Лучшая архитектура на базе Docker и Kubernetes — миф или реальность?
Как изменился мир разработки ПО в эпоху Docker и Kubernetes? Можно ли построить архитектуру один раз и навсегда на базе этих технологий? Возможно ли унифицировать процессы разработки и интеграции, когда все «упаковано» в контейнеры? Какие требования предъявляются таким решениям? Какие ограничения несут они с собой? Упростят ли они жизнь простым разработчикам или сделают её тяжелее?
Пришло время ответить на все эти и не только эти вопросы! (В тексте и оригинальных иллюстрациях)
Данная статья проведет вас по кругу от реальной жизни к процессам разработки и через архитектуру вернет в реальную жизнь, отвечая по ходу на важнейшие вопросы в каждом из этих секторов. Также я попробую обозначить ряд компонент и принципов, которые должны стать частью архитектуры, не вдаваясь в конкретные имплементации, а лишь приводя примеры возможных доступных решений.
Окончательное заключение о вопросе из заголовка статьи может вас расстроить, ровно как и очень порадовать других читателей — все будет зависеть от вашего опыта, того как вы воспримите нижеследующий рассказ из трех глав и, вполне вероятно, настроения в этот день, поэтому не стесняйтесь здоровых дискуссий и вопросов после прочтения!
Оглавление
- От реальной жизни к процессам разработки
- Установка среды разработчика
- Автоматизированное тестирование
- Доставка систем
- Непрерывность в интеграции и доставке
- Система отката
- Обеспечение информационной безопасности и аудит
- От процессов к архитектуре
- Микросервисная архитектура
- Важнейшие компоненты и решения экосистемы
- Identity сервис
- Автоматизированный провижининг серверов
- Git репозиторий и таск трекер
- Docker Registry
- CI/CD сервис и система доставки сервисов
- Система сбора и обработки логов
- Tracing Система
- Мониторинг и алертинг
- API шлюз и Single Sign-on
- Шина событий (Event Bus) и шина интеграций (Enterprise Integration/Service Bus)
- Базы данных и другие Stateful сервисы
- Зеркала зависимостей
- От архитектуры к реальной жизни
От реальной жизни к процессам разработки
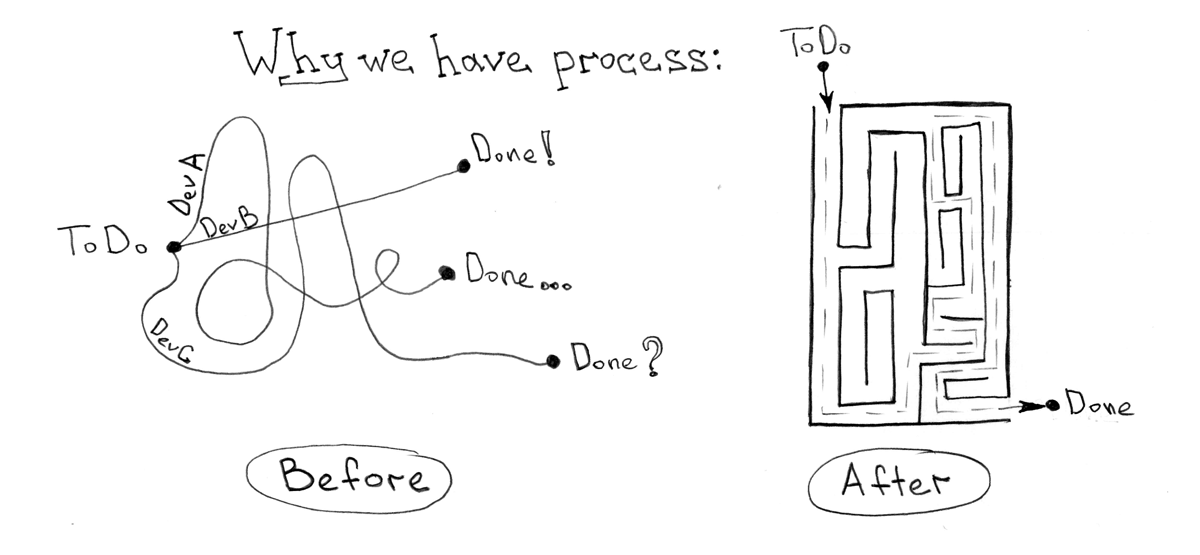
В большинстве своем, все процессы разработки, которые я когда либо видел или был удостоен устанавливать/настраивать, служат, по сути, одной простой цели — сократить время между рождением идеи и ее доставки в «боевое» окружение при какой-то заданной, в общем случае константной, величине качества кода.
А уж плохая это идея или хорошая совершенно не важно. Плохие идеи обычно ускоряют, дабы проверить и затем отказаться и, возможно, по-быстрому дезинтегрировать. Что важно сказать тут, так это то, что процесс отката на предыдущую версию (без этой «безумной» идеей) тоже ложится на плечи робота, которым автоматизированы ваши процессы.
Непрерывная интеграция и доставка, обычно, кажутся спасательным кругом в мире разработки. Чего казалось бы проще? Есть идея, есть код — поехали! Все бы хорошо, если бы не одно большое «НО». Как показывает мой опыт, процесс интеграции и доставки довольно сложно формализовать в отрыве от используемых технологий и бизнесс-процессов протекающих в компании.
Не смотря на всю кажущуюся сложность задачи, мир постоянно подкидывает отличные идеи и технологии, приближающие нас (ну лично меня уж точно…) к утопическому и идеальному механизму, который бы сгодился для практически любого случая. Следующий шаг на пути к этому — Docker и Kubernetes. Уровень абстракции и идеологический подход дают мне право сказать, что 80% задач теперь можно решить практическими одними и теми же методами.
20% никуда, естественно, не делись. Но это как раз та область, где интересно работать и творить, а не заниматься одними и теми же рутинным проблемами архитектуры и процессов. Поэтому, сконцентрировавшись единожды на «архитектурном каркасе», мы можем позабыть (без ущерба для дела) о необходимости возвращаться к этим 80% решенных проблем
Что же все это значит, и как Docker решает проблемы наших процессов разработки?
