Kaggle: не можем ходить — будем бегать
Насколько сложна тема машинного обучения? Если Вы неплохо математически подкованы, но объем знаний о машинном обучении стремится к нулю, как далеко Вы сможете зайти в серьезном конкурсе на платформе Kaggle?

О площадке и конкурсе
Kaggle — это сообщество интересующихся ML (от новичков до крутых профи) и площадка для проведения конкурсов (часто с внушительным призовым фондом).
Чтобы сразу погрузиться во все прелести ML, решил сразу выбрать серьезный конкурс. Такой как раз был в наличии: Two Sigma: Using News to Predict Stock Movements. Суть конкурса в двух словах — предсказывать цену акций различных компаний на основе состояния актива и новостей, связанных с данным активом. Призовой фонд конкурса составляет 100 000 $, которые распределят между участниками, занявшими первые 7 мест.
Конкурс является особенным по двум причинам:
- это Kernels-only конкурс: обучать модели можно только в облаке Kaggle Kernels;
- окончательное распределение мест будет известно только через полгода после завершения приема решений; в течение этого времени решения будут предсказывать цены на текущую дату.
О задаче
По условию мы должны предсказывать уверенность ![$\hat{y}_{ti} \in [-1,1]$](https://habrastorage.org/getpro/habr/formulas/408/faa/39e/408faa39e905758341448a5f1dfb3560.svg) в том, что доходность актива вырастет. Доходность актива считается относительно доходности рынка в целом. Целевая метрика является кастомной — это не более привычные RMSE или MAE, а коэффициент Шарпа, который в данном случае считается так:
в том, что доходность актива вырастет. Доходность актива считается относительно доходности рынка в целом. Целевая метрика является кастомной — это не более привычные RMSE или MAE, а коэффициент Шарпа, который в данном случае считается так:

где ,
,  — доходность актива i относительно рынка для дня t на 10-дневном горизонте,
— доходность актива i относительно рынка для дня t на 10-дневном горизонте,  — булева переменная, показывающая, включается ли i-й актив в оценку для дня t,
— булева переменная, показывающая, включается ли i-й актив в оценку для дня t,  — среднее значение
— среднее значение  ,
,  — среднеквадратичное отклонение .
— среднеквадратичное отклонение .
Коэффициент Шарпа — это доходность с поправкой на риск, значения коэффициента показывают эффективность трейдера:
- меньше 1: плохая эффективность,
- 1 — 2: средняя, нормальная эффективность,
- 2 — 3: отличная эффективность,
- больше 3: идеальная.
- time(datetime64[ns, UTC]) — текущее время (в данных по движению рынка во всех строках 22:00 UTC)
- assetCode(object) — идентификатор актива
- assetName(category) — идентификатор группы активов для связи с данными новостей
- universe(float64) — булево значение, показывающее, будет ли учитываться этот актив в расчете score
- volume(float64) — объем торгов за день
- close(float64) — цена закрытия для данного дня
- open(float64) — цена открытия для данного дня
- returnsClosePrevRaw1(float64) — доходность от закрытия до закрытия за предыдущий день
- returnsOpenPrevRaw1(float64) — доходность от открытия до открытия за предыдущий день
- returnsClosePrevMktres1(float64) — доходность от закрытия до закрытия за предыдущий день, скорректированная относительно движения рынка в целом
- returnsOpenPrevMktres1(float64) — доходность от открытия до открытия за предыдущий день, скорректированная относительно движения рынка в целом
- returnsClosePrevRaw10(float64) — доходность от закрытия до закрытия за предыдущие 10 дней
- returnsOpenPrevRaw10(float64) — доходность от открытия до открытия за предыдущие 10 дней
- returnsClosePrevMktres10(float64) — доходность от закрытия до закрытия за предыдущие 10 дней, скорректированная относительно движения рынка в целом
- returnsOpenPrevMktres10(float64) — доходность от открытия до открытия за предыдущие 10 дней, скорректированная относительно движения рынка в целом
- returnsOpenNextMktres10(float64) — доходность от открытия до открытия за следующие 10 дней, скорректированная относительно движения рынка в целом. Это значение мы и будем предсказывать.
- time(datetime64[ns, UTC]) — время в UTC доступности данных
- sourceTimestamp(datetime64[ns, UTC]) — время в UTC публикации новости
- firstCreated(datetime64[ns, UTC]) — время в UTC первой версии данных
- sourceId(object) — идентификатор записи
- headline(object) — заголовок
- urgency(int8) — типы новостей (1: alert, 3: article)
- takeSequence(int16) — не совсем понятный параметр, номер в некоторой последовательности
- provider(category) — идентификатор провайдера новости
- subjects(category) — список кодов тем новостей (может быть географический признак, событие, сектор промышленности и т.д.)
- audiences(category) — список кодов аудиторий новости
- bodySize(int32) — кол-во символов в теле новости
- companyCount(int8) — кол-во компаний, явно упомянутых в новости
- headlineTag(object) — некий тэг заголовка от компании Thomson Reuters
- marketCommentary(bool) — признак, что новость касается общих условий рынка
- sentenceCount(int16) — кол-во предложений в новости
- wordCount(int32) — кол-во слов и знаков препинания в новости
- assetCodes(category) — список активов, упомянутых в новости
- assetName(category) — код группы активов
- firstMentionSentence(int16) — предложение, в котором впервые упоминается актив:
- relevance(float32) — число от 0 до 1, показывающее релевантность новости относительно актива
- sentimentClass(int8) — класс тональности новости
- sentimentNegative(float32) — вероятность, что тональность отрицательная
- sentimentNeutral(float32) — вероятность, что тональность нейтральная
- sentimentPositive(float32) — вероятность, что тональность положительная
- sentimentWordCount(int32) — кол-во слов в тексте, которые относятся к активу
- noveltyCount12H(int16) — «новизна» новости за 12 часов, рассчитывается относительно предыдущих новостей о данном активе
- noveltyCount24H(int16) — то же, за 24 часа
- noveltyCount3D(int16) — то же, за 3 дня
- noveltyCount5D(int16) — то же, за 5 дней
- noveltyCount7D(int16) — то же, за 7 дней
- volumeCounts12H(int16) — объем новостей о данном активе за 12 часов
- volumeCounts24H(int16) — то же, за 24 часа
- volumeCounts3D(int16) — то же, за 3 дня
- volumeCounts5D(int16) — то же, за 5 дней
- volumeCounts7D(int16) — то же, за 7 дней
Задача по сути является задачей бинарной классификации, то есть, мы предсказываем бинарный признак, будет доходность расти (1 класс) или уменьшаться (0 класс).
