Ложные срабатывания. Новая техника ловли двух зайцев

Проблема ложных срабатываний. Точность и полнота.
Если есть универсальная болевая точка DLP-систем, то это, без сомнения, ложные срабатывания. Они могут быть вызваны неправильной настройкой политик, но соль в том, что даже если интегратор постарался, и все внедрено-настроено грамотно, ложные срабатывания все равно никуда не исчезают. И их много. Если услышите, что у кого-то их нет, не верьте, «everybody lies». Мы долго в этой отрасли, и все серьезные конкурентные решения регулярно тестируем. Ложные срабатывания — это бич всех современных DLP, от которого страдают прежде всего заказчики.
В этой статье мы расскажем о новом подходе к политикам фильтрации информационного трафика на предмет риска ИБ. Метод основан на применении двух этапов фильтрации, что отличает его от традиционной одноуровневой фильтрации. Такой подход позволяет более эффективно решать проблему ложных срабатываний, т.е. сокращать и мусор, и долю пропущенных инцидентов.
Сегодня будет немного теории, а через неделю — много практики.
Прежде всего, напомним 2 свойства, определяющих качество любого механизма фильтрации информации, а именно: точность и полнота (precision and recall, на языке статистики — ошибки I-го и II-го рода).
Представим себе некую компанию с информационным трафиком. В нем имеется некая выборка документов, состоящая из множества A — ценных документов. Фильтрационный механизм должен выявить их в информационном трафике. Точность — это доля документов, верно отмеченных как ценные среди всех отмеченных фильтром, а полнота — доля верно найденных из заранее известного множества ценных документов А. Попробуем расписать это в виде формул, чтобы было чуть понятнее.
Например, А = 10 коммерческих предложений. Наш фильтр нашел B = 8 документов верно и C = 4 ложно, следовательно, D = 2 документа мы не нашли. Тогда:


Естественно, что точность и полнота противостоят друг другу. Проиллюстрируем это на простом примере условия фильтрации.
В качестве условий детектирования информации на предмет риска ИБ выступают ключевые слова, количество вложений, число получателей, форматы файлов, тональность лексики и еще миллион условий. Без потери общности мы выберем в качестве такого условия размер файла V.
Пусть для некоторой организации распределение количества файлов ценной информации и мусора по размеру файла выглядит следующим образом:

Тогда борьба за точность даст такой результат поиска (найдены файлы размером > V):
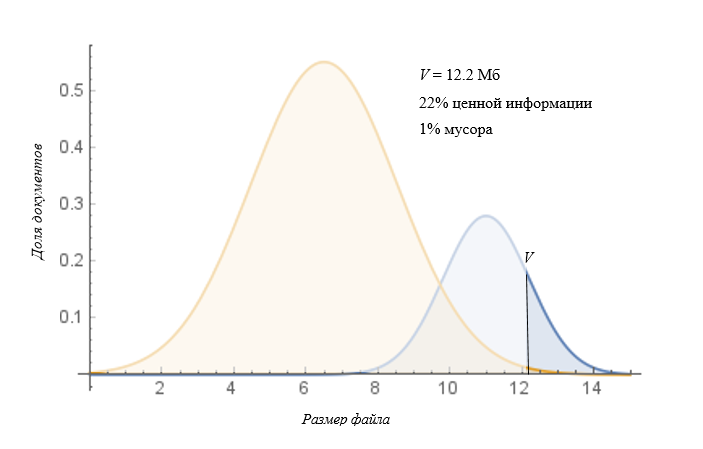
Естественно, такая политика фильтрации не годится по самой банальной причине — мы теряем из вида львиную долю важной информации, что недопустимо. Однако одновременно эта политика дает нам и серьезное преимущество. Известно, что инциденты ИБ высокой критичности подвергаются незамедлительному разбору, и такой подход, при котором мы сразу получаем наиболее критичные инциденты без лишнего мусора, позволяет повысить скорость реагирования.
Борьба за полноту будет выглядеть так (найдены файлы размером > V):
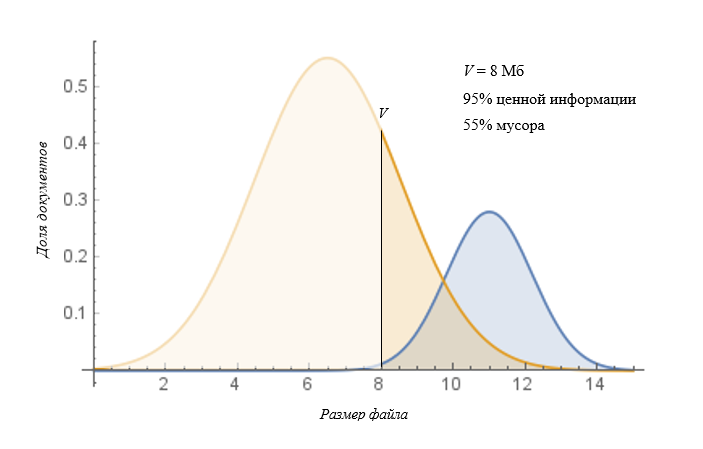
В этой ситуации, более привычной и характерной для отечественных реалий, политика информационной безопасности размечает значительно больше трафика, сохраняя при этом почти все инциденты. Но и в этом случае результат не позволяет назвать такой подход эффективным. Причина этого — снова фактор времени. Офицер безопасности сталкивается с большим числом ложных срабатываний, что замедляет реагирование на инциденты высокой критичности.
Добиться 100% точности и 100% полноты ввиду, вообще говоря, случайного характера анализируемых данных, удается редко. На чем же построены маркетинговые заявления вендоров о едва ли не отрицательном числе ложных срабатываний в их продуктах? Иногда разработчики DLP намеренно вуалируют один из показателей, выдавая его за качество детектирования, и тем самым делают арифметику невольной слугой необъективной подачи информации.
Одновременно высокие точность и полнота, как правило, встречаются в точных науках (физика, химия, биология). Например, по единственному состоянию цепочки белков можно определить уникальную (если у человека нет близнеца или клона) цепочку ДНК и её носителя. По уникальному отпечатку пальцев можно идентифицировать преступника, а по уникальному спектру поглощения можно определить химический состав вещества. В детектировании информации тоже имеется место для подобных решений. Речь идет о поиске информации по уникальному признаку (сумма MD5, или ее родственник — цифровой отпечаток). Во всех вышеперечисленных ситуациях мы имеем «свойство», однозначно отделяющее нужный объект от «мусора».
Однако по понятным причинам эта технология эффективна лишь для защиты неизменяемых файлов, чего в реальной жизни недостаточно.
 Стоит отметить, что сам процесс передачи информации не является объектом изучения классических точных наук, хоть уже и имеет под собой сильный математический аппарат теории информации, заложенный Клодом Шенноном в его работах по теории связи более 70 лет назад («Теория связи в секретных системах», «Математическая теория связи»).
Стоит отметить, что сам процесс передачи информации не является объектом изучения классических точных наук, хоть уже и имеет под собой сильный математический аппарат теории информации, заложенный Клодом Шенноном в его работах по теории связи более 70 лет назад («Теория связи в секретных системах», «Математическая теория связи»).
Нетрудно догадаться, что точность и полнота — те самые два зайца, о которых говорится в названии статьи. Во второй части мы расскажем, как же не упустить ни одного из них и решить «проклятый вопрос» всех DLP-систем — проблему ложных срабатываний.
Авторы:
Максим Бузинов, старший математик, компания Solar Security.
Галина Рябова, руководитель направления Solar Dozor, компания Solar Security.