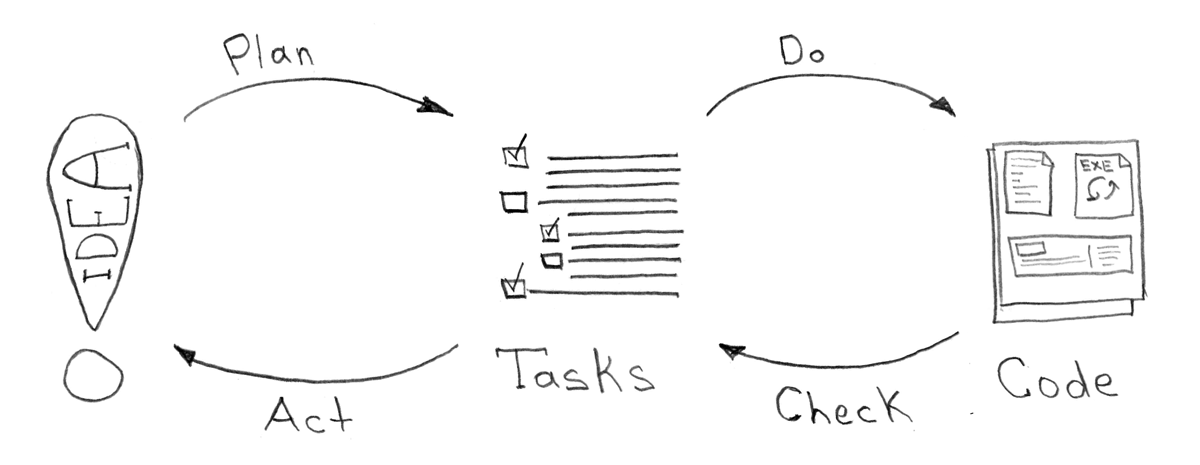
Возьмем простой процесс разработки, который я также предлагаю рассматривать как и вполне достаточный в подавляющем большинстве случаев:
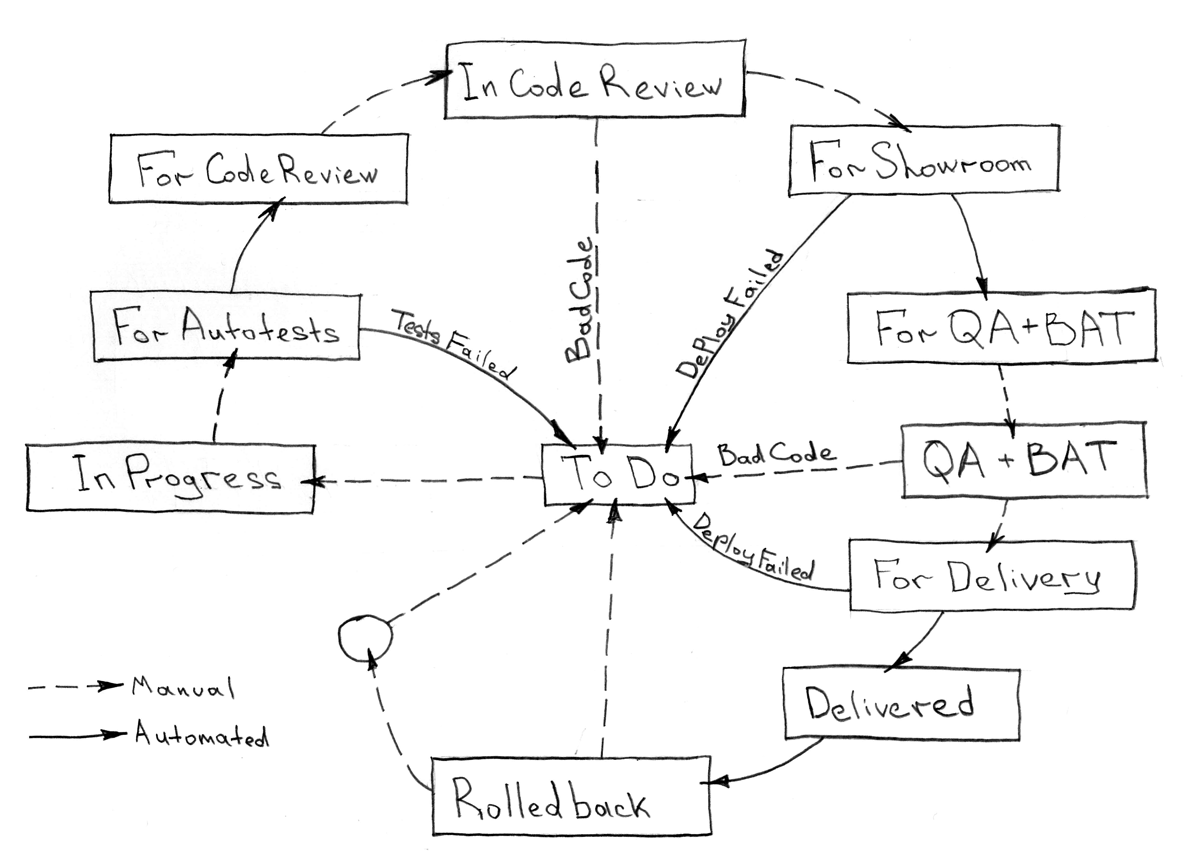
Все, что должно быть автоматизировано из данной последовательности этапов любой задачи, вполне себе может быть унифицировано и не требовать изменений при должном подходе на протяжении времени.
Установка среды разработчика
Любой проект должен содержать в себе docker-compose.yml. Он легко избавит разработчика от необходимости думать о том, как и что ему нужно делать, чтобы запустить ваше приложение/сервис на локальной машине. Простая команда docker-compose up должна включать это приложение со всеми зависимостями, наполнять базу данных фикстурами, подключать локальный код внутрь контейнера, включать слежку над кодом для компиляции на лету и в конечном итоге отвечать на ожидаемом порту.
Если же речь идет о создании нового сервиса, то разработчик так же не должен задаваться вопросами о том как начать, куда коммитить или какие фреймворки выбрать. Все это должно быть заблаговременно описано в инструкциях-стандартах и продиктовано шаблонами сервисов для разных случаев: frontend, backend, worker и других типов.
Автоматизированное тестирование
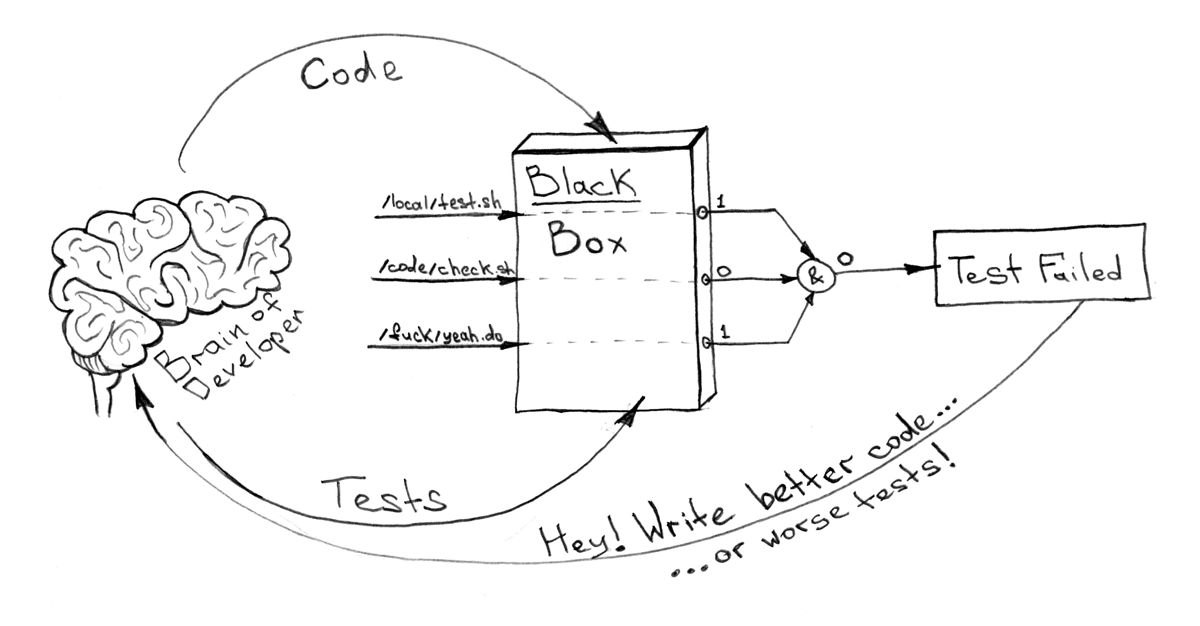
Все что хочется знать о «черной коробочке» (почему мы так называем контейнер я расскажу чуть позже), так это то, что внутри нее все впорядке. Да или нет. 1 или 0. При наличии конечного числа команд, которые нужно выполнить внутри контейнера, и docker-compose.yml, описывающего зависимости, это легко можно автоматизировать и унифицировать особо не погружаясь в детали имплементации.