Об инструментах
Kaggle Kernels — облачная вычислительная платформа, поддерживающая совместную работу. Поддерживаются kernel«ы следующих типов:
- Python Script
- R Script
- Jupyter Notebook
- RMarkdown
Каждый kernel запускается в своем docker-контейнере. В контейнере установлено большое количество пакетов, список для питона можно посмотреть здесь. Технические спецификации такие:
- CPU: 4 ядра,
- RAM: 17 ГБ,
- диск: 5 ГБ постоянных и 16 ГБ временных,
- максимальное время работы скрипта: 9 часов (на момент старта конкурса было 6 часов).
Также в Kernels доступны и GPU, однако в данном конкурсе использование GPU было запрещено.
Keras — высокоуровневый нейросетевой фреймворк, работающий поверх TensorFlow, CNTK или Theano. Очень удобный и понятный API, и есть возможность добавлять свои топологии сетей, функции потерь и всякое другое, используя API бэкенда.
Scikit-learn — крупная библиотека алгоритмов машинного обучения. Полезный источник алгоритмов предобработки и анализа данных для использования вместе с более специализированными фреймворками.
Валидация модели
Прежде чем отправлять модель на оценку, нужно как-то проверить локально, насколько хорошо она работает, — то есть, придумать способ локальной валидации. Я попробовал следующие подходы:
- перекрестная валидация vs простое пропорциональное разбиение на тренировочное/тестовое множества;
- локальный расчет коэффициента Шарпа vs ROC AUC.
В итоге наиболее близкие к конкурсной оценке результаты, как ни странно, показало сочетание пропорционального разбиения (эмпирически подобрал разбиение 0.85/0.15) и AUC. Вероятно, перекрестная валидация не очень подходит, так как поведение рынка сильно отличается на ранних этапах тренировочных данных и на оценочном периоде. Почему AUC сработал лучше, чем коэффициент Шарпа — вообще не берусь сказать.
Первые попытки
Так как задача заключается в предсказании временного ряда, то первым было опробовано классическое решение — рекуррентная нейросеть (RNN), а точнее, её варианты LSTM и GRU.
Главный принцип работы рекуррентных сетей заключается в том, что для каждого выходного значения на вход подается не один семпл, а целая последовательность. Из этого следует, что:
- нам нужна некоторая предобработка исходных данных — генерация этих самых последовательностей длиной t дней для каждого актива;
- модель на основе рекуррентной сети не сможет предсказать выходное значение, если нет данных за предыдущие t дней.
Я генерировал последовательности для каждого дня, начиная с t, поэтому при довольно больших t (от 20) полный набор тренировочных семплов перестал помещаться в память. Проблема решилась использованием генераторов, так как Keras умеет использовать генераторы в качестве входных и выходных наборов данных как для тренировки, так и для предсказания.
Первоначальная подготовка данных была максимально наивной: рыночные данные берем целиком плюс добавляем пару фич (день недели, месяц, номер недели в году), а данные новостей пока не трогаем вообще.
Первая модель использовала t = 10 и выглядела так:
model = Sequential()
model.add(LSTM(256, activation=act.tanh, return_sequences=True, input_shape=(data.timesteps, data.features)))
model.add(LSTM(256, activation=act.relu))
model.add(Dense(data.assets, activation=act.relu))
model.add(Dense(data.assets))
Ничего адекватного выжать из этой модели не вышло, score был около нуля (даже немного в минусе).
