабо предназначены для облаков. Но на деле всё больше и больше заказчиков выходят в облака. Работа требует высокой производительности, так как в ней крутится очень много больших аналитических запросов, которые потребляют много ЦПУ, требуют много памяти и предъявляют высокие требования к дискам и сетевой инфраструктуре. Как результат, когда клиенты разворачивают распределённые СУДБ в облаке, они могут столкнуться с несколькими проблемами.
Первая — это недостаточная производительность сети. Так как это всё в облаке крутится в виртуальной среде, на одном гипервизоре может быть много машин. Виртуальные машины могут быть разбросаны по разным гипервизорам. Более того, в какие-то моменты они могут быть вообще разбросаны по разным дата-центрам, супервизоры на них могут крутиться виртуально. И из-за этого очень сильно страдает сеть. При переработке миллиарда записей в таблице нужно, скажем, 10 серверов, и он гоняет эти данные между всеми серверами. Внутри работает подвид, и даже внутри одного сервера работает много таких подвидов. Их может быть 10–20, и вот они все начинают во время выполнения запроса гонять данные по сети. Сеть падает, как озимые. Какой вывод из этого можно сделать? Используйте облака с высокой пропускной способностью каналов, например, Облако КРОК, которое на Infiniband даёт 56 Гб.
Вторая проблема — на всё это очень косо смотрят файрволы и DDoS-защиты. Накололись, решили. Перед использованием рекомендуем запланировать лишний час на перепроверку всех настроек.
Ещё важны незаметная живая миграция и обновление. Чтобы перетащить машину на другой гипервизор, а потом обратно, нужно не потерять пакеты. Необходимо шаманить с настройками в итоге. К примеру, мы почти сразу полезли за увеличением буфера обмена. MTU подняли до «джамбофрейма» 9 000.
Конечно, диски, которые HDD. Они очень не любят такую запись, особенно когда это очень-очень случайные сектора в очереди с остальными запросами. Решили разделением хранилища на сегменты: один — только для Greenplum, другой — общий. Нужно это для ситуаций, когда с десяток заказчиков