Например, вот так!
Здесь под тестированием я имею ввиду не только, и не столько юнит, но и любое другое тестирование, включая функциональное, интеграционное, тестирование кода на стиль (code style) и дублирование, проверку устаревших зависимостей, нарушение лицензий используемых пакетов, и много всего прочего. Акцент стоит поставить на то, что все это должно быть инкапсулировано внутрь вашего Docker образа.
Доставка систем
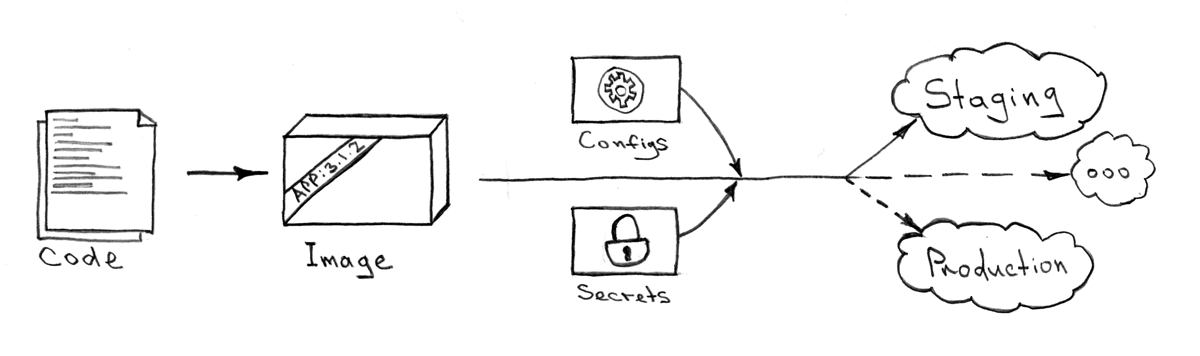
Не важно когда и куда вы хотите установить ваше детище. Результат, ровно как и процесс установки, должен быть всегда один и тот же. Нет так же разницы какую часть всей экосистемы или из какого git репозитория вы будете это делать. Идемпотентность здесь является наиважнейшей составляющей. Единственное что должно быть задано — это переменные управляющие установкой.
Алгоритм, который мне кажется наиболее эффективным, для решения такой задачи:
- Собрать образы из всех
Dockerfile-ов (Например, вот так) - C помощью мета-проекта доставить эти образы в Kubernetes по средствам Kube API. Запуск доставки обычно требует несколько входных параметров:
- Kube API endpoint
- ресурс секретов — обычно они отличаются для разных контекстов (local/showroom/staging/production)
- имена систем для выкладки и тэги Docker образов для этих систем (полученных на предыдущем шаге)
В качестве такого единого на все системы и сервисы мета-проекта (проекта описывающего как устроена экосистема и каким образом в нее доставляются изменения), я предпочитаю использовать Ansible playbook-и c данным модулем для интеграции с KubeAPI. Однако, искушенные автоматизаторы могут позволить себе и множество других вариантов — я приведу свои чуть ниже. Единственное о чем не стоит забывать, так это о централизованном/унифицированном способе управления архитектурой. Это позволяет удобно и единообразно управлять всеми сервисами/системами и купировать на взлете любые проявления грядущего зоопарка из технологий и систем выполняющих похожие функции.
Обычно установка среды требуется в:
- «ShowRoom» — для каких-то ручных проверок или отладки системы
- «Staging» — для почти боевого окружения и интеграций с внешними системами (обычно находится в DMZ в отличие от
ShowRoom-ов) - «Production» — собственно окружение для конечного пользователя
Непрерывность в интеграции и доставке

Имея унифицированный способ тестирования «черных коробочек» — наших Docker образов, мы должны считать, что результат полученный такими тестами разрешает нам беспроблемно и с чистой совестью интегрировать feature-branch в upstream или master ветку git репозитория.
Единственным камнем преткновения при таком подходе становится то, в какой последовательности мы должны делать интеграцию и доставку. А при отсутствии релизов остро встает вопрос о том, как предотвратить «race condition» на одной системе при множестве параллельных feature-branch.
Следующий процесс обязательно должен быть запущен в режиме отсутствия конкуренции, иначе «race condition» не будет давать вам покоя:
- Пытаемся обновить
feature-branchдоupstream(git rebase/merge) - Собираем образы из
Dockerfile-ов - Тестируем все собранные образы
- Запускаем и дожидаемся окончания доставки необходимых систем с образами из шага 2
- Если предыдущий шаг оборвался или из-за внешних факторов, производим откат эко-системы к предыдущему состоянию
- Сливаем
feature-branchвupstreamи отправляем в репозиторий
Любой сбой и на любом шаге должен обрывать процесс доставки и возвращать задачу разработчику для решения проблемы, будь то «не прошедшие» тесты или проблемы слияние веток.
Этот же рецепт подразумевает возможность работы с более чем одним репозиторием. Для этого весь процесс должен выполняться для всех репозитория в порядке шагов алгоритма, а не многократно и итеративно для каждого репозитория в отдельности
Помимо всего прочего Kubernetes позволяет выкатывать обновления частично для проведения различных AB тестов и анализа проблем. Это достигается внутренними средствами и разделением сервисов (точек доступа) и непосредственно приложений. Вы всегда можете сбалансировать новую и старую версию компоненты в нужных пропорциях для анализа проблем и возможного отката.
Система отката
Любой деплой должен быть обратим — это обязательное требование которое предъявляется к нашему архитектурному каркасу. Это влечет за собой много явных и не очень нюансов разработки систем.
Вот часть наиболее важных из них:
- Сервис должен уметь настраивать свое окружение ровно как и откатывать изменения. Например: миграции БД, схема в RabbitMQ, и т.д.
- В случае невозможности откатить окружение, оно должен быть полиморфным и поддерживать как старую так и новую версию кода. К примеру: миграции БД не должны нарушать работу старой версии сервиса в нескольких поколениях (обычно достаточно 2 или 3 поколения)
- Обратная совместимость любого обновления сервиса. Обычно это: API совместимость, форматы сообщений, и т.д.
