Маленькие оптимизации в Java 9-16
Когда выходит новая версия Java, главные фичи всегда активно обсуждают. Но есть и работа, которая обычно остается «невидимой»: небольшие оптимизации в стандартной библиотеке. Они помогают нам, незаметно ускоряя наш код и ничего не требуя взамен, а мы даже ничего о них не знаем!
Эту ситуацию исправляет Тагир Валеев (lany), рассказывая о таких оптимизациях. Сначала он выступил на Joker 2019 с докладом «Java 9–14: маленькие оптимизации», можете посмотреть его видеозапись. Затем, поскольку зрителям очень понравилось, на JPoint 2020 он развил тему. А теперь мы решили сделать из второго доклада пост для Хабра, чтобы его можно было не только увидеть, но и прочитать.

Далее под катом текст пойдет от лица спикера.
Вступление
Мы посмотрим только на самые базовые вещи, которыми прямо или косвенно пользуются все: строки, коллекции и рефлексию. Мы не рассматриваем API, появившиеся после Java 8. Все улучшения производительности вы получите бесплатно, если будете запускать ваш Java 8-код на более новой JVM.
Проведем замеры производительности кода. Я не буду делать вид, что они очень научные, но надеюсь, что показательные и выводы из них правильные. Тесты проводились на Intel Core i7–6820HQ под Windows 10. Все они однопоточные, поэтому количество ядер процессора не принципиально. Чтобы нивелировать эффект от смены сборщика мусора по умолчанию, всегда использовалась опция +UseParallelGC. На всех иллюстрациях производительность измеряется по среднему времени выполнения, то есть «чем меньше, тем лучше».
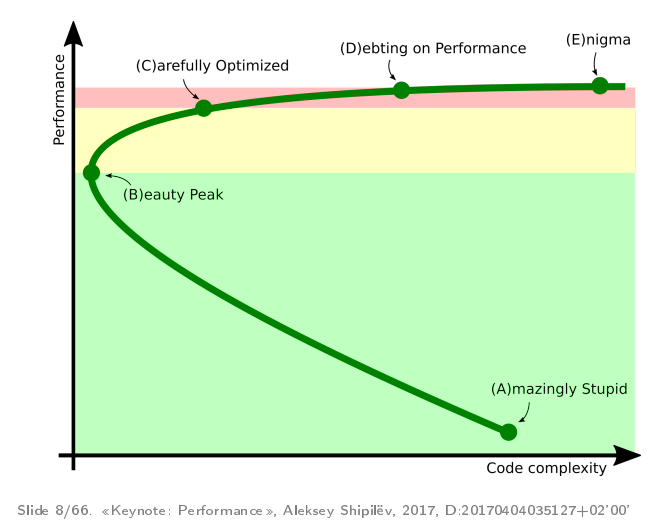
Если вы знаете доклад Алексея Шипилёва о производительности, то должны помнить «Кривую имени Ш.» В качестве упражнения можете про каждую оптимизацию в этом докладе прикинуть, где она на этой кривой.
String.hashCode
Начнем с замера производительности String.hashCode. Напишем бенчмарк, в котором будем вычислять хеш-код строки «Бегавшая через бары»:
@Benchmark
public int calcHashCode() {
return "Бегавшая через бары".hashCode();
}При сравнении Java 12 и Java 13 получаем следующее:

Как же удалось ускорить вычисление хеш-кода более чем в 4 раза? Все дело в самой строке, она не случайная. Вы скорее выиграете в лотерею, чем наткнётесь на такую. Сравним производительность вычислений двух строк: «Бегавшая через бары» и «Бегавший через бары»:
@Benchmark
public int calcHashCode() {
return "Бегавшая через бары".hashCode();
}
@Benchmark
public int calcHashCode2() {
return "Бегавший через бары".hashCode();
}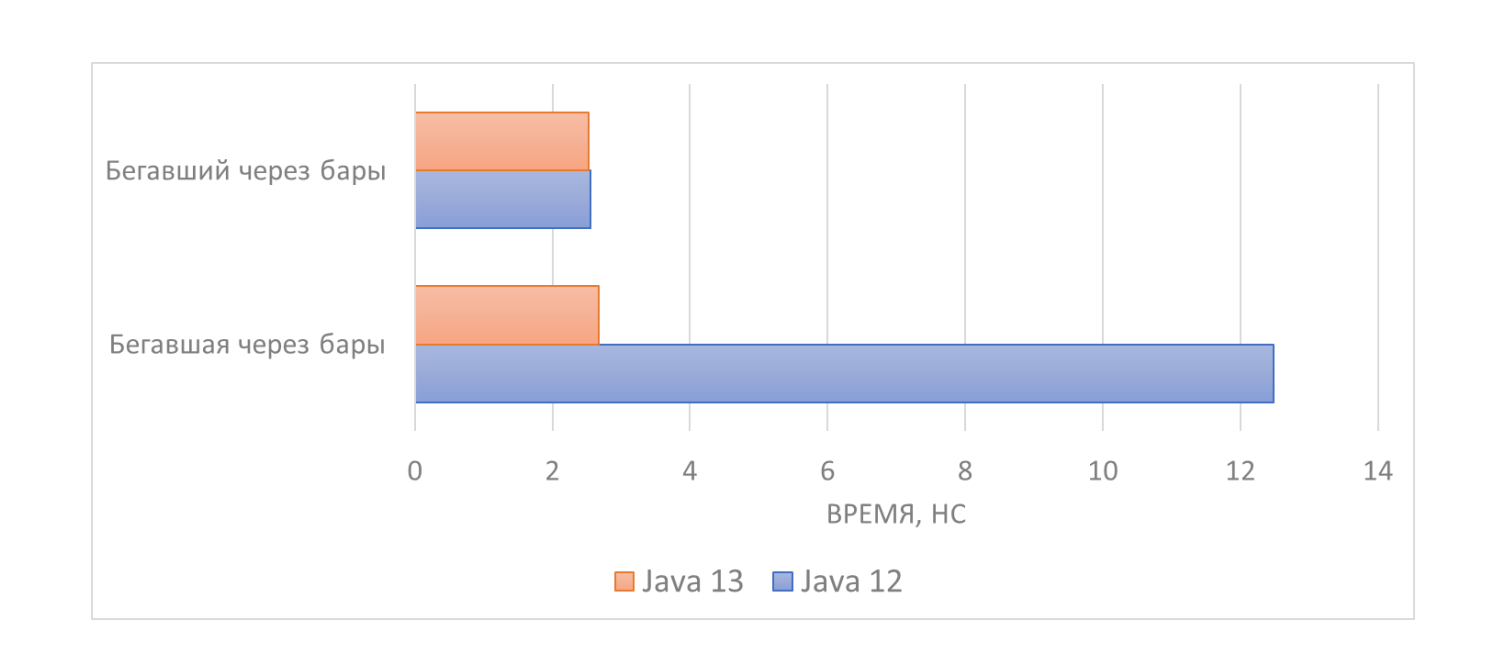
Оказывается, в Java 12, когда «он» уже бегал через бары быстро, «она» ещё бегала медленно. Но в Java 13 наконец наступило равенство полов. В чём дело?
В значении хеш-кода. С Java 9 по Java 12 метод hashCode () выглядел так (до этого чуть по-другому, потому что не было Compact Strings):
/** Cache the hash code for the string */
private int hash; // Default to 0
public int hashCode() {
int h = hash;
if (h == 0 && value.length > 0) {
hash = h = isLatin1() ? StringLatin1.hashCode(value)
: StringUTF16.hashCode(value);
}
return h;
}Формула хеш-кода давно специфицирована, и ее нельзя менять. В одном случае из 4 миллиардов значением хеш-кода получается 0. И в этом случае полученный хеш-код нельзя закешировать. Чтобы различать ситуации, когда хеш-код подсчитан и еще нет, во втором случае как раз используют 0 как его значение. А если у вашей строки он такой и оказался — ну что ж, вы неудачник, будете пересчитывать его всегда.
Об этом на JPoint 2015 рассказывал Алексей Шипилёв в докладе «Катехизис java.lang.String». На Java 8 его пример «сверхинструментом пренебрегшая» также давал хеш-код 0, а строка «пренебрегшая сверхинструментом» давала уже другое значение. Он также раскритиковал мнение перфекционистов, что необходимо добавить специальный флаг для таких случаев, потому что размер объекта String вырос бы для всех.
Но теперь некоторые перфекционисты победили, причем Алексей им помог.
Посмотрим на layout объекта String в Java 8. Оказывается, на 64-битной JVM в String и так терялось 4 байта, причем хоть со сжатыми ссылками, хоть без. То есть можно занять 1 байт.

С другой стороны, в 32-битной JVM потерь не было. Может быть, еще в каких-то экзотических конфигурациях с другим выравниванием в строках тоже не пропадало место, поэтому добавление флага заняло бы дополнительную память.