разворачивает параллельно инсталляции Greenplum. MPP максимально утилизируют именно дисковую подсистему, облачные сервисы имеют интерконнект к хранилищу, и производительность там почти такая же, как у канала. Если все клиенты облака не делают расчёт MPP, то можно получить очень существенный выигрыш. Эффективное распределение мощностей в таких нагрузках очень хорошо работает.
И из-за собственной архитектуры Greenplum в облаке показывает себя по КПД лучше, чем Redshift, BigQuery и Snowflake.
Как выглядит развёртывание:
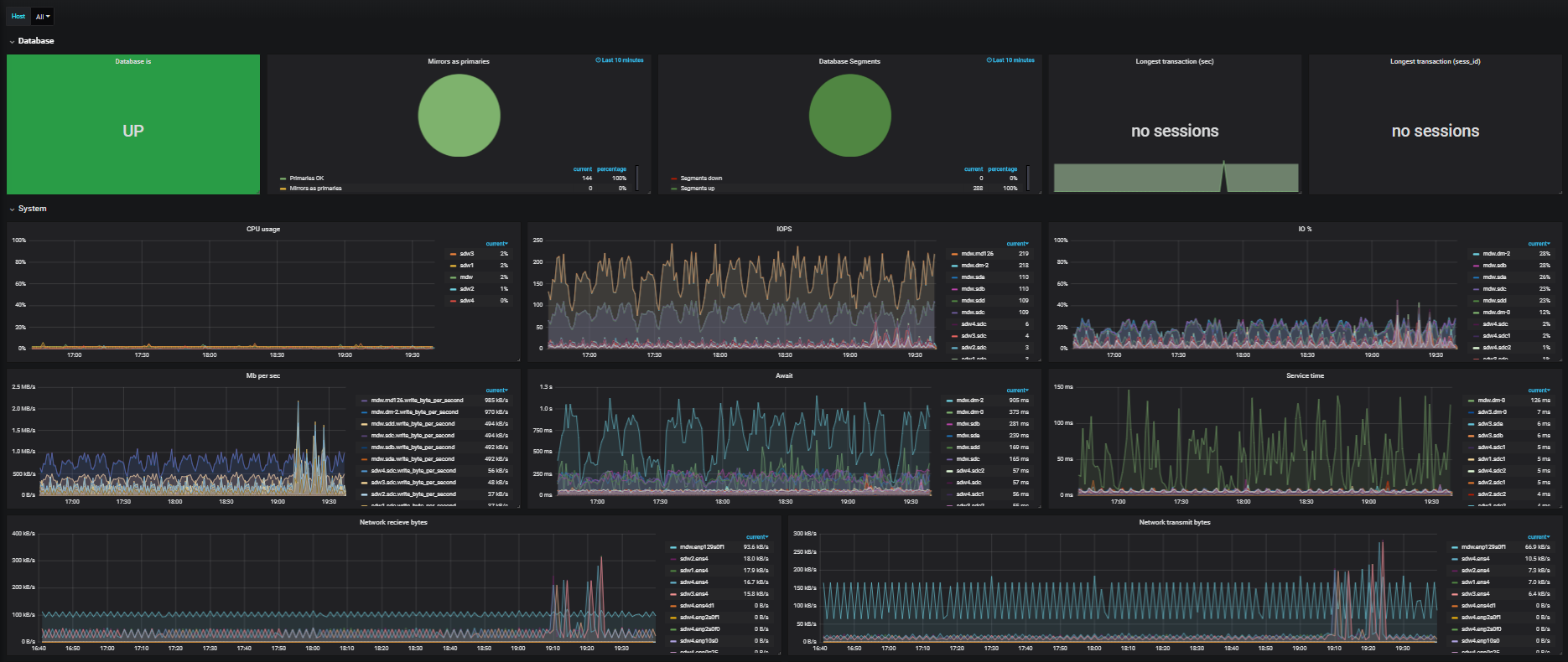
Вот так:
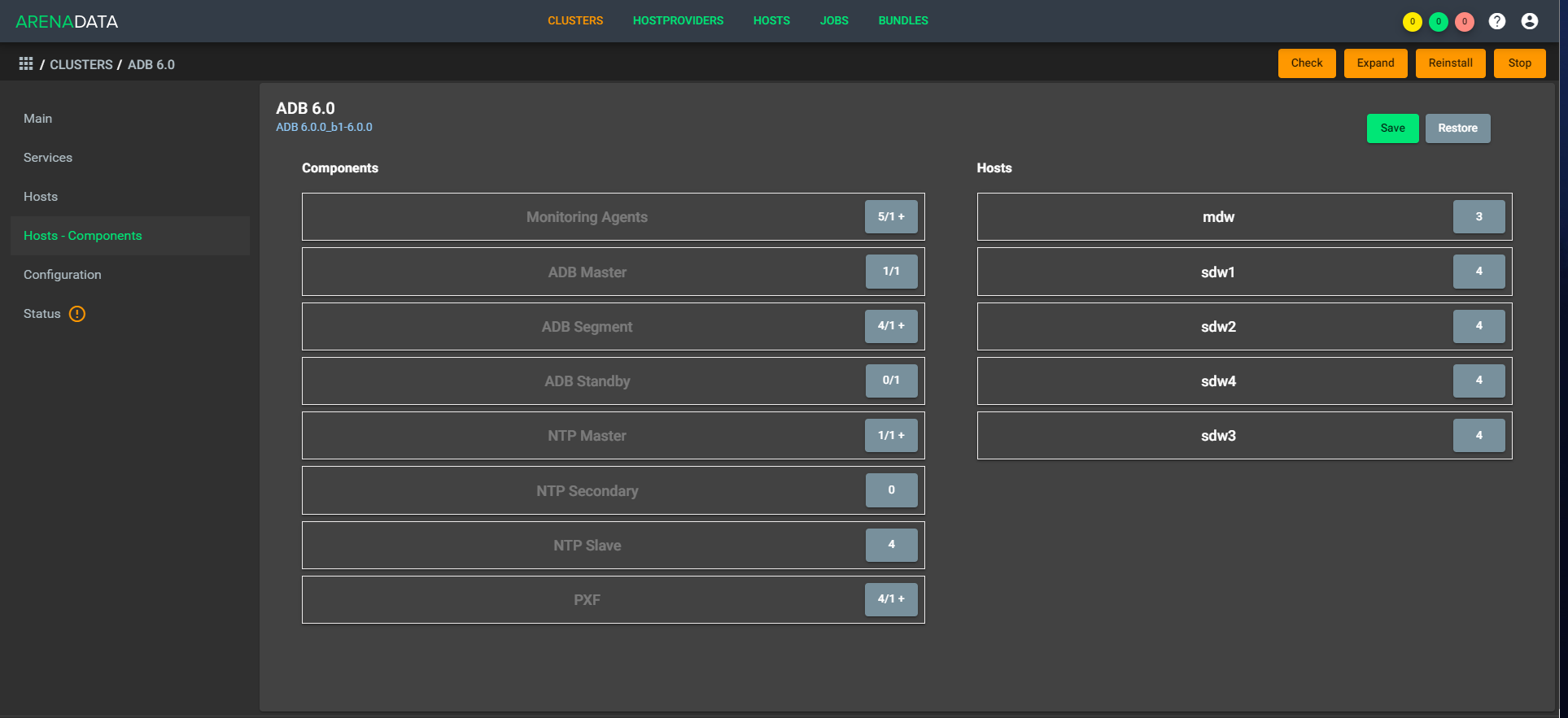
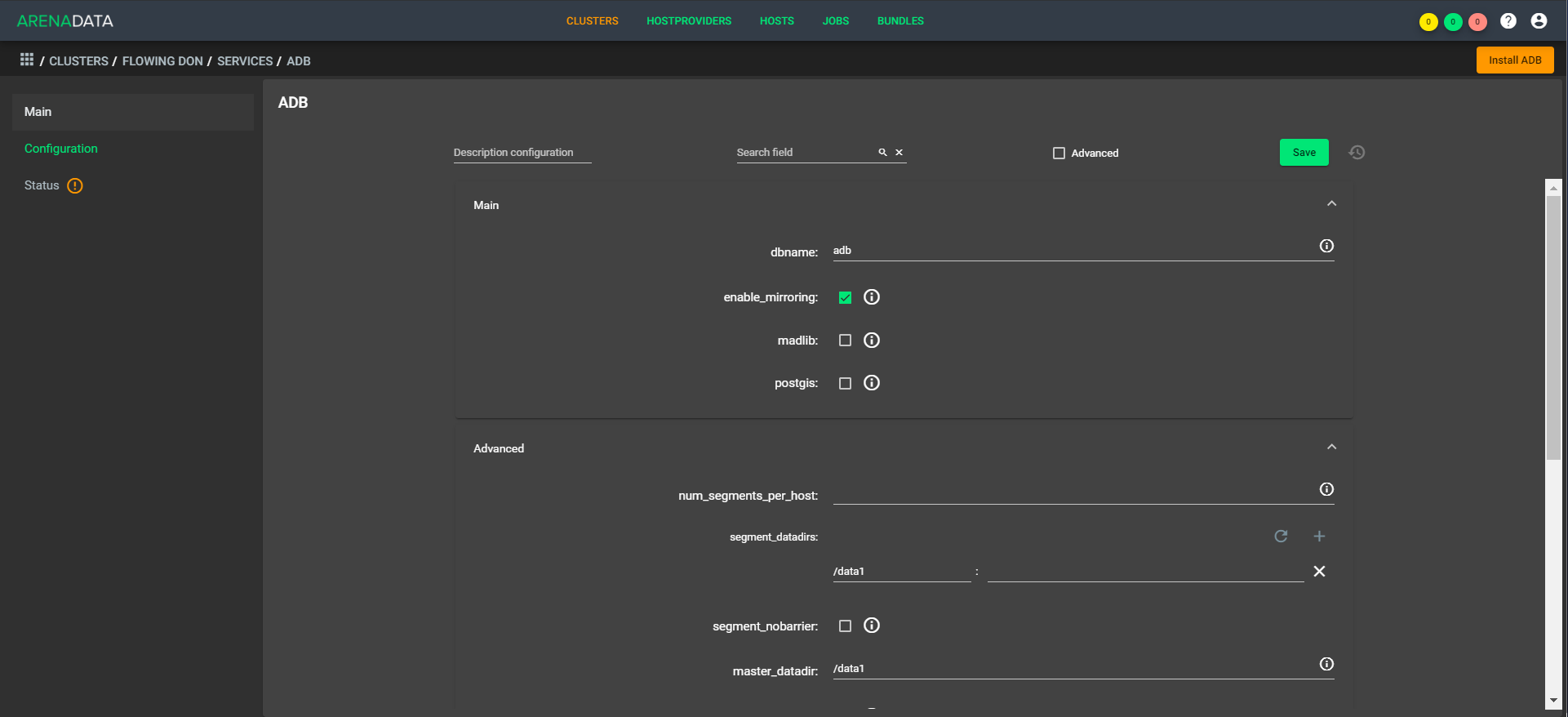
Архитектура «дышащая», то есть можно быстро развернуть и сжать простым множителем в конфигурации. Как пример — днём у нас работает пять ЦПУ, а вечером у нас поднимается 1 000 обработчиков, и работает десять ЦПУ. При этом не нужно делать баланс данных, потому что они лежат внутри одного хранилища. Из коробки доступно расширение, быстрое сжатие ещё нужно немного допиливать.
