Agile в работе с аутсорсом

Бекграунд и подготовка
С марта 2016 года Cofoundit работал в ручном режиме: мы сами подбирали сотрудников и сооснователей в стартапы и изучали потребности пользователей. Собрали требования и в июне приступили к разработке сервиса. Два месяца ушло на создание прототипа и еще месяц на доработку финальной версии. Мы начали работать над продуктом в середине июня, в августе выпустили закрытую бету, в конце сентября — официально запустились и продолжаем работу.
С самого начала в качестве методологии я рассматривал только agile. Первую неделю мы посвятили планированию: разбили задачу на небольшие таски, спланировали спринты, каждый длиной в неделю. Большинство задач укладывалось в один спринт, но поначалу некоторые занимали и два, и три.
Первые спринты были откровенно неудачными — мы задержали релиз на неделю и начали отставать от графика. Но этот опыт помог нам правильно оценить сроки и отказаться от избыточного функционала. Изначально мы хотели сделать сервис с симметричным поиском: чтобы и специалист, и проект могли просматривать анкеты друг друга и начинать общение. В результате в работе осталась только первая часть: кандидат может просматривать и выбирать анкеты стартапов, а проект видит только тех специалистов, которые уже проявили к нему интерес. То есть по сути мы запустили минимальный жизнеспособный продукт.
Управление эффективностью
С помощью «Джиры» и плагина Time in status я постоянно следил за тем, как работает команда, и сколько времени занимает жизненный цикл задачи. Я считал время пяти основных этапов: в разработке (с момента создания таска до отправки на ревью), ревью кода (происходит на стороне команды аутсорса), деплой, тестирование и утверждение (со стороны сервиса, то есть мной).
В таблице указано количество дней, в течение которых задача находилась на каждом этапе разработки. Несмотря на то, что в нашем случае над задачей единовременно работал только один специалист (разработчик, тестировщик или менеджер), эти данные не равны человеко-часам: задача висит в статусе, даже если работа над ней не идет. Я специально не показываю сбор требований, время ожидания релиза и другие этапы, которые никак не отображают скорость работы команды. Статистику по июню толком собрать не удалось, поэтому этих данных нет в таблице.
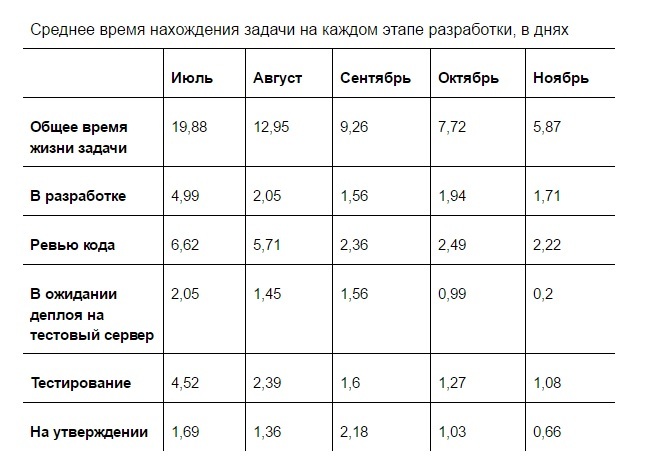
По результатам работы в июле я обратил внимание, что задачи дольше всего находятся в трех статусах: в работе, на тестировании и на ревью. Проще всего было решить проблему долгого тестирования. Тестировщик в нашей команде работал part-time и просто не успевал оперативно тестировать все задачи. Мы поговорили с подрядчиком и перевели его в проект на full-time. Это сократило время тестирования в два раза.
Для основных повторяющихся сценариев мы стали делать автотесты на selenium. Это позволило нашему тестировщику быстрее проводить регрессионное тестирование. Мы сократили время на заполнение анкет, без которого нельзя протестировать новый функционал сервиса. Потом мы продолжали наращивать число автотестов и улучшать показатели эффективности.
Во вторую очередь я начал разбираться с задержками на этапе разработки. При недельных итерациях я не мог позволить задаче висеть в работе пять дней (весь спринт). До финального релиза хотелось как минимум несколько раз посмотреть функционал в работе. Я решил проблему, разделив задачи на более мелкие.
По результатам августа мы отставали по показателю «Время на ревью» со стороны команды аутсорса. Сначала я постоянно напоминал исполнителю, что он должен посмотреть код и дать комментарии. В ноябре я передал эту обязанность тестировщику. С этого момента, как только он заканчивал работу над задачей, он сам оповещал ответственного за ревью. Полностью мы реализовали такой подход только в ноябре, когда деплой на тестовый сервер стал занимать меньше времени.
В сентябре слабыми показателями были «Утверждение» со стороны команды сервиса и «Ожидание деплоя на тестовый сервер». «Приемку» удалось ускорить просто более пристальным вниманием и быстрым реагированием на задачи. К тому же к этому времени процесс разработки уже вошел в ритм, и уже не так много моего времени уходило на поддержание.
