Курс «PostgreSQL для начинающих»: #1 — Основы SQL
Этим постом я запускаю публикацию расширенных транскриптов лекционного курса «PostgreSQL для начинающих», подготовленного мной в рамках «Школы backend-разработчика» в «Тензоре».
В программе: рассказ об основах SQL, возможностях простых и сложных SELECT, анализ производительности запросов, разбор [не]эффективного применения индексов и особенностей работы транзакций и блокировок в этой СУБД.
Курс не претендует на лавры «войти в айти», поэтому подразумевает наличие у слушателя опыта программирования или работы с другими СУБД, и, главное, желания самостоятельно изучать тему работы с PostgreSQL глубже.
Для тех, кому комфортнее смотреть и слушать, а не читать — доступна видеозапись:

Что такое SQL
Сегодня у нас первая лекция из серии «PostgreSQL для начинающих», и говорить на ней мы будем о самых основах SQL — вот этого «хвостика» в названии PostgreSQL.
Меня зовут Боровиков Кирилл, и в «Тензоре» я занимаюсь всем, что касается баз данных — как SQL, так и NoSQL — разных. Но сегодня мы будем говорить именно об SQL.
Во-первых, SQL — это Structured Query Language — «язык структурированных запросов», вот определение из wiki:
SQL (МФА: [ˈɛsˈkjuˈɛl]; аббр. от англ. Structured Query Language — «язык структурированных запросов») — декларативный язык программирования, применяемый для создания, модификации и управления данными в реляционной базе данных, управляемой соответствующей системой управления базами данных.
В нем отметим три ключевых момента: SQL — это декларативный язык, который используется для управления данными в реляционных базах. Давайте чуть подробнее посмотрим, что это значит…
Декларативный язык
Что вообще такое «декларативный» язык программирования и в противовес ему «императивный»?

Императивные и декларативные языки программирования
Императивные ЯП, к которым относится большая часть тех, которые вы знаете, с которыми вам приходилось сталкиваться, заставляют вас четко описать «как» достичь нужного результата: булочку разрезать пополам, положить на нее котлету, дальше соус, сыр, … и на выходе у вас, наверное, получится гамбургер, если вы нигде в процессе не ошиблись.
В отличие от них декларативные ЯП (которых вам, наверное, встречалось всего два, зато они общеизвестны: HTML и SQL), позволяют просто описать «что» мы хотим получить. Например, просто подъехать к окну заказа и сказать «Хочу гамбургер!» И в этот момент нас не интересует ни при какой температуре, ни сколько времени он будет готовиться, ни кто конкретно его будет готовить — вся эта информация нам неинтересна, мы просто заказываем конкретный результат.
Безусловно, у обоих подходов есть плюсы и минусы — например, императивные языки позволяют лучше оперировать машинными ресурсами на «низовом» уровне: мы можем «отрезать» себе кусочек памяти, загрузить процессор конкретной задачей, зато приходится сильно постараться, чтобы где-нибудь не проехать по «чужой» памяти или не «споткнуться» о Null Pointer Exception.
Декларативные языки, как правило, позволяют вам существенно короче описать то, что вы хотите получить. Но, к сожалению, только в той области, под которую они «заточены». Например, упоминавшийся HTML хорошо приспособлен под отображение данных (в основном, текстовых), а это означает, что все остальное на нем делать будет либо вовсе невозможно, либо очень сложно и некомфортно.
А вот SQL «заточен» под…
Управление данными