Temporal Convolutional Networks
Более современным нейросетевым решением для предсказания временных рядов являются TCN. Суть этой топологии весьма проста: берем одномерную сверточную сеть и применяем её к нашей последовательности длиной t. Более продвинутые варианты используют несколько сверточных слоев с разным dilation. Реализация TCN была частично скопирована (иногда на уровне идей) отсюда (визуализация стека TCN взята из статьи о Wavenet).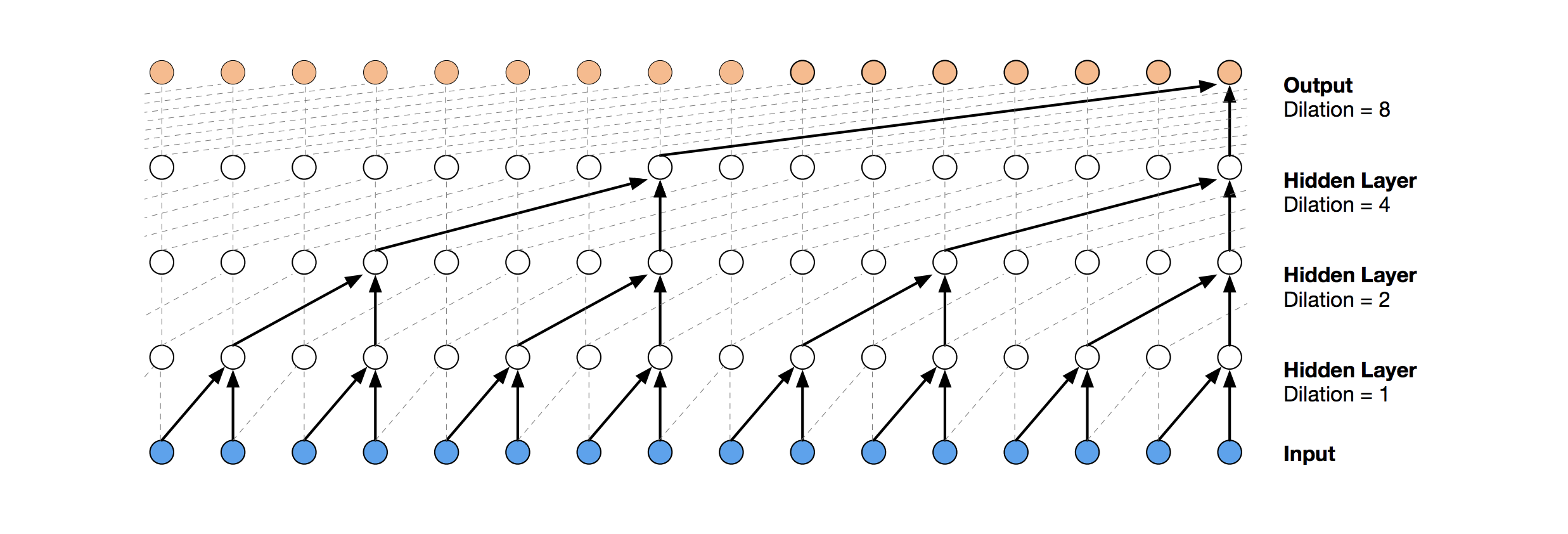
Первым относительно удачным решением стала вот такая модель, включающая слой GRU поверх TCN:
model = Sequential()
model.add(Conv1D(512,3, activation=act.relu, padding='causal', input_shape=(data.timesteps, data.features)))
model.add(Conv1D(100,3, activation=act.relu, padding='causal', dilation_rate=2))
model.add(Conv1D(100,3, activation=act.relu, padding='causal', dilation_rate=4))
model.add(GRU(256))
model.add(Dense(data.assets, activation=act.relu))
Такая модель выдает score = 0.27668. Небольшим тюнингом (количество фильтров TCN, размер batch) и увеличением t до 100 получаем уже 0.41092:
batch_size = 512
model = Sequential()
model.add(Conv1D(8,3, activation=act.relu, padding='causal', input_shape=(data.timesteps, data.features)))
model.add(Conv1D(4,3, activation=act.relu, padding='causal', dilation_rate=2))
model.add(Conv1D(4,3, activation=act.relu, padding='causal', dilation_rate=4))
model.add(GRU(16))
model.add(Dense(1, activation=act.sigmoid))
Далее добавляем нормализацию и dropout:
batch_size = 512
dropout_rate = 0.05
def channel_normalization(x):
max_values = K.max(K.abs(x), 2, keepdims=True) + 1e-5
out = x / max_values
return out
model = Sequential()
if(data.timesteps > 1):
model.add(Conv1D(16,2, activation=act.relu, padding='valid', input_shape=(data.timesteps, data.features)))
model.add(Lambda(channel_normalization))
model.add(SpatialDropout1D(dropout_rate))
model.add(Conv1D(16,1, padding='valid'))
for i in range(1, 6):
model.add(Conv1D(16,2, activation=act.relu, padding='valid', dilation_rate=2**i))
model.add(Lambda(channel_normalization))
model.add(SpatialDropout1D(dropout_rate))
model.add(Conv1D(16,1, padding='valid'))
model.add(Flatten())
else:
model.add(Flatten(input_shape=(data.timesteps, data.features)))
model.add(Dense(256, activation=act.relu))
model.add(Dense(1, activation=act.sigmoid))
Применяя эту модель в том числе и на ранних шагах (с t = 1), получаем score = 0.53578.
Gradient Boosting Machines
На этом этапе идеи закончились, и я решил сделать то, что нужно было сделать в самом начале: посмотреть публичные решения других участников. Большинство неплохих решений вообще не использовали нейросети, отдавая предпочтение GBM.
Gradient Boosting — это метод ML, на выходе которого мы получаем ансамбль простых моделей (чаще всего деревьев решений). За счет большого количества таких простых моделей и происходит оптимизация функции потерь. Более подробно о Gradient Boosting можно почитать, например, здесь.
В качестве реализации GBM использовали lightgbm — достаточно известный фреймворк от Microsoft.
Взятые отсюда модель и предобработка данных сразу дают score около 0.64:
def prepare_data(marketdf, newsdf):
# a bit of feature engineering
marketdf['time'] = marketdf.time.dt.strftime("%Y%m%d").astype(int)
marketdf['bartrend'] = marketdf['close'] / marketdf['open']
marketdf['average'] = (marketdf['close'] + marketdf['open'])/2
marketdf['pricevolume'] = marketdf['volume'] * marketdf['close']
newsdf['time'] = newsdf.time.dt.strftime("%Y%m%d").astype(int)
newsdf['assetCode'] = newsdf['assetCodes'].map(lambda x: list(eval(x))[0])
newsdf['position'] = newsdf['firstMentionSentence'] / newsdf['sentenceCount']
newsdf['coverage'] = newsdf['sentimentWordCount'] / newsdf['wordCount']
# filter pre-2012 data, no particular reason
marketdf = marketdf.loc[marketdf['time'] > 20120000]
# get rid of extra junk from news data
droplist = ['sourceTimestamp','firstCreated','sourceId','headline','takeSequence','provider','firstMentionSentence', 'sentenceCount','bodySize','headlineTag','marketCommentary','subjects','audiences','sentimentClass', 'assetName', 'assetCodes','urgency','wordCount','sentimentWordCount']
newsdf.drop(droplist, axis=1, inplace=True)
marketdf.drop(['assetName', 'volume'], axis=1, inplace=True)
# combine multiple news reports for same assets on same day
newsgp = newsdf.groupby(['time','assetCode'], sort=False).aggregate(np.mean).reset_index()
# join news reports to market data, note many assets will have many days without news data
return pd.merge(marketdf, newsgp, how='left', on=['time', 'assetCode'], copy=False)
import lightgbm as lgb
print ('Training lightgbm')
# money
params = {
"objective" : "binary",
"metric" : "binary_logloss",
"num_leaves" : 60,
"max_depth": -1,
"learning_rate" : 0.01,
"bagging_fraction" : 0.9, # subsample
"feature_fraction" : 0.9, # colsample_bytree
"bagging_freq" : 5, # subsample_freq
"bagging_seed" : 2018,
"verbosity" : -1
}
lgtrain, lgval = lgb.Dataset(Xt, Yt[:,0]), lgb.Dataset(Xv, Yv[:,0])
lgbmodel = lgb.train(params, lgtrain, 2000, valid_sets=[lgtrain, lgval], early_stopping_rounds=100, verbose_eval=200)
Предобработка здесь уже включает данные новостей, объединяя их с рыночными данными (однако делая это достаточно наивно, учитывается только один код актива из всех, которые упоминаются в новости). Этот вариант предобработки я взял за основу во всех последующих решениях.