Однако в Java 9 появились компактные строки, большую часть которых делал сам Алексей Шипилёв, и все это стало неважно. Для их обозначения уже требуется дополнительный байт, который показывает, влезает ли строка в кодировку Latin-1, или же в ней есть UTF-16 символы. Теперь полезная нагрузка строки теряет 3 байта, и вряд ли можно представить такую конфигурацию VM, в которой 3 лишних байта превратятся в 0. А раз они свободны, почему же тогда не занять еще один из них?
Это и сделали в Java 13, добавив булево поле String.hashIsZero:

И еще два байта осталось для потомков. Теперь вычисление хеш-кода выглядит так:
private int hash; // Default to 0
private boolean hashIsZero; // Default to false;
public int hashCode() {
int h = hash;
if (h == 0 && !hashIsZero) {
h = isLatin1() ? StringLatin1.hashCode(value)
: StringUTF16.hashCode(value);
if (h == 0) {
hashIsZero = true;
} else {
hash = h;
}
}
return h;
}Но почему добавили именно поле hashIsZero? Кажется, логичнее было бы завести поле hashIsCalculated и устанавливать его в true, когда хеш вычислен.
Оказывается, метод hashCode () никак не синхронизирован, поэтому в нем возможна гонка по данным. Когда поле одно, подобное можно делать аккуратно, так как благодаря гарантии атомарности каждый из потоков увидит либо вычисленный хеш-код, либо 0 (тогда он вычислит вручную). Но запись двух полей неатомарна, и другие потоки могут увидеть одну из этих записей. И если сделать поле hashIsCalculated и не добавить синхронизации, то другой поток может увидеть в hashIsCalculated значение true и хеш, равный 0, и вернет неправильный хеш.
Поэтому придумали такое изящное решение, при котором никогда не пишут более одного поля в объект String: когда одно поле меняется, другое всегда имеет значение по умолчанию, поэтому атомарность сохраняется.
Когда это отправили на ревью, Алексей Шипилёв долго всех убеждал, что так делать не надо, потому что это неоправданная сложность. Но перфекционизм победил.
String.concat
Конкатенацию строк можно провести не только через +, но и через метод String.concat (). Выясним, какой из этих способов быстрее. Напишем бенчмарк:
@Param({"", "is a very very very very very very very very cool conference!"})
String data;
@Benchmark
public String concat() {
return "JPoint ".concat(data);
}
@Benchmark
public String plus() {
return "JPoint " + data;
}Сначала проверим на конкатенацию пустой строки с непустой:
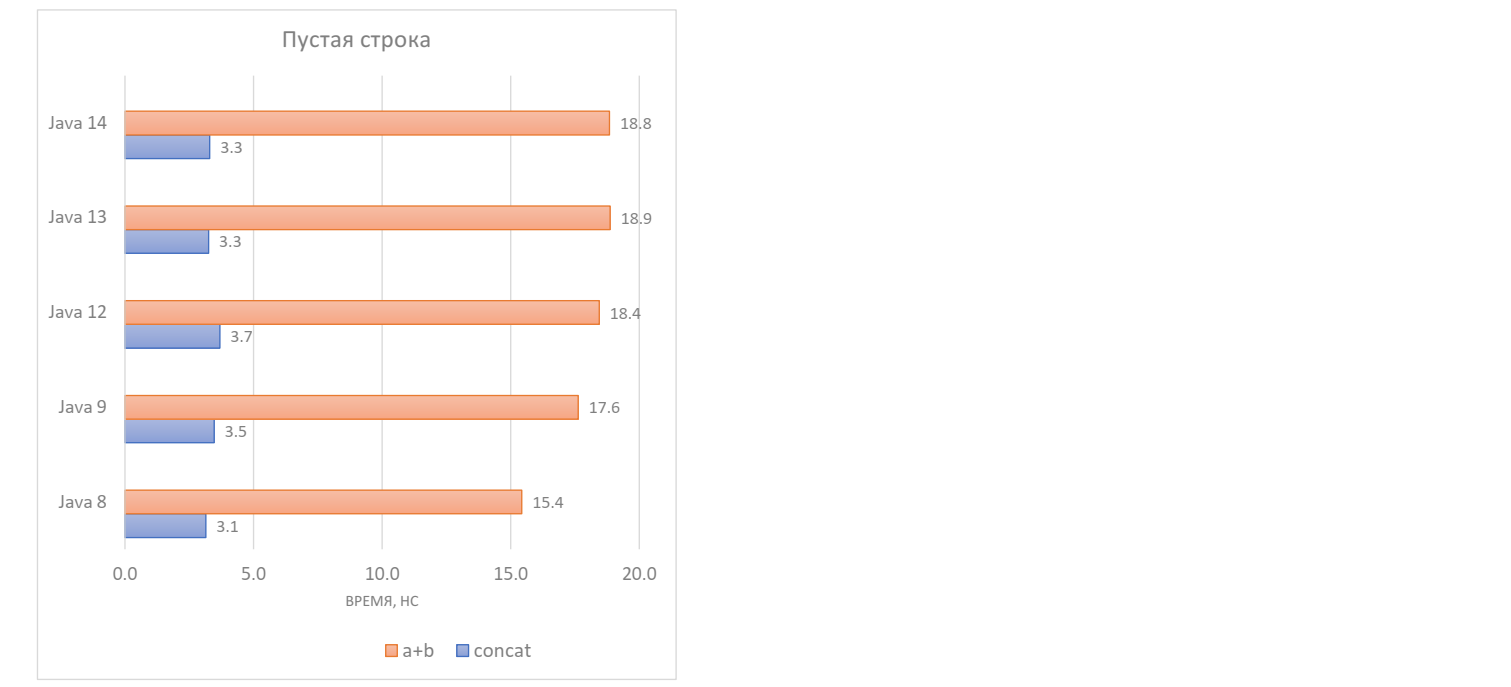
Оказывается, метод String.concat () работает в Java 8–14 за ~3 нс, а конкатенация через + занимает больше 15 нс, причем замедляется в новых версиях до ~19 нс. Почему?
Проблема кроется в спецификации Java. Результатом конкатенации строк всегда должна быть новая строка. Это требование идет с ранних версий спецификации, и убрать его было бы breaking change. А String.concat () не скован этим ограничением, даже наоборот: в его спецификации четко прописано, что если длина строки-аргумента равна 0, то возвращается исходная строка. Это тоже странно, поскольку это правило в обратную сторону не работает: если строка слева пустая, тогда аргумент копируется в новую строку.
Пустые строки мы не так часто конкатенируем, давайте посмотрим на непустые.
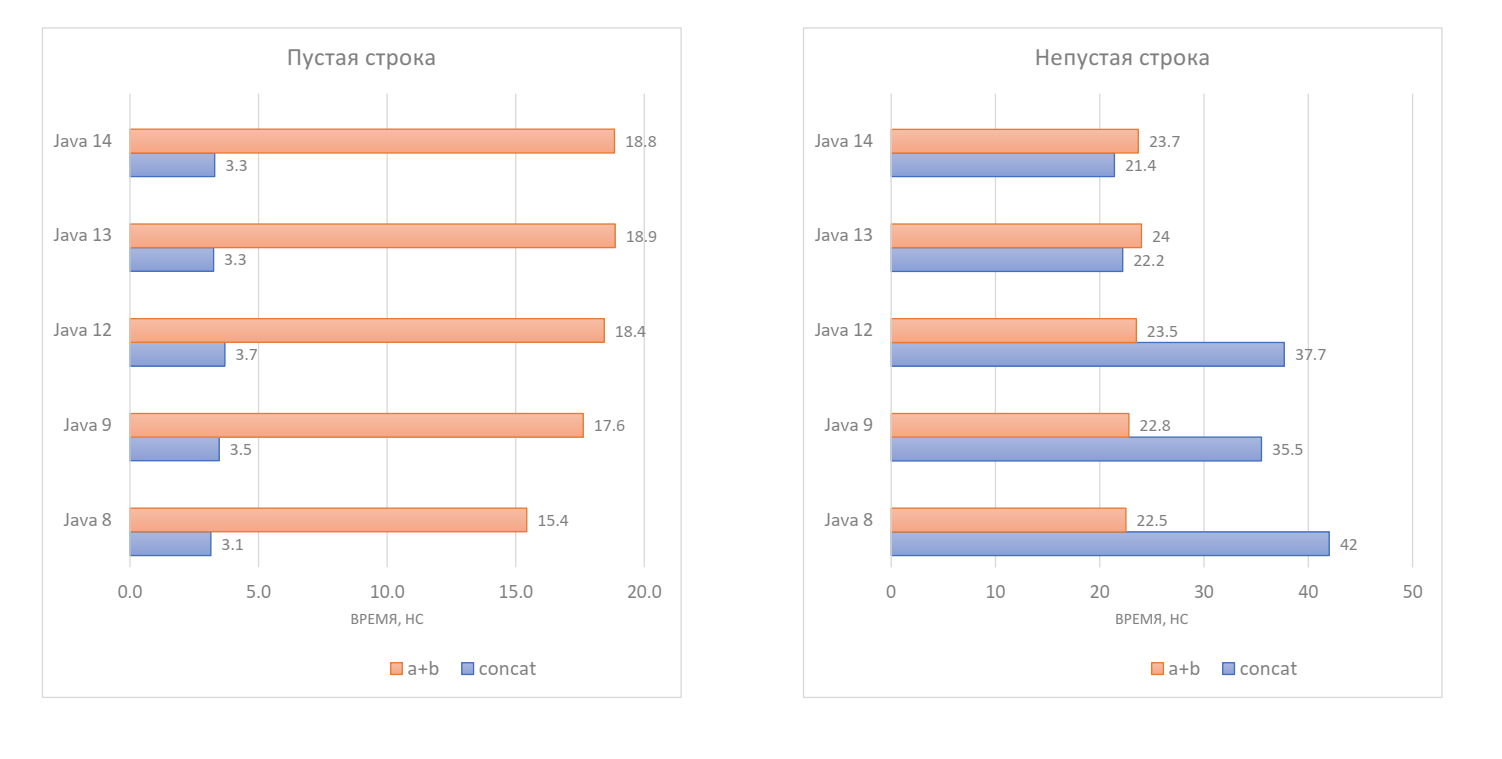
С бенчмарком маленьких оптимизаций в непустых строках есть трудности, потому что были и большие оптимизации. В Java 8 String.concat () отработал вдвое медленнее, чем конкатенация через +, а в Java 9 он заметно ускорился благодаря внедрению компактных строк. До Java 12 картина была примерно одинаковой, но в Java 13 и Java 14 String.concat () работает быстрее конкатенации через + примерно на 10%.
