Машинное обучение в инвестиционной компании: классифицируем обращения в техническую поддержку
В теории использование машинного обучения (ML) помогает сократить участие человека в процессах и операциях, перераспределять ресурсы и уменьшить затраты. Насколько это работает в условиях конкретной компании и сферы деятельности? Как показывает наш опыт — работает.
На определенном этапе развития мы в компании «ВТБ Капитал» столкнулись с острой необходимостью сократить время на обработку запросов в техническую поддержку. После анализа возможных вариантов было решено применить ML-технологию для категоризации обращений от бизнес-пользователей Calypso, ключевой инвестиционной платформы компании. Быстрая обработка таких запросов крайне важна для высокого качества ИТ-сервиса. Помочь в решении этой задачи мы попросили наших ключевых партнеров — компанию EPAM.

Итак, запросы в службу поддержки поступают по e-mail и трансформируются в тикеты в Jira. Затем специалисты поддержки вручную классифицируют их, расставляют приоритеты, вносят дополнительные данные (например, из какого отдела и локации поступил запрос, к какому функциональному блоку системы он относится) и назначают исполнителей. Всего используется порядка 10 категорий запросов. Это, к примеру, может быть просьба проанализировать какие-либо данные и предоставить автору запроса информацию, добавить нового пользователя и т.д. Причем действия могут быть как стандартными, так и нестандартными, поэтому очень важно сразу правильно определить тип запроса и назначить выполнение на нужного специалиста.
Важно отметить: «ВТБ Капитал» хотел не только разработать прикладное технологическое решение, но и оценить возможности различных представленных на рынке инструментов и технологий. Одна задача, два разных подхода, две технологические платформы и три с половиной недели: каким оказался результат?
Прототип №1: технологии и модели
Основой для разработки прототипа стал подход, предложенный командой EPAM, и исторические данные — порядка 10000 тикетов из Jira. Основное внимание было сосредоточено на 3 обязательных полях, которые содержит каждый такой тикет: Issue Type (тип проблемы), Summary («шапка» письма или тема запроса) и Description (описание). В рамках проекта планировалось решить задачу анализа текста из полей Summary и Description и по его результатам автоматически определять тип запроса.
Именно особенности текста в этих двух полях тикета стали главной технической сложностью при анализе данных и разработки моделей ML. Так, поле Summary может содержать достаточно «чистый» текст, но включающий в себя специфические слова и термины (как пример — CWS reports not running). Для поля Description, напротив, характерен более «грязный» текст с обилием специальных символов, обозначений, бэкслэшей и остатков нетекстовых элементов:
Dera colleagues,
Could you please explain to us what is the difference between FX_Opt_delta_all and FX_Opt_delta_cash risk measures?
!01D39C59.62374C90_image001.png! )
Кроме того, в тексте нередко сочетаются несколько языков (преимущественно, естественно, русский и английский), могут встречаться бизнес-терминология, рунглиш и программистский сленг. И конечно, поскольку запросы нередко пишутся в спешке, то в обоих случаях не исключены опечатки и орфографические ошибки.
Технологии, выбранные командой EPAM, включали в себя Python 3.5 для разработки прототипа, NLTK + Gensim + Re для процессинга текста, Pandas + Sklearn для анализа данных и разработки моделей и Keras + Tensorflow как фреймворк глубокого обучения и бэкэнд.
С учетом возможных особенностей изначальных данных для извлечения признаков из поля Summary были построены три представления: на уровне символов, сочетания символов и отдельных слов. Каждое из представлений использовалось как вход в рекурентную нейронную сеть.
В свою очередь в качестве представления для поля Description были выбраны статистика служебных символов (важна для обработки текста с использованием восклицательных знаков, слэшей и т.д.) и средние значения строк после фильтрации служебных символов и «мусора» (для компактного сохранения структуры текста), а также представление на уровне слов после фильтрации стоп-слов. Каждое представление выступало в качестве входа в нейронную сеть: статистика в полносвязную, построчное и на уровне слов — в рекурентную.