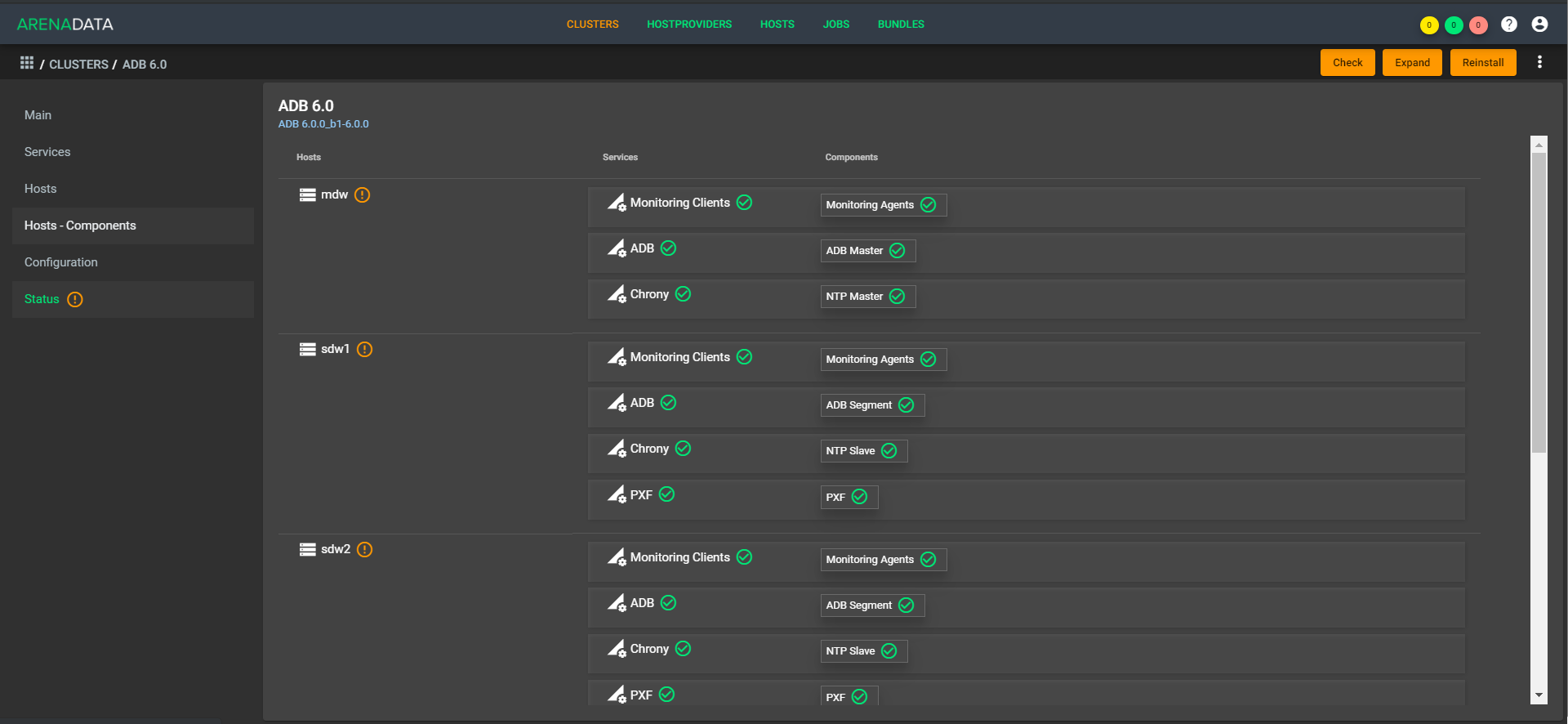
Сейчас для заказчика есть единая точка управления. Он приходит в одно место, кидает туда запрос вроде: «Разверните мне кластерный план на таких-то машинах», и наша поддержка развёртывает машины в облаке (у нас или у заказчика), располагает там Greenplum, запускает, настраивает и все настройки делает. То же самое касается мониторинга, управления, обновления. По мере автоматизации это будет уходить с поддержки на кнопки в личном кабинете.
Мы сначала поняли всё удобство такого подхода на внутренних проектах, а потом начали давать как SaaS заказчикам. У нас глубокая интеграция с S3 — это позволяет использовать Greenplum как систему с разделёнными слоями вычисления и хранения, или использовать S3 для бекапов, а Greenplum как ядро в составе КХД в облаке. Есть гибкое развёртывание сред для enterprise с помощью API КРОК и API ADCM.
