Lock-free структуры данных. Iterable list
 Lock-free list является основой многих интересных структур данных, — простейшего hash map, где lock-free list используется как список коллизий, split-ordered list, построенный целиком на списке с оригинальным алгоритмом расщепления bucket’а, многоуровневого skip list, являющегося по сути иерархическим списком списков. В предыдущей статье мы убедились, что можно придать такую внутреннюю структуру конкурентному контейнеру, чтобы он поддерживал thread-safe итераторы в динамичном мире lock-free контейнеров. Как мы выяснили, основным условием для того, чтобы lock-free контейнер стал итерабельным, является стабильность внутренней структуры: ноды не должны физически удаляться (delete). В этом случае итератор суть просто (быть может, составной) указатель на ноду с возможностью перехода к следующей (оператор инкремента).
Lock-free list является основой многих интересных структур данных, — простейшего hash map, где lock-free list используется как список коллизий, split-ordered list, построенный целиком на списке с оригинальным алгоритмом расщепления bucket’а, многоуровневого skip list, являющегося по сути иерархическим списком списков. В предыдущей статье мы убедились, что можно придать такую внутреннюю структуру конкурентному контейнеру, чтобы он поддерживал thread-safe итераторы в динамичном мире lock-free контейнеров. Как мы выяснили, основным условием для того, чтобы lock-free контейнер стал итерабельным, является стабильность внутренней структуры: ноды не должны физически удаляться (delete). В этом случае итератор суть просто (быть может, составной) указатель на ноду с возможностью перехода к следующей (оператор инкремента).Можно ли такой подход распространить на lock-free list?… Посмотрим…
Обычный lock-free список имеет такое строение узла:
template
struct list_node {
std::atomic next_;
T data_;
};
В нем данные инкорпорированы прямо в узел, поэтому удаление ключа (данных) приводит к удалению ноды целиком.
Разделим узел и данные — пусть узел содержит указатель на данные, которые он несет:
template
struct node {
std::atomic next_;
std::atomic data_;
};
Тогда для удаления ключа достаточно обнулить поле
data_ у ноды.В результате наш список приобретет такую внутреннюю структуру:
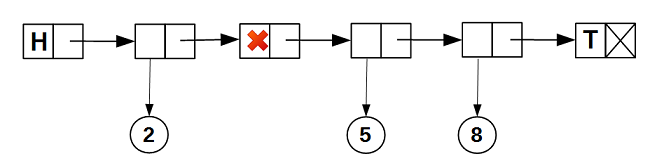
Ноды никогда не удаляются, так что список итерабельный: итератор есть фактически указатель на ноду:
template
struct iterator {
guarded_ptr gp_;
node* node_;
T* operator ->() { return gp_.ptr; }
iterator& operator++() {
// проходим далее по списку, начиная с node_,
// пропуская узлы с пустыми данными
}
};
Наличие
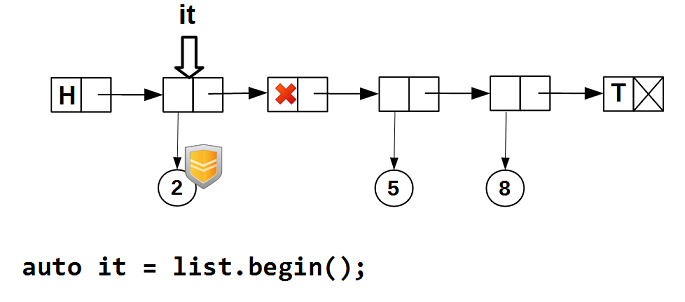
guarded_ptr (который содержит защищенный hazard pointer’ом указатель на данные) обязательно, так как мы не можем гарантировать, что другой поток не удалит данные, на которые позиционирован итератор. Можно гарантировать только то, что на момент перехода итератора на узел node_ он (узел) содержал данные. Защищенный указатель нам гарантирует, что пока итератор находится на узле node_, его данные не будут физически удалены (delete). Посмотрим в картинках, как это работает. Мы начинаем обход списка — итератор позиционируется на первый узел с непустыми данными:
Далее инкрементируем итератор — он пропускает узлы с пустыми данным: 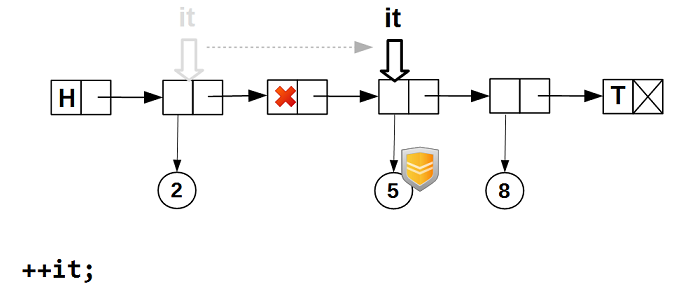
Даже если какой-то другой поток удалит данные узла, на котором позиционирован итератор, guarded_ptr итератора гарантирует нам, что данные не будут физически удалены, пока итератор стоит на узле: 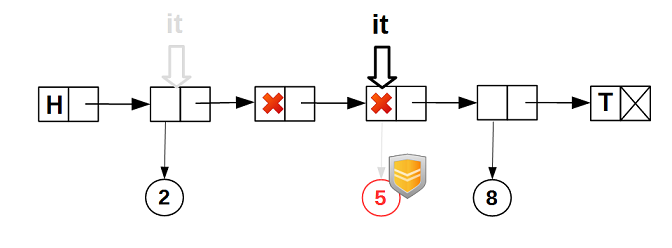
Возможна ситуация, когда данные будут удалены из списка, а затем к тому же самому узлу node_ будут приписаны другие данные. При этом итератор позиционирован на узел node_. Было бы странно, если бы в этом случае operator ->() итератора возвращал указатель на разные данные. guarded_ptr гарантирует нам неизменность данных, возвращаемых итератором, но совершенно не препятствует их изменению другими потоками: 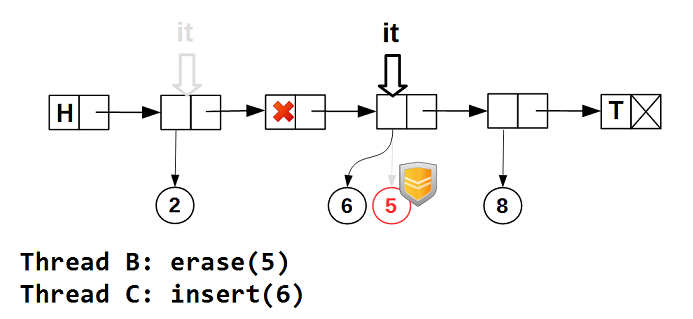
Как видим, построенный iterable list поддерживает thread-safe итераторы и имеет очень простую операцию удаления ключа (данных), которая сводится просто к обнулению (с помощью примитива CAS) поля data_ узла. Операция insert() добавления новых данных несколько сложнее, так как возможны два случая:
— вставка нового узла между существующими узлами списка с непустыми данными: 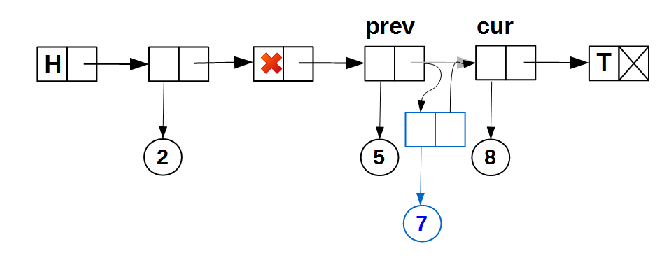
Этот алгоритм вставки узла нам уже знаком по одной из предыдущих статей.
— установка поля data_ у пустого узла prev: 
На этом можно было бы закончить статью, если бы второй случай — reusing empty data_ — не подкинул бы пару сюрпризов.
Сюрприз первый
Первая (наивная) версия вставки в iterable list выглядела так:

Функция linear_search — это обычный линейный поиск в списке (ну, не совсем обычный, — все же список у нас конкурентный, так что приседания с атомарными операциями и hazard pointer’ами нам обеспечены), возвращает true, если ключ найден и false в противном случае. Out-параметр функции pos (типа insert_pos) заполняется всегда. Поиск останавливается как только найден ключ не менее искомого data. Для вставки нас интересует неудача поиска — в этом случае pos будет содержать позицию вставки. Узел pos.cur всегда будет непустым (или же он будет указывать на конец списка — специально выделенный узел tail), а вот pos.prev — предыдущий для pos.cur — может указывать на пустой узел, — именно этот случай нас особо интересует. Поля prevData и curData структуры insert_pos — это значения data_ для prev и cur соответственно. Заметим также, что нам нет необходимости защищать указатели на узлы prev и cur hazard pointer’ами, так как узлы из нашего списка никогда не удаляются. А вот данные могут удаляться, поэтому их мы защищаем.
Итак, наивная реализация просто проверяет: если предыдущий узел пустой (pos.prevData == nullptr), то мы пытаемся записать в него ссылку на вставляемые данные. Так как список у нас конкурентный (более того, пока он даже lock-free, но мы это скоро исправим), изменение указателя prev.data_ делаем атомарным CAS’ом: если он успешен, значит, нам никакой другой поток не помешал и мы вставили новые данные в список.