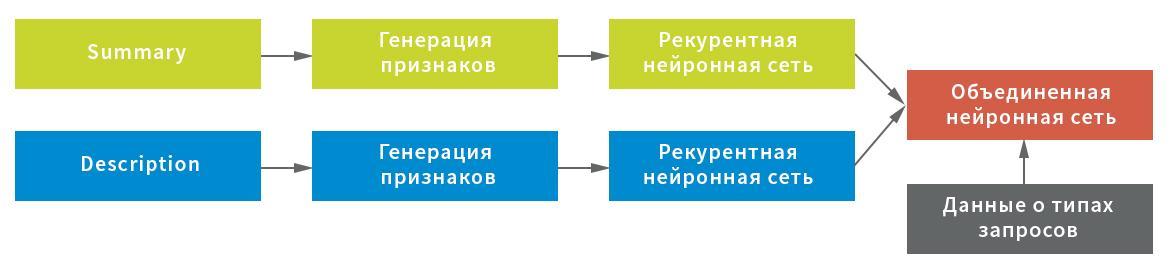
В данной схеме в качестве рекурентной сети использовалась нейронная сеть, состоящая из двунаправленного (bidirectional) GRU слоя с рекурентным и обычным dropout«ом, пулинга скрытых состояний рекурентной сети с применением слоя GlobalMaxPool1D и полносвязного (Dense) слоя с дропаутом. Для каждого из входов строилась своя «голова» нейронной сети, а затем они объединялись через конкатенацию и замыкались на целевую переменную.
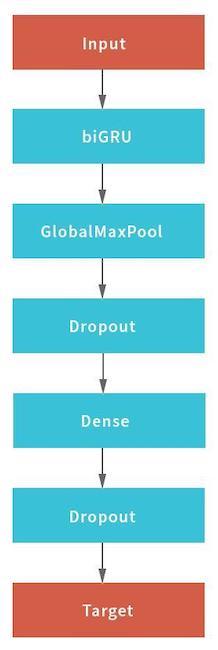
Для получения финального результата объединенная нейронная сеть возвращала вероятности принадлежности конкретного запроса к каждому из типов. Данные были разбиты на пять блоков без пересечений: модель строилась по четырем из них и проверялась на пятом. Так как каждому запросу может быть присвоен только один тип запроса, то правило для принятия решения было простым — по максимальному значению вероятности.
Прототип №2: алгоритмы и принципы работы
Второй прототип, в качестве базы для которого было взято предложение, подготовленное командой «ВТБ Капитал», представляет собой приложение на Microsoft .NET Core с библиотеками Microsoft.ML для реализации алгоритмов машинного обучения и Atlassian.Net SDK для взаимодействия с Jira через REST API. Основой для построения ML-моделей также стали исторические данные — 50000 Jira-тикетов. Как и в первом случае, машинное обучение охватило поля Summary и Description. Перед использованием оба поля также проходили «очистку». Из письма пользователя удалялись приветствия, подписи, история переписки и нетекстовые элементы (например, изображения). Кроме того, с помощью встроенного в Microsoft ML функционала из текста на английском языке вычищались стоп-слова, не имеющие значения для процессинга и анализа текста.
В качестве алгоритма машинного обучения был выбран Averaged Perceptron (бинарная классификация), который дополняется методом One Versus All для обеспечения многоклассовой классификации
Оценка результатов
Ни одна ML-модель не может (возможно, пока) обеспечить 100% точность результата.
Алгоритм Прототипа №1 обеспечивает долю правильной классификации (Accuracy), равную 0,8003 от общего количества запросов, или 80%. При этом значение аналогичной метрики в ситуации, когда предполагается, что правильный ответ будет выбран человеком из двух представленных решением, достигает 0,901, или 90%. Безусловно, встречаются кейсы, где разработанное решение работает хуже или не может дать правильный ответ — как правило, в силу очень короткого набора слов или специфичности информации в самом запросе. Свою роль играет и пока недостаточно большой объем тех данных, которые использовались в процессе обучения. По предварительной оценке увеличение объема обрабатываемой информации даст возможность повысить правильность классификации еще на 0.01–0.03 пункта.