Откатывать состояния в Kubernetes кластере довольно просто (kubectl rollout undo deployment/some-deployment и kubernetes восстановит предыдущий «слепок»), однако мета-проект должен содержать в себе информацию и об этом. Более сложные алгоритмы отката доставки крайне не рекомендуются хотя и необходимы порой.
Что может стать причиной запуска этого механизма:
- Высокий процент ошибок приложения после релиза
- Сигналы от ключевые точек мониторинга
- Не прошедшие
smokeтесты - Ручной режим — человеческое решение
Обеспечение информационной безопасности и аудит
Невозможно выделить отдельного процесса, который «создаст» стопроцентную безопасность вашей экосистемы как от внешних так и от внутренних угроз, однако стоит заметить, что архитектурный каркас должен быть выполнен с оглядкой на стандарты и политики безопасности компании на каждом из уровней и во всех подсистемах.
Далее я рассмотрю подробнее все три уровня предложенного решения, когда буду описывать мониторинг и алертинг, которые также являются сквозными и имеют фундаментальную значимость в разрезе целостности системы.
Kubernetes имеет набор весьма неплохих встроенных механизмов для разграничения прав доступа, сетевых политик, аудита событий и прочих мощных инструментов относящихся к информационной безопасности. При должном упорстве, вы будете способны построить отличный периметр защиты способный устоять и не дать закончиться успехом единой атаке или утечке данных.
От процессов к архитектуре
Эта жесткая связь между процессами разработки и эко-средой, которую вы пытаетесь построить не должна давать вам покоя. Добавляя к классическим требования, предъявляемым к архитектуре информационных систем (гибкость, масштабируемость, доступность, надежность, защищенность от угроз и т.д.), запрос о хорошей интеграции с процессами разработки и доставки, вы многократно умножаете ценность такой архитектуры.
Тесная интеграция процессов разработки и экосистемы уже давно породила такое понятие как DevOps (Development Operations), что по сути является логичным шагом на пути к тотальной автоматизации и оптимизации инфраструктуры. Однако при наличии хорошо продуманной архитектуры и качественных подсистемах вашей платформы, DevOps задачи должны сводиться к минимуму.
Микросервисная архитектура
Я полагаю, нет надобности вдаваться в детали пользы сервис ориентированной архитектуры (SOA — Service Oriented Architecture), а, также, почему эти сервисы должны быть микро. Скажу лишь то, что, если вы решились использовать Docker и Kubernetes, то скорее всего должны понимать (и принимать), что в этом мире быть огромным монолитом очень тяжело и, я бы сказал, идеологически неправильно.
Docker, который рассчитан на запуск единственного процесса и строгой работы с персистентностью, форсирует нас думать в рамках DDD (Domain Driven Development) и относится к упакованному коду как к черной коробке с торчащими наружу портами для доступа.
Важнейшие компоненты и решения экосистемы
Из моей практики дизайна систем повышенной доступности и надежности, я бы выделил несколько компонентов, которые практически необходимы для работы микросервисов.
Не смотря на то, что все компоненты и их описания ниже приведены в разрезе Kubernetes окружения (которое в рамках данной статьи является ключевым с точки зрения подхода и архитектуры), вы можете обращаться к данному списку и как к чеклисту для любой другой платформы.
Если вы (как и я) придете к выводу, что неплохо было бы управлять служебными сервисами, описанными ниже, как обычными Kubernetes сервисами, то рекомендацией будет иметь для этого отдельно стоящий кластер или кластер отличный от «production». Например, вы можете использовать «staging» кластер, который будет защищать вас от ситуации, когда «боевое» окружение не стабильно, но все же должно иметь источник образо, кода или мониторинга. Иными словами, таким образом, вы решите проблему «курицы и яйца»
Identity сервис
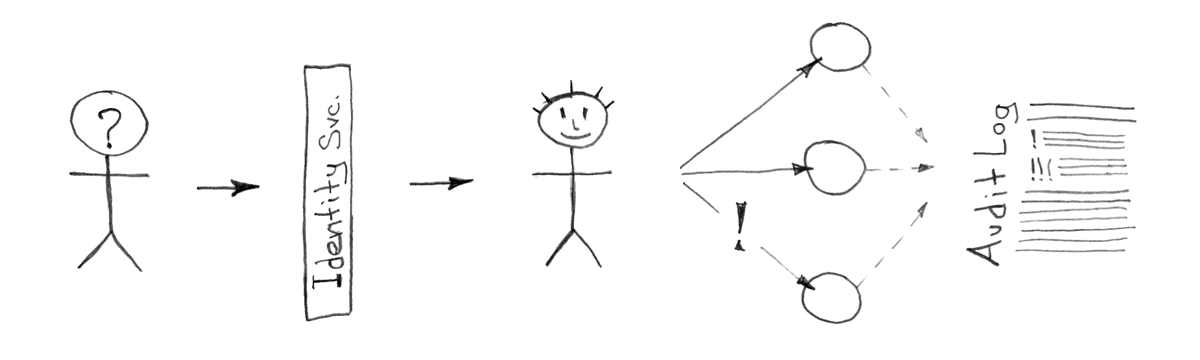
Все, как правило, начинается с доступа, доступа к серверам, виртуальным машинам, приложениям, офисной почте, и т.д. Если вы являетесь (или хотите стать) клиентом одной из крупных корпоративных платформ (типа IBM, Google или Microsoft), то скорее всего эта проблема будет решена для вас соответствующими сервисами этих вендоров. Но что делать, если это не ваш путь, и вы хотите иметь свое собственное решение управляемое только вами и желательно доступное по бюджету?
Данный список должен вам помочь определиться с необходимым вариантом и понять трудозатраты на установку и обслуживание. Этот выбор должен быть безусловно согласован с политикой безопасности компании и одобрен службой (информационной) безопасности.