Но не спешите переходить на String.concat (). В Java 9 был реализован JEP 280 — конкатенация строк через invokedynamic-вызовы. Однако для конкатенации через + необходимо перекомпилировать ваше приложение, а метод String.concat () будет использовать код из JEP 280 даже без перекомпиляции.
Перекомпилируем бенчмарк с таргетом Java 9 и запустим заново:
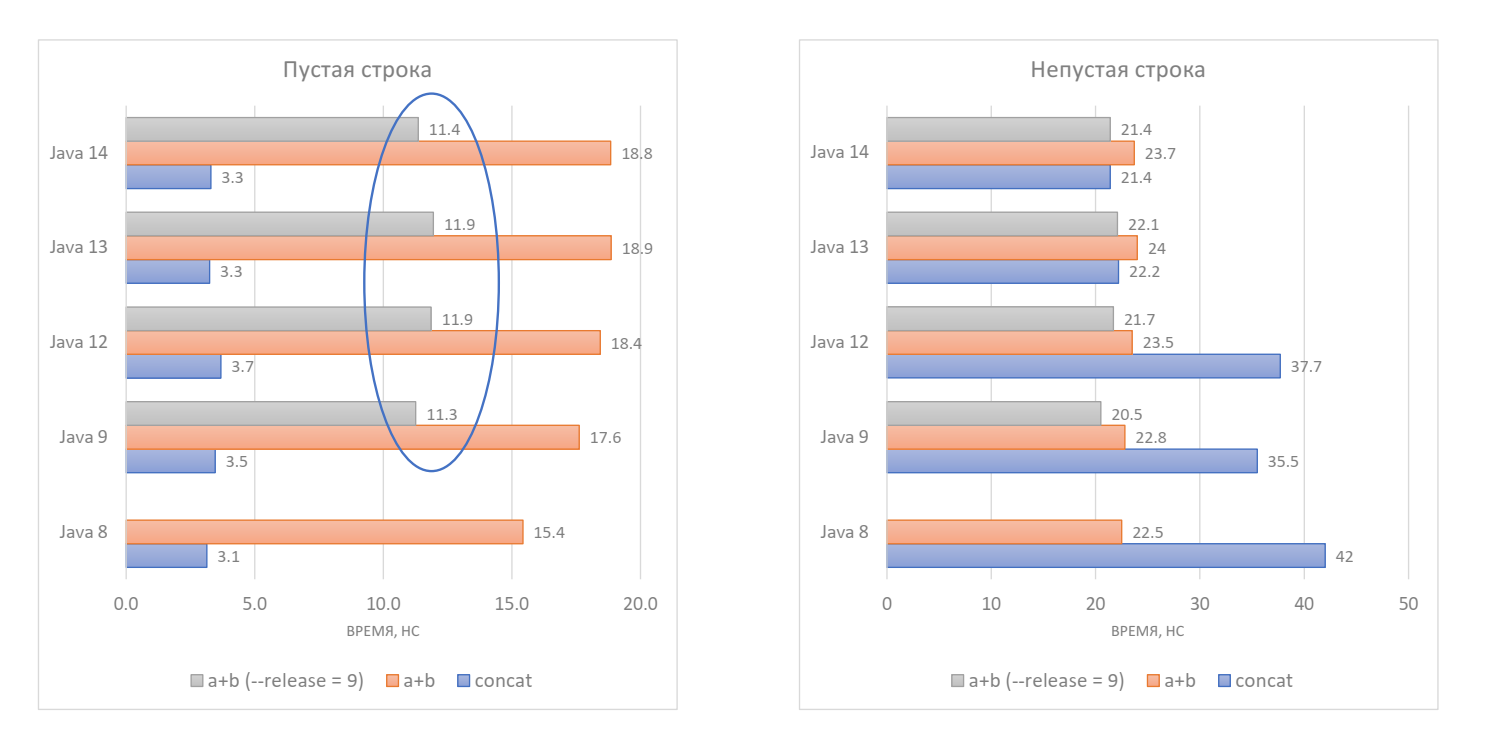
Если конкатенация была с пустой строкой, то она стала заметно быстрее и деградация в свежих версиях Java перестала наблюдаться. Конкатенация с непустой строкой также всегда быстрее, чем до перекомпиляции, и сравнялась по производительности со String.concat (). Что же стало решающим фактором в таком скачке производительности?
Посмотрим на код метода String.concat () в Java 12:
public String concat(String str) {
if (str.isEmpty()) {
return this;
}
if (coder() == str.coder()) {
byte[] val = this.value;
byte[] oval = str.value;
int len = val.length + oval.length;
byte[] buf = Arrays.copyOf(val, len);
System.arraycopy(oval, 0, buf, val.length, oval.length);
return new String(buf, coder);
}
int len = length();
int olen = str.length();
byte[] buf = StringUTF16.newBytesFor(len + olen);
getBytes(buf, 0, UTF16);
str.getBytes(buf, len, UTF16);
return new String(buf, UTF16);
}Метод проверяет компактность обеих строк, соединяет их в байтовый массив, а затем приватный конструктор из байтового массива создает новую строку. Все выглядит довольно оптимально, и неясно, как все улучшить.
public String concat(String str) {
if (str.isEmpty()) {
return this;
}
return StringConcatHelper.simpleConcat(this, str);
}
static String simpleConcat(Object first, Object second) {
String s1 = stringOf(first);
String s2 = stringOf(second);
// start "mixing" in length and coder or arguments, order is not
// important
long indexCoder = mix(initialCoder(), s2);
indexCoder = mix(indexCoder, s1);
byte[] buf =(indexCoder);
// prepend each argument in reverse order, since we prepending
// from the end of the byte array
indexCoder = prepend(indexCoder, buf, s2);
indexCoder = prepend(indexCoder, buf, s1);
return newString(buf, indexCoder);
}В Java 13 метод стал делегировать вспомогательному методу simpleConcat (), который теперь используется в обоих способах конкатенации строк. Кажется, что веток теперь меньше, однако они спрятаны в методы mix () и prepend (). Улучшение производительности кроется в реализации внутреннего метода newArray ():
static byte[] newArray(long indexCoder) {
byte coder = (byte)(indexCoder >> 32);
int index = (int)indexCoder;
return (byte[]) UNSAFE.allocateUninitializedArray(byte.class, index << coder);
}Метод выделяет неинициализированный массив, то есть еще не забитый нулями. На этом и экономим. А в Java 12 вместо внутреннего метода newArray () использовался публичный метод copyOf (), который должен занулить массив.
Конкатенация пустых строк
График конкатенации пустой строки мне долго не давал покоя.

Да, нужно создать новый объект, но 11 нс — это много. Я подумал над этим, и это вылилось в новый патч JDK-8247605, причем он попадет в Java 16.