Результаты лучшей модели в метриках точности (Precision) и полноты (Recall) оцениваются так:

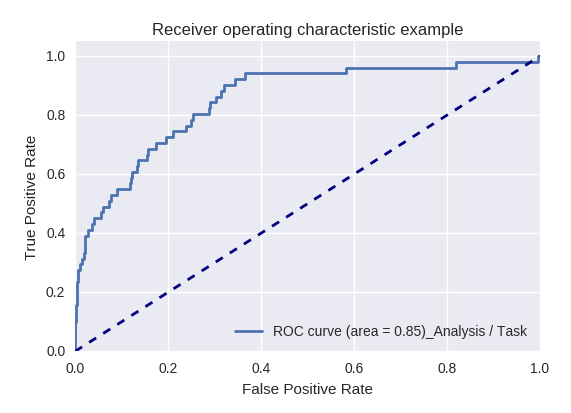
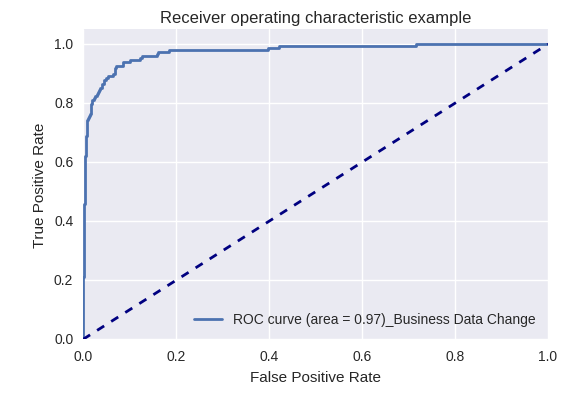
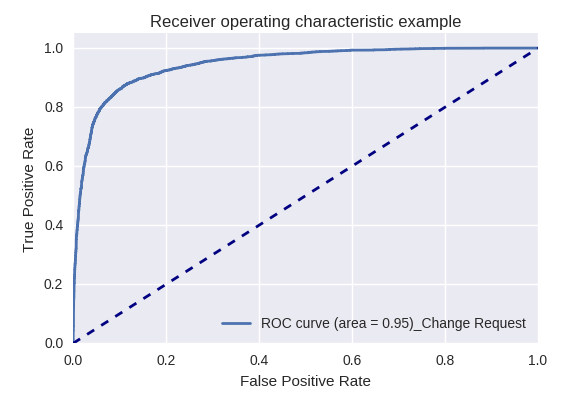
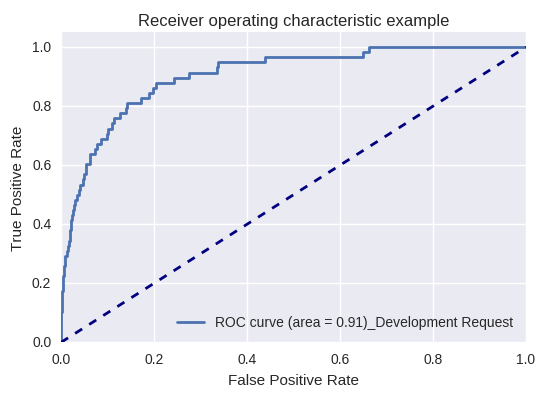
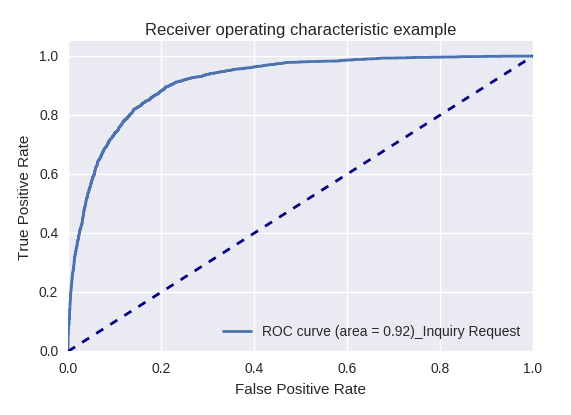
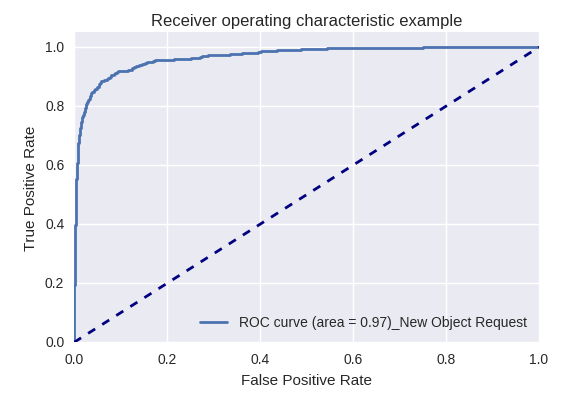
Если оценить качество модели в целом для различных типов запросов с помощью ROC-AUC-кривых, то результаты выглядят следующим образом.