Автоматизированный провижининг серверов
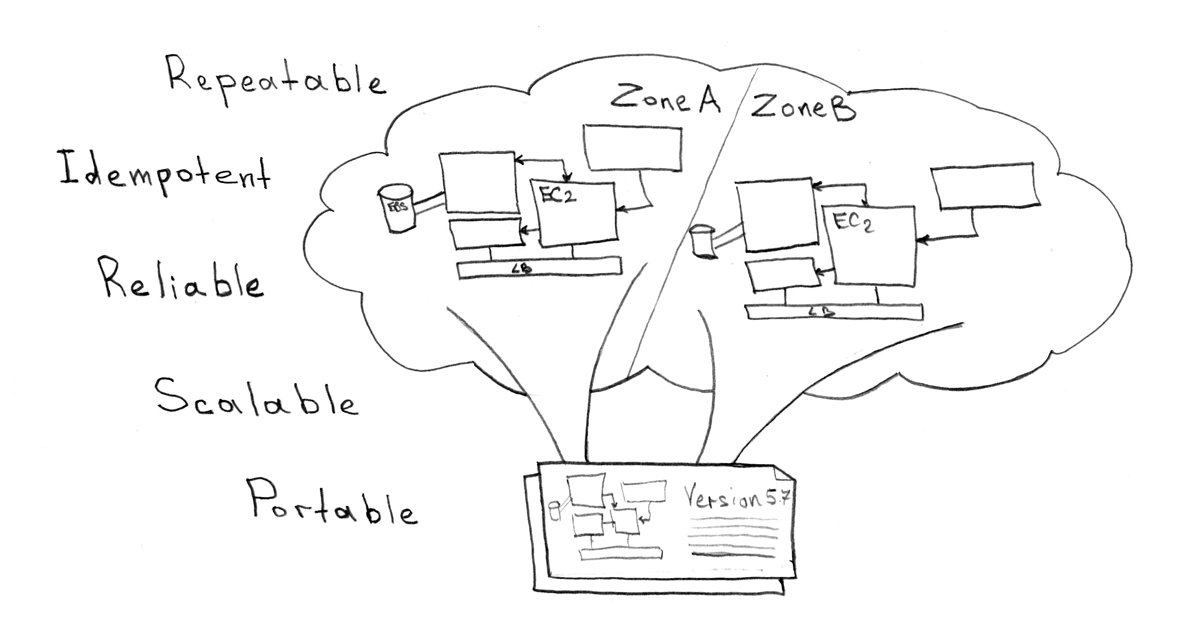
Не смотря на то, что Kubernetes требует совсем небольшого числа компонентов на физических машинах/облачных VM (docker, kubelet, kube proxy, etcd кластер), вы должны автоматизировать добавления новых машин и управление кластером. Несколько вариантов механизмов, как делать это легко и просто:
- KOPS — инструмент позволяет установить кластер на одном из двух облачных провайдеров — AWS или GCE
- Teraform — в целом позволяет управлять инфраструктурой для любого окружения и следует идеологии IAC (Infrastructure as Code, инфраструктура как код)
- Ansible — инструмент еще более широкого спектра применения и служит для автоматизации любого рода.
Хочу заметить, что из предложенного списка, как уже говорилось выше — в разделе о доставке систем, я предпочитаю последний вариант (с небольшим модулем для интеграции с Kubernetes), так как он наиболее гибко позволяет работать и c серверами, и с объектами k8s, и вообще осуществлять любого рода автоматизацию. Однако, ничто не мешает вам использовать, к примеру, Teraform и его модуль для Kubernetes. KOPS же полностью не применим для работы на «bare metal», однако, на мой взгляд, идеальный инструмент для работы с AWS/GCE!
Git репозиторий и таск трекер
Нет нужды говорить о том, что для полноценной работы разработчиков и других смежных ролей, необходимо иметь место для совместной работы, обсуждений хранения кода. Сложно ответить на вопрос о лучшем сервисе для этого, могу лишь упомянуть, что для меня в качестве таск трекера классически является бесплатный redmine или платная Jira и бесплатный «олдскульный» gerrit или платный bitbucket
Стоит обратить внимание на два наиболее консистентных, однако комерческих, стэка для совместной корпоративной работы: Atlassian и Jetbrains. Вы можете использовать полностью один из них или комбинировать различные компоненты в вашем решении.
Для обеспечения наибольшего эффекта использования трекера и репозитория, вы должны иметь ввиду стратегии работы и интеграции этих двух сущностей. Так например, пара советов по обеспечению целостности кода и относящихся к нему задач (естественно вы можете выбрать свои стратегии):
- Возможность «пушить» в удаленный репозиторий должна быть только в ветку с номером задачи (
TASK-1/feature-34) - Любая ветка должна быть заблокирована и не доступна для обновлений, если соответствующая задача не в статусе «In Progress» или подобном
- Ветка должна быть доступна для слияния только после определенного числа положительных код ревью
- Любые шаги предназначенные для автоматизации не должны быть доступны для разработчиков непосредственно
masterветка должна быть доступна для непосредственного изменения только привилегированными разработчиками — все остальное доступно только роботу «автоматизатору»- Ветка не должна быть доступна для слияния, если соответствующая задача находится в статусе отличном от «For Delivery» или подобном
Docker Registry
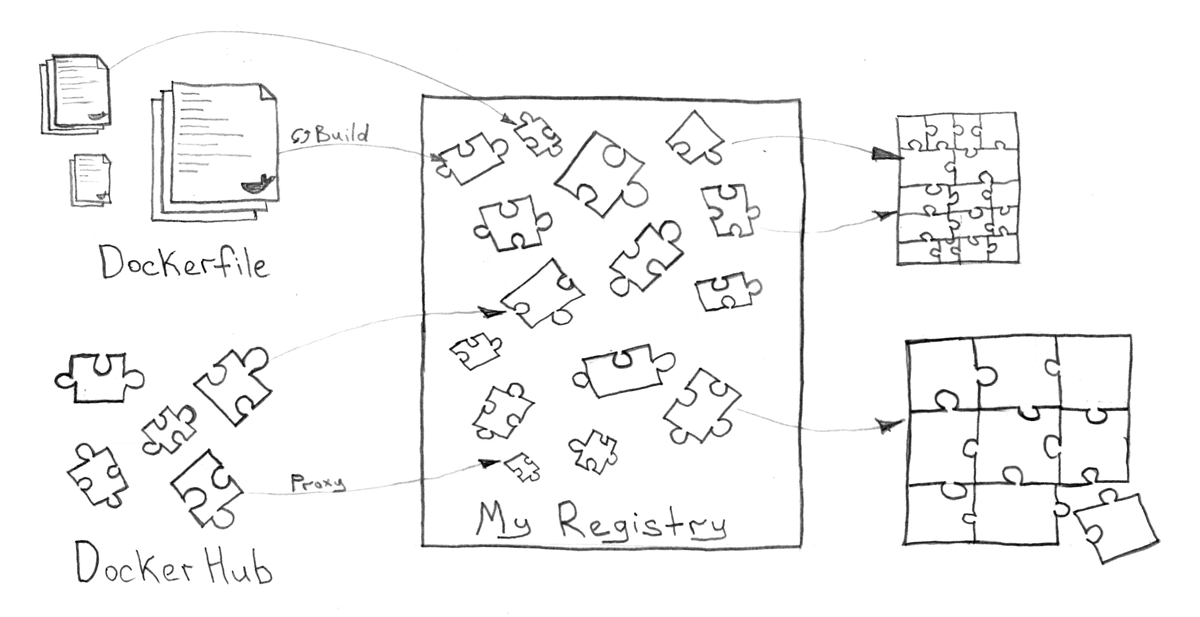
Функция управления Docker образами должна быть отдельно обозначена, поскольку имеет огромное значение для хранения и доставки сервисов. Дополнительно к этому, такая система должна поддерживать работу с пользователями, группами и доступом, уметь удалять старые и ненужные образы, предоставлять GUI и restful API.