Посмотрим снова на код метода simpleConcat ():
static String simpleConcat(Object first, Object second) {
String s1 = stringOf(first);
String s2 = stringOf(second);
// start "mixing" in length and coder or arguments, order is not
// important
long indexCoder = mix(initialCoder(), s2);
indexCoder = mix(indexCoder, s1);
byte[] buf =(indexCoder);
// prepend each argument in reverse order, since we prepending
// from the end of the byte array
indexCoder = prepend(indexCoder, buf, s2);
indexCoder = prepend(indexCoder, buf, s1);
return newString(buf, indexCoder);
}Предположим, что строка s1 или s2 — пустая. Мы не можем просто вернуть другую строку, потому что нас ограничивает спецификация. Но спецификация не обязывает выделять под нее новый массив. Ведь массив с байтами внутри строки не меняется и спрятан, а значит, его можно переиспользовать и больше ничего не делать. Сделать это весьма просто — можно делегировать к конструктору строки от строки:
...
String s1 = stringOf(first);
String s2 = stringOf(second);
if (s1.isEmpty()) {
// newly created string required, see JLS 15.18.1
return new String(s2);
}
if (s2.isEmpty()) {
// newly created string required, see JLS 15.18.1
return new String(s1);
}
...Это публичный конструктор, он существует с давних пор и, как правило, не нужен, потому что строки неизменяемые. Но он как раз переиспользует внутренний массив, поэтому хорошо подходит под наши цели.
Патч добрался до ранних сборок Java 16, и их уже можно скачать и протестировать:
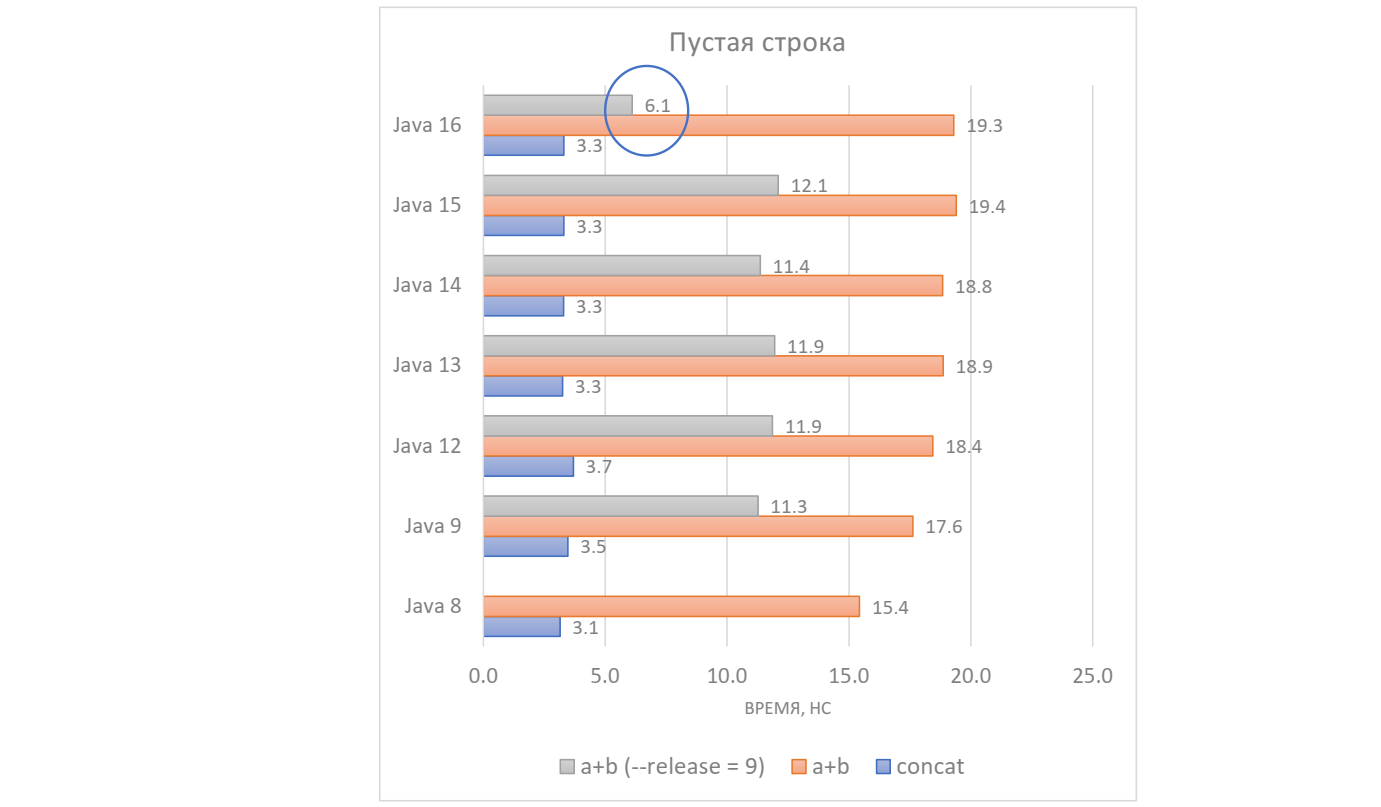
Теперь конкатенация любой строки (причем неважно, справа или слева находится пустая строка) уже не требует копирования массива, а значит, занимает гораздо меньше времени — ~6 нс.
Вдобавок мы экономим память: если и исходная строка, и результат конкатенации оказались долгоживущими, то они будут сидеть на одном массиве навсегда. Но это работает, если включена target-версия Java 9 и выше.
В этом и прелесть конкатенации через invokedynamic — мы можем улучшать существующую фичу, вообще не меняя байткода.
TreeMap.computeIfAbsent и другие методы коллекций
Речь пойдет о пяти методах, которые появились в Java 8 в интерфейсе map:
- putIfAbsent ()
- computeIfAbsent ()
- computeIfPresent ()
- compute ()
- merge ()
Все они модифицируют не больше одной записи в map, и все, кроме putIfAbsent (), принимают лямбду, которая тем или иным образом говорит, как мы будем модифицировать значение. Так как эти методы были добавлены в интерфейс, они имеют реализацию по умолчанию, чтобы не сломать уже существующий код. Посмотрим, как выглядит реализация по умолчанию метода computeIfAbsent ():
default V computeIfAbsent(K key,
Function mappingFunction) {
Objects.requireNonNull(mappingFunction);
V v;
if ((v = get(key)) == null) {
V newValue;
if ((newValue = mappingFunction.apply(key)) != null) {
put(key, newValue);
return newValue;
}
}
return v;
}Метод computeIfAbsent () позволяет вычислить значение и поместить в map, если там ничего не было. Если же значение было, и не было равно null, то метод возвращает старое значение.
В реализации по умолчанию есть очевидный недостаток. Если записи не было, то придется ее искать дважды: сперва при вызове get () ищем запись в хеш-таблице или дереве, не находим, а затем при вызове put () нужно найти, куда положить запись. То есть мы 2 раза делаем одно и то же, а операция может быть недешевой.
Понятно, что мы ничего не сделаем, не зная устройства конкретного map. В противном случае мы можем предоставить специализированную реализацию. Если посмотреть на реализацию данного метода в Java 8, то видно, что во многих map специализация имеется:
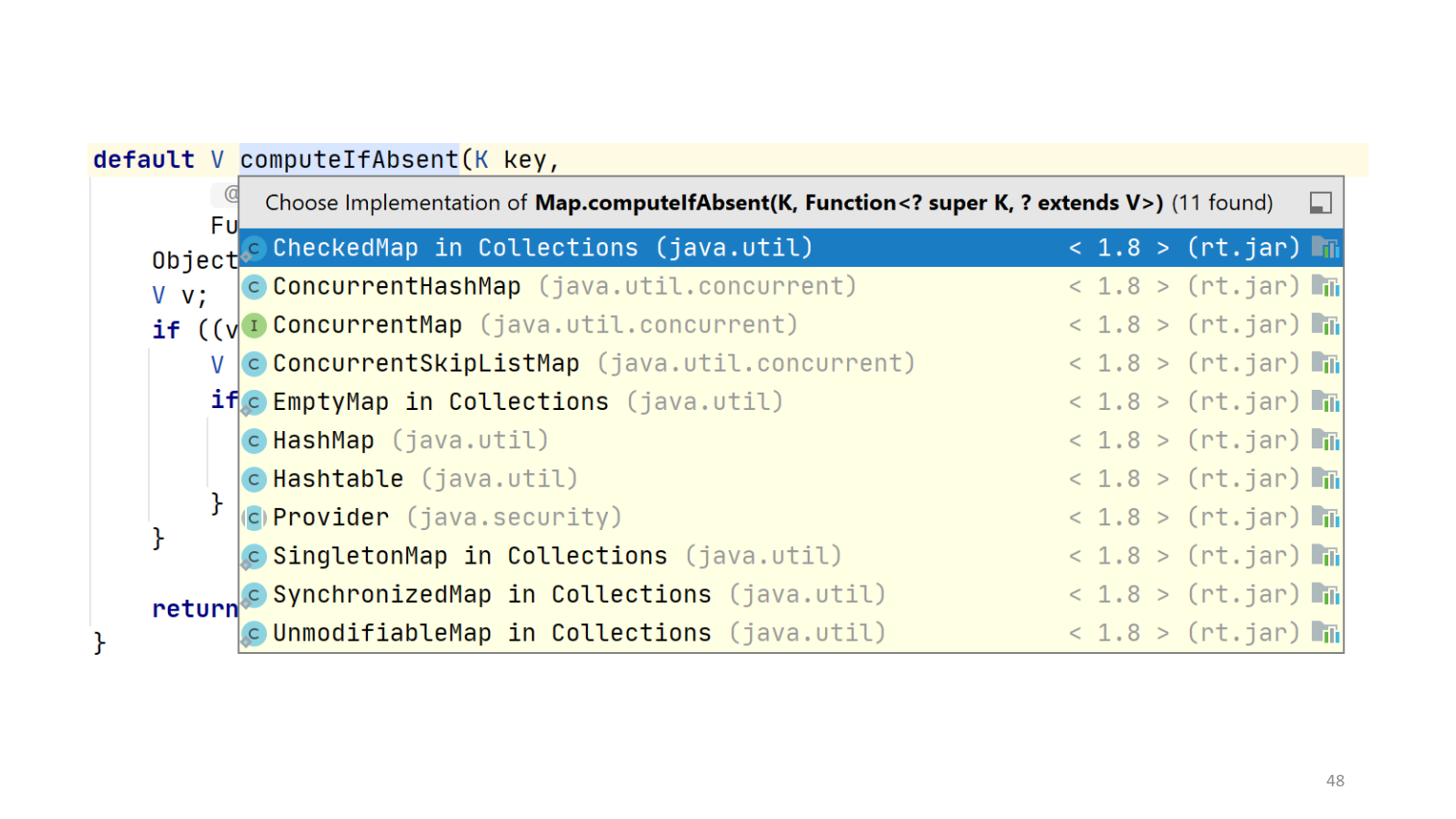
А для TreeMap реализации нет. А ведь поиск в нем — недешевая операция с логарифмической сложностью, потому что там красно-чёрное дерево. В реализации по умолчанию поиск приходится делать дважды, хотя в оптимальной можно пройти по дереву всего один раз, найти подходящий узел и после вызова пользовательской функции не искать узел повторно.