Здесь нас ожидает первый сюрприз. Предположим, поток A добавляет некий ключ в список: linear_search() выполнен, структура insert_pos проинициализирована позицией вставки, и поток готов вызвать link(), но тут его время прошло и он стал тыквой был вытеснен операционной системой. В это время со списком работает поток B: 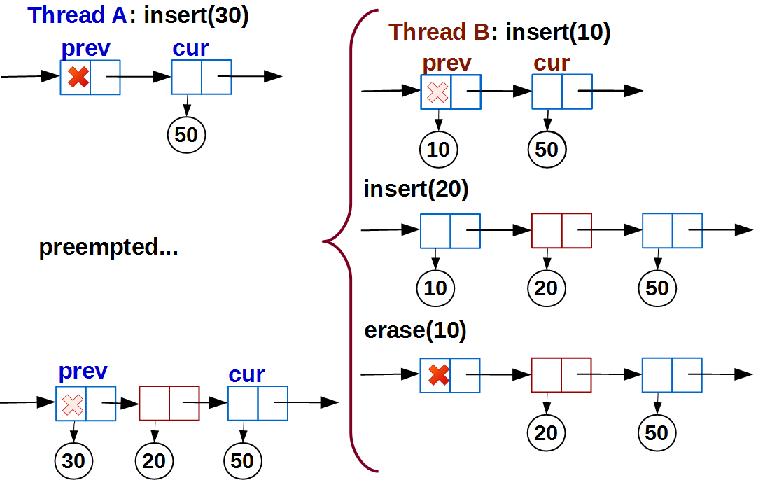
На момент возобновления потока A список неузнаваемо изменился, но с точки зрения найденной позиции pos потока A не изменилось ничего: prev как был пустым, так пустым и остался. Поэтому поток A запишет данные с ключом 30 в prev и успешно закончит вставку, тем самым сломав упорядоченность списка.
Это разновидность ABA-проблемы, которая не решается применением hazard pointer’ов, так как указатель prev->data_ у нас NULL. Линковать новые данные в пустой узел мы имеем право только тогда, когда связка prev → cur у нас не изменилась после поиска; более того, не изменились и данные этих узлов. Для решения этой проблемы применим технику marked pointer: младший бит указателя на данные узла будем использовать как признак «вставляется новый узел». Причем маркировать надо оба узла — prev и cur, — иначе другой поток может удалить данные у cur и упорядоченность списка вновь нарушится (не забудем, что узел cur всегда непустой). В результате изменится структура узла и функция link() добавления данных примет вид:
template
struct node {
std::atomic< node * > next_;
std::atomic< marked_ptr< T, 1 >> data_;
};
bool link( insert_pos& pos, T& data ) {
// маркируем данные prev и cur
if ( !pos.cur->data_.CAS( marked_ptr(pos.curData, 0),
marked_ptr(pos.curData, 1))) {
// не удалось — какой-то другой поток нам помешал
return false;
}
if ( !pos.prev->data_.CAS( marked_ptr(pos.prevData, 0),
marked_ptr(pos.prevData, 1))) {
// не удалось — опять нам мешают
// не забываем снять метку
pos.cur->data_.store( marked_ptr(pos.curData, 0));
return false;
}
// проверяем, что связка prev -> cur осталась прежней
if ( pos.prev->next_.load() != pos.cur ) {
// кто-то уже успел что-то добавить между prev и cur
pos.prev->data_.store( marked_ptr(pos.prevData, 0));
pos.cur->data_.store( marked_ptr( pos.curData, 0));
return false;
}
// все проверки удачны, можно добавлять
if ( pos.prevData == nullptr ) {
// устанавливаем новые данные у пустого узла
// быть может, здесь достаточно атомарного store
bool ok = pos.prev->data_.CAS( marked_ptr( nullptr, 1 ),
marked_ptr( &data, 0 ));
// снимаем метку у cur
pos.cur->data_.store( marked_ptr( pos.curData, 0));
return ok;
}
else {
// вставка новой ноды — алгоритм Harris/Michael
// здесь не рассматриваем
// но не забываем по окончании снять флаги
}
}
Введение marked pointer также влияет на функцию удаления данных (которая, как мы помним, сводится к простому обнулению поля
data_): теперь мы должны обнулять только непомеченные данные, но это не добавляет сложности процедуре удаления. Поиск по списку вовсе игнорирует наш маркер.В итоге iterable list перестал быть lock-free: если поток пометил хотя бы один из узлов, а затем был убит (исключению в функции
link() возникнуть неоткуда), условие lock-free нарушается, так как узел останется помеченным навсегда и в конце концов когда-нибудь приведет к бесконечному активному ожиданию снятия метки. С другой стороны, убивать потоки во время работы грешно — плохая практика, так что я не вижу здесь особых рисков.Сюрприз второй
К сожалению, тестирование показало, что это не полное решение. Если наивный iterable list часто показывал нарушение отсортированности данных и даже в дебажной сборке, то после введения marked pointers тесты стали показывать нарушение очень редко и только в релизной сборке. Это сигнал, что у нас очень неприятная проблема, практически не воспроизводимая за разумное время и решаемая только аналитически.
