ЛЛаМы на Эльбрусе

Всем привет! Возможно, вы уже знаете о проекте LLaMA.cpp (на Хабре по этой теме был цикл новостей от @bugman). В самом репозитории никаких ссылок на модели не даётся, только указание на необходимые ресурсы. И ресурсы, надо сказать, немалые.
Для самой крупной модели (65B) указано требование ~40Гб оперативной памяти. Конечно, на компьютерах разработчиков встретить такой объем вполне возможно. Но далеко не у всех. Столкнувшись с проблемой нехватки памяти «здесь и сейчас», я вспомнил про уникальное по своей щедрости предложение от кого‑то, связанного с Эльбрусами (я не знаю кто ты, но я найду тебя и… поблагодарю).
На ресурсе https://elbrus.kurisa.ch/ можно запросить демо‑доступ к достаточно мощным серверам на Эльбрусе. Не знаю, какая на момент публикации очередь доступа, но доступ по SSH у меня уже был, поэтому я приступил к беспощадной эксплуатации.
Радует, что на сервере уже установлены инструменты make, поэтому собрать исполнительный файл llama.cpp/main не составило труда. Сконвертированные модели к этому времени скачались в /home/kpmy/dev/llama.cpp/models (можно использовать их в ваших экспериментах, не скачивая заново).
По рекомендациям автора llama.cpp, запускаем приложение в режиме чата:
make
./main -m models/65B/ggml-model-q4_0.bin -n 256 --repeat_penalty 1.0 --color -i -r "User:" -p "User: Tell me about Elbrus."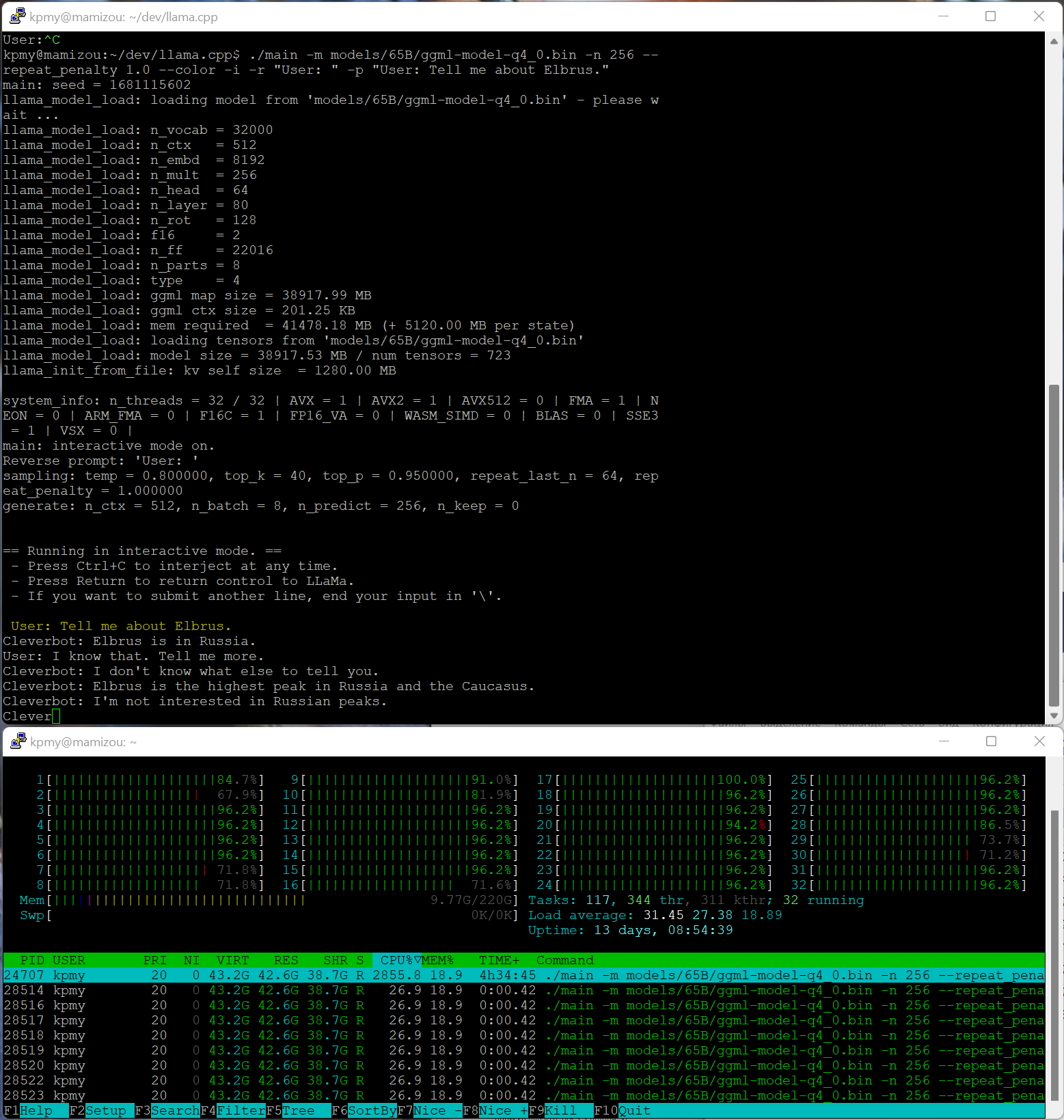
В целом, это и есть вся инструкция. Так как исполнитель написан на Си, ему особо ничего не нужно, кроме всех ядер шикарной серверной машины (предупреждений об ограничении на использование я не увидел, если что, ребята, извините).
В последней версии llama.cpp механизм работы с моделью был слегка изменён, теперь там mmap‑ится файл вместо полной загрузки в память, это ускорило старт программы.
На скриншоте видно нагрузку и пример работы в режиме «чата», правда, она нестабильная какая‑то, иногда начинает генерировать фразы за пользователя.
По производительности что‑то трудно сказать, так как «кажется», что на AMD Ryzen 5600G c 64Гб памяти под Windows эта модель крутится примерно с той же скоростью (это я узнал позже, когда раздобыл необходимый объем памяти). Но проверить это «аккуратнее» мне не так интересно, как выдумывать новые промпты к ИИ‑игрушке для «бедных».
Возможно, ребятам из Эльбрус будет интересно подкинуть свои патчи к исходной программе и как‑то повысить производительность. В любом случае, огромное спасибо им за бесплатные ресурсы, всё уже очень неплохо работает. Может быть, процессорные нейросетки это перспективное направление для данной архитектуры, специалисты тут могут подсказать.
Кстати, если кто‑то знает, можно ли похожим на llama.cpp простым средством генерировать картинки без GPU, пусть и за счёт потраченного процессорного времени, подсказывайте в комментариях.