Сергей Куксенко предложил оптимальную реализацию еще в 2017 году, когда шла работа над Java 10. Было несколько комментариев на Code Review, но потом дело заглохло. В 2019 году я подхватил патч и довел до конца, попутно исправив один баг в исходной реализации и добавив реализацию метода merge (), тесты и бенчмарки. Патч добрался до Java 15, и бенчмарки показывают, что работа не была напрасной:
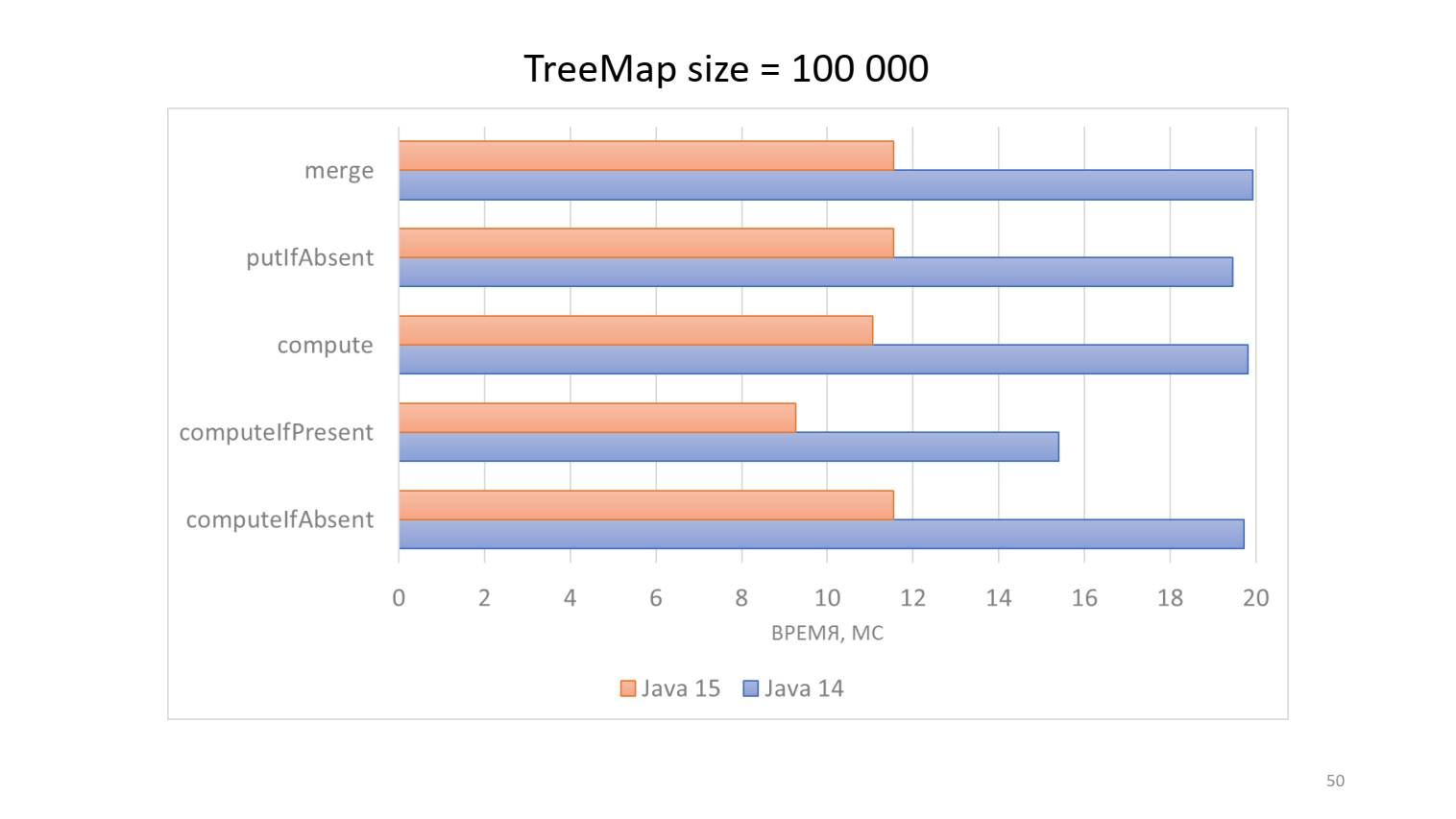
Это специальный показательный показательный бенчмарк, в котором каждый раз происходит два обращения к ключу. То есть в map в computeIfAbsent () изначально значений не было, и они туда добавляются. А в computeIfPresent () значения уже были, и их модифицировали. Для маленьких map эффект будет меньше, потому что глубина дерева меньше, но 10–20% мы выигрываем даже на них.
У патча есть и обратная сторона. Чтобы ее проиллюстрировать, сделаем то, что рано или поздно многие программисты делают, только стесняются говорить — подсчет чисел Фибоначчи.
public BigInteger fibo(int arg) {
if (arg < 1) {
throw new IllegalArgumentException();
}
if (arg <= 2) {
return BigInteger.ONE;
}
return fibo(arg - 1).add(fibo(arg - 2));
}
public static void main(String[] args) {
Fibo fibo = new Fibo();
System.out.println(fibo.fibo(100));
}Совершенно без стыда напишем наивный рекурсивный алгоритм и запустим вычисление с аргументом 100. Программа надолго задумалась, и ждать смысла нет. Закэшируем:
Map map = new HashMap<>();
private BigInteger calcFibo(int arg) {
if (arg < 1) {
throw new IllegalArgumentException();
}
if (arg <= 2) {
return BigInteger.ONE;
}
return fibo(arg - 1).add(fibo(arg - 2));
}
public BigInteger fibo(int arg) {
BigInteger value = map.get(arg);
if (value == null) {
value = calcFibo(arg);
map.put(arg, value);
}
return value;
} Делаем метод приватным, переименовываем его, а в публичный метод вставляем HashMap. При этом calcFibo () рекурсивно обращается к кэшу, поэтому каждое предыдущее число считается один раз, и мы не получаем экспоненциального взрыва, так что программа быстро выдаст правильный ответ.
Проверим, работает ли наш кэш:
public static void main(String[] args) {
Fibo fibo = new Fibo();
System.out.println(fibo.fibo(100));
// 354224848179261915075
System.out.println(fibo.map.get(100));
// 354224848179261915075
}Там действительно лежит наше число. Если мы второй раз будем считать число Фибоначчи от 100, то программа просто возьмет значение из map. Посчитаем, сколько записей в нашей map:
System.out.println(fibo.map.size());
// 100 И действительно в ней всего 100 записей. Приятно, когда программа работает, как ожидаешь.
Однако это код в стиле Java 7. Давайте используем более современные методы. Сама IntelliJ IDEA предлагает заменить if в методе fibo () на computeIfAbsent (), что мы и сделаем:
public BigInteger fibo(int arg) {
return map.computeIfAbsent(arg, this::calcFibo);
}В итоге весь метод свернулся в одну строку, и программа продолжает быстро работать. Однако поиск нашего числа в кеше теперь возвращает null. Странно. Размер map теперь составляет 185. Программа ведет себя совсем не так, как ожидалось.
