Машинное обучение в Додо. Как запустить новое направление, если ты разработчик
По катом история о том, как в Додо появилось направление машинного обучения. Спойлер: это я его запустил. Хардкорных технических подробностей тут не будет, обязательно посвящу им отдельную статью. Сегодня больше про мотивацию и поддержку коллег.
Подготовка
Я сталкивался с темой машинного обучения трижды, пока из этого не получилось что-то стоящее.
Российская школа
Впервые я столкнулся с машинным обучением во ВШЭ — получал вторую вышку по направлению Big Data Systems, когда устраивался в Додо. Пройдя эту огромную хайповую тему по касательной, я не понимал, зачем вообще потратил три года жизни. И уж тем более не думал о том, как это может пригодиться в компании. Я тогда не был готов к этому вызову судьбы.
Чешский вояж
Второй раз столкнулся с этой темой в Праге, на закрытом хакатоне Майкрософт по машинному обучению. Вместе с ребятами из других компаний мы работали над задачей прогнозирования спроса в Додо в праздники и пиковые дни. Обратно я вернулся с готовой моделью, прогнозирующей спрос. Именно после этого хакатона появились мысли, что я смогу применять полученные знания в компании. Не тут-то было.
Ну есть у тебя моделька в Jupyter, и что? Как её использовать? Все попытки объяснить это бизнесу сталкивались суровой реальностью: и так понятно, что в праздники и пиковые дни будет много заказов. Взрослые пиццерии умеют прогнозировать продажи на основе данных прошлого года, а у новых хватало проблем и без этого. Мы отложили попытки заняться развитием машинного обучения. Но идея, что мы можем делать больше с данными, слишком прочно засела в голове и не хотела оттуда вылезать. Теперь я был готов к вызову, а компания нет.
Американская мечта
Третья встреча стала судьбоносной. К нашей команде попала сложная, но интересная задача: разработать модуль кастомизированной пиццы для США. Это когда ты можешь заказать пиццу с любым набором ингредиентов, создать свой рецепт. В проекте надо было проработать всё: от изменений в архитектуре базы данных до клиентского кода на сайте. Мы вцепились в задачу и разработали продукт, который я считаю настоящей победой. Главная оценка прилетела в слак от Алёны, нашего CEO в США.
Модуль мы сделали, но я видел проблему в масштабировании. Что, если функциональность появится не в одной-двух пиццериях в штатах, а в большой сети? Как управлять таким продуктом, планировать запасы? Я решил, что этот кейс может доказать необходимость развития машинного обучения в Додо. Я чувствовал, что на этот раз и я, и компания готовы к запуску нового направления.
Один на один с машинами
В фоновом режиме я занялся анализом продаж американской кастомизированной пиццы. С помощью алгоритмов кластеризации удалось показать, что в основе всех рецептов, созданных пользователями, лежат шесть базовых наборов ингредиентов плюс пара случайных. Даже простой отчет на основе этого алгоритма позволил бы в полуручном режиме прогнозировать продажи и планировать запасы. Благодаря отсутствию бюрократии и возможности перестраиваться на ходу нам дали зелёный свет, чтобы начать заниматься этим направлением.
Мы с техдиректором понимали и не раз обсуждали, что мне нужно будет выйти из текущей команды и заняться развитием нового направления, показать, что это нам необходимо. Мне нужно было в быстром темпе погружаться в новую сферу. Я понимал, что если не получится, есть два пути. Первый — вернуться к разработке в другой команде Додо. Второй — обновить резюме на HH и искать новую работу. Не хотелось ни того, ни другого. В этом состоянии я находился примерно три месяца, пока не зацепился за модуль дополнительных продаж.
Первый проект
Еще один спойлер: оказалось, что для запуска ML не нужно упарываться над чем-то сложным. Очевидно, не правда ли? Но это очень сложно понять в начале пути.
Модуль, который предлагает добавить в заказ дополнительный продукт, напрямую не управляется никем. Это значит, я могу творить с ним, что вздумается. Вишенка на торте — возможность увеличить продажи с помощью более персонализированных предложений. Раньше модуль работал просто: если в заказ была добавлена пицца, в дополнительных продажах отображалась категория напитков, если пицца и напиток, то десерты и так далее.
Небезразличие огромного количества людей опять показало, что я работаю в компании, где поддержка может быть оказана абсолютно всеми. Над данными и дополнительными предложениями я часами работал с коллегой из маркетинга. Нам удалось кластеризовать всех пользователей по их вкусовым предпочтениям и лояльности, для каждой группы составить статичные предложения на основе топовых продуктов в кластере.