Вы можете использовать как облачные решения (например hub.docker.com), так и любой приватный сервис, который может быть установлен даже внутри самого Kubernetes кластера. Довольно интересным сервисом для этого может стать Vmware Harbor, который позиционируется как корпоративное решение для Docker Registry. На худой конец, можно обойтись и обычным Docker Registry, если вы не особо нуждаетесь в сложной системе и просто хотите хранить образы.
CI/CD сервис и система доставки сервисов
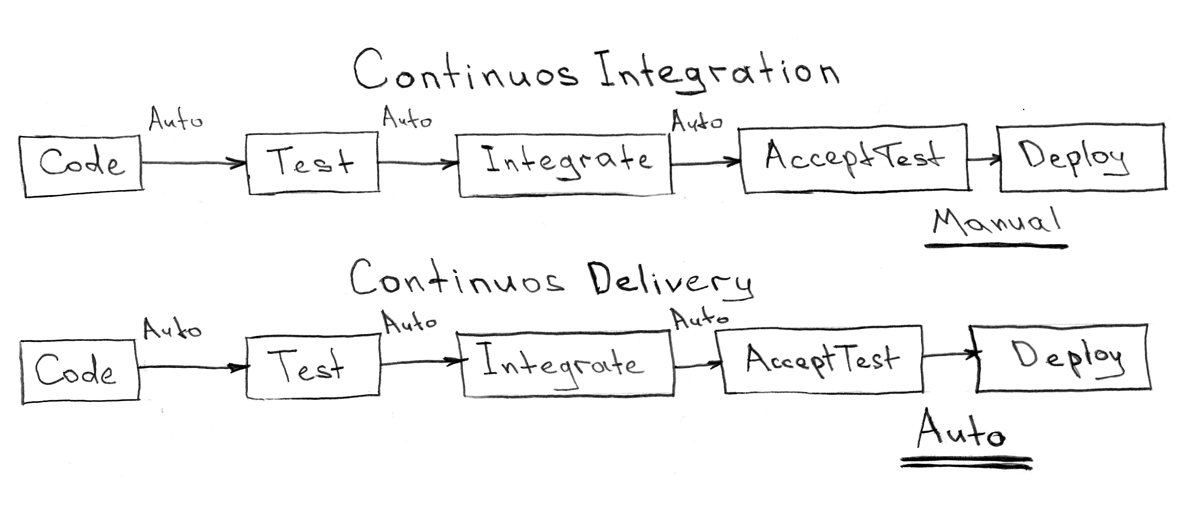
Все компоненты, о которых мы говорили прежде (git репозиторий, таск трекер, мета-проект с Ansible Playbook-ами, внешнии зависимости), не могут существовать отдельно подвешенными в вакууме. Заполнить этот вакуум должен как раз сервис непрерывной интеграции и доставки.
CI — Continuous Integration — Непрерывная интеграция
CD — Continuous Delivery — Непрерывная доставка
Сервис должен быть довольно простым и не иметь логики относящейся к способам доставки или настройки систем. Все что должен делать CI/CD сервис, так это реагировать на события из внешнего мира (изменение в git репозитории, переход задачи в таск трекере,) и запускать какие то действия описанные в мета-проекте. Также это место которое является точкой контроля всех репозиториев и инструментом управления ими (слияния веток, обновления из upstream/master)
Я исторически привык использовать довольно мощный и в то же время очень простой инструмент от Jetbrains — TeamCity, но не вижу никаких проблем, если вы решите использовать, например, бесплатный Jenkins.
Опираясь на вышеизложенное, по сути, во всей этой схеме, существует всего четыре основных и один вспомогательный процесс, которые должен запускать сервис интеграции:
- Автоматическое тестирование сервисов — обычно для отдельно взятого репозитория, по изменению состояние ветки или по наступлении статуса «Awaiting Autotests»(или подобного)
- Доставка сервисов — обычно из meta-проекта для ряда сервисов (а следовательно и репозиториев), по наступлении статусов «Awaiting Showroom», «Awaiting Delivery» для развертывания среды QA и «production» соответственно
- Откат — обычно из meta-проекта для какой-то конкретной части одного сервиса или целого сервиса по наступления внешнего события или триггера из неудавшегося процесса доставки
- Удаление сервисов — требуется для полного удаления всей экосистемы из отдельно взятого тестового окружения (
showroom), по истечении статусаIn QA, когда окружение больше не нужно - Сборка образов (вспомогательный процесс) — может быть использован как в процессе для доставки сервисов, так и самостоятельно, если нужно просто собрать
Dockerобразы и отправить их в Docker Registry, зачастую используется для каких-то широко используемых образов (БД, общие сервисы, не часто меняющиеся сервисы)
Система сбора и обработки логов

Единственный способ для любого Docker контейнера сделать доступными свои логи — писать их в STDOUT или STDERR корневого процесса запущенного в этом самом контейнере. По сути для разработчика сервиса не имеет значения что дальше происходит с этими данными, главное чтобы они были доступны во время необходимости и желательно до предсказуемой точки в прошлом. Вся ответственность здесь за исполнение этих ожиданий ложится на Kubernetes и тех людей которые поддерживают экосистему.
В официальной документации вы можете найти описание базовой, и вообщем то не плохой, стратегии работы с логами, что поможет вам выбрать необходимый сервис для аггрегации и хранения огромного числа текстовых данных.
Исходя из той же документации, рекомендованными сервисами для системы логирования являются fluentd для сбора, запущенный как агент на каждой ноде кластера, и Elasticsearch для хранения и индексации данных. Многие могут не согласиться с оптимальностью данного решения, но простота использования и достаточная надежность, позволяют мне говорить о том, что с этого следует как минимум начать.
Elasticsearch довольно требовательное к ресурсам решени, но отлично масштабируется и имеет уже готовые Docker образы для запуска как индивидуальной ноды так и нужного размера кластера.
Tracing Система

Каким бы идеальным не был ваш код, наверняка вы захотите изучить его под «микроскопом» в реальном боевом окружении и понять «а что же пошло не так, ведь локально то все работает?!». Медленные запросы в БД, неправильно работающий кэш, медленные диски или сеть до внешнего ресурса, варианты распространения транзакций в эко-среде, узкие места и недостаточно масштабированные вычислительные сервисы — это часть причин, по которым вы будете вынуждены проследить и оценить временные затраты выполнения вашего кода под реальной нагрузкой.
Opentracing и Zipkin справляются с этой задачей для большинства современных языков программирования и не добавляют большой дополнительной нагрузки после инструментирования кода. Все собираемые данные, естественно, должны быть сохранены в подходящем для вас месте, использование которого предусмотрено в качестве соответствующей компоненты.
Сложности, которые возникают при инструментировании кода и пробрасывнии «Trace Id» сквозь все сервисы, очереди сообщений, базы данных и т.д., решаются вышеупомянутыми стандартами разработки и шаблонами сервисов, заботящихся о единообразии подхода и работы с такого рода средой.