На самом деле наша map оказалась сломанной, и такова цена оптимизации. Когда мы находимся внутри метода, мы должны сделать get () и put (), но не хотим проходить по хеш-таблице два раза.
У метода computeIfAbsent () довольно сложный код, поэтому посмотрим лишь на его алгоритм:
- Найти место в хэш-таблице.
- Если там есть запись, вернуть значение из неё.
- Иначе вызвать функцию mappingFunction ().
- Если функция вернула null, вернуть null.
- Иначе создать запись и поместить её в ранее найденное место.
- При необходимости увеличить хеш-таблицу.
- Увеличить size на 1.
- Вернуть то, что вернула функция на шаге 3.
Это хорошо работает, если наша функция не модифицирует map, однако в редких случаях это не так. В случае с Фибоначчи функция рекурсивно вычисляет одно из предыдущих чисел и кэширует его тоже. В результате на предыдущем расчете хеш-таблица могла быть увеличена, то есть мог быть выделен новый массив, а старый уже никому не нужен. А здесь на шаге 5 мы создаем запись в старом массиве, который уже не проверяем.
Также могло оказаться, что мы уже на предыдущих шагах рекурсии уже посчитали текущее значение и засунули его в map, увеличив размер массива на 1. Поэтому HashMap стал сломанным. При этом алгоритм устроен так, что поломка HashMap не приводит к неправильному результату.
В Java 9, к счастью, эту проблему решили. Ну как решили: теперь код стал выкидывать ConcurrentModificationException. Зато благодаря этому все HashMap остаются целыми.
Если мы всё-таки очень хотим computeIfAbsent (), мы можем использовать TreeMap вместо HashMap, ведь, как мы выяснили, метод имеет в TreeMap неоптимизированную реализацию по умолчанию. Это хорошо работает в Java 8–14, но в Java 15 снова выскакивает та же ошибка, ведь теперь у метода есть моя оптимизированная реализация.
Получается, в таких сценариях метод computeIfAbsent () не подходит, и идея провалилась. Даже в документации указано, что
The mapping function should not modify this map during computation.
ArrayList.removeIf
Метод removeIf () появился в Java 8 у всех коллекций, и его реализация по умолчанию выглядит так:
default boolean removeIf(Predicate filter) {
Objects.requireNonNull(filter);
boolean removed = false;
final Iterator each = iterator();
while (each.hasNext()) {
if (filter.test(each.next())) {
each.remove();
removed = true;
}
}
return removed;
} Мы создаем итератор, бежим им по коллекции, затем с помощью Iterator.remove () удаляем элементы, которые успешно прошли фильтр, а затем обновляем булеву переменную removed, чтобы сообщить, удалось ли удалить элемент. Такой код до Java 8 мы писали вручную, и теперь это не нужно.
Прелесть default-методов и в том, что их можно переопределить в конкретных классах и сделать более оптимальную реализацию. В ArrayList этот метод был переопределен еще в Java 8, но в Java 9 его улучшили. Измерим производительность, а затем посмотрим на реализацию.
Бенчмарк будет простым: создадим ArrayList, закинем в него числа от 0 до size-1 и будем удалять элементы:
data = new ArrayList<>();
for (int i = 0; i < size; i++) {
data.add(i);
}Проведем несколько бенчмарков, в которых будем копировать массив из эталона, а затем удалять элементы. Результаты удаления могут зависеть от количества удаляемых элементов и их расположения, поэтому сделаем несколько тестов:
removeAll: list.removeIf(x -> true);
removeHalf: list.removeIf(x -> x % 2 == 0);
removeLast: list.removeIf(x -> x == size - 1);
removeFirst: list.removeIf(x -> x == 0);
removeNone: list.removeIf(x -> false);Посмотрим, сколько времени занимает выполнение ArrayList.removeIf () в Java 8 со средним размером 1000 элементов:
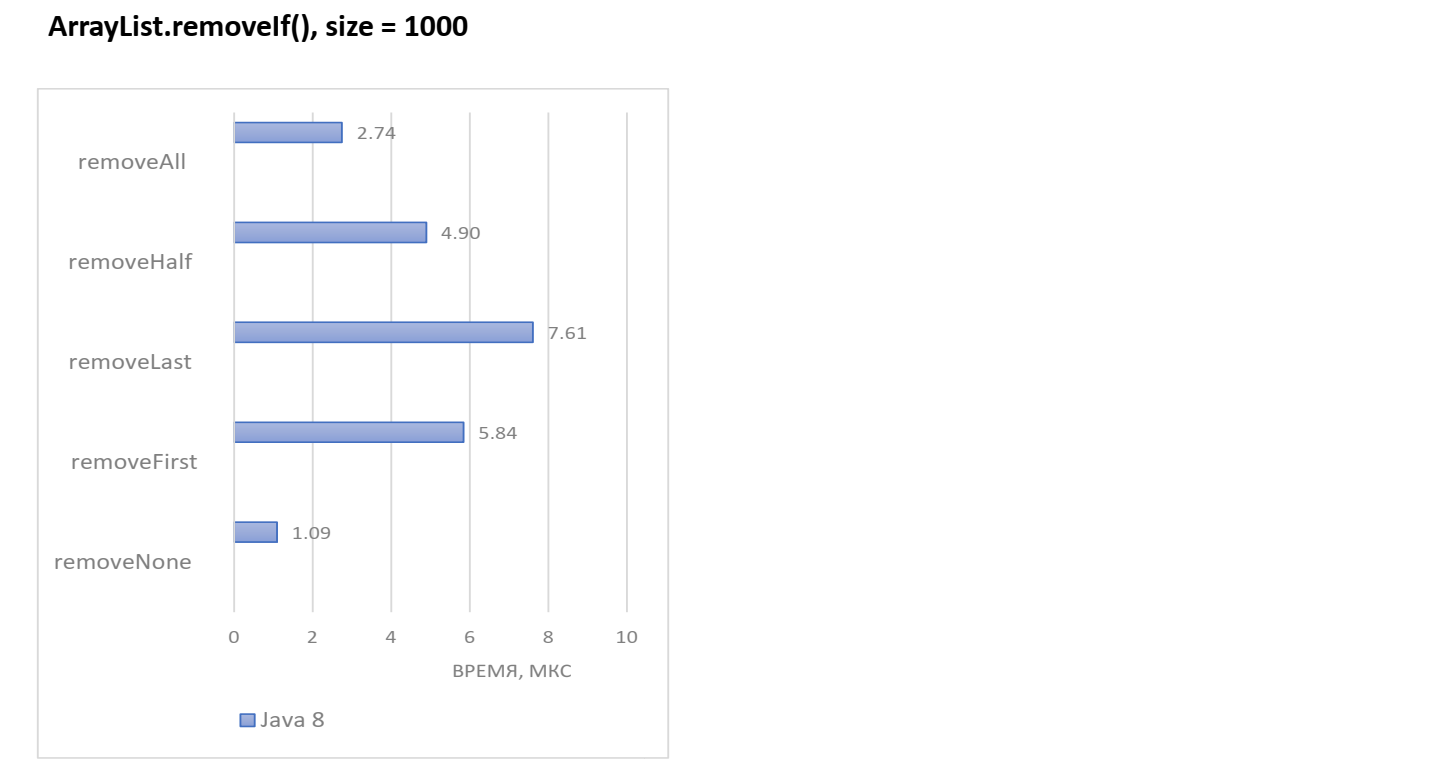
Выглядит разумно, что removeAll победил removeHalf и removeFirst. Мы помним, что внутри ArrayList лежит обычный массив. Если удалить первый элемент, то весь массив необходимо сдвигать. В случае же удаления всего массива необходимо просто занулить все элементы. Однако удаление последнего элемента заняло больше всего времени, хотя кажется, что достаточно занулить последний элемент.
Обернем наш ArrayList в subList, содержащий все элементы, и снова замерим производительность:

Теоретически картина не должна была сильно меняться. Но на практике мы видим существенную разницу во всех тестах. В removeAll мы проигрываем более чем в 20 раз, в removeHalf — примерно в 6 раз. Но зато removeLast и removeFirst с subList работает в разы быстрее.
В чем секрет «длинных» графиков? В Java 8 subList (0, size).removeIf () не реализован вообще, и используется default-реализация с итераторами. Поэтому когда мы удаляем много элементов, каждое удаление двигает хвост массива, и в итоге мы имеем квадратичную сложность.
Посмотрим на результаты тех же тестов в Java 9:

Значения с subList и без него почти одинаковы, и все отличия в рамках погрешности, потому что в Java 9 о subList тоже подумали. Приятно, что исчезли огромные выбросы. Да и логика восторжествовала: removeLast перешел на второе место после removeNone. Хоть это решение выглядит более оптимальным, но оно проигрывает по производительности subList в removeFirst в Java 8. Разгадаем загадку таких странных графиков.
