Kubernetes кластер за $20 в месяц
Поднимаем кластер для обслуживания веб-приложений без записи состояния (stateless web applications) вместе с ingress, letsencrypt, не используя средства автоматизации вроде kubespray, kubeadm и любых других.
Время на чтение: ~45–60 минут, на воспроизведение действий: от 3-х часов.
На написание статьи меня сподвигла потребность в своём собственном кластере kubernetes для экспериментов. Автоматические решения установки и настройки, которые есть в открытом доступе, не работали в моем случае, так как я использовал не-мейнстримовые дистрибутивы Linux. Плотная работа с kubernetes в IPONWEB стимулирует иметь такую площадку, решая свои задачи в комфортном ключе, в том числе и для домашних проектов.
В статье будут фигурировать следующие компоненты:
— Ваш любимый Linux — я использовал Gentoo (node-1: systemd / node-2: openrc), Ubuntu 18.04.1.
— Kubernetes Server — kube-apiserver, kube-controller-manager, kube-scheduler, kubelet, kube-proxy.
— Containerd + CNI Plugins (0.7.4) — для организации контейнеризации возьмем containerd + CNI вместо docker (хотя изначально вся конфигурация была поднята на docker, так что ничего не помешает использовать его в случае необходимости).
— CoreDNS — для организации service discovery компонентов, работающих внутри kubernetes кластера. Рекомендована версия не ниже 1.2.5, так как с этой версии появляется вменяемая поддержка работы coredns в качестве процесса, запущенного вне кластера.
— Flannel — для организации сетевого стека, общения подов и контейнеров между собой.
— Ваша любимая db.

- В статье не рассматривается стоимость решений vps/vds, представленных на рынке, равно как и возможность развертывания машин на этих сервисах. Предполагается, что у вас есть уже что-то развернутое, или же вы в состоянии это сделать самостоятельно. Также не освещены процессы установки/настройки вашей любимой базы данных и приватного docker репозитория, если таковой вам нужен.
- Мы можем использовать как containerd + cni plugins, так и docker. Статья не рассматривает использование docker в качестве средства контейнеризации. Если вы хотите использовать docker, вы сами сможете сконфигурировать соответствующим образом flannel, дополнительно вам понадобится настроить kubelet, а именно — удалить все опции, относящиеся к containerd. Как показали мои эксперименты, docker и containerd на разных узлах в качестве средств для контейнеризации будут работать корректно.
- Мы не можем использовать
host-gwbackend для flannel, подробнее читайте секцию Конфигурация Flannel - Мы не будем использовать ничего для мониторинга, бэкапов, сохранения пользовательских файлов (состояния), хранения файлов конфигурации и кода приложений (git/hg/svn/etc)
В ходе работы я пользовался большим количеством источников, но хочу отметить отдельно достаточно подробное руководство Kubernetes the hard way, которое освещает около 90% вопросов базовой конфигурации собственного кластера. Если вы уже ознакомились с этим руководством, можете смело переходить сразу к части Конфигурация Flannel
Список терминов / Глоссарий
- api-server — физическая или виртуальная машина, на которой располагается совокупность приложений для запуска и корректного функционирования kubernetes kube-apiserver’а. В рамках данной статьи это etcd, kube-apiserver, kube-controller-manager, kube-scheduler.
- master — выделенная рабочая станция или VPS инсталляция, синоним api-server.
- node-X — выделенная рабочая станция или VPS инсталляция,
Xуказывает порядковый номер станции. В рамках данной статьи все номера уникальны и являются ключевыми для понимания:- node-1 — машина номер 1
- node-2 — машина номер 2
- vCPU — виртуальный CPU, ядро процессора. Число соответствует количеству ядер: 1vCPU — одно ядро, 2vCPU — два, и так далее.
- user — пользователь или пользовательское пространство. При использовании
user$в инструкциях командной строки термин обозначает любую клиентскую машину. - worker — рабочий узел, на котором будут производится непосредственные вычисления, синонимично
node-X - ресурс — сущность, которой оперирует кластер kubernetes. В ресурсы kubernetes входит большое количество связанных между собой сущностей.
В процессе поднятия кластера я не ставил задачу добиться оптимизации железных ресурсов таким образом, чтобы поместиться в бюджет $20 в месяц. Нужно было просто собрать работающий кластер с как минимум двумя рабочими узлами (nodes). Поэтому изначально кластер выглядел так:
- машина с 2 vCPU / 4G RAM: api-server + node-1 [20$]
- машина с 2 vCPU / 4G RAM: node-2 [20$]
После того как первая версия кластера заработала, я решил перестроить его так, чтобы разграничить узлы, ответственные за запуск приложений внутри кластера (рабочие узлы, они же workers), и API мастер-сервера.
В результате я получил ответ на вопрос: «Как получить более-менее недорогой, но функционирующий кластер, если я хочу размещать там не самые толстые приложения».