Мониторинг и алертинг
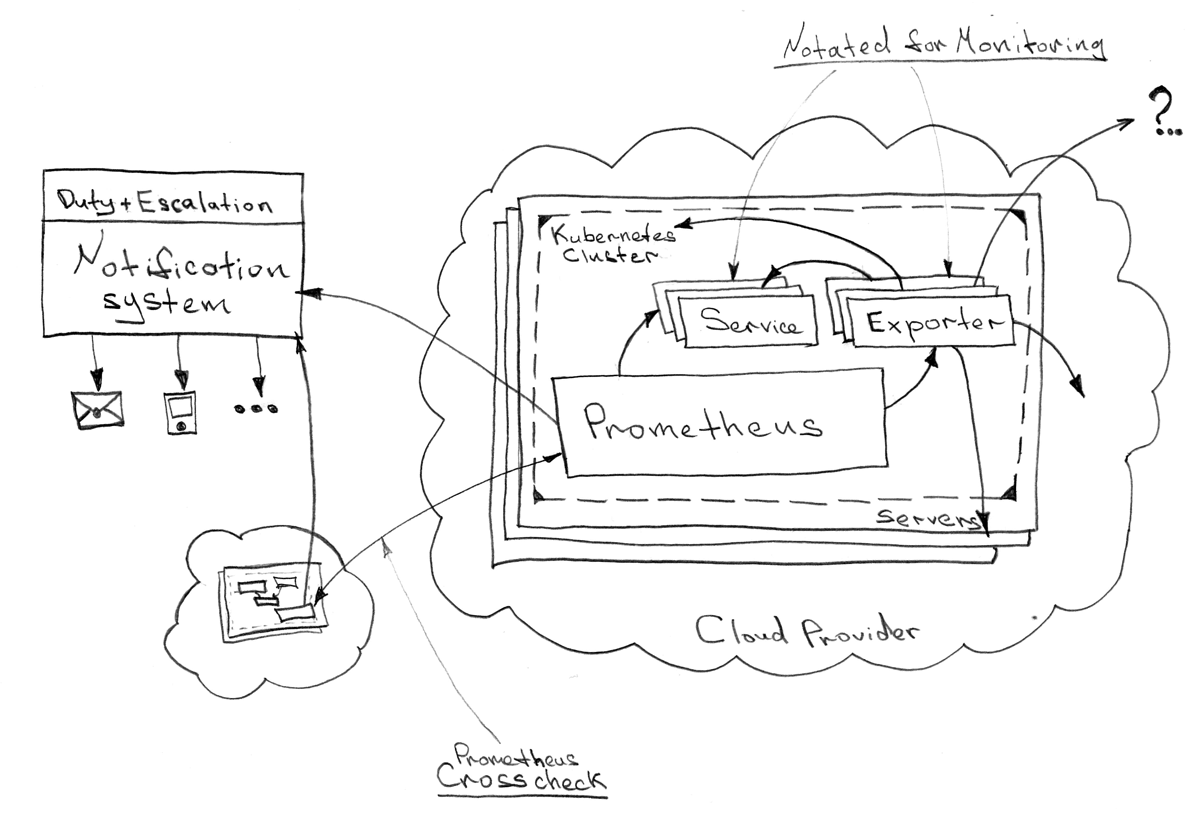
Prometheus стал стандартом де-факто в современных системах и что более важно поддерживается в Kubernetes практически «из коробки». Вы можете обратиться к официальной документации Kubernetes, чтобы более детально изучить вопрос мониторинга и алертинга.
Мониторинг, вероятно, эта одна из немногих служебных систем, которая должна быть установлена внутри кластера, непосредственно подлежащему быть объектом отслеживания проблем. НО мониторинг системы мониторинга (уж простите за тавтологию) может быть выполнен только извне (например с того же «staging» окружения). «Крос-чек» довольно удобное решение в любых распределенных системах и не сильно усложняет архитектуру крайне унифицированной экосреды.
Весь спектр мониторинга делится на три вполне логически изолированных уровня, с примерами наиболее важных, на мой взгляд, точек анализа на каждом из них:
- Физический уровень:
- Сетевые ресурсы и их доступность
- Диски (i/o, доступный объем)
- Базовые ресурсы отдельных узлов (CPU, RAM, LA)
- Уровень кластера:
- Доступность основных систем кластера на каждой ноде (kubelet, kubeAPI, DNS, etcd, и т.д.)
- Количество свободных ресурсов и их равномерное распределение
- Анализ дозволенного и фактического потребления ресурсов сервисами
- Перезагрузки
pod-ов
- Уровень сервисов:
- Любого рода проверки приложений от контента в БД до частоты вызовов API
- Количество ошибочных HTTP статусов на API шлюзе
- Объемы очередей и утилизация
worker-ов - Множество метрик для БД (отставание репликаций, время и количество транзакций, медленные запросы, т.д.)
- Анализ ошибок для не HTTP процессов
- Мониторинг запросов в лог-систему (можно трансформировать любые запросы в метрики)
Что же касается оповещения о проблемах на каждом из уровней, то тут я бы хотел рекомендовать использовать один из множества внешних сервисов, которые способны слать уведомления в email, SMS или звонить на мобильный телефон.
Хотел бы отметить систему OpsGenie которая имеет тесную интеграцию c alertmanager-ом из Prometheus.
OpsGenie весьма гибкий инструмент для нотификаций о проблемах, который позволяет нам решать проблемы эскалаций, круглосуточных дежурств, выбора канала связи и много всего прочего. Также не составляет труда распределять проблемы по командам. К примеру, различные уровни мониторинга должны отправлять нотификации различным командам/отделам: физический — Infra+Devops, кластера — Devops, приложения — множествам ответственных команд.
API шлюз и Single Sign-on
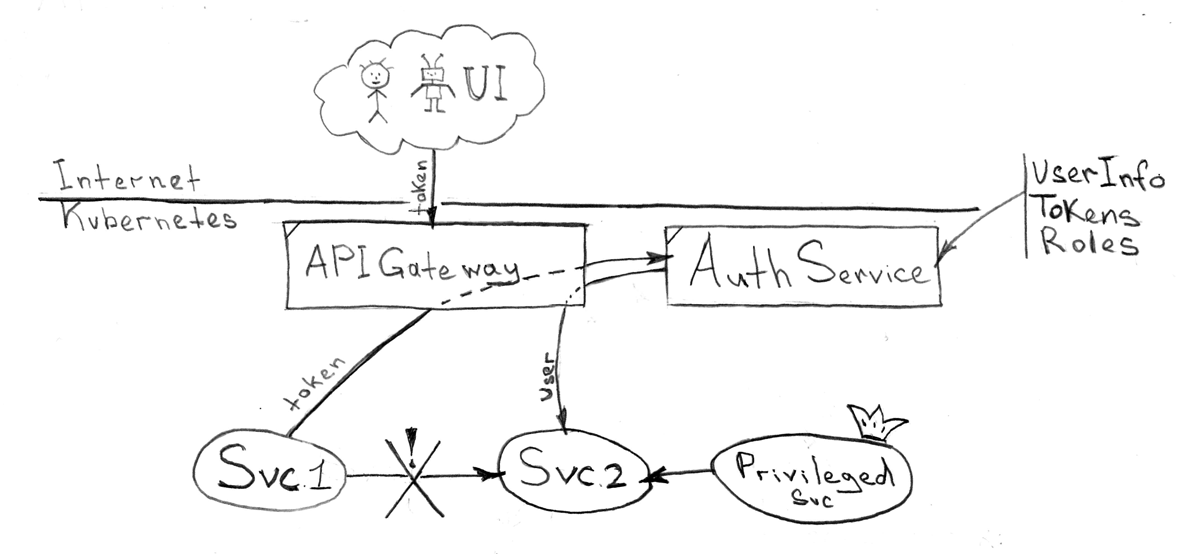
Для авторизации, аутентификации, регистрации пользователей (здесь, в отличие от раздела «Identity сервис», я имею ввиду внешних пользователей-клиентов компании), да и любого другого рода управления доступом ко всем своим сервисам, вам может понадобиться высоконадежный сервис, который будет иметь возможность гибкой интеграции с API шлюзом. Нет никаких противопоказаний использовать тоже самое решение, что вы выбрали и для «Identity сервиса», однако вы можете захотеть разделить эти два рксурса и иметь различный уровень доступности и надежности.