Реализация removeIf () в Java 8 состоит из двух кусков:
public boolean removeIf(Predicate filter) {
Objects.requireNonNull(filter);
// figure out which elements are to be removed
// any exception thrown from the filter predicate at this stage
// will leave the collection unmodified
int removeCount = 0;
final BitSet removeSet = new BitSet(size);
final int expectedModCount = modCount;
final int size = this.size;
for (int i=0; modCount == expectedModCount && i < size; i++) {
@SuppressWarnings("unchecked")
final E element = (E) elementData[i];
if (filter.test(element)) {
removeSet.set(i);
removeCount++;
}
}
if (modCount != expectedModCount) {
throw new ConcurrentModificationException();
}
// shift surviving elements left over the spaces
// left by removed elements
final boolean anyToRemove = removeCount > 0;
if (anyToRemove) {
final int newSize = size - removeCount;
for (int i=0, j=0; (i < size) && (j < newSize); i++, j++) {
i = removeSet.nextClearBit(i);
elementData[j] = elementData[i];
}
for (int k=newSize; k < size; k++) {
elementData[k] = null; // Let gc do its work
}
this.size = newSize;
if (modCount != expectedModCount) {
throw new ConcurrentModificationException();
}
modCount++;
}
return anyToRemove;
}В первом куске мы пробегаем по массиву, опрашиваем фильтр и заполняем BitSet, выставляя биты тем элементам, которые хотим удалить. Казалось бы, мы могли бы удалять сразу из массива без BitSet, но тогда в промежутках ArrayList был бы поломан. Так как в процессе мы вызываем пользовательскую функцию, поломанный ArrayList могут увидеть извне. Поэтому было решено делать все модификации после фильтрации. Тогда наш предикат будет видеть исходное состояние списка при чтении. Это отличается от поведения default-метода, где предыдущие модификации предикату видны.
Потом мы пробегаем по сформированному BitSet и стандартным методом двух курсоров выкидываем удаленные элементы. Затем циклом зануляем хвост, чтобы GC смог собрать удаленные объекты.
Становится понятно, почему removeLast был медленнее всего. В этом случае мы должны пробежать по всему BitSet в цикле:
for (int i=0, j=0; (i < size) && (j < newSize); i++, j++) {
i = removeSet.nextClearBit(i);
elementData[j] = elementData[i];
}Каждый раз мы находим пустой бит, кроме последнего, читаем элемент и его перезаписываем, не производя никакой полезной работы. И только в конце мы зануляем единственный удаленный элемент.
А removeAll в первый цикл вообще не заходит, потому что newSize равен 0. Он просто зануляет весь массив во втором цикле, который к тому же хорошо векторизуется.
for (int k=newSize; k < size; k++) {
elementData[k] = null; // Let gc do its work
}Что произошло в Java 9? Во-первых, реализация переехала в закрытый метод, которому передается начало и конец массива, который надо обойти. Благодаря этому метод может использоваться и для subList.
boolean removeIf(Predicate filter, int i, final int end) {
Objects.requireNonNull(filter);
int expectedModCount = modCount;
final Object[] es = elementData;
// Optimize for initial run of survivors
for (; i < end && !filter.test(elementAt(es, i)); i++)
;
// Tolerate predicates that reentrantly access the collection for
// read (but writers still get CME), so traverse once to find
// elements to delete, a second pass to physically expunge.
if (i < end) {
…
} else {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
return false;
}
}Заметьте, что параметр i нещадно используется как счетчик цикла внутри метода вопреки всем канонам красивого программирования, но ради производительности.
Из этого кода видно, что сделана очень важная оптимизация — мы проматываем серию элементов в начале списка в случае, если фильтр возвращает false. В частности, если удаления нет, то цикл просто проматывается до конца, и больше ничего не делаем.
Основная часть метода проходит в условии, если фильтр что-то нашел:
if (i < end) {
final int beg = i;
final long[] deathRow = nBits(end - beg); // new long[((n - 1) >> 6) + 1];
deathRow[0] = 1L; // set bit 0
for (i = beg + 1; i < end; i++)
if (filter.test(elementAt(es, i)))
setBit(deathRow, i - beg); // bits[i >> 6] |= 1L << i;
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
modCount++;
int w = beg;
for (i = beg; i < end; i++)
if (isClear(deathRow, i - beg)) // (bits[i >> 6] & (1L << i)) == 0;
es[w++] = es[i];
shiftTailOverGap(es, w, end);
return true;
} else { … }Чтобы избежать лишнего объекта, здесь сделан BitSet «на коленке». С помощью статических элементов nBits (), setBit () и isClear мы напрямую выделяем массив long и оперируем в нем битами. Да, экономия на спичках, но для базового класса это допустимо.
Наш примитивный BitSet начинается уже с первого найденного элемента, а не с начала списка. Поэтому в removeLast мы выделим всего один элемент, заодно упростив жизнь сборщику мусора.
Заметим, что кое в чем мы проиграли. В прошлый раз мы отслеживали число удалений, благодаря чему мы знали, когда хвост BitSet содержит только удаленные элементы, и прекращали по нему бежать. В этот раз такая оптимизация не была сделана.
Подведем итог бенчмарков в Java 9. В Java 9 быстродействие более ровное и меньше зависит от того, что мы удаляем. Мы выигрываем, если удаляем элементы ближе к концу либо если удаляем очень много элементов. И существенное улучшение в одних случаях привело к небольшому ухудшению в других.
hashSet.removeIf ()
Попробуем теперь удалять не из ArrayList, а из HashSet. Сперва нужно добавить что-то ненужное. Положим в HashSet списки целых чисел: [], [0], [0, 1] и т. д.:
HashSet> set;
@Setup
public void setup() {
set = IntStream.range(0, 1000)
.mapToObj(i -> IntStream.range(0, i).boxed().collect(Collectors.toList()))
.collect(Collectors.toCollection(HashSet::new));
} Так как мы хотим удалять много раз, нам нужно восстанавливать HashSet в исходное положение. Поэтому бенчмарк будет выглядеть так:
@Benchmark
public Set> removeHalf() {
Set> copy = new HashSet<>(set);
copy.removeIf(list -> list.size() > 500);
return copy;
}
@Benchmark
public Set> noRemove() {
return new HashSet<>(set);
} Второй бенчмарк только копирует, но ничего не удаляет. Оценим скорость копирования в Java 8:
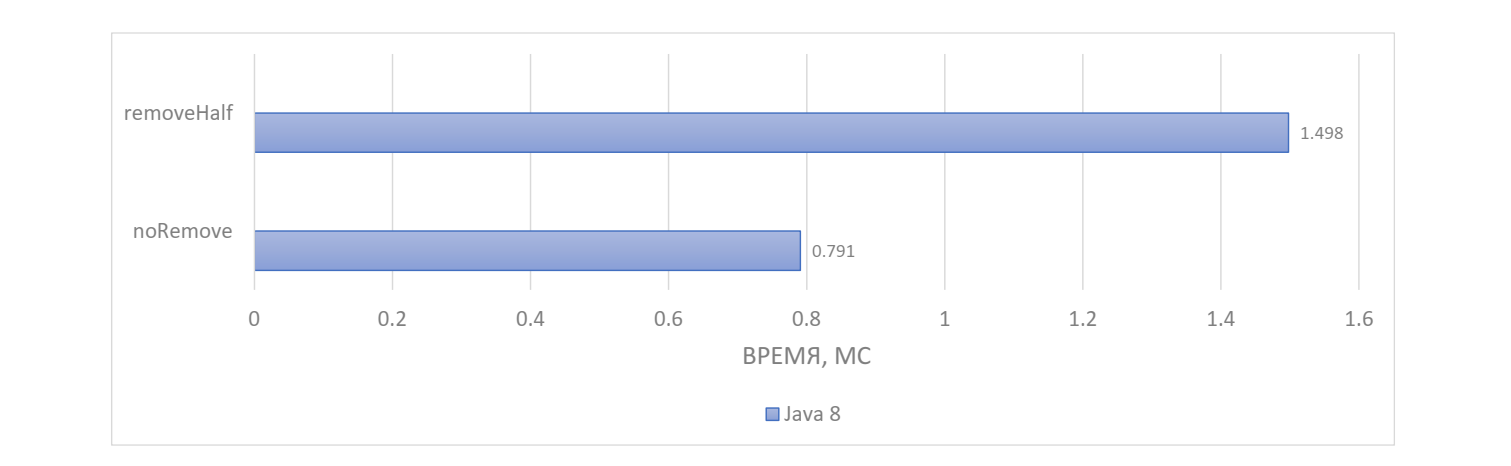
Получаем, что копирование + удаление длится вдвое дольше, чем просто копирование. Следовательно, удаление по расходу ресурсов близко к копированию, что довольно накладно.