Как показал анализ, проблема фактически ортогональна первой:
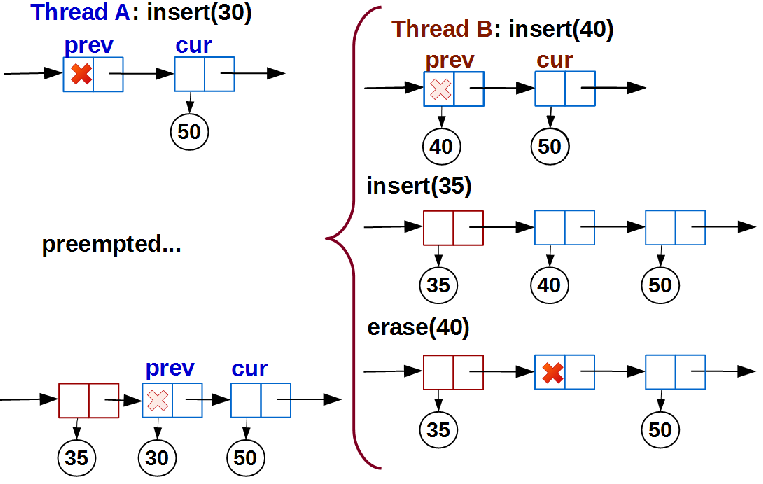
Как и в первом случае, поток A вытесняется перед входом в link(). Пока A дожидается, когда его вновь запланируют, другие потоки успевают похулиганить выполнить над списком такую последовательность добавлений/удалений, которая не нарушает предусловий функции link() потока A, но приводят к нарушению отсортированности списка.
Решение — добавить ещё одно условие в link(): после того, как мы пометили узлы prev и cur, между которыми должны вставить новый (или использовать пустой prev), мы должны проверить, что позиция вставки не изменилась. Проверить это можно единственным способом — найти узел, следующий за новыми данными, и убедиться, что он равен cur:
bool link( insert_pos& pos, T& data ) {
// маркируем данные prev и cur
// ... как и было
// проверяем, что связка prev -> cur осталась прежней
// ... как и было
// проверяем, что позиция вставки не изменилась
if ( find_next( data ) != pos.cur ) {
// oops! Нам опять помешали…
pos.prev->data_.store( marked_ptr(pos.prevData, 0));
pos.cur->data_.store( marked_ptr( pos.curData, 0));
return false;
}
// все проверки удачны, можно добавлять
// ... как и было
}
Здесь вспомогательная функция
find_next() ищет узел, ближайший сверху к data.
Заключение
Таким образом, итерабельный конкурентный список построить можно. Поиск в нем является lock-free, но вставка и, как следствие, удаление у него все же не lock-free. Зачем он такой нужен?…
Во-первых, наличие thread-safe итераторов в некоторых задачах важно. Во-вторых, этот список интересен тем, что операция удаления ключа в нем намного легче, чем вставка, — достаточно обнулить указатель на данные у узла; обычно удаление намного тяжелее, см. двухфазное удаление из классического lock-free списка. Наконец, эта задача была лично для меня неким вызовом, так как до этого я считал концепцию итераторов в принципе нереализуемой для конкурентных контейнеров.
Надеюсь, что данный алгоритм будет полезен, реализацию см. libcds: MichaelSet/Map и SplitListSet/Map на основе
IterableList с поддержкой потокобезопасных итераторов.Основы:
- Атомарность и атомарные примитивы
- Откуда пошли быть барьеры памяти
- Модель памяти
Внутри:
- Схемы управления памятью
- RCU
- Эволюция стека
- Очередной трактат
- Диссекция очереди
- Concurrent maps: разминка
- Concurrent maps: rehash, no rebuild
- Concurrent maps: skip list
- Concurent maps: деревья
- Итераторы: multi-level array
- Iterable list
Извне:
- Введение в libcds