Вся межсервисная интеграция не должна быть сложной и каждый сервис не должен заботиться об авторизации, аутентификации пользователей и друг друга. Вместо этого архитектура и собственно экосистема обязана предоставить некий прокси сервис, который будет решать эти задачи. Все что необходимо будет сделать так это «завернуть» все коммуникации, весь HTTP трафик через него.
Здесь рекомендуется рассмотреть наиболее логичный варианту интеграции с API шлюзом, а следовательно и со всей вашей эко-средой — токены. Этот метод сгодится для всех трех случаев доступа: из UI приложения, сервис-сервис и из внешних системы. Подзадача получения токена (на основании логина и пароля), в данном случае, соответственно ложится на само UI приложение или на разработчика сервиса. Также имеет смысл заложить возможность разного срок жизни для токена используемом в UI приложении (короткий TTL) и других случаев (длинный и задаваемый вручную TTL)
Часть задач, которые решает API шлюз:
- Доступ ко всем сервисам экосистемы как извне так и внутри экосистемы (сервисы не общаются с друг другом напрямую)
- Интеграция c Single Sign-on сервисом:
- Трансформация токенов и подмешивание в HTTP запрос заголовков с идентификационными данными пользователя (ID, ролей, прочей информации) для конечного сервиса
- Управление доступом (запретить/разрешить) к конечному запрашиваемому сервису на основе ролей полученных от Single Sign-on
- Единая точка мониторинга для HTTP трафика
- Объединение API документации от разных сервисов (например, слияние Swagger json/yaml файлов)
- Возможность управлять роутингом для всей вашей экосистемы на базе доменов и запрашиваемых URI
- Единственная точка доступа для трафика извне и интеграции с провайдером доступа
Шина событий (Event Bus) и шина интеграций (Enterprise Integration/Service Bus)
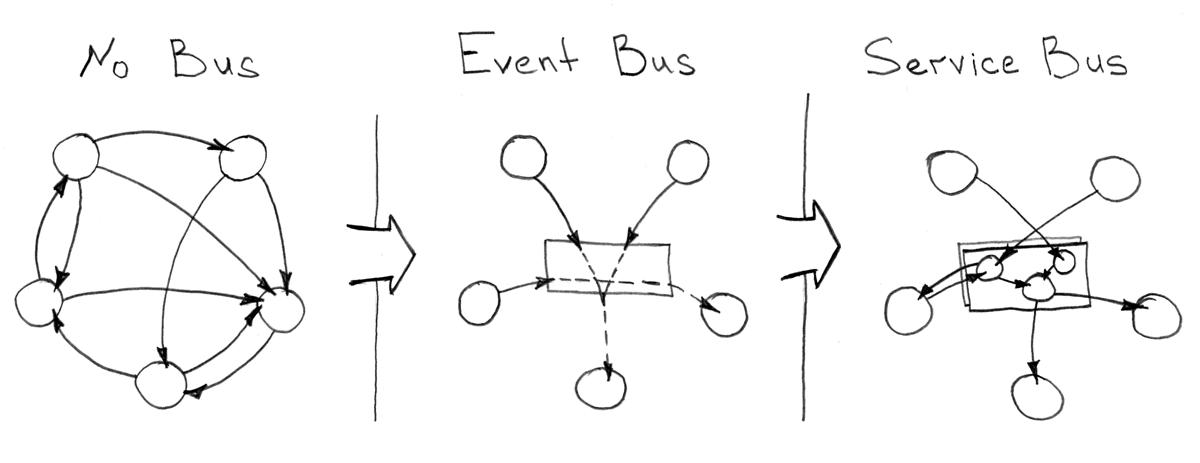
Когда экосреда подразумевает работу сотни сервисов, так или иначе работающих в одном макро-домене, то с большой долей вероятности все эти компоненты будут создавать тысячи вариантов коммуникаций и интеграций. Для того чтобы упорядочить эти потоки данных и не создавать множество взаимных использований сервисов, вы должны исследовать вопрос о доставке сообщений до большого числа адресатов по наступлении определенных событий, в отрыве от контекста использования этих событий в будущем. Иными словами, вам нужна будет шина событий, которая предоставит возможность публиковать события по какому-то стандартному протоколу и с другой стороны подписываться на них.
В качестве шины событий вы можете использовать любую систему, способную осуществлять работу так называемого брокера: RabbitMQ, Kafka, ActiveMQ и др. В общем случае высокая доступность и консистентность данных являются критичными для такого рода сервисов, однако CAP теорема заставит вас пойти на какой-то компромисс для распределения и кластеризации данной шины.
Казалось бы, что шина данных должна решить всевозможные проблемы межсервисных коммуникаций, но при росте числа сервисов от тысячи и десятков тысяч, даже самая лучшая архитектура на базе шины событий «даст течь», и вы обратите свой взор к подходу шины интеграций, которая по сути расширяет возможность «Dumb pipe — Smart Consumer» подхода, описанного выше.
Есть десятки проблем и предпосылок к использованию «Enterprise Integration/Service Bus» подхода, который решает или пытается нивилировать данные сложности сервисно-ориентированной архитектуры. Вот небольшая часть из задач, встречающихся наиболее часто:
- Агрегация множества сообщений
- Разбиение одного события на несколько
- Синхронный/транзакционный анализ реакции системы на событие
- Согласование интерфейсов, особенно характерно для интеграции с внешними системами
- Усложненная логика в роутинге событий
- Множественная интеграция с одними и теми же сервисами (извне и внутри)
- Не масштабируемая централизация шины данных
В качестве свободно распространяемого ПО для создания корпоративной шины интеграции, вы можете изучить Apache ServiceMix, который включает в себя несколько компонент незаменимых для проектирования и разработки подобного рода сервис ориентированных архитектур.
Базы данных и другие Stateful сервисы
Docker, ровно как и Kubernetes, абсолютно изменил правила игры для сервисов, подразумевающих персисте