Цифры и пруфы
Я прикрутил логирование дополнительных продуктов и запустил новые предложения на выборке из 2 млн пользователей.
Выборка из пользователей — это лишь малая часть продаж. Надо было двигаться в сторону неавторизованных и новых клиентов. Я перелопатил достаточно статей и литературы про Collaborative Filtering и разные алгоритмы предложений для пользователей. Выиграла идея рекомендаций на основе продуктов в корзине. Item-Based-рекомендации и косинусная мера сходимости легли в основу новой, пусть и простой, но уже работающей модели.
В декабре мы запустили модуль Item-Based рекомендаций. Статистика показала, что покупатели действительно могут быть заинтересованы в совершенно разных продуктах, а не только в напитках. Возможно, именно после этого в Додо поверили, что данные и развитие машинного обучения позволят конкурировать на перегруженных предложениями рынках в будущем.
Немного статистики.
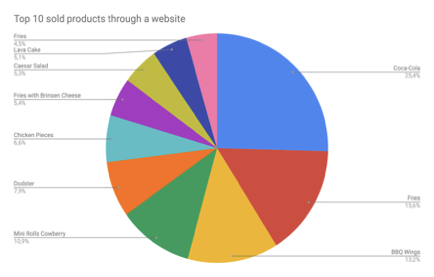
10 самых продаваемых продуктов на сайте

10 самых продаваемых продуктов мобильном приложении

Рост продаж по неделям
Технический трейлер
Ниже немного технических подробностей, почему в основе модели лежит косинусная мера схожести. Это превью к статье, которая выйдет через пару месяцев. Если вам не по душе математика — смело перепрыгивайте в последний раздел.
Исходная таблица внизу показывает количество заказов с приобретённым товаром каждого пользователя. Мы можем определить схожесть покупок одного пользователя с другим — для этого надо посчитать расстояние между векторами пользователей.
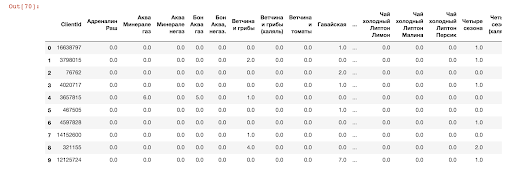
Таблица продаж продуктов по клиентам
Расстояние будет зависеть от выбранной метрики. Расчёт евклидова пространства включает в себя вес и величину вектора: 
где a и b это два разных вектора клиента из таблицы. Давайте посмотрим, как будет выглядеть это расстояние на абстрактном примере.
Предположим, мы рассматриваем историю трех клиентов — a, b и c. Построим матрицу их покупок.
Рассчитав евклидовы расстояния между клиентами, мы получим следующие значения:
d (a, b) = 16,22;
d (b, c) = 13,38;
d (a, c) = 13,64.
Эти значения показывают, что наиболее близки друг к другу клиенты b и c. Но если посмотреть на исходные данные, картина складывается противоположная. Клиенты a и b предпочитают заказывать больше Пепперони и периодически другие продукты, а клиент c предпочитает пиццу Супреме. Можем сделать вывод, что величина вектора имеет негативный эффект для расчета расстояний между клиентами. Косинусная мера схожести как раз учитывает угол между векторами, отбрасывая значимость величины вектора: 
Рассчитав по этой формуле расстояние, получим:
d (a, b) = 0,9183;
d (b, c) = 0,5848;
d (a, c) = 0,7947;
Мы видим, что клиенты a и b находятся ближе друг к другу. Они предпочитают один набор товаров без учета разницы количества сделанных заказов. Такая логика сходится с нашим экспертным мнением и позволяет предположить, что предпочтения клиентов a и b наиболее близки друг к другу.
Это трейлер, подробности через два месяца.
Поиск своего
Сейчас мы находимся на стадии формирования команды, в которой будут специалисты по организации хранения данных, разработке моделей машинного обучения, вывода их в продакшн. Но главное, мы теперь лучше понимаем, зачем нам нужно всё это. Мы вольны делать по-настоящему крутые вещи, от организации интеллектуальной системы логистики и планирования запасов до фантастических идей автоматизации пиццерий с использованием технологий Computer Vision.
Верьте в себя и свои силы, даже если результат не виден на горизонте. Хотелось бы завершить статью чужой мыслью — цитатой Макса Вебера с его доклада перед студентами Мюнхенского университета: «одной только тоской и ожиданием ничего не сделаешь, и нужно действовать по-иному — нужно обратиться к своей работе и соответствовать «требованию дня» — как человечески, так и профессионально. А данное требование будет простым и ясным, если каждый найдет своего демона и будет послушен этому демону, ткущему нить его жизни». Найдите своего.