Запросы на действие (Action Request) и анализ информации (Analysis/Task Request)

Запросы на изменение бизнес-данных (Business Data Request) и на изменения (Change Request)
Запросы на разработку (Development Request) и на предоставление информации (Inquiry Request)
Запросы на создание нового объекта (New Object Request) и добавление нового пользователя (New User Request)

Производственный запрос (Production Request) и запрос, связанный с поддержкой UAT/DEV (UAT/Dev Support Request)

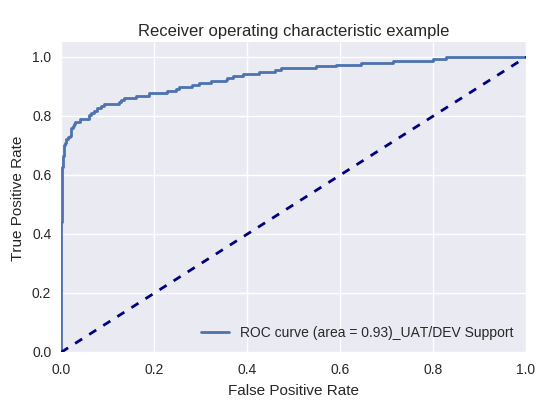
Примеры правильной и ошибочной классификации для некоторых типов запросов приведены ниже:
Запрос на предоставление информации (Inquiry Request)

Запрос на изменение (Change Request)
Correct classification
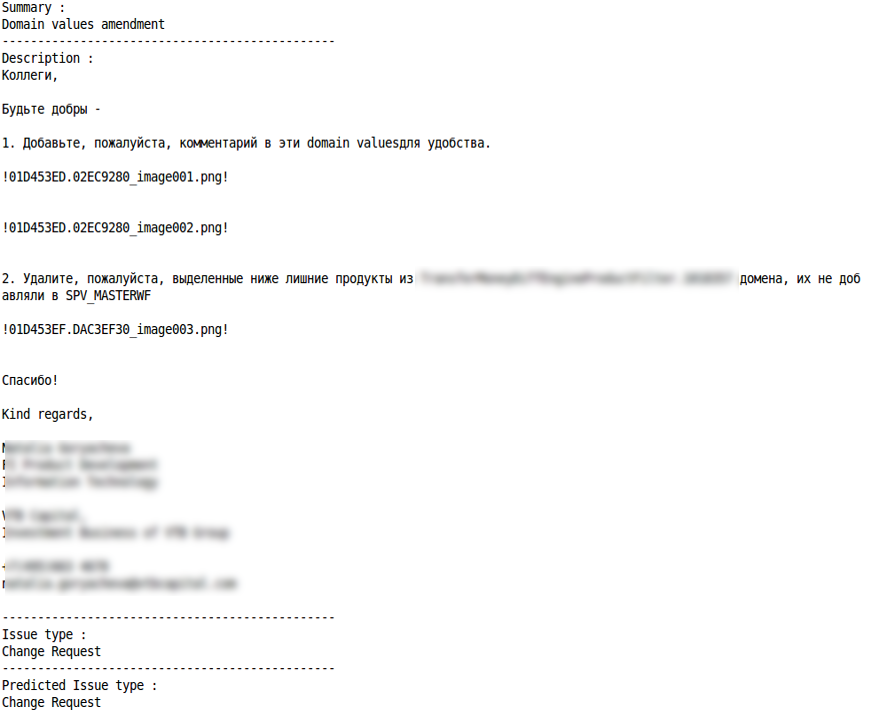
Misclassification

Запрос на действие (Action request)
Correct classification
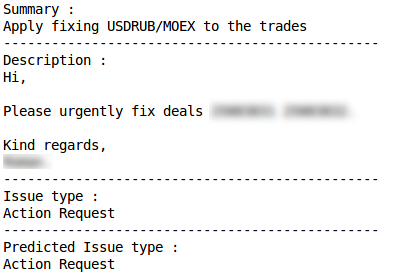
Misclassification
Производственный запрос (Production Issue)
Correct Classification
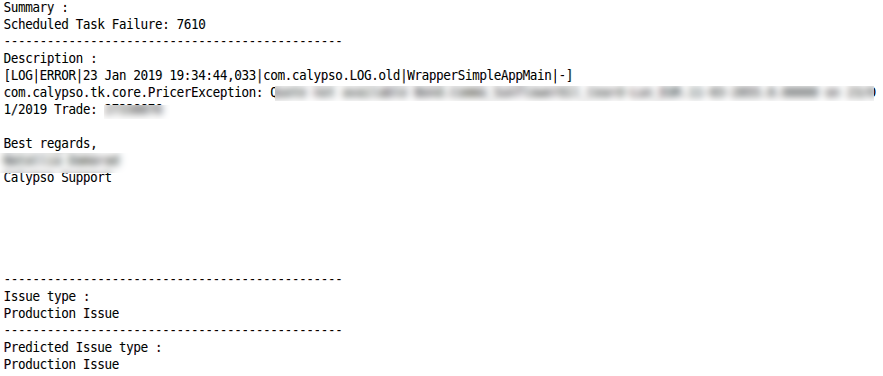
Misclassification
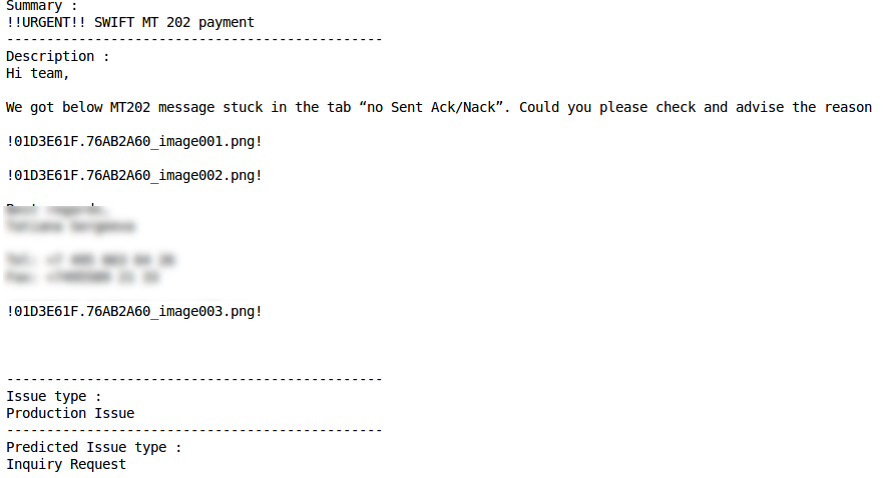
Хорошие результаты показал и второй прототип: ML примерно в 75% случаев правильно определяет тип запроса (метрика Accuracy). Возможность для улучшения показателя связана с повышением качества исходных данных, в частности, устранением случаев, когда одни и те же запросы были отнесены к разным типам.
Подводим итоги
Каждый из реализованных прототипов показал свою эффективность, и сейчас в опытно-промышленную эксплуатацию в «ВТБ Капитал» запущена комбинация из двух разработанных прототипов. Небольшой эксперимент с ML меньше чем за месяц и с минимальными затратами дал возможность компании познакомиться с инструментарием машинного обучения и решить важную прикладную задачу по классификации обращений пользователей.
Полученный разработчиками EPAM и «ВТБ Капитал» опыт — помимо применения для дальнейшего развития реализованных алгоритмов для обработки запросов пользователей — может быть переиспользован при решении самых разных задач, связанных с потоковой обработкой информации. Движение небольшими итерациями и охват одного процесса за другим позволяет постепенно осваивать и комбинировать различные инструменты и технологии, выбирая хорошо себя показавшие варианты и отказываясь от менее эффективных. Это интересно для ИТ-команды и в тоже время помогает получать результаты, важные для управления и бизнеса.