Время деплоя на тестовый сервер в сентябре занимало больше 15% — это было чрезвычайно странно. Выяснилось, что после проведения ревью задачи её выкладывал на тест последний исполнитель. Нужно было мержить ветки, иногда возникали конфликты, исполнитель отвлекался от текущих задач. В октябре мы прикрутили к репозиторию механизм автоматического выкладывания задач, что сильно сократило время деплоя. Потом мы отладили процесс и в итоге за два месяца сократили время на деплой в 8 (восемь!) раз.
Итого, за пять месяцев мы сократили время решения задачи почти в четыре раза. Раньше путь задачи от постановки до утверждения результата занимал в среднем 20 календарных дней. Теперь, когда срок сократился до пяти календарных дней, стало проще контролировать этапы разработки, оценивать итоговые сроки решения задач и планировать загрузку команды.
Прогнозирование сроков
Другая важная задача — точная оценка сроков. По условиям договора с подрядчиком мне в целом было невыгодно попадать в оценку. Если задача делалась быстрее, мы платили только за потраченное на нее время, а если команда не укладывалась в сроки, то мы платили меньше.
Но у меня были другие причины добиваться точной оценки сроков. Например, скорость реализации иногда влияет на выбор функциональностей. Если на внедрение одной фичи уйдет день, а на другую — три дня, то менеджер с большой долей вероятности выберет более быстрый в разработке вариант. При этом «однодневная» фича на практике может занять те же три дня, и если бы это было известно заранее, выбор опций мог быть другим.
Я посчитал процент точности, с которой каждый программист попадает в оценку. В результате я получил коэффициенты, которые помогли точнее планировать сроки. Например, если программист оценил задачу в 10 часов, но его коэффициент ошибки около 40%, то я могу смело считать, что на задачу уйдет 14 часов. Профит.
Сложность состоит в том, что ошибки в оценке сроков бывают несистемными. Одни таски программист может делать в четыре раза медленнее, а другие — в два раза быстрее. Это сильно усложняет расчеты и планирование.
Поэтому я посчитал не только среднее отклонение в оценке сроков для каждого разработчика, но и процент отклонения от среднего. Если он был меньше 20%, я считал это хорошим результатом — такая погрешность в сроках не мешала мне планировать. Но были отклонения и в 30%, и в 50%, и они сильно мешали работе над релизом.
Например, разработчик оценивал сроки выполнения в 10 дней, его стандартное отклонение от сроков 40%, так реальный срок выполнения задачи становится 14 дней. Но если отклонение от среднего составит 50%, то это еще 7 дней работы над задачей. Итого, срок работы составит 21 день вместо обещанных 10 и ожидаемых 14. С такими опозданиями невозможно работать, поэтому я старался найти их причину и исправить.

В «Джире» я проанализировал опоздания и их причины — сделал выводы, что большее отклонение от планового времени приходится на задачи, которые не проходят апрув у меня, и которые тестировщик по несколько раз возвращает после тестирования.
Сначала я исправил ситуацию с задачами из «приёмки». Основная причина возврата заключалась в том, что тестировщик недостаточно анализировал задачу. Во время тестирования он действовал «по обстоятельствам», а иногда и вовсе не понимал, как должна работать функция. Решили, что тестировщик будет готовить Definition of done (DoD) к каждой задаче: не подробные тест-кейсы, а примерное описание того, что и в каком направлении он будет смотреть.
Я же со своей стороны просматривал эти DoD и, в случае ошибочного понимания или недостаточного объема тестирования, сразу указывал на это тестировщику. В итоге количество возвратов из «приемки» сократилось практически до нуля, и оценивать сроки стало проще.
Что касается частого возвращения задач из теста обратно в разработку, выяснилось, что почти треть случаев происходит из-за ошибки при деплое: например, не запущены нужные скрипты. То есть опция совсем не работала, но это можно было понять и без помощи тестировщика.
Решили, что при развертывании задачи на сервер программист будет сам проверять простые сценарии, чтобы убедиться, что все характеристики работают. Только после этого задача уходит в тест. Такая процедура занимает не больше пяти минут, а число возвратов из тестирования сократилось более чем на 30%.
Для сложных задач мы приняли решение проводить созвон с разработчиком, тимлидом и тестировщиком. Я комментировал документацию и подробно рассказывал, что именно и как я хочу, чтобы было реализовано. Если команда разработки видела какие-то недочеты на этом этапе, мы сразу вносили изменения в документацию. В таких случаях оценкой сроков занималось минимум два человека — разработчик и тимлид.
За четыре месяца средняя ошибка при планировании уменьшилась в 1,4 раза. Количество отклонений более 50% от средней ошибки сократилось с 9% до 1%.
Сбор и анализ статистики помог мне вовремя увидеть слабые места и исправить ошибки управления командой. Какие-то из них могли произойти и у «домашних» разработчиков, какие-то — особенность работы с аутсорсом. Надеюсь, принципы работы с внутренней статистикой пригодятся и вам.