В Java 9 удаление стало значительно быстрее, и уже около 10% времени уходит на удаление. Как же этого добились? Наверное, снова хитрую реализацию HashSet.removeIf () сделали? Однако специализированной реализации вообще нет. Вместо этого используется стандартная реализация Collection.removeIf (), которая делегирует к HashSet.iterator ().remove (). HashSet.iterator ().remove () делегирует далее к HashMap.keySet ().iterator ().remove (). Как мы помним, в HashSet лежит обычный HashMap с default-значением, где мы используем ключи как set. Далее мы переходим к HashMap.KeyIterator.remove (), но в нем нет метода remove (). Дело в том, что по HashMap можно создавать разные итераторы: keySet ().iterator (), valueSet ().iterator (), entrySet ().iterator (), но удаление будет работать одинаково, поэтому оно вынесено в общий суперкласс.

Разгадка кроется в родительском классе HashIterator. Что же там оптимизировали, что удаление стало быстрее? В нем удалили две строчки и добавили одну:

Внутреннему методу removeNode (), который и выполняет удаление, передается хеш ключа. До Java 9 хеш вычислялся заново по ключу, хотя в этом особого смысла не было, потому что хеш уже хранится в доступном узле.
Понятно, что я схитрил с бенчмарком. Я создал множество списков, а списки свой хеш не хранят и каждый раз вычисляют заново. Во многих случаях хеш-код вычисляется быстро или кэшируется, поэтому разница не так заметна, но в таких сценариях становится просто гигантской.
Благодаря тому, что этот метод много где используется, эффект можно наблюдать во многих случаях. Если вы прямо или косвенно пользуетесь удалением через итератор, в любой коллекции, производной от HashMap или LinkedHashMap, вы пройдете через этот метод.
HashMap.containsKey
Схожая оптимизация появилась в Java 15 и касается пустых Map. Бенчмарк будет такой:
HashMap, String> emptyMap;
HashMap, String> nonEmptyMap;
List key;
@Setup
public void setup() {
emptyMap = new HashMap<>();
nonEmptyMap = new HashMap<>();
nonEmptyMap.put(Collections.emptyList(), "");
key = IntStream.range(0, 500).boxed().collect(Collectors.toList());
}
@Benchmark
public boolean containsInEmpty() {
return emptyMap.containsKey(key);
}
@Benchmark
public boolean containsInNonEmpty() {
return nonEmptyMap.containsKey(key);
} Мы создали два HashMap. Один из них будет пустой, а в другой сложим один элемент. Мы проверяем наличие ключа со сложным хеш-кодом, например, список из 500 чисел. В результате мы получаем:
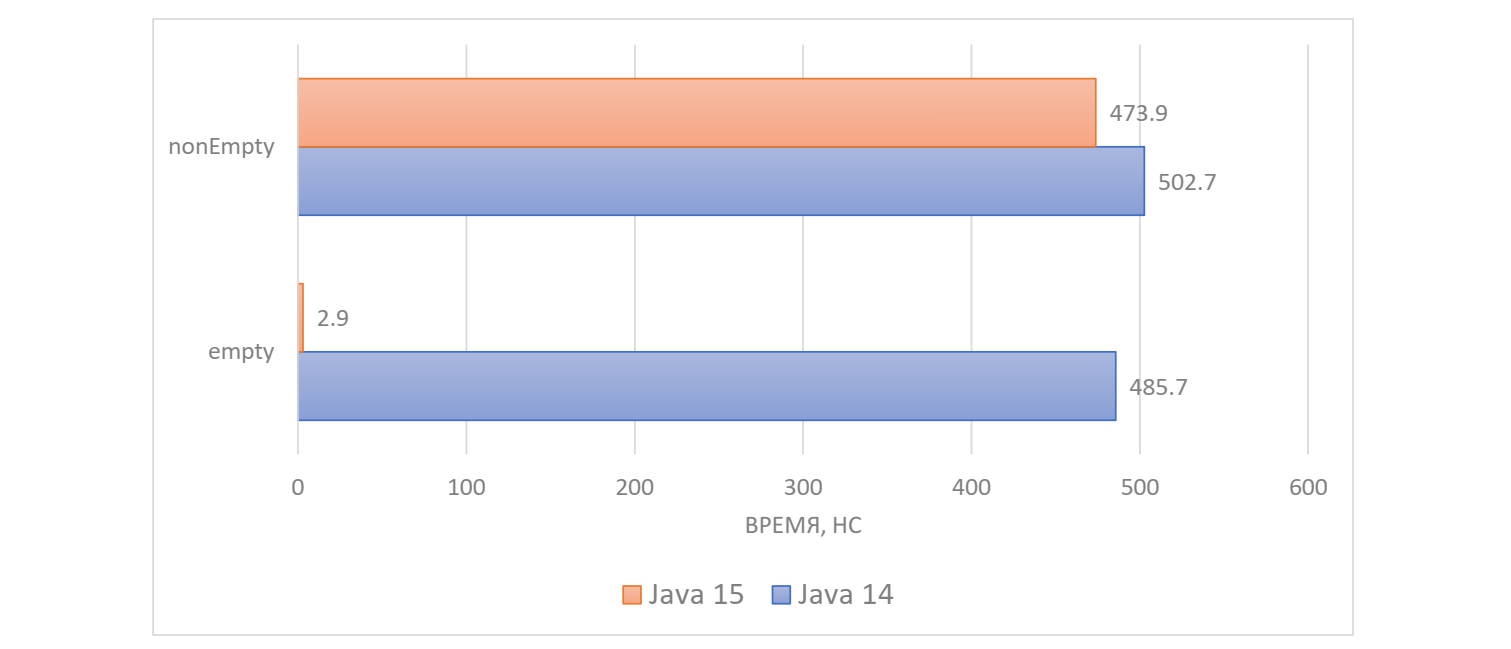
В Java 14 мы тратим около 500 нс и с пустым, и с непустым списком, а в Java 15 с пустым списком уходит всего около 3 нс. Очевидно, что не нужно считать хеш-код, если список пустой.
Здесь исправление очень простое, хоть и нетривиальное. Важной частью реализации HashMap является метод getNode (), который ищет элемент в хеш-таблице по ключу. До Java 15 он принимал сразу хеш и ключ, то есть хеш должен был вычислить тот, кто вызывает этот метод.
final Node getNode(int hash, Object key) {
Node[] tab; Node first, e; int n; K k;
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
…
}
return null;
} А в Java 15 расчет хеш-кода перенесли внутрь getNode (). Это не только упростило использование метода, но и позволило отложить вычисление хеш-кода до того, как оно потребуется. А хеш-код может вообще не потребоваться, если таблица пустая.
final Node getNode(Object key) {
Node[] tab; Node first, e; int n, hash; K k;
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & (hash = hash(key))]) != null) {
…
}
return null;
} Соответственно поменялись все точки вызова, в результате чего ускорился не только containsKey (), но и get () и getOrDefault (). Но за эту оптимизацию тоже пришлось заплатить цену.
Метод computeIfPresent () применяет функцию для существующего ключа и заменяет ее значение. А если функция вернула null, то значение надо удалить. И в этом редком случае ключ теперь нужно вычислять дважды.
Для демонстрации напишем бенчмарк. Чтобы он был стабильным, мы добавляем в пустой map один элемент и тут же удаляем его через computeIfPresent ().

Конечно, computeIfPresent () тоже можно переписать, заинлайнив getNode (), чтобы повторного вычисления не требовалось, но это усложнит код, и на эту деградацию скрепя сердце пошли. Все-таки computeIfPresent () используется редко, а возвращает null еще реже.
Class.getSimpleName ()
Поговорим про Reflection. У класса есть имя, и так сложилось, что оно может быть разное. Есть три разных метода получения имени: class.getName (), class.getCanonicalName (), class.getSimpleName (). Class.getName () возвращает имя, разделенное точками, а потом имя JVM-класса. Class.getCanonicalName () возвращает имя класса, где вложенный класс отделяется точками, как в исходниках Java-программы. Class.getSimpleName () возвращает имя класса без пакета и окружающих классов. Проверим, какой же из этих методов быстрее:

В Java 8 getName () работает почти мгновенно, и кажется, что имя кешируется. Методы getCanonicalName () и getSimpleName () возвращаются не так быстро, причем скорость зависит от того, вложенный ли класс или же верхнего уровня. Явно значения считаются на лету, а не берутся из кеша.
В Java 11 все стало гораздо быстрее, и явно значения стали кешировать. Однако getCanonicalName () и getSimpleName () все равно работают на 1,3 нс медленнее, чем getName (). Разберемся, откуда взялась разница.
public String getName() {
String name = this.name;
if (name == null)
this.name = name = getName0();
return name;
}
// cache the name to reduce the number of calls into the VM
private transient String name;
private native String getName0();В getName () мы видим обычную процедуру кеширования в поле. Даже в случае гонки несколько потоков просто вызовут getNam
