Linux API. Управление буферизацией файлового ввода-вывода, осуществляемой в ядре
 Привет, Хаброжители! Мы уже писали о книге Майкла Керриска «Linux API. Исчерпывающее руководство». Сейчас решили опубликовать отрывок из книги «Управление буферизацией файлового ввода-вывода, осуществляемой в ядре»
Привет, Хаброжители! Мы уже писали о книге Майкла Керриска «Linux API. Исчерпывающее руководство». Сейчас решили опубликовать отрывок из книги «Управление буферизацией файлового ввода-вывода, осуществляемой в ядре»
Сброс буферной памяти ядра для файлов вывода можно сделать принудительным. Иногда это необходимо, если приложение, прежде чем продолжить работу (например, процесс, журналирущий изменения базы данных), должно гарантировать фактическую запись вывода на диск (или как минимум в аппаратный кэш диска).
Перед тем как рассматривать системные вызовы, используемые для управления буферизацией в ядре, будет нелишним рассмотреть несколько относящихся к этому вопросу определений из SUSv3.
Синхронизированный ввод-вывод с обеспечением целостности данных и файла
В SUSv3 понятие синхронизированного завершения ввода-вывода означает «операцию ввода-вывода, которая либо привела к успешному переносу данных [на диск], либо была диагностирована как неудачная».
В SUSv3 определяются два различных типа завершений синхронизированного ввода-вывода. Различие между типами касается метаданных («данных о данных»), описывающих файл. Ядро хранит их вместе с данными самого файла. Подробности метаданных файла будут рассмотрены в разделе 14.4 при изучении индексных дескрипторов файлов. Пока же будет достаточно отметить, что файловые метаданные включают такую информацию, как сведения о владельце файла и его группе, полномочия доступа к файлу, размер файла, количество жестких ссылок на файл, метки времени, показывающие время последнего обращения к файлу, время его последнего изменения и время последнего изменения метаданных, а также указатели на блоки данных.
Первым типом завершения синхронизированного ввода-вывода в SUSv3 является завершение с целостностью данных. При обновлении данных файла должен быть обеспечен перенос информации, достаточной для того, чтобы позволить в дальнейшем извлечь эти данные для продолжения работы.
— для операции чтения это означает, что запрошенные данные файла были перенесены (с диска) в процесс. Если есть отложенные операции записи, которые могут повлиять на запрошенные данные, данные будут перенесены на диск до выполнения чтения.
— для операции записи это означает, что данные, указанные в запросе на запись, были перенесены (на диск), как и все метаданные файла, требуемые для извлечения этих данных. Ключевой момент, на который нужно обратить внимание: чтобы обеспечить извлечение данных из измененного файла, необязательно переносить все медатанные файла. В качестве примера атрибута метаданных измененного файла, который нуждается в переносе, можно привести его размер (если операция записи приводит к увеличению размера файла). В противоположность этому метки времени изменяемого файла не будут нуждаться в переносе на диск до того, как произойдет последующее извлечение данных.
Вторым типом завершения синхронизированного ввода-вывода, определенного в SUSv3, является завершение с целостностью файла. Это расширенный вариант завершения синхронизованного ввода-вывода с целостностью данных. Отличие этого режима заключается в том, что в ходе обновления файла все его метаданные переносятся на диск, даже если этого не требуется для последующего извлечения данных файла.
Системные вызовы для управления буферизацией, проводимой в ядре при файловом вводе-выводе
Системный вызов fsync () приводит к сбросу всех буферизованных данных и всех метаданных, которые связаны с открытым файлом, имеющим дескриптор fd. Вызов fsync () приводит файл в состояние целостности (файла) после завершения синхронного ввода-вывода.
Вызов fsync () возвращает управление только после завершения переноса данных на дисковое устройство (или по крайней мере в его кэш-память).
#include
int fsync(int fd);
Возвращает при успешном завершении 0 или –1 при ошибке
Системный вызов fdatasync () работает точно так же, как и fsync (), но приводит файл в состояние целостности (данных) после после завершения синхронного ввода-вывода.
#include
int fdatasync(int fd);
Возвращает при успешном завершении 0 или –1 при ошибке
Использование fdatasync () потенциально сокращает количество дисковых операций с двух, необходимых системному вызову fsync (), до одного. Например, если данные файла изменились, но размер остался прежним, вызов fdatasync () вызывает лишь принудительное обновление данных. (Выше уже отмечалось, что для завершения синхронной операции ввода-вывода с целостностью данных нет необходимости переносить изменение таких аттрибутов, как время последней модификации файла.) В отличие от этого вызов fsync () приведет также к принудительному переносу на диск метаданных.
Такое сокращение количества дисковых операций ввода-вывода будет полезным для отдельных приложений, для которых решающую роль играет производительность и неважно аккуратное обновление конкретных метаданных (например, отметок времени). Это может привести к существенным улучшениям производительности приложений, производящих несколько обновлений файла за раз. Поскольку данные и метаданные файла обычно располагаются в разных частях диска, обновление и тех и других потребует повторяющихся операций поиска вперед и назад по диску.
В Linux 2.2 и более ранних версиях fdatasync () реализован в виде вызова fsync (), поэтому не дает никакого прироста производительности.
Начиная с ядра версии 2.6.17, в Linux предоставляется нестандартный системный вызов sync_file_range (). Он позволяет более точно управлять процессом сброса данных файла на диск, чем fdatasync (). При вызове можно указать сбрасываемую область файла и задать флаги, устанавливающие условия блокировки данного вызова. Дополнительные подробности вы найдете на странице руководства sync_file_range (2).
Системный вызов sync () приводит к тому, что все буферы ядра, содержащие обновленную файловую информацию (то есть блоки данных, блоки указателей, метаданные и т. д.), сбрасываются на диск.
#include
void sync(void);
В реализации Linux функция sync () возвращает управление только после того, как все данные будут перенесены на дисковое устройство (или как минимум в его кэш-память). Но в SUSv3 разрешается, чтобы sync () просто вносила в план перенос данных для операции ввода-вывода и возвращала управление до завершения этого переноса.
Постоянно выполняемый поток ядра обеспечивает сброс измененных буферов ядра на диск, если они не были явным образом синхронизированы в течение 30 секунд. Это делается для того, чтобы не допустить рассинхронизации данных буферов с соответствующим дисковым файлом на длительные периоды времени (и не подвергнуть их риску утраты при отказе системы). В Linux 2.6 эта задача выполняется потоком ядра pdflush. (В Linux 2.4 она выполнялась потоком ядра kupdated.)
Срок (в сотых долях секунды), через который измененный буфер должен быть сброшен на диск кодом потока pdflush, определяется в файле /proc/sys/vm/dirty_expire_centisecs. Дополнительные файлы в том же самом каталоге управляют другими особенностями операции, выполняемой потоком pdflush.
Включение режима синхронизации для всех записей: O_SYNC
Указание флага O_SYNC при вызове open () приводит к тому, что все последующие операции вывода выполняются в синхронном режиме:
fd = open(pathname, O_WRONLY | O_SYNC);
После этого вызова open () каждая проводимая с файлом операция write () автоматически сбрасывает данные и метаданные файла на диск (то есть записи выполняются как синхронизированные операции записи с целостностью файла).
В старых версиях системы BSD для обеспечения функциональных возможностей, включаемых флагом O_SYNC, использовался флаг O_FSYNC. В glibc флаг O_FSYNC определен как синоним O_SYNC.
Влияние флага O_SYNC на производительность
Использование флага O_SYNC (или же частые вызовы fsync (), fdatasync () или sync ()) может сильно повлиять на производительность. В табл. 13.3 показано время, требуемое для записи 1 миллиона байт в только что созданный файл (в файловой системе ext2) при различных размерах буфера с выставленным и со сброшенным флагом O_SYNC. Результаты были получены (с помощью программы filebuff/write_bytes.c, предоставляемой в исходном коде для книги) с использованием «ванильного» ядра версии 2.6.30 и файловой системы ext2 с размером блока 4096 байт. В каждой строке приводится усредненное значение, полученное после 20 запусков для заданного размера буфера.
Таблица 13.3. Влияние флага O_SYNC на скорость записи 1 миллиона байт
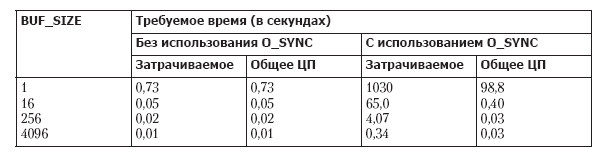
Как видно, указание флага O_SYNC приводит к чудовищному увеличению затрачиваемого времени при использовании буфера размером 1 байт более чем в 1000 раз. Обратите также внимание на большую разницу, возникающую при выполнении записей с флагом O_SYNC, между затраченным временем и временем задействования ЦП. Она является последствием блокирования выполнения программы при фактическом сбросе содержимого каждого буфера на диск.
В результатах, показанных в табл. 13.3, не учтен еще один фактор, влияющий на производительность при использовании O_SYNC. Современные дисковые накопители обладают внутренней кэш-памятью большого объема, и по умолчанию установка флага O_SYNC просто приводит к переносу данных в эту кэш-память. Если отключить кэширование на диске (воспользовавшись командой hdparm –W0), влияние O_SYNC на производительность станет еще более существенным. При размере буфера 1 байт затраченное время возрастет с 1030 секунд до приблизительно 16 000 секунд. При размере буфера 4096 байт затраченное время возрастет с 0,34 секунды до 4 секунд. В итоге, если нужно выполнить принудительный сброс на диск буферов ядра, следует рассмотреть, можно ли спроектировать приложение с использованием бóльших по объему буферов для write () или же подумать об использовании вместо флага O_SYNC периодических вызовов fsync () или fdatasync ().
Флаги O_DSYNC и O_RSYNC
В SUSv3 определены два дополнительных флага состояния открытого файла, имеющих отношение к синхронизированному вводу-выводу: O_DSYNC и O_RSYNC.
Флаг O_DSYNC приводит к выполнению в последующем синхронизированных операций записи с целостностью данных завершаемого ввода-вывода (подобно использованию fdatasync ()). Эффект от его работы отличается от эффекта, вызываемого флагом O_SYNC, использование которого приводит к выполнению в последующем синхронизированных операций записи с целостностью файла (подобно fsync ()).
Флаг O_RSYNC указывается совместно с O_SYNC либо с O_DSYNC и приводит к расширению поведения, связанного с этими флагами при выполнении операций чтения. Указание при открытии файла флагов O_RSYNC и O_DSYNC приводит к выполнению в последующем синхронизированных операций чтения с целостностью данных (то есть прежде чем будет выполнено чтение, из-за наличия O_DSYNC завершаются все ожидающие файловые записи). Указание при открытии файла флагов O_RSYNC и O_SYNC приводит к выполнению в последующем синхронизированных операций чтения с целостностью файла (то есть прежде, чем будет выполнено чтение, из-за наличия O_SYNC завершаются все ожидающие файловые записи).
До выхода версии ядра 2.6.33 флаги O_DSYNC и O_RSYNC в Linux не были реализованы и в заголовочных файлах glibc эти константы определялись как выставление флага O_SYNC. (В случае с O_RSYNC это было неверно, поскольку O_SYNC не влияет на какие-либо функциональные особенности операций чтения.)
Начиная с ядра версии 2.6.33, в Linux реализуется флаг O_DSYNC, а реализация флага O_RSYNC, скорее всего, будет добавлена в будущие выпуски ядра.
До выхода ядра 2.6.33 в Linux отсутствовала полная реализация семантики O_SYNC. Вместо этого флаг O_SYNC был реализован как O_DSYNC. В приложениях, скомпонованных со старыми версиями GNU библиотеки C для старых ядер, в версиях Linux 2.6.33 и выше флаг O_SYNC по прежнему ведет себя как O_DSYNC. Это сделано для сохранения привычного поведения таких программ. (Для сохранения обратной бинарной совместимости в ядре 2.6.33 флагу O_DSYNC было присвоено старое значение флага O_SYNC, а новое значение O_SYNC включает в себя флаг O_DSYNC (на одной из машин это 04010000 и 010000 соответственно). Это позволяет приложениям, скомпилированным с новыми заголовочными файлами, получать в ядрах, вышедших до версии 2.6.33, по меньшей мере семантику O_DSYNC.)
13.4. Обзор буферизации ввода-вывода
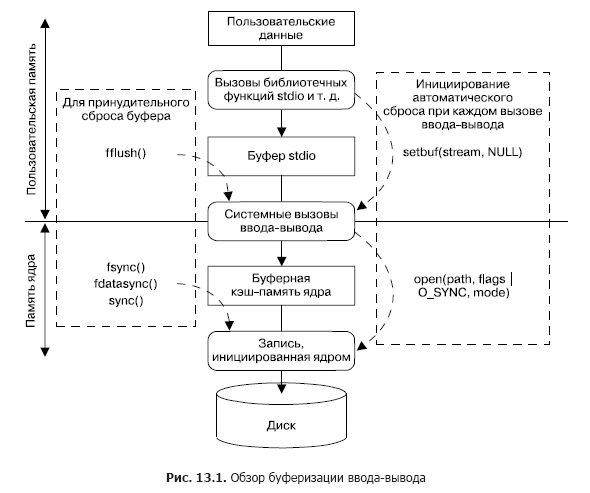
На рис. 13.1 приведена схема буферизации, используемой (для файлов вывода) библиотекой stdio и ядром, а также показаны механизмы для управления каждым типом буферизации. Если пройтись по схеме вниз до ее середины, станет виден перенос пользовательских данных функциями библиотеки stdio в буфер stdio, который работает в пользовательском пространстве памяти. Когда этот буфер заполнен, библиотека stdio прибегает к системному вызову write (), переносящему данные в буферную кэш-память ядра (находящуюся в памяти ядра). В результате ядро инициирует дисковую операцию для переноса данных на диск.
В левой части схемы на рис. 13.1 показаны вызовы, которые могут использоваться в любое время для явного принудительного сброса любого из буферов. В правой части показаны вызовы, которые могут применяться для автоматического выполнения сброса либо за счет выключения буферизации в библиотеке stdio, либо включением для системных вызовов файлового вывода синхронного режима выполнения, чтобы при каждом вызове write () происходил немедленный сброс на диск.
13.5. Уведомление ядра о схемах ввода-вывода
Системный вызов posix_fadvise () позволяет процессу информировать ядро о предпочитаемой им схеме обращения к данным файла.
Ядро может (но не обязано) использовать информацию, предоставляемую системным вызовом posix_fadvise () для оптимизации задействования им буферной кэш-памяти, повышая тем самым производительность ввода-вывода для процесса и для системы в целом. На семантику программы вызов posix_fadvise () не влияет.
#define _XOPEN_SOURCE 600
#include
int posix_fadvise(int fd, off_t offset, off_t len, int advice);
Возвращает при успешном завершении 0 или положительный номер ошибки при ее возникновении
Аргумент fd является дескриптором файла, идентифицирующим тот файл, о схеме обращения к которому нужно проинформировать ядро. Аргументы offset и len идентифицируют область файла, к которой относится уведомление: offset указывает на начальное смещение области, а len — на ее размер в байтах. Присвоение для len значения 0 говорит о том, что имеются в виду все байты, начиная с offset и заканчивая концом файла. (В версиях ядра до 2.6.6 значение 0 для len интерпретировалось буквально, как 0 байт.)
Аргумент advice показывает предполагаемый характер обращения процесса к файлу. Он определяется с одним из следующих значений.
POSIX_FADV_NORMAL — у процесса нет особого уведомления, касающегося схем обращения. Это поведение по умолчанию, если для файла не дается никаких уведомлений. В Linux эта операция устанавливает для окна упреждающего считывания данных из файла его исходный размер (128 Кбайт).
POSIX_FADV_SEQUENTIAL — процесс предполагает последовательное считывание данных от меньших смещений к бóльшим. В Linux эта операция устанавливает для окна упреждающего считывания данных из файла его удвоенное исходное значение.
POSIX_FADV_RANDOM — процесс предполагает обращение к данным в произвольном порядке. В Linux этот вариант отключает упреждающее считывание данных из файла.
POSIX_FADV_WILLNEED — процесс предполагает обращение к указанной области файла в ближайшее время. Ядро выполняет упреждающее считывание данных для заполнения буферной кэш-памяти данными файла в диапазоне, заданном аргументами offset и len. Последующие вызовы read () в отношении файла не блокируют дисковый ввод-вывод, а просто извлекают данные из буферной кэш-памяти. Ядро не дает никаких гарантий насчет продолжительности нахождения извлекаемых из файла данных в буферной кэш-памяти. Если при работе другого процесса или ядра возникнет особая потребность в памяти, то страница в конечном итоге будет повторно использована. Иными словами, если память остро востребована, нам нужно гарантировать небольшой разрыв по времени между вызовом posix_fadvise () и последующим вызовом (или вызовами) read (). (Функциональные возможности, эквивалентные операции POSIX_FADV_WILLNEED, предоставляет характерный для Linux системный вызов readahead ().)
POSIX_FADV_DONTNEED — процесс не предполагает в ближайшем будущем обращений к указанной области файла. Тем самым ядро уведомляется, что оно может высвободить соответствующие страницы кэш-памяти (если таковые имеются). В Linux эта операция выполняется в два этапа. Сначала, если очередь записи на базовом устройстве не переполнена серией запросов, ядро сбрасывает любые измененные страницы кэш-памяти в указанной области. Затем ядро предпринимает попытку высвободить все страницы кэш-памяти из указанной области. Для измененных страниц в данной области второй этап завершится успешно, только если они были записаны на базовое устройство в ходе первого этапа, то есть очередь записи на устройстве не переполнена. Так как приложение не может проверить состояние очереди на устройстве, гарантировать освобождение страниц кэша можно, вызвав fsync () или fdatasync () в отношении дескриптора fd перед применением POSIX_FADV_DONTNEED.
POSIX_FADV_NOREUSE — процесс предполагает однократное обращение к данным в указанной области файла, без ее повторного использования. Тем самым ядро уведомляется о том, что оно может высвободить страницы после однократного обращения к ним. В Linux эта операция в настоящее время остается без внимания.
Спецификация posix_fadvise () появилась только в SUSv3, и этот интерфейс поддерживается не всеми реализациями UNIX. В Linux вызов posix_fadvise () предоставляется, начиная с версии ядра 2.6.
13.6. Обход буферной кэш-памяти: непосредственный ввод-вывод
Начиная c версии ядра 2.4, Linux позволяет приложению обходить буферную кэш-память при выполнении дискового ввода-вывода, перемещая данные непосредственно из пользовательского пространства памяти в файл или на дисковое устройство. Иногда этот режим называют непосредственным или необрабатываемым вводом-выводом.
Приведенная здесь информация относится исключительно к Linux и не стандартизирована в SUSv3. Тем не менее некоторые варианты непосредственного доступа к вводу-выводу в отношении устройств или файлов предоставляются большинством реализаций UNIX.
Иногда непосредственный ввод-вывод неверно понимается в качестве средства достижения высокой производительности ввода-вывода. Но для большинства приложений использование непосредственного ввода-вывода может существенно снизить производительность. Дело в том, что ядро выполняет несколько оптимизаций для повышения производительности ввода-вывода за счет использования буферной кэш-памяти, включая последовательное упреждающее чтение данных, выполнение ввода-вывода в кластерах, состоящих из дисковых блоков, и позволение процессам, обращающимся к одному и тому же файлу, совместно задействовать буферы в кэш-памяти. Все эти виды оптимизации при использовании непосредственного ввода-вывода утрачиваются. Он предназначен только для приложений со специализированными требованиями к вводу-выводу, например для систем управления базами данных, выполняющих свое собственное кэширование и оптимизацию ввода-вывода, и которым не нужно, чтобы ядро тратило время центрального процессора и память на выполнение таких же задач.
Непосредственный ввод-вывод можно выполнять либо в отношении отдельно взятого файла, либо в отношении блочного устройства (например, диска). Для этого при открытии файла или устройства с помощью вызова open () указывается флаг O_DIRECT.
Флаг O_DIRECT работает, начиная с версии ядра 2.4.10. Использование этого флага поддерживается не всеми файловыми системами и версиями ядра Linux. Большинство базовых файловых систем поддерживают флаг O_DIRECT, но многие файловые системы, не относящиеся к UNIX (например, VFAT), — нет. Можно проверить поддержку этой возможности, протестировав выбранную файловую систему (если файловая система не поддерживает O_DIRECT, вызов open () даст сбой с выдачей ошибки EINVAL) или исследовав на этот предмет исходный код ядра.
Если один процесс открыл файл с флагом O_DIRECT, а другой — обычным образом (то есть с использованием буферной кэш-памяти), то согласованность между содержимым буферной кэш-памяти и данными, считанными или записанными через непосредственный ввод/вывод, отсутствует. Подобного развития событий следует избегать.
Сведения об устаревшем (ныне нерекомендуемом) методе получения необрабатываемого (raw) доступа к дисковому устройству можно найти на странице руководства raw (8).
Ограничения по выравниванию для непосредственного ввода-вывода
Поскольку непосредственный ввод-вывод (как на дисковых устройствах, так и в отношении файлов) предполагает непосредственное обращение к диску, при выполнении ввода-вывода следует соблюдать некоторые ограничения.
— переносимый буфер данных должен быть выровнен по границе памяти, кратной размеру блока.
— Смещение в файле или в устройстве, с которого начинаются переносимые данные, должно быть кратно размеру блока.
— длина переносимых данных должна быть кратной размеру блока.
Несоблюдение любого из этих ограничений влечет за собой возникновение ошибки EINVAL. В показанном выше перечне под размером блока подразумевается размер физическего блока устройства (обычно это 512 байт).
При выполнении непосредственного ввода-вывода в Linux 2.4 накладывается больше ограничений, чем в Linux 2.6: выравнивание, длина и смещение должны быть кратны размеру логического блока используемой файловой системы. (Обычно размеры логических блоков в файловой системе равны 1024, 2048 или 4096 байт.)
Пример программы
В листинге 13.1 предоставляется простой пример использования O_DIRECT при открытии файла для чтения. Эта программа воспринимает до четырех аргументов командной строки, указывающих (в порядке следования) файл, из которого будут считываться данные, количество считываемых из файла байтов, смещение, к которому программа должна перейти, прежде чем начать считывание данных из файла, и выравнивание буфера данных, передаваемое read (). Последние два аргумента опциональны и по умолчанию настроены соответственно на значения нулевого смещения и 4096 байт.
Рассмотрим примеры того, что будет показано при запуске программы:
$ ./direct_read /test/x 512 Считывание 512 байт со смещения 0
Read 512 bytes Успешно
$ ./direct_read /test/x 256
ERROR [EINVAL Invalid argument] read Длина не кратна 512
$ ./direct_read /test/x 512 1
ERROR [EINVAL Invalid argument] read Смещение не кратно 512
$ ./direct_read /test/x 4096 8192 512
Read 4096 bytes Успешно
$ ./direct_read /test/x 4096 512 256
ERROR [EINVAL Invalid argument] read Выравнивание не кратно 512
Программа в листинге 13.1 выделяет блок памяти, который выровнен по адресу, кратному ее первому аргументу, и для этого использует функцию memalign (). Функция memalign () рассматривалась в подразделе 7.1.4.
#define _GNU_SOURCE /* Получение определения O_DIRECT из */
#include
#include
#include "tlpi_hdr.h"
int
main(int argc, char *argv[])
{
int fd;
ssize_t numRead;
size_t length, alignment;
off_t offset;
void *buf;
if (argc < 3 || strcmp(argv[1], "–help") == 0)
usageErr("%s file length [offset [alignment]]\n", argv[0]);
length = getLong(argv[2], GN_ANY_BASE, "length");
offset = (argc > 3) ? getLong(argv[3], GN_ANY_BASE, "offset") : 0;
alignment = (argc > 4) ? getLong(argv[4], GN_ANY_BASE,
"alignment") : 4096;
fd = open(argv[1], O_RDONLY | O_DIRECT);
if (fd == -1)
errExit("open");
/* Функция memalign() выделяет блок памяти, выровненный по адресу,
кратному ее первому аргументу. Следующее выражение обеспечивает
выравнивание 'buf' по границе, кратной 'alignment',
но не являющейся степенью двойки. Это делается для того, чтобы в случае,
к примеру, запроса буфера с выравниванием, кратным 256 байтам,
не происходило случайного получения буфера, выровненного также
и по 512-байтовой границе. Приведение к типу '(char *)' необходимо
для проведения с указателем арифметических операций (что невозможно
сделать с типом 'void *', который возвращает memalign(). */
buf = (char *) memalign(alignment * 2, length + alignment)
+ alignment;
if (buf == NULL)
errExit("memalign");
if (lseek(fd, offset, SEEK_SET) == -1)
errExit("lseek");
numRead = read(fd, buf, length);
if (numRead == -1)
errExit("read");
printf("Read %ld bytes\n", (long) numRead);
exit(EXIT_SUCCESS);
}
_______________________________________________________________filebuff/direct_read.c
» Более подробно с книгой можно ознакомиться на сайте издательства
» Оглавление
» Отрывок
Для Хаброжителей скидка 20% по купону — Linux