Управление операциями или данными
Большинство императивных языков программирования взаимодействуют с какими-то атомарными, «штучными» вещами: состояниями системы или событиями, которые в ней происходят.
В отличие от них, SQL работает с большими наборами данных — записей или «строк». Строки группируются в таблицы, которые, будучи связаны некоторыми отношениями между собой, образуют базу данных.
Реляционные базы
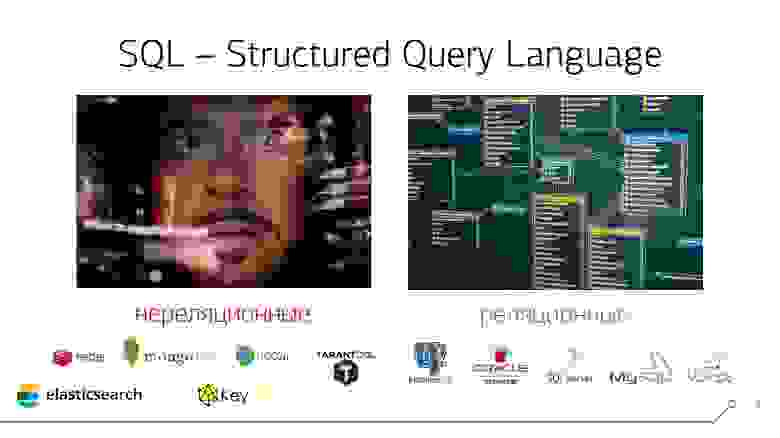
Нереляционные и реляционные СУБД
Слово «отношения» здесь ключевое, поскольку именно оно определяет, что ваша СУБД является реляционной — то есть в такой базе будут находиться связанные таблицы.
Потому что существуют достаточно много видов нереляционных СУБД, преимущество которых заключается в возможности, хоть и жертвуя универсальностью, под каждую конкретную прикладную задачу подобрать наиболее подходящий из них: Key-Value, документарные, графовые, поисковые («заточенные» под полнотекстовый или фразовый поиск) или даже мультипарадигмальные, приближающиеся по возможностям к традиционным SQL-базам.
Все эти варианты нереляционных СУБД никак не заставляют нас конкретизировать структуру хранения данных в нашей базе, и прямо рядом с ключом-числом можно положить ключ-строку или вовсе динамически заменить скалярное значение на список.
В отличие от них, в реляционных базах, структура жестко задается на моменте разработки, и ее нельзя быстро «перетряхнуть» в динамике — это достаточно сложный процесс. Безусловным стандартом работы с ними сейчас является именно SQL, универсальный по своим возможностям, его поддерживают все ведущие enterprise-СУБД.
Хотя, конечно, не обошлось и без «ложки дегтя». Как и любой язык, SQL выработал со временем определенный «диалекты», и каждая СУБД старается «отрастить» свой, чтобы сделать использование именно своих особенностей еще удобнее.
Поэтому, если у вас стоит задача писать максимально переносимый между СУБД софт, который будет все запросы формировать одинаково понятными для всех СУБД, то либо это будет очень сложным процессом, либо вы получите крайне неэффективные запросы, не использующие хоть какую-то специфику возможностей конкретной базы. То есть любой универсальный запрос на SQL будет одинаково выполняться на всех таких базах, но на всех — не настолько эффективно, насколько можно было бы сделать с учетом специфики.
Хранение данных в реляционных базах

Хранение данных в реляционных базах
Все базы нужны для того, чтобы хранить какие-то прикладные данные, и в SQL-ориентированных некоторый класс объектов — например, «документы» (бумажка с подписью), с атрибутами «номер» и «дата» — будет представлен отдельной таблицей.
Атрибуты объекта будут являться ее столбцами, экземпляры объектов — строками, а на пересечении — в поле конкретной строки — будет храниться значение данного атрибута для конкретного экземпляра (Номер = 123, Дата = 01.01.2000).
Поэтому все строки одной таблицы имеют один и тот же формат, в отличие от нереляционных баз.
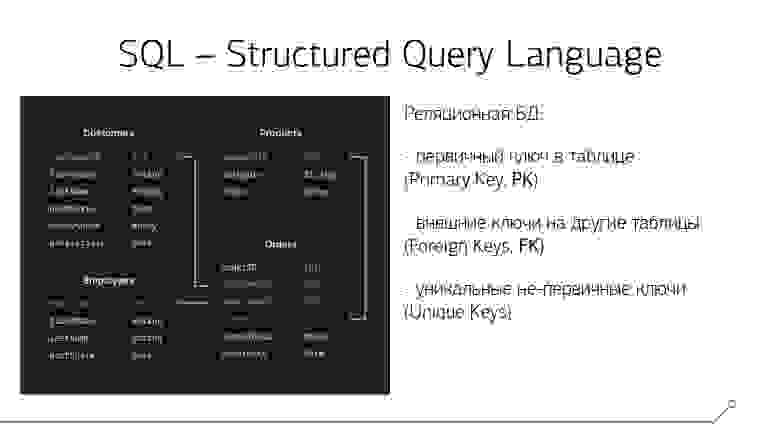
Варианты связей и ключей
Между собой таблицы связываются какими-то отношениями, которые определяются ключами.
Как правило, у любой таблицы есть первичный ключ (Primary Key, PK), и он необходим, чтобы уникально идентифицировать любую из строк этой таблицы.
Конечно, бывают ситуации, когда у вас в таблице по вполне определенным прикладными причинам может не быть первичного ключа. Например, вы пишете какую-то систему хранения логов, и запись данных в нее происходит настолько часто, что даже 1 секунда не является уникальным идентификатором — когда у вас таких событий происходит за секунду 10, вы их все пишете, а время отличить между ними никак не можете. И тогда вам или придется добавить в таблицу в качестве первичного суррогатный ключ, или вообще стоит его не делать — если отдельные записи не требуется уникально идентифицировать, а на нее никто не ссылается.
Потому что первичные ключи, классически, используются именно для того, чтобы иметь возможность сослаться на конкретную запись или провзаимодействовать с ней. А как раз чтобы «сослаться» со стороны подчиненной таблицы используются внешние ключи (Foreign Keys, FK) — они определяют по соответствию значений каких полей в дочерней и родительской таблице устанавливается связь.
В принципе, внешний ключ может ссылаться не обязательно на первичный, но и на любой уникальный ключ (Unique Key), которых на таблице, в отличие от первичного, у вас может быть несколько. Например, в таблице, куда вы записываете всех своих клиентов, первичным ключом может выступать суррогатный идентификатор, а дополнительным уникальным ключом — его ИНН.
Развитие стандарта SQL

Вехи развития стандарта SQL
Мы говорим об SQL, подразумевая, что это общепринятый стандарт, утвержденный ANSI и ISO, по которому даже разные сертификаты выдаются, ему уже 40 лет… Но, несмотря на столь почтенный, по меркам IT-технологий, возраст, это не какая-то замшелая скрижаль, на которой все давно высечено рунами.
Нет, это вполне живой организм, который активно развивается, и раз в 3–5 лет появляется новое расширение стандарта. И «бег» за поддержкой этого стандарта как раз и определяет путь развития современных СУБД.
Например, если взглянуть на стандарт 2016 года, то… работу с JSON пытались зарелизить в PostgreSQL 16, которая вышла в этом октябре, Row Level Security сделали еще в версии 15, если не раньше, в вот pattern matching только сейчас пытаются доработать для будущей версии 17, ровно как и JSON, поскольку финальный вариант патчей в v16 не вошел.
То есть на данный момент стандарт SQL по своей проработке опережает возможности реальных СУБД. Это ровно та самая разница между декларативным описанием в стандарте «как должно быть» и фактической реализацией на императивных языках «внутри» движка базы «как это должно работать».
Особенности PostgreSQL
Пока мы все говорили про SQL в целом, давайте теперь коснемся особенностей непосредственно PostgreSQL.
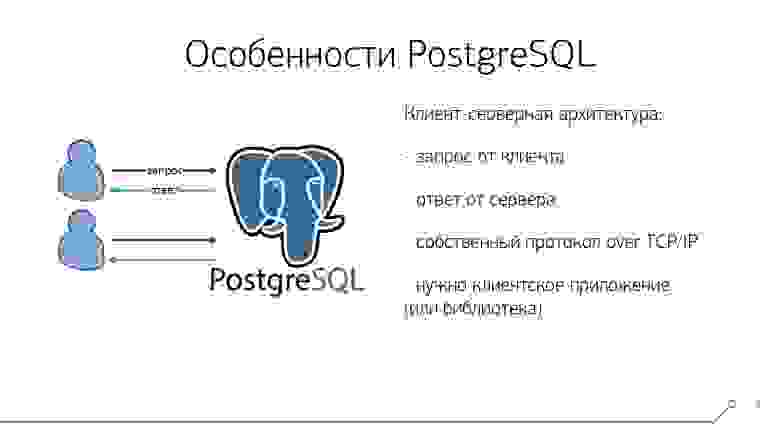
Клиент-серверная архитектура PostgreSQL
Во-первых, в отличие от некоторых других СУБД, PostgreSQL исповедует клиент-серверную архитектуру. Это означает, что у нас всегда есть некоторый клиент, который формирует запрос и по собственному протоколу «поверх» TCP/IP отправляет его серверу. Как правило, этот запрос текстовый и содержит какие-то SQL-команды. А в ответ мы получаем некоторый код результата и, возможно, выборку.
Для того, чтобы иметь возможность послать это все серверу и получить обратно, необходимо либо клиентское приложение, либо какая-то библиотека, необходимая для вашего приложения.
Общение с PostgreSQL-базой

Клиентские приложения для PostgreSQL
Если вы будете развиваться в сфере работы с PostgreSQL, то рано или поздно станете хардкорным разработчиком или админом, или DBA, вы точно будете пользоваться утилитой psql — это нативный консольный клиент, который входит в состав стандартного дистрибутива самого PostgreSQL-сервера, поэтому «есть везде».
Но пока вы не достигли таких вершин или просто не любите консоль, можете использовать любую из пары десятков GUI-утилит.

Библиотеки для PostgreSQL
Если же вам необходимо интегрировать работу с PostgreSQL в свое приложение, то вам необходимо найти подходящую к вашему языку программирования клиентскую библиотеку — их более 30 вариантов, включая экзотические в наших широтах Haskel, Erlang или Rust.
Даже офисные продукты вроде Access, Excel или даже 1C можно заставить работать как PostgreSQL-клиента, если использовать ODBC-драйвер. Так что возможности как-то повзаимодействовать с PostgreSQL ограничены исключительно вашей фантазией.
Базовые SQL-команды
Так из чего же будет состоять ваша жизнь, когда вы будете активно писать на SQL? На 99% — это будет команда SELECT:

SELECT — 99% всей работы с базой данных
А вместе все операторы, которые приведены на этом слайде, покрывают 99.9% всех типовых задач. То есть 99% — SELECT, а 0.9% — всякие CREATE, ALTER, INSERT, ... Потому что самая основная задача любой базы данных — это не столько хранение данных или их прием, сколько отдача.
Правильно попросить ее «отдать», что мы хотим, чтобы она сделала это эффективно, не перегрузилась при этом, и вернула именно те данные, которые были нам нужны — это мы и постараемся научиться делать в рамках данного курса.
Создаем демо-базу
Но, прежде чем говорить, как мы из базы что-нибудь возьмем, надо сначала эти данные в базе как-то получить.
«Чтобы продать прочитать что-нибудь ненужное, нужно сначала купить записать что-нибудь ненужное, а у нас денег базы нет.»
почти кот Матроскин, «Трое из Простоквашино»
Поэтому давайте начнем с создания простейшей базы. А для того, чтобы что-то создать в SQL, нам необходима команда CREATE — она отвечает за создание в SQL любого типа объектов:

Создаем что угодно с помощью CREATE
Но нас пока будут интересовать только две: CREATE DATABASE, чтобы создать базу, и CREATE TABLE, чтобы создать таблицу в ней:
CREATE DATABASE tst;
CREATE TABLE tbl(
k -- имя поля
integer -- тип поля
, v
text
);Полную спецификацию этих команд я приводить не буду, она доступна в документации по ссылкам выше и даже уже на русском языке, благодаря коллегам из PostgresPro.
Замечу только, что при создании таблицы нам надо заранее определить имена и типы полей — то есть формат записей, которые там будут храниться — прямо в соответствии с определением реляционной базы данных.
Базовый синтаксис
Если вдруг кто-то не догадался, то два минуса в предыдущем примере означают однострочный комментарий, прямо как «две косых» в привычных языках программирования вроде C или JavaScript, а многострочный так и вовсе выглядит точно так же.
-- это однострочный комментарий
/* а это -
- многострочный */
fld -- это поле/столбец
Fld -- это то же самое поле
FLD -- ... и это – все оно же (приводится к lower case)
"Fld" -- а вот это – тоже поле, но совсем другое (кавычки дают регистрозависимость)
'str' -- это строка
'st''r' -- это строка с одинарным апострофом
E'st\'r' -- ... и это – она же
$$st'r$$ -- ... и даже вот это
$abcd$st'r$abcd$И раз уж мы затронули тему синтаксиса, то тем, кто работал с другими СУБД некоторые вещи могут быть непривычны.
Во-первых, все поля регистронезависимы — как бы и где бы вы его не написали, оно будет приведено к нижнему регистру. Если же вам хочется указать для поля «странное» имя — например, с пробелом, по-русски, по-китайски, или просто сохранить его регистр, то указывать его надо везде в обычных двойных кавычках — никаких странностей вроде квадратных скобок или обратных апострофов.
Зато, во-вторых, обычные строковые литералы бывают как в апострофах, так и в виде эскейп-последовательностей или даже »$-quoting-string».
Базовые типы данных
При создании таблицы выше мы указывали имена полей и их типы. Какими могут быть имена, мы уже обсудили, давайте посмотрим теперь на то, какими могут быть их типы.
Все типы в PostgreSQL можно разделить на базовые (числовые, символьные, даты/времени и логический тип) и расширенные.
Числовые типы
Числовые типы в PostgreSQL определяются своей разрядностью: 2-, 4- и 8-байтные целочисленные, 4- и 8-байтовые с переменной точностью (с плавающей точкой) и numeric/decimal с указанной точностью (хранится посимвольно).
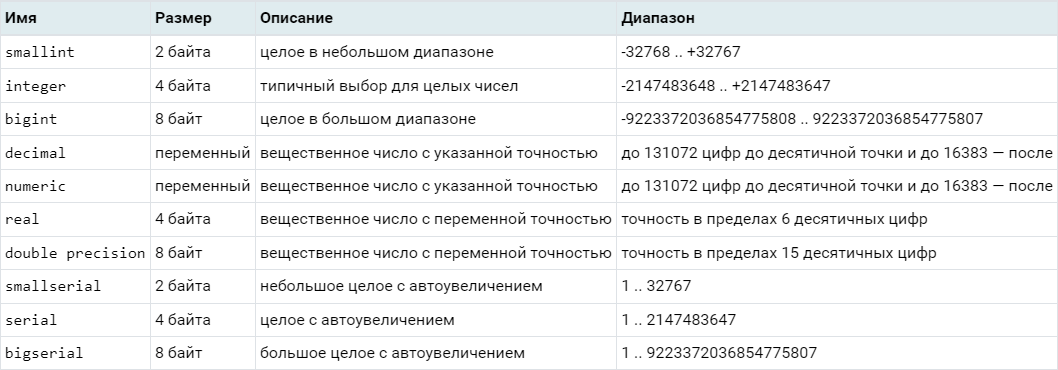
Числовые типы данных
Выбор между целочисленными типами достаточно прост: если все ожидаемые значения в пределах сотни, то не надо резервировать под них 8-байтовый bigint. Как правило, стандартного 4-байтового integer достаточно для большинства задач.
numeric стоит использовать для различных «денежных» вещей, где недопустимо «потерять копейку на округлениях»:
SELECT 3.1415926::real;
-- 3.1415925 - чуток потеряли
SELECT 3.1415926::numeric;
-- 3.1415926 - а тут все четкоЕще пара вещей может вызвать недоумение у людей с опытом программирования:
serial-псевдотипы (аналогAUTO_INCREMENT / IDENTITYиз других СУБД), которые позволяют определить поля с автоматически формируемым возрастающим значением «по умолчанию»:1, 2, 3, ...нет
unsigned— все числовые типы знаковые, поэтому «честно» положить диапазон[0x00000000..0xFFFFFFFF]вintegerне получится, только со смещением «наполовину»
Символьные типы
Символьные/строковые типы представлены парой описанных в стандарте char/varchar и парой PostgreSQL-специфичных bpchar/text.

Символьные типы
Если вы не предполагаете перенос вашего приложения на другую СУБД, то можете спокойно использовать тип text везде, поскольку указание ограничения длины не дает никаких бонусов. Конечно, за исключением случаев, когда вам действительно требуется ограничить длину записываемого в поле — например, для 2-буквенного кода страны.
Типы даты/времени
Дата и время в PostgreSQL, технически, хранятся как целочисленные, со значением от Unix Epoch (01.01.1970) в соответствующих единицах (микросекундах или сутках):

Типы даты/времени
В этом их отличие от некоторых других СУБД, где timestamp может храниться как текстовая строка.
А раз это просто числа, то арифметические операции над ними тоже допустимы:
SELECT '2024-01-01'::date - 1;
-- 2023-12-31 - за день до
SELECT '2024-01-01'::date - 8 * '1 hour'::interval;
-- 2023-12-31 16:00:00 - за 8 часов до
SELECT extract(epoch from '2024-01-01'::timestamp);
-- 1704067200 - превратили timestamp в double precision
SELECT '1970-01-01 00:00:00'::timestamp + 1704067200 * '1 second'::interval;
-- 2024-01-01 00:00:00 - ... и обратноОпционально, во временном значении можно использовать часовой пояс (with time zone) или указывать сохраняемую точность (timestamp(0) означает хранение «до секунд»).
Логический тип
Логические значения представлены типом boolean:

Логический тип
Он может принимать значения TRUE/FALSE и, с учетом SQL-специфики, значение NULL, равно как и любой другой тип.
Специальные типы данных
Помимо базовых типов, «из коробки» PostgreSQL предоставляет массу других, более специализированных, типов:
двоичные данные, перечисления, геометрические, сетевые адреса, битовые строки, вектора текстового поиска, UUID, XML, JSON, массивы, диапазоны
Например, всякие картографические сервисы любят использовать геометрические типы данных с расширением PostGIS, а слабоструктурированные данные можно хранить в JSON, причем ничуть не хуже какой-нибудь MongoDB, а идентификаторы в распределенных системах — в UUID.
Если вдруг и этих типов вам окажется мало — можно создать свой и работать с ним как с любым другим полем. Главное, правильно его описать, задать соответствующие функции ввода-вывода, хранения и обработки.
Вообще, PostgreSQL очень хорошо расширяем, поэтому EXTENSION'ы, которые для него можно найти и подключить, составляют достаточно весомую часть его преимуществ по отношению к другим СУБД.
Базовые SQL-команды (#2)
Давайте снова вернемся к нашей демо-базе и наконец добавим туда хоть какие-то данные.
INSERT
За добавление данных, за их вставку в таблицу, в SQL отвечает команда INSERT:
INSERT INTO tbl( -- куда будем вставлять данные
k -- имена полей
, v
)
VALUES -- перечисляем вставляемые строки
(1, '1st string')
, (102, 'another string')
, (3, NULL); -- вовсе не ''Мы указываем, в какую таблицу и в какие поля должны быть добавлены данные, и, в простейшей форме INSERT … VALUES, прямо перечисляем те строки, которые хотим вставить. Значения в них позиционно соответствуют указанным полям таблицы.
Да вот беда — рука у нас дрогнула, и вместо »2» у нас вставилось »102», а третья строка у нас вставилась вообще без данных в текстовое поле… Замечу, что пустая строка и NULL — совсем разные значения.
UPDATE
Давайте мы эти данные поправим. А за изменение каких-то данных в SQL отвечает команда UPDATE:
UPDATE
tbl
SET
k = k - 100 -- правила изменения значений полей
, v = '2nd string'
WHERE
k = 102; -- условие отбора строкВ ней мы указываем, в какой таблице (а таблица — это ключевой момент работы с SQL, и практически все, что придется делать, мы будем делать именно с таблицей) и как мы хотим изменить поля.
При этом полей можно менять сразу несколько. То есть если в некоторых императивных языках программирования деструкция объектов только-только занимает свое место в стандартах, то в SQL это было всегда — «у такого-то набора полей задай новые значения вот так-то».
И, дополнительно, описываем условие, которое должно отобрать только те строки, для которых наша операция должна отработать. В данном случае мы для строки с k = 102 (обратите внимание на одинарное равенство при сравнении) хотим изменить строковое значение v на новое, а из значения k вычесть 100 (присвоение точно так же описывается одинарным символом равенства).
DELETE
А последняя строка, в которую у нас «просочился» NULL вместо текстовой строки, нам вообще не нужна. Давайте ее просто удалим — для этого есть команда DELETE:
DELETE FROM
tbl
WHERE
v IS NULL;Обратите внимание, что с NULL-значениями нельзя пользоваться обычными операторами типа «равно»/«не равно», для них есть свои операторы IS. В данном случае мы используем IS NULL, чтобы проверить на совпадение с NULL-значением.
NULL-логика
Потому что базовые операторы (=, <>, NOT) выдают значение NULL, если его имеет хотя бы один из аргументов. А при приведении типов в условии оно превращается в «ложь», и ни одну запись вы не отберете.
Поэтому для сравнений NULL и с ним (в конкретном поле или для всей строки сразу) стоит использовать операторы IS/IS NOT или IS DISTINCT FROM/IS NOT DISTINCT FROM. Некоторые вещи не всегда очевидны, поэтому вот шпаргалка, которой можно пользоваться:
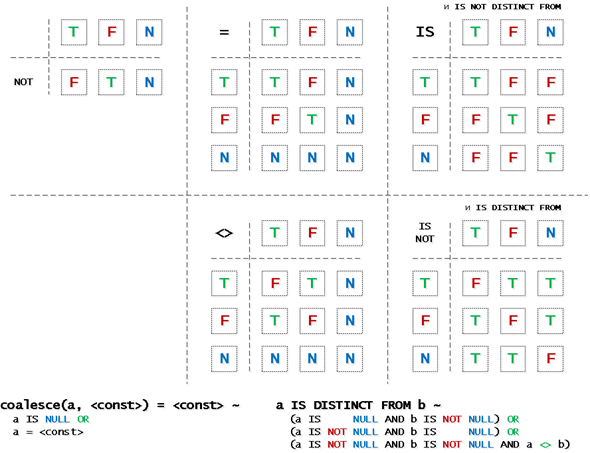
NULL-логика
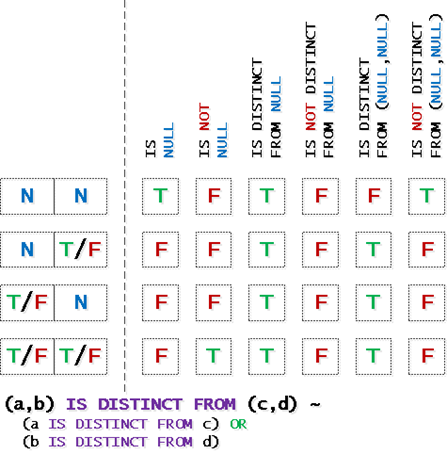
IS-операторы
… RETURNING
А что, если мы хотели не просто удалить записи, но и узнать, какие именно были удалены?…
Чтобы СУБД ответила нам не просто »я вставила/обновила/удалила две строки», а »я обработала две вот такие строки», необходимо воспользоваться ключевым словом RETURNING и перечислить те поля, которые мы хотим увидеть:
DELETE FROM
tbl
WHERE
v IS NULL
RETURNING *;В данном случае мы используем »*», которая в SQL означает «все поля». В данном случае мы увидим, что удаляется одна строка со значением 3 в поле k:
k | v
integer | text
3 |SELECT
И, наконец-то, мы можем сделать то, ради чего мы базу-то и создавали — что-то из нее взять, выбрав из нашей таблицы какие-то записи.
Для этого воспользуемся командой SELECT, про которую говорили ранее, опять же, указав »*» вместо списка полей:
SELECT
*
FROM
tbl;И мы увидим то, что осталось в таблице после всех наших манипуляций:
k | v
integer | text
1 | 1st string
2 | 2nd stringМы видим две строки, которые соответствуют тому условию, которое мы задали для выборки. Только что-то никакого условия в запросе мы при этом не видим… и это мы обсудим на следующей лекции.
А пока что вы познакомились с абсолютным минимумом, который вам будет необходим для работы с SQL в PostgreSQL — или в других SQL-ориентированных СУБД.

«Теперь, Нео, ты знаешь кунг-фу!»
А на сегодня — все!