Немного добавив фич (firstMentionSentence, marketCommentary, sentimentClass), а также заменив метрику на ROC AUC, получим score 0.65389.
Ансамбль
Следующим удачным решением было использование ансамбля, состоящего из нейросетевой модели и GBM (хотя «ансамбль» — это громкое название для двух моделей). Результирующее предсказание получаем усреднением предсказаний двух моделей, применяя, таким образом, механизм soft voting. Такое решение позволило получить score 0.66879.
Exploratory Data Analysis и Feature Engineering
Еще одна вещь, с которой нужно было начать, это EDA. Прочитав, что важно понять корреляцию между фичами, строим такую картинку (картинки в этом разделе кликабельны): 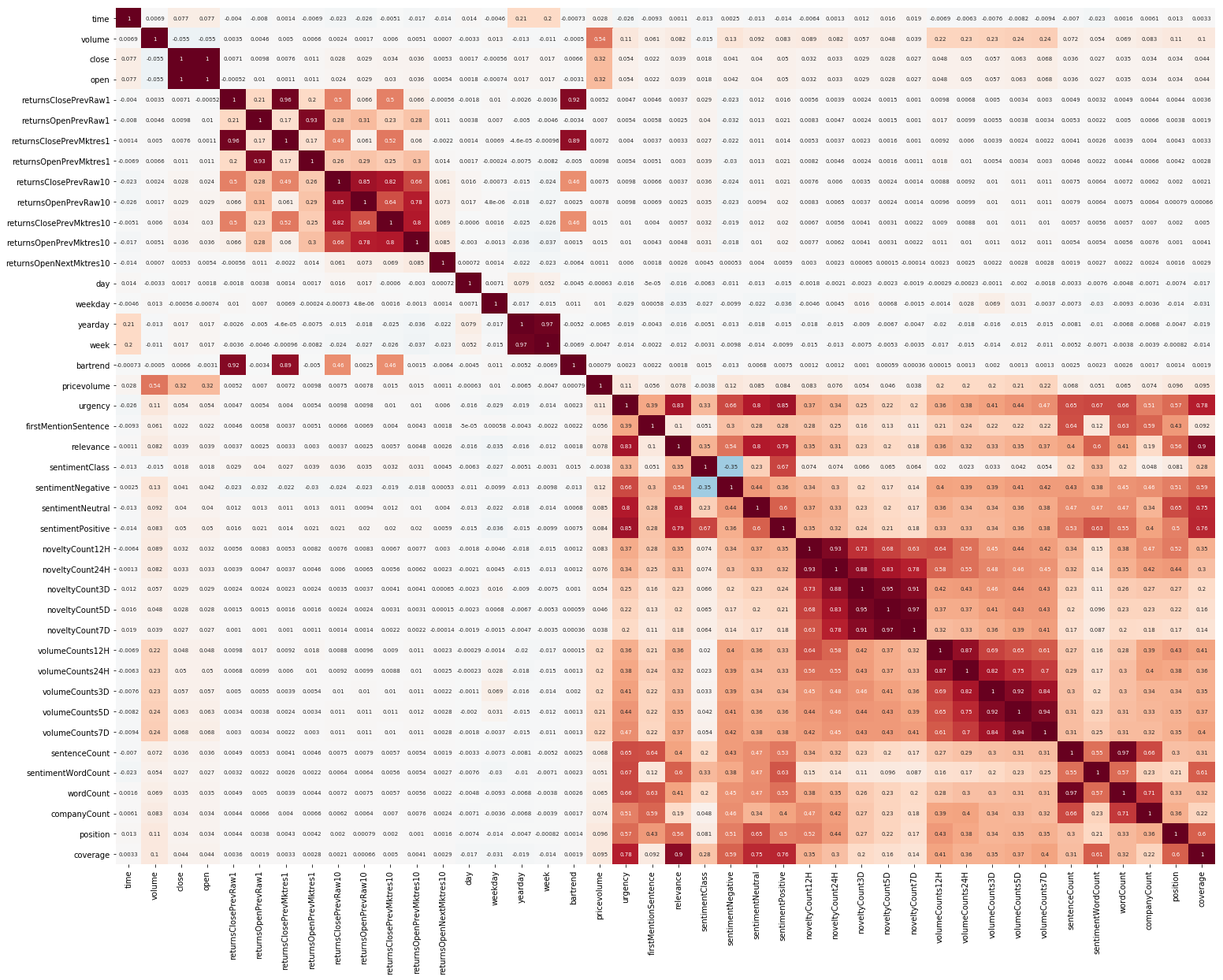
Здесь отчетливо видно, что корреляция отдельно внутри рыночных и новостных данных достаточно высока, однако с целевым значением хоть как-то коррелируют только значения доходностей. Так как данные представляют временной ряд, то есть смысл посмотреть также автокорреляцию целевого значения: 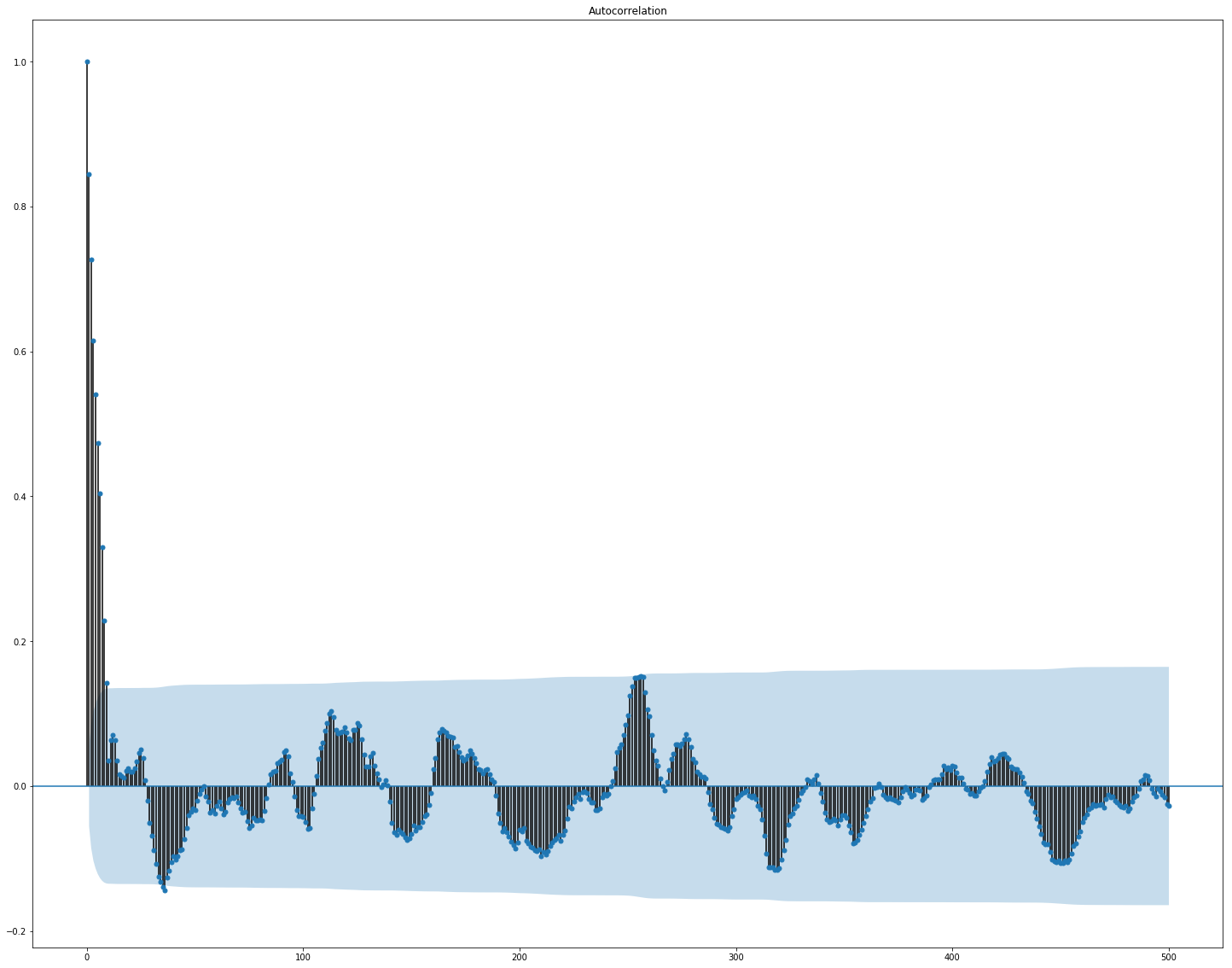
Видно, что после 10-дневного периода зависимость сильно падает. Вероятно, это и обуславливает неплохую работу GBM, учитывающих только фичи с 10-дневной задержкой (которые уже есть в изначальном наборе данных).
Выбор и предобработка фич крайне важна для всех алгоритмов ML. Попробуем воспользоваться автоматическими способами извлечения фич, а именно методом главных компонент (PCA):