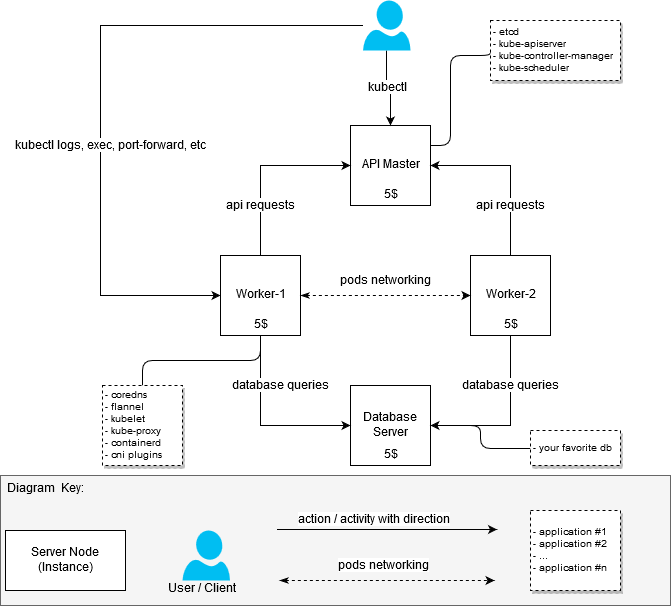
(Планируется быть таким)

(Скрадено из интернетов, если кто-то вдруг еще не знает или не видел)
Компоненты и их производительность
Первым делом стоило понять, какое количество ресурсов мне нужно, чтобы запустить программные комплексы, которые относятся непосредственно к кластеру. Поиск по запросу «hardware requirements» не дал конкретных результатов, поэтому пришлось подойти к задаче с практической точки зрения. В качестве измерения MEM и CPU я взял статистику от systemd — можно считать, что измерения производились весьма любительским способом, но задачи получения точных значений и не стояло, так как вариантов дешевле $5 за инстанс я все равно не нашёл.
Можно было найти VPS/VDS дешевле при размещении серверов на территории России или СНГ, но печальные истории, связанные с РКН и его действиями, создают определенные риски и порождают естественное желание их избежать.
Итак:
- Конфигурация мастер-сервера / серверов (Master Nodes):
- etcd (3.2.17): 80 — 100M, метрики снимались в случайно выбранное время. В среднем потребление памяти etcd не превышало 300M;
- kube-apiserver (1.12.x — 1.13.0): 237.6M ~ 300M;
- kube-controller-manager (1.12.x — 1.13.0): приблизительно 90M, выше 100M не поднималось;
- kube-scheduler (1.12.x — 1.13.0): приблизительно 20M, потребление выше 30–50M не зафиксировано.
- Конфигурация рабочих серверов (Worker Nodes):
- kubelet (1.12.3 — 1.13.1): приблизительно 35 Mb, потребление выше 50M не зафиксировано;
- kube-proxy (1.12.3 — 1.13.1): приблизительно 7.5 — 10M;
- flannel (0.10.0): приблизительно 15–20M;
- coredns (1.3.0): приблизительно 25M;
- containerd (1.2.1): потребление containerd невысоко, но в статистике отображаются также процессы контейнеров, запущенные демоном.
Нет, не нужен. Мастер-узлу не требуется docker или containerd как таковой, хотя в интернете есть большое количество руководств, которые для тех или иных нужд включают использование окружения для контейнеризации. В рассматриваемой конфигурации выключение containerd из списка зависимостей было сделано преднамеренно, однако, каких-то очевидных плюсов такого подхода я не выделяю.
Конфигурация, предоставленная выше, является минимальной и достаточной для того, чтобы запустить кластер. Никаких дополнительных действий/компонент не требуется, разве что вы захотите что-то добавить по своему усмотрению.
Для построения тестового кластера или кластера для домашних проектов будет вполне достаточно 1vCPU/1G RAM для функционирования мастер-нода. Разумеется, нагрузка на мастер-ноду будет изменяться в зависимости от количества задействованных рабочих узлов (workers), а также наличия и объема сторонних запросов к api-server.
Я разнес master и worker конфигурации следующим образом:
- 1x Master с установленными компонентами: etcd, kube-apiserver, kube-controller-manager, kube-scheduler
- 2x Workers с установленными компонентами: containerd, coredns, flannel, kubelet, kube-proxy
Для конфигурации мастера необходимо функционирование следующих компонентов:
-
etcd — для хранения данных для api-server’а, а также для flannel;
-
kube-apiserver — собственно, api-server;
-
kube-controller-manager — для генерации и обработки событий;
-
kube-scheduler — для распределения зарегистрированных через api-server ресурсов — например, подов.
Для конфигурации «рабочих лошадок» необходимо функционирование следующих компонентов: -
kubelet — для запуска подов, обеспечения конфигурирования сетевых настроек;
-
kube-proxy — для организации маршрутизации/балансировки kubernetes сервисов;
-
coredns — для service discovery внутри запущенных контейнеров;
-
flannel — для организации сетевого доступа контейнеров, работающих на разных узлах, а также для динамического распределения сетей по узлам (kubernetes node) кластера.
Тут следует сделать маленькое отступление: coredns может быть запущен и на мастер-сервере. Ограничений, которые бы заставили запускать coredns именно на рабочих узлах, нет, кроме нюанса конфигурации coredns.service, который попросту не запустится на стандартном/немодифицированном Ubuntu сервере из-за конфликта с сервисом systemd-resolved. Я и не стремился решить эту проблему, так как меня вполне устраивали 2 ns сервера, расположенные на рабочих узлах.
Чтобы сейчас не тратить времени на ознакомление со всеми деталями процесса конфигурирования компонентов, предлагаю самостоятельно ознакомиться с ними в руководстве Kubernetes the hard way. Я же сосредоточусь на отличительных особенностях моего варианта конфигурирования.
Файлы
Все файлы для функционирования компонентов кластера для мастера и рабочих узлов помещены в /var/lib/kubernetes/ для удобства. При необходимости вы можете разместить их иным образом.
Сертификаты
Основой для генерации сертификатов служит все тот же Kubernetes the hard way, существенных отличий практически нет. Для перегенерации подчиненных сертификатов были написаны простые bash скрипты вокруг cfssl приложений — это очень пригодилось в процессе отладки.
Вы можете сгенерировать сертификаты под ваши нужды, пользуясь предложенными ниже скриптами, рецептами из Kubernetes the hard way или другими подходящими инструментами.
Взять скрипты можно тут: kubernetes bootstrap. