Квоты в Kubernetes: очевидные, менее очевидные и совсем не очевидные
Привет, Хабр! Я Виктор, техлид продукта CI/CD в Samokat.tech. А это, :(){ :|:& };: fork-бомба, которая создаёт свои дочерние процессы бесконечно. Запуск такой штуки в контейнере без ограничений роняет всю ноду. Не используйте в проде! Если запустить в WSL, то винду тоже укладывает. Как же избежать запуска такой штуки на проде? Помогут квоты.
Давайте разберемся как работают квоты в Kubernetes. Там есть немало граблей. В этой статье поделюсь своим опытом по работе с квотами — расскажу, чем квоты хороши, что у них под капотом, в каких задачах используются и почему нужны даже в среде single-tenant.
Базовые понятия: контейнер
Начнём с определений и того, как устроены контейнеры.
Контейнер — это просто изолированный линуксовый процесс. Изоляция реализуется механизмами ядра Linux: cgroup, Namespaces, Capabilities и другими.
cgroup — это механизм, который ограничивает потребление ресурсов «железа»: память, CPU, диск и сеть.
Namespaces — это абстракция над ресурсами ядра операционной системы.
Существует семь пространств имён в Namespace:
cgroup
IPC (InterProcessConnection)
Network
Mount
PID
User
UTS
Например, если процессы проходят в одном Namespace PID, то они делят между собой пространство номеров процессов. А если в разных, то у каждого нумерация будет своя. За счёт этого механизма в каждом контейнере родительский процесс имеет PID 1.
Capabilities — это разрешения процесса на выполнение определённых системных вызовов.
Всего их около 40. Например:
CAP_CHOWN — разрешение на смену UID и GUID файла.
CAP_KILL — разрешение на отправку сигналов (sigterm, sigkill и др.).
Если у контейнера нет такого разрешения, то из него нельзя завершить собственный процесс. А если есть, то можно.
Полный список тут.
Что происходит, когда мы запускаем контейнер?
У нас есть Docker Client. Мы выполняем команду docker run Nginx. Она отправляет в Docker Daemon запрос «создать контейнер». Для этого Docker Daemon идёт в контейнер Runtime, которым по умолчанию является Containerd. Это высокоуровневый Runtime. Следом он направляется в так называемый Shim — прослойку между низкоуровневым и высокоуровневым Runtime. Shim транслирует всё в низкоуровневые команды, обращается в Runc, который создаёт cgroup и Namespace и размещает там процесс. Всё это и есть контейнер.
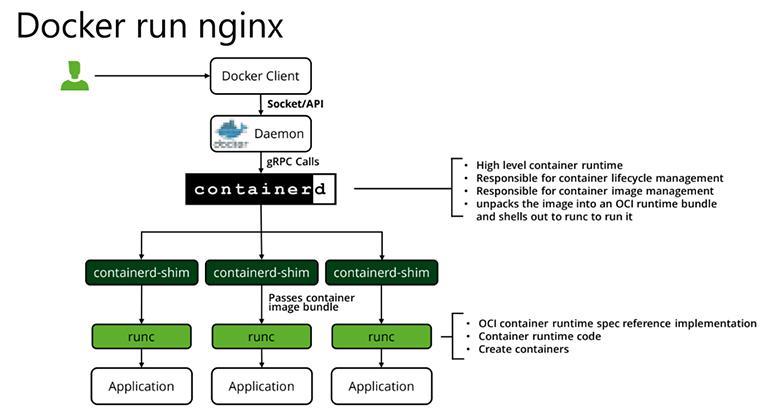
Если вы ни разу не запускали контейнер с помощью голого Runc, то очень советую. Занятный академический эксперимент, который хорошо показывает как много слоёв абстракции скрывают от нас высокоуровневые рантаймы. Например, Docker.
А теперь давайте вернемся к cgroup, так как именно они реализуют основные квоты Kubernetes.
cgroup или контрольные группы
cgroup или контрольные группы позволяют помещать процессы в иерархические группы, в которых системные ресурсы могут быть ограничены.
Контроллеры первой версии
Вообще cgroup — это не единый инструмент, а куча отдельных контроллеров для разных ресурсов. Многие знакомы именно с первой версией cgroup. Контроллеры, которые отвечают за ресурсы в cgroup v1, писались по-разному и в разное время. Вот, например, цитата из документации memory контроллера, которая показывает насколько там всё просто и понятно (ссылка https://www.kernel.org/doc/Documentation/cgroup-v1/memory.txt):
NOTE: This document is hopelessly outdated and it asks for a complete
rewrite. It still contains a useful information so we are keeping it
here but make sure to check the current code if you need a deeper
understanding.
Какие контроллеры cgroup v1 нас интересуют:
CPU — гарантирует минимальное количество «CPU shares». Управляет гарантированным выделением ресурсов процессоров, чтобы всем хватило.
Cpuact — создаёт отчёты об использовании ресурсов процессора и считает как используется процессорное время.
Cpuset — позволяет закрепить процесс за определёнными ядрами. Говорит, что к конкретному ядру имеет доступ только определённый процесс. Мы прикрепляем процессы к ядрам, чтобы предоставить эксклюзивное использование.
Memory — отслеживает и ограничивает количество памяти процесса.
Blkio — устанавливает лимиты на чтение и запись с блочных устройств.
Про все эти контроллеры мы поговорим ниже в контексте K8s.
Контроллеры второй версии
Когда появились единые стандарты написания контроллеров, всё переписали и вообще всё стало лучше и понятнее. Результатом стали контроллеры второй версии. K8s поддерживает cgroup v2, но чтобы начать их использовать, нужно чтобы они были включены на уровне системы для systemd. Ну и поддержка со стороны Container Runtime тоже нужна. Правда все современные runtime, такие как Containerd, уже умеют с ними работать.
Также нужна поддержка со стороны приложений. Например, Java знает о cgroup v2 только с 15+ версией, а о cgroup v1 — с 8й. Позже поддержку бекпортнули и в более ранние версии, но если java меньше 15, то есть шанс, что в вашей версии они не поддерживаются. Тогда при переходе на cgroups v2 приложение не будет знать об ограничении ресурсов и начнёт считать, что ему доступны все ресурсы ноды.
Квоты в Kubernetes
Квоты — это механизмы, которые позволяют ограничивать использование ресурсов для контейнера. А еще квоты позволяют гарантировать контейнеру наличие обещанных ему ресурсов Квоты назначаются не на под, а на контейнеры, из которых он состоит. Это важно!
Limits & requests
Requests (реквесты) — это количество ресурсов, наличие которых мы гарантируем контейнеру. Контейнер просто не запустится, если нет достаточного количества свободного ресурса.
Limits (лимиты) — это максимальное количество ресурса, доступное контейнеру. Они никак не гарантируются и могут многократно превышать свободные и общие ресурсы ноды. Лимиты можно задавать произвольно: если скажете, что у вас лимит 100500 ядер или йоттабайты памяти, контейнер зашедулится и будет считать, что ему доступно именно столько ресурсов.
В ванильном k8s, если задать только лимиты, то реквесты автоматически получат такое же значение. Если проставить только реквесты, то лимитов не будет вообще.
В Openshift поведение другое, но какое точно — я не помню :)
Quality of Service class
У K8s есть три QOS-класса:
Guaranteed, когда для каждого контейнера в поде проставлены равные друг другу лимиты и реквесты по CPU и памяти. Важно, что лимиты должны быть равны реквестам для каждого контейнера. Если хотя бы для одного они расходятся, то мы не получим гарантированный QOS.
Burstable, когда мы не удовлетворяем критериям Guaranteed, но хотя бы для одного контейнера в поде есть реквесты или лимиты по CPU или памяти.
BestEffort, когда ни один контейнер в поде не имеет реквестов или лимитов по CPU или памяти. Применяется, когда вообще ничего нет.
На самом деле классы сами по себе не несут никакой практической пользы. Они косвенно влияют на eviction, хотя этот механизм сравнивает превышение requests над limits при выборе пода для eviction. В итоге получается, что если у нас мало ресурсов на ноде и надо их частично освободить, то с большей вероятностью уйдут BestEffort, чем Guaranteed. Но если ресурсов совсем не хватает, то уйдут и поды гарантированного класса.
Очевидные квоты
Переходим к квотам и разберём их по порядку — от самых очевидных к менее известным.
Квоты, о которых многие знают или слышали — Compute Resource quota. Начнём с памяти.
Memory
Limit. Есть cgroup — Memory, и она определяет Memory Limit. Когда приложение достигло лимита по памяти, cgroup вызывает Out Of Memory (OOM) Killer, который убивает один из процессов контейнера. Важно, что не обязательно PID 1.
OOM Killer ничего не знает про внутреннее устройство контейнера. Если в контейнере больше одного процесса, то OOM Killer, посчитает OOM Score и убьёт какой-то процесс.
Представьте ситуацию: у вас есть условный NGINX, у которого есть корневой процесс. Внутри некоторое количество воркеров, которые занимают всю память. OOM Killer убивает воркер. Контрольный процесс NGINX видит это и переподнимает воркер. Пока OOM Killer не попадет в родительский процесс, другие процессы внутри контейнера будут убиваться и перезапускаться. А пользователей будут встречать пятисотые ошибки. В реальности это очень плохо видно и обнаруживается только, если целенаправленно мониторить.
Requests. При использовании, cgroup v1 память под requests не резервируется, но на момент запуска она должна быть доступна. Если же используются cgroup v2, то специальные контроллеры выделяют память с помощью Memory.min и Memory.low и эксклюзивно резервируют ее под ваш процесс. Если мы задаём реквест, cgroup v2 эту память резервирует, и ей больше никто не может пользоваться, а cgroup v1 просто удостоверяются, что эта память доступна и никем не используется.
Tmpfs учитывается как память, потребляемая контейнером. Если вы хотите писать во временное In-memory хранилище, нужно учитывать это при выставлении квоты по памяти.
В cgroup v2 появился флаг memory.oom.group. Если он выставлен для cgroup, то OOM Killer убьет все процессы в этой cgroup. Недавно поддержка этой фичи появилась в k8s (https://github.com/kubernetes/kubernetes/pull/117793)
Теперь рассмотрим, как этим пользоваться.
Memory. Приложения
Приложения должны знать о том, что cgroup существуют, но это не всегда реализуется. В некоторых случаях надо настраивать явно и отдельно. К примеру, есть старая Java, которой надо проставлять Xmx, потому что иначе она для своих хипов считает всю память ноды. Начиная с 10-й версии, Java по умолчанию ставит флаг «Use Container Support», благодаря которому процессы стараются узнать об ограничениях, наложенных на них через cgroups. Но опять же, если у вас cgroup v2, а Java v11, она ничего не найдёт и будет считать, что ограничений нет.
CPU requests
Теперь самое интересное, посмотрим, как работают реквесты по процессору.
Спойлер: в работе реквестов и лимитов по процессору используются разные механизмы.
Реквесты используют CPU Shares. Корневая cgroup (Root) содержит некоторое количество долей CPU. По умолчанию это 1024 доли на каждое ядро. Эта cgroup наследует дочерним cgroup пропорционально их CPU Shares и так далее. Выглядит как на схеме ниже.

В этом примере у нас 4 ядра и корневая cgroup Root содержит 4096 shares. В этой cgroup содержатся другие cgroup: system.slice, User.slice и Kubepods. Возможно, вы заметили, что математика не сходится. Долей в абсолютных единицах может быть выделено любое количество, но их количество считается относительно друг друга. То есть в данном примере у kubepod будет 4/6 процессорного времени, а у system.slice и user.slice — по 1/6.
Дальше Kubepods делится по разным QOS (Quality Of Service). Внутри есть контейнер, в нём какие-то Shares, и Completely Fair Scheduler (линуксовый механизм шедулинга процессора) обеспечивает честный доступ к процессорному времени пропорционально выделенной доле. Ограничения на использование cpu работают, только если есть конкуренция. Соответственно, если остальные процессы полностью не используют гарантированное для них процессорное время, то любой другой процесс может использовать больше cpu, чем ему гарантированно.
Если же все процессы максимально пытаются использовать CPU, то каждый из них получит лишь гарантированную долю процессорного времени.
CPU limits
Лимиты используют контроллеры cfs_period_us и cfs_quota_us. Здесь стоит «us» по аналогии с латинским «μs» — микросекунды.
В отличие от реквестов, лимиты базируются на отрезках времени:
Квоты по умолчанию считаются 100-миллисекундными отрезками.
Это считается так. Мы выдаём квоту контейнеру — два ядра. Это значит, что ему доступно две секунды процессорного времени в одну секунду реального. Следовательно, контейнеру доступно 200 мс процессорного времени за 100 мс реального.
А дальше происходит следующее.
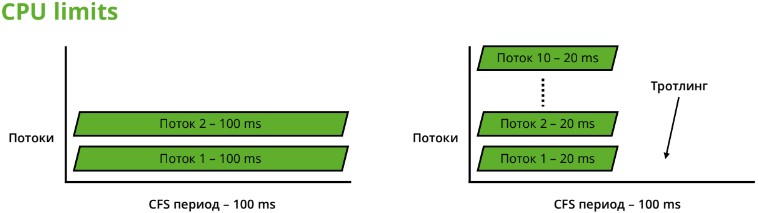
1. 2 потока при квоте 2 ядра (200ms в 100ms период)
2. 10 потоков при квоте 2 ядра (200ms в 100ms период)
Слева контейнер, внутри которого два потока, и каждому достаётся по 100 мс. Они работают отлично. А справа такой же контейнер, в котором мы запустили приложение в десять потоков. Но ему всё ещё доступно 200 мс за 100 мс реального времени.
Представим, что ситуация эталонная, все потоки одинаковые, и каждый использовал свою квоту за 20 мс. Дальше наступает троттлинг: в течение 80 мс ничего не происходит, процессу вообще не достается процессорное время. График такого процесса выглядит так: «работаем 20 мс, не работаем 80 мс, работаем 20 мс, не работаем 80 мс».
Это одна из причин старой доброй рекомендации: один контейнер — один процесс. Если у вас многопоточное приложение в контейнере, думайте, как оно потребляет процессор и задавайте такие квоты, чтобы хватало. Общая рекомендация — 1 ядро лимита на один поток. Иногда можно поэкспериментировать с CFS-периодом, чтобы квота считалась более короткими окнами и периоды троттлинга были меньше. Но это уже задача со звёздочкой.
История бага Completely Fair Scheduler
Про CPU-лимиты ходят интересные байки. К примеру, много рекомендаций вроде «не надо пользоваться квотами на CPU, всё дико тормозит, мы получаем рандомные троттлинги и всё очень плохо». Кажется, корень такого мнения — давний баг Completely Fair Scheduler, который исправили в ноябре 2019 года в ядре 4.14.4. CFS и правда слишком агрессивно троттлил, так как считал системные вызовы в квоту процесса, соответственно квота кончалась преждевременно.
Баг описан в посте Overly aggressive CFS. Там сделан разбор с примерами кода, и видно, как это работает.
Но возможны и другие проблемы. Например, мои коллеги раскопали, что при выставлении 1024 shares java игнорирует cpu cgroup и считает, что ей доступны все ядра ноды.
Подробнее тут: https://habr.com/ru/companies/samokat_tech/articles/735638/
С CPU вообще всё сложно:
Hypertreading
Hypertreading часто включен, потому что солидней видеть 40 ядер, а не 20. Выглядит, будто Hypertreading даёт производительность х2, а реально — около 20% и то при хорошем сценарии, когда все ядра загружены.
То есть вы поделили ноду между контейнерами, нарезали квоты, но половина ядер — ненастоящие. Поэтому если нужна честная производительность, то надо выключить Hypertreading.
Вчера вы купили одни сервера, а завтра Intel обновил модельную линейку, и вы завезли в кластер новые — в итоге на разных нодах разные процессоры. Значит, где-то одно и то же приложение будут работать быстрее, а где-то медленнее даже при равной частоте процессора. А если еще и частоты различаются…
А ещё есть многопроцессорные системы. Один контейнер заехал в один процессор, второй — в другой, они между собой общаются, а это долго. А когда они вдвоём на одном физическом процессоре — всё происходит быстрее.
Эти ситуации объективно мало кому мешают, но когда у вас адовый highload, и вы боретесь за микросекунды, то добро пожаловать в увлекательный мир понимая, как вообще работает процессор.
В целом квоты в K8s — это история про баланс. С одной стороны, есть высокая утилизация ресурсов, а с другой стороны гарантия их доступности. Если мы хотим высокие гарантии по используемым ресурсам, то утилизация будет низкой. И наоборот, если нужна высокая утилизация, то вероятен частый троттлинг и низкая гарантия доступности ресурсов.
При этом универсального ответа, как найти баланс, нет. Решение лежит в части архитектуры приложения. Квоты в K8s далеко не идеальны, но ничего лучше у нас нет.
CPU Management Policies
CPU Management Policies позволяет закреплять выделенные ядра за отдельными контейнерами. Для этого используется Cpuset cgroup.
Ограничения
Средняя утилизация кластера при этом, конечно же, снижается. Ядро будет доступно только определенному контейнеру и даже если оно почти не используется — другим контейнерам процессорное время этого ядра выделяться не будет.
На Хабре есть перевод классной статьи ребят из Uber на эту тему (https://habr.com/ru/companies/wunderfund/articles/658309/). Там рассказывают, что CPU Management Policies по умолчанию довольно умные, умеют всё раскидывать по numa-нодам, но возможна и более тонкая настройка.
CPU. Приложения
Что касается приложений — важно понимать, как всё работает с реальным железом поверх абстракций и учитывать, как выделяются ресурсы CPU.
Kubernetes scheduler и ресурсы
Теперь обсудим, для чего нужны очевидные квоты и как применить их на практике.
В K8s есть Scheduler (шедулер) — один из компонентов, который определяет, на какую ноду будет размещаться POD.
Шедулер работает в два этапа:
Filtering — выбирает подходящие ноды и выкидывает лишние.
Scoring — оценивает подходящие ноды и выбирает из них.
В итоге на ноду, которая победила, заезжает контейнер.
Filtering в шедулере работает по квотам. А квоты помогают оптимально разносить нагрузки по контейнерам. В K8s для каждой ноды известно доступное количество ресурсов — Allocatable Pool. Поэтому сумма реквестов контейнеров, запущенных на этой ноде не может быть больше, чем это значение. Соответственно, если Allocatable Pool исчерпан, то больше на ноду ничего зашедулено не будет. Других способов понять, что нода утилизирована у шедуллера нет.
Как квоты решают проблему недостатка ресурсов
У шедулера есть большое количество плагинов, но нам сейчас интересен NodeResourcesFit. Он проверяет ресурсы на нодах на этапе Filtering и смотрит, что доступно по реквестам. На этапе Scoring плагин выбирает подходящую ноду. У него есть три стратегии:
LeastAllocated, применяется по умолчанию — приоритет для ноды, которая менее всего утилизирована.
MostAllocated — приоритет для ноды, которая более всего утилизирована, но где всё же достаточно ресурсов для нагрузки.
RequestedToCapacityRatio — сравнивается соотношение ёмкости ноды к запрошенному количеству ресурсов, таким образом более требовательные контейнеры будут запущены на более «жирных» нодах.
Вообще, при необходимости, шедулер хорошо тюнится для конкретных случаев, если стандарные сценарии вам не подходят. А ещё можно написать свой шедулер, документация k8s рассказывает, как это сделать.
Менее очевидные квоты
Теперь посмотрим на менее очевидные квоты — Storage и Ephemeral Storage.
Storage квоты
Квоты на storage ограничивают потребление подсистемы хранения в рамках Namespaces.
Что они могут:
Requests.storage — квота на суммарный размер всех PVC в Namespaces.
Persistentvolumeclaims — квота на количество PVC в Namespaces.
.storageclass.storage.k8s.io/ — квоты для конкретных storage class.
Квоты по Storage ограничивают пользователя от бесконтрольного потребления подсистемы хранения и помогают вам понимать сколько и какого места вы выделили в каждый конкретный Namespaces.
Квоты Ephemeral Storage
Эфемерное хранилище
В эфемерке хранятся: emptyDir маунты (кроме tmpfs), логи контейнера, которые пишутся logging-драйвером, и rw-слой контейнера.
Так как все контейнеры обычно используют один раздел хостовой операционной системы, то любой из них может полностью занять всё доступное место, что повлияет на всех соседей.
Возможно, дальше придёт Eviction, выселит этот контейнер, но какое-то время у всех будет: «No space left on device», и дырки в логах.
Requests
Реквесты проверяют количество свободного места, которое должно быть на ноде на момент запуска контейнера, и участвуют в шедулинге.
Важно, что реквесты не резервируют свободное место. То есть на момент запуска место доступно, но в процессе работы его может стать меньше.
Limits
Лимиты говорят какое максимальное количество эфемерного хранилища доступно для контейнера. При превышении контейнер будет перезапущен.
Storage. Каких квот нет, а хотелось бы
Квот по IOPS нет. Если какой-то безумный контейнер неистово пишет на диск, то у всех остальных контейнеров, использующих тот же диск будут проблемы.
Ранее я упомянул blkio-контроллер для cgroup, он может ограничивать iops для блочных устройств, но поддержки таких ограничений в k8s нет. В cgroup v2 есть полноценная поддержка iops квот (max-read-ops, max-write-ops, max-read в байтах, в том числе, в секунду), но в k8s поддержки также нет. Я надеюсь, что рано или поздно она появится.
Совсем неочевидные квоты
Теперь расскажу про совсем неочевидные квоты.
Object Count Quota
Эта квота говорит, какое максимальное количество ресурсов определенного типа вообще может быть в namespace:
count/
Пример для кастомного ресурса widgets из API группы example.com:
count/widgets.example.com
Список плюс-минус типовых Object Count Quota:
Какие задачи решают эти квоты.
Защита от ошибок.
В k8s есть лимит количества подов на одну ноду. По умолчанию в K8s — 110 штук. Соответственно, если кто-то создаст в Namespace очень много подов, то больше никто в кластере поды создавать не сможет. Речь не обязательно про злой умысел и попытку устроить denial of service в кластере, но и защита от мисконфигурации.
Предотвращает плохие практики
Можно принудить разработчиков хранить секреты в Vault, установив нулевую квоту на secrets или запретить использование nodePorts.
PID limits
Для контейнера можно выставить ограничения по количеству PID. Это не совсем квота в понимании K8s, а скорее глобальная настройка Kubelet.
Количество PID ограничено и общее для всей ноды. Поэтому если в контейнере создать много процессов, то количество PID может исчерпаться, что приведёт к проблемам при создании новых процессов.
Зачем нужны PID limits внутри контейнера хорошо объясняет злой смайлик:
:(){ :|:& };:
Это уже знакомая нам по вступлению к статье fork-бомба, которая создаёт свои дочерние процессы бесконечно. Повторюсь: запуск такой штуки в контейнере без ограничений роняет всю ноду; не используйте в проде! И да, если запустить в WSL, то винду тоже укладывает.
Квоты на Extended Resources
Extended Resources — это любые внешние для k8s ресурсы. K8s ничего о них не знает и никак с ними не работает.
Ресурсы бывают двух видов:
Каждая нода имеет какое-то количество ресурса, который можно использовать. Node level часто управляются Device Plugin.
Квоты на Extended Resources могут быть представлены только целыми числами и не имеют limits, есть только requests.
Пример квоты на extended resource NVIDIA драйвера, который отдаёт кастомный ресурс GPU:
requests.nvidia.com/gpu:»4»
А вот так нельзя, поддерживаются только реквесты:
limits.nvidia.com/gpu:»4»
Extended Resources используются шедулером, но их работа очень условная абстракция, которая может быть использована только с дополнительным кодом, таким как драйверы, плагины или операторы. Из коробки логики работы с конкретными Extended Resources в k8s нет.
Но есть инструменты, которые как будто вообще не про квоты в контексте K8s, но тоже что-то ограничивают.
Network Bandwith
Например, многие CNI плагины позволяют ограничивать ширину канала для контейнера. Можно ограничивать и входящий и исходящий канал. Это пригодится, если у вас есть контейнер, который гоняет данные массово, но вы не хотите, чтобы он занял всю сеть.
Network Bandwith обычно настраивается через аннотации к pod, на которую смотрит cni плагин и устанавливает соответствующие ограничения. Это не квота в привычном понимании, но смысл тот же.
Общие ресурсы
Контейнеры используют ряд общих ресурсов, которые шарятся, но часто никак не ограничиваются. Покажу пару примеров.
Ядро
У эфемерного хранилища контейнеров общая файловая система и общий пул файловых дескрипторов — Inode. Они нужны для идентификации файлов в системе. Если внутри одного контейнера создать большое количество файлов, то Inode кончатся на всей файловой системе. Никто больше никаких файлов создавать не сможет.
Ещё есть Dentry Cache — кэш файловой системы хранит связь между файлами и директориями, в которых они находятся.
В качестве примера приведу крутейшую историю про взаимное влияние контейнеров (для чтения нужен ВПН), когда за счёт Dentry Cache независимые контейнеры влияли на производительность друг друга.
Пара рекомендаций по внедрению квот
Параметры Kube-reserved и System-reserved резервируют часть ресурсов ноды под системные компоненты и не отдают их, а предоставляют пользовательским контейнерам. Соответственно, если где-то ресурс закончится, то это не повлияет на работу Kubelet.
А еще не рекомендую проставлять Default квоты. Все квоты должны выставляться явно, чтобы избегать unexpected behaviour из-за непонятно откуда взявшихся ограничений, о которых могут не знать разработчики при запуске своих приложений. Пусть лучше контейнер для которого квоты не установлены — не запустится с явной ошибкой.
Зачем вводить квоты
Есть несколько причин, почему стоит ввести квоты:
Уменьшить влияние контейнеров друг на друга.
Повысить стабильность нод кластера.
Получить предсказуемую производительность контейнеров или явно от неё отказаться ради переподписки.
Если вы используете переподписку по квотам, то получаете контракт: кто-то проставил эти квоты и взял на себя ответственность, что готов к разным побочным эффектам, в зависимости от размера переподписки.
Даже если у вас не multi-, а single-tenant система, в ней есть компоненты, которые важно защитить от удаления с ноды. Например, контейнеры CNI или средства мониторинга. Использование квот позволяет уменьшить это влияние и сделать поведение системы более предсказуемым.