from sklearn.decomposition import PCA
from sklearn.preprocessing import StandardScaler
market_x = market_data.loc[:,features]
scaler = StandardScaler()
scaler.fit(market_x)
market_x = scaler.transform(market_x)
pca = PCA(.95)
pca.fit(market_x)
market_pca = pca.transform(market_x)
Посмотрим, какие фичи генерирует PCA: 
Видим, что метод работает не очень хорошо на наших данных, так как итоговая корреляция новых фич с целевым значением невелика.
Тонкая настройка и нужна ли она
Многие модели ML имеют достаточно большое количество гиперпараметров, то есть, «настроек» самого алгоритма. Их можно подбирать вручную, но есть также и механизмы автоматического подбора. Для последнего существует библиотека hyperopt, которая реализует два алгоритма подбора — случайный поиск и Tree-structured Parzen Estimator (TPE). Пробовал оптимизировать:
- параметры lightgbm (тип алгоритма, кол-во листьев, learning rate и другие),
- параметры нейросетевых моделей (кол-во фильтров TCN, кол-во блоков памяти GRU, dropout rate, learning rate, тип решателя).
В итоге все решения, найденные при помощи такой оптимизации, выдавали меньший score, хотя на тестовых данных работали лучше. Вероятно, причина кроется в том, что данные, по которым считается score, не очень-то похожи на валидационные данные, отобранные из тренировочных. Таким образом, для этой задачи тонкая настройка не очень подходит, так как приводит к переобучению модели.
Финальное решение
По правилам соревнования участники могут выбрать два решения для финального этапа. Мои финальные решения практически одинаковы и содержат ансамбль из двух моделей — GBM и многослойного GRU. Отличия только в том, что одно решение совсем не использует новостные данные, а другое использует, но только для нейросетевой модели.
Решение с новостными данными: 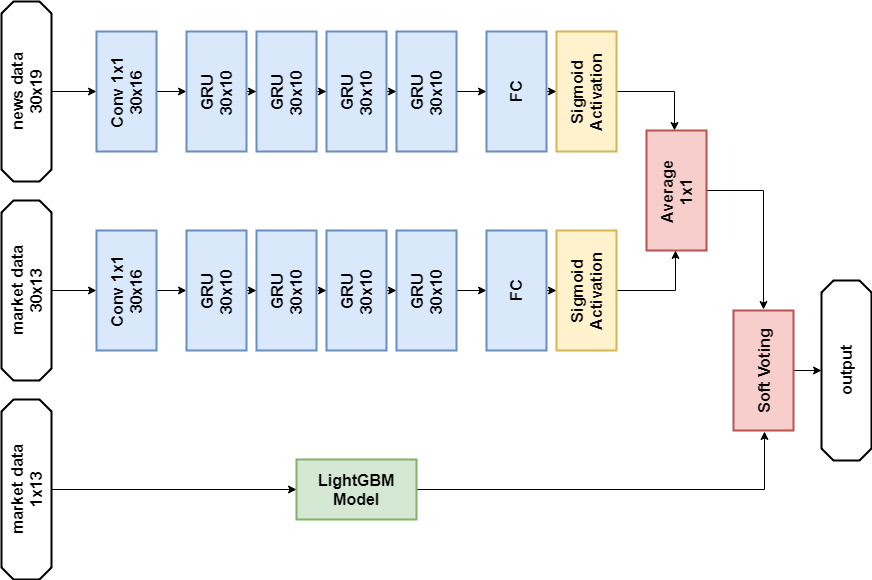
import numpy as np
import pandas as p
import itertools
import functools
from kaggle.competitions import twosigmanews
from sklearn.preprocessing import StandardScaler, LabelEncoder
import tensorflow as tf
from keras.models import Sequential, Model
from keras.layers import Dense, GRU, LSTM, Conv1D, Reshape, Flatten, SpatialDropout1D, Lambda, Input, Average
from keras.optimizers import Adam, SGD, RMSprop
from keras import losses as ls
from keras import activations as act
import keras.backend as K
import lightgbm as lgb
# fix random
from numpy.random import seed
seed(42)
from tensorflow import set_random_seed
set_random_seed(42)
env = twosigmanews.make_env()
(market_train_df, news_train_df) = env.get_training_data()
def cleanData(market_data, news_data):
market_data = market_data[(market_data['returnsOpenNextMktres10'] <= 1) & (market_data['returnsOpenNextMktres10'] >= -1)]
return market_data, news_data
def prepareData(marketdf, newsdf, scaler=None):
print('Preparing data...')
print('...preparing features...')
marketdf = marketdf.copy()
newsdf = newsdf.copy()
# a bit of feature engineering
marketdf['time'] = marketdf.time.dt.strftime("%Y%m%d").astype(int)
marketdf['bartrend'] = marketdf['close'] / marketdf['open']
marketdf['average'] = (marketdf['close'] + marketdf['open'])/2
marketdf['pricevolume'] = marketdf['volume'] * marketdf['close']
newsdf['time'] = newsdf.time.dt.strftime("%Y%m%d").astype(int)
newsdf['position'] = newsdf['firstMentionSentence'] / newsdf['sentenceCount']
newsdf['coverage'] = newsdf['sentimentWordCount'] / newsdf['wordCount']
# filter pre-2012 data, no particular reason
marketdf = marketdf.loc[marketdf['time'] > 20120000]
# get rid of extra junk from news data
droplist = ['sourceTimestamp','firstCreated','sourceId','headline','takeSequence','provider',
'sentenceCount','bodySize','headlineTag', 'subjects','audiences',
'assetName', 'wordCount','sentimentWordCount', 'companyCount',
'coverage']
newsdf.drop(droplist, axis=1, inplace=True)
marketdf.drop(['assetName', 'volume'], axis=1, inplace=True)
# unstack news
newsdf['assetCodes'] = newsdf['assetCodes'].apply(lambda x: x[1:-1].replace("'", ""))
codes = []
indices = []
for i, values in newsdf['assetCodes'].iteritems():
explode = values.split(", ")
codes.extend(explode)
repeat_index = [int(i)]*len(explode)
indices.extend(repeat_index)
index_df = p.DataFrame({'news_index': indices, 'assetCode': codes})
newsdf['news_index'] = newsdf.index.copy()
# Merge news on unstacked assets
news_unstack = index_df.merge(newsdf, how='left', on='news_index')
news_unstack.drop(['news_index', 'assetCodes'], axis=1, inplace=True)
# combine multiple news reports for same assets on same day
newsgp = news_unstack.groupby(['time','assetCode'], sort=False).aggregate(np.mean).reset_index()
# join news reports to market data, note many assets will have many days without news data
res = p.merge(marketdf, newsgp, how='left', on=['time', 'assetCode'], copy=False) #, right_on=['time', 'assetCodes'])
res.marketCommentary = res.marketCommentary.astype(float)
targetcol = 'returnsOpenNextMktres10'
target_presented = targetcol in res.columns
features = [col for col in res.columns if col not in ['time', 'assetCode', 'universe', targetcol]]
print('...scaling...')
if(scaler == None):
scaler = StandardScaler()
scaler = scaler.fit(res[features])
res[features] = scaler.transform(res[features])
print('...done.')
return type('', (object,), {
'scaler': scaler,
'data': res,
'x': res[features],
'y': (res[targetcol] > 0).astype(int).values if target_presented else None,
'features': features,
'samples': len(res),
'assets': res['assetCode'].unique(),
'target_presented': target_presented
})
def generateTimeSeries(data, n_timesteps=1):
data.data[data.features] = data.data[data.features].fillna(data.data[data.features].mean())
#data.data[data.features] = data.data[data.features].fillna(0)
assets = data.data.groupby('assetCode', sort=False)
def grouper(n, iterable):
it = iter(iterable)
while True:
chunk = list(itertools.islice(it, n))
if not chunk:
return
yield chunk
def sample_generator():
while True:
for assetCode, days in assets:
x = days[data.features].values
y = (days['returnsOpenNextMktres10'] > 0).astype(int).values if data.target_presented else None
for i in range(0, len(days) - n_timesteps + 1):
yield (x[i: i + n_timesteps], y[i + n_timesteps - 1] if data.target_presented else 0)
def batch_generator(batch_size):
for batch in grouper(batch_size, sample_generator()):
yield tuple([np.array(t) for t in zip(*batch)])
n_samples = functools.reduce(lambda x,y : x + y, map(lambda t : 0 if len(t[1]) + 1 <= n_timesteps else len(t[1]) - n_timesteps + 1, assets))
return type('', (object,), {
'gen': batch_generator,
'timesteps': n_timesteps,
'features': len(data.features),
'samples': n_samples,
'assets': list(map(lambda x: x[0], filter(lambda t : len(t[1]) + 1 > n_timesteps, assets)))
})
def buildRNN(timesteps, features):
i = Input(shape=(timesteps, features))
x1 = Lambda(lambda x: x[:,:,:13])(i)
x1 = Conv1D(16,1, padding='valid')(x1)
x1 = GRU(10, return_sequences=True)(x1)
x1 = GRU(10, return_sequences=True)(x1)
x1 = GRU(10, return_sequences=True)(x1)
x1 = GRU(10)(x1)
x1 = Dense(1, activation=act.sigmoid)(x1)
x2 = Lambda(lambda x: x[:,:,13:])(i)
x2 = Conv1D(16,1, padding='valid')(x2)
x2 = GRU(10, return_sequences=True)(x2)
x2 = GRU(10, return_sequences=True)(x2)
x2 = GRU(10, return_sequences=True)(x2)
x2 = GRU(10)(x2)
x2 = Dense(1, activation=act.sigmoid)(x2)
x = Average()([x1, x2])
model = Model(inputs=i, outputs=x)
return model
def train_model_time_series(model, data, val_data=None):
print('Building model...')
batch_size = 4096
optimizer = RMSprop()
# define roc_callback, inspired by https://github.com/keras-team/keras/issues/6050#issuecomment-329996505
def auc_roc(y_true, y_pred):
value, update_op = tf.metrics.auc(y_true, y_pred)
metric_vars = [i for i in tf.local_variables() if 'auc_roc' in i.name.split('/')[1]]
for v in metric_vars:
tf.add_to_collection(tf.GraphKeys.GLOBAL_VARIABLES, v)
with tf.control_dependencies([update_op]):
value = tf.identity(value)
return value
model.compile(loss=ls.binary_crossentropy, optimizer=optimizer, metrics=['binary_accuracy', auc_roc])
print(model.summary())
print('Training model...')
if(val_data == None):
model.fit_generator(data.gen(batch_size),
epochs=8,
steps_per_epoch=int(data.samples / batch_size),
verbose=1)
else:
model.fit_generator(data.gen(batch_size),
epochs=8,
steps_per_epoch=int(data.samples / batch_size),
validation_data=val_data.gen(batch_size),
validation_steps=int(val_data.samples / batch_size),
verbose=1)
return type('', (object,), {
'predict': lambda x: model.predict_generator(x, steps=1)
})
def train_model(data, val_data=None):
print('Building model...')
params = {
"objective" : "binary",
"metric" : "auc",
"num_leaves" : 60,
"max_depth": -1,
"learning_rate" : 0.01,
"bagging_fraction" : 0.9, # subsample
"feature_fraction" : 0.9, # colsample_bytree
"bagging_freq" : 5, # subsample_freq
"bagging_seed" : 2018,
"verbosity" : -1 }
ds, val_ds = lgb.Dataset(data.x.iloc[:,:13], data.y), lgb.Dataset(val_data.x.iloc[:,:13], val_data.y)
print('...training...')
model = lgb.train(params, ds, 2000, valid_sets=[ds, val_ds], early_stopping_rounds=100, verbose_eval=100)
print('...done.')
return type('', (object,), {
'model': model,
'predict': lambda x: model.predict(x.iloc[:,:13], num_iteration=model.best_iteration)
})
n_timesteps = 30
market_data, news_data = cleanData(market_train_df, news_train_df)
dates = market_data['time'].unique()
train = range(len(dates))[:int(0.85*len(dates))]
val = range(len(dates))[int(0.85*len(dates)):]
train_data_prepared = prepareData(market_data.loc[market_data['time'].isin(dates[train])], news_data.loc[news_data['time'] <= max(dates[train])])
val_data_prepared = prepareData(market_data.loc[market_data['time'].isin(dates[val])], news_data.loc[news_data['time'] > max(dates[train])], scaler=train_data_prepared.scaler)
model_gbm = train_model(train_data_prepared, val_data_prepared)
train_data_ts = generateTimeSeries(train_data_prepared, n_timesteps=n_timesteps)
val_data_ts = generateTimeSeries(val_data_prepared, n_timesteps=n_timesteps)
rnn = buildRNN(train_data_ts.timesteps, train_data_ts.features)
model_rnn = train_model_time_series(rnn, train_data_ts, val_data_ts)
def make_predictions(data, template, model):
if(hasattr(data, 'gen')):
prediction = (model.predict(data.gen(data.samples)) * 2 - 1)[:,-1]
else:
prediction = model.predict(data.x) * 2 - 1
predsdf = p.DataFrame({'ast':data.assets,'conf':prediction})
template['confidenceValue'][template['assetCode'].isin(predsdf.ast)] = predsdf['conf'].values
return template
day = 1
days_data = p.DataFrame({})
days_data_len = []
days_data_n = p.DataFrame({})
days_data_n_len = []
for (market_obs_df, news_obs_df, predictions_template_df) in env.get_prediction_days():
print(f'Predicting day {day}')
days_data = p.concat([days_data, market_obs_df], ignore_index=True, copy=False, sort=False)
days_data_len.append(len(market_obs_df))
days_data_n = p.concat([days_data_n, news_obs_df], ignore_index=True, copy=False, sort=False)
days_data_n_len.append(len(news_obs_df))
data = prepareData(market_obs_df, news_obs_df, scaler=train_data_prepared.scaler)
predictions_df = make_predictions(data, predictions_template_df.copy(), model_gbm)
if(day >= n_timesteps):
data = prepareData(days_data, days_data_n, scaler=train_data_prepared.scaler)
data = generateTimeSeries(data, n_timesteps=n_timesteps)
predictions_df_s = make_predictions(data, predictions_template_df.copy(), model_rnn)
predictions_df['confidenceValue'] = (predictions_df['confidenceValue'] + predictions_df_s['confidenceValue']) / 2
days_data = days_data[days_data_len[0]:]
days_data_n = days_data_n[days_data_n_len[0]:]
days_data_len = days_data_len[1:]
days_data_n_len = days_data_n_len[1:]
env.predict(predictions_df)
day += 1
env.write_submission_file()
Решение без новостных данных: 
def buildRNN(timesteps, features):
i = Input(shape=(timesteps, features))
x1 = Lambda(lambda x: x[:,:,:13])(i)
x1 = Conv1D(16,1, padding='valid')(x1)
x1 = GRU(10, return_sequences=True)(x1)
x1 = GRU(10, return_sequences=True)(x1)
x1 = GRU(10, return_sequences=True)(x1)
x1 = GRU(10)(x1)
x1 = Dense(1, activation=act.sigmoid)(x1)
model = Model(inputs=i, outputs=x1)
return model
Оба решения выдавали похожий результат (около 0.69) на первом этапе конкурса, что соответствовало 566 месту из 2927. После первого месяца новых данных позиции в списке участников сильно перемешались, и решение с новостными данными оказалось на 65 месте из оставшихся 697 команд с результатом 3.19251, а что будет в течение следующих пяти месяцев, не знает никто.
Что еще попробовал
Кастомные метрики
Так как решения оцениваются по коэффициенту Шарпа, то логично попробовать использовать его в качестве метрики для ранней остановки обучения.
Метрика для lightgbm:
def sharpe_metric(y_pred, train_data):
y_true = train_data.get_label() * 2 - 1
std = np.std(y_true * y_pred)
mean = np.mean(y_true * y_pred)
sharpe = np.divide(mean, std, out=np.zeros_like(mean), where=std!=0)
return "sharpe", sharpe, True
Проверка показала, что такая метрика работает в данной задаче хуже, чем AUC.
Механизм внимания
Механизм внимания позволяет нейросети сфокусироваться на «наиболее важных» признаках в исходных данных. Технически, внимание представляется вектором весов (чаще всего получаемых при помощи полносвязного слоя с активацией softmax), которые перемножаются на выход другого слоя. Я использовал реализацию, в которой внимание применяется к временной оси:
def buildRNN(timesteps, features):
def attention_3d_block(inputs):
a = Permute((2, 1))(inputs)
a = Dense(timesteps, activation=act.softmax)(a)
a = Permute((2, 1))(a)
mul = Multiply()([inputs, a])
return mul
i = Input(shape=(timesteps, features))
x1 = Lambda(lambda x: x[:,:,:13])(i)
x1 = Conv1D(16,1, padding='valid')(x1)
x1 = GRU(10, return_sequences=True)(x1)
x1 = attention_3d_block(x1)
x1 = GRU(10, return_sequences=True)(x1)
x1 = attention_3d_block(x1)
x1 = GRU(10, return_sequences=True)(x1)
x1 = attention_3d_block(x1)
x1 = GRU(10)(x1)
x1 = Dense(1, activation=act.sigmoid)(x1)
model = Model(inputs=i, outputs=x1)
return model
Эта модель выглядит достаточно красиво, однако прироста score такой подход не дал, получилось около 0.67.
Что не успел сделать
Несколько направлений, которые выглядят перспективными:
Выводы
Наше приключение подошло к концу, можно попробовать подвести итоги. Конкурс оказался сложным, но мы смогли не ударить в грязь лицом. Это намекает, что порог входа в ML не так уж высок, но, как в любом деле, настоящая магия (а её в машинном обучении предостаточно) доступна уже профессионалам.
Итоги в цифрах:
- Максимальный score на первом этапе: ~0.69 против ~1.5 у первого места. Что-то вроде среднего по больнице, значение 0.7 преодолели немногие, максимальный score публичного решения так же ~0.69, чуть больше моего.
- Место на первом этапе: 566 из 2927.
- Score на втором этапе: 3.19251 после первого месяца.
- Место на втором этапе: 65 из 697 после первого месяца.
Обращаю внимание, что цифры по второму этапу пока ни о чем особенно не говорят, так как данных пока еще очень мало для качественной оценки решений.
Ссылки
Финальное решение с использованием новостей
Two Sigma: Using News to Predict Stock Movements — страница конкурса
Keras — нейросетевой фреймворк
LightGBM — GBM фреймворк
Scikit-learn — библиотека алгоритмов машинного обучения
Hyperopt — библиотека для оптимизации гиперпараметров
Статья о WaveNet
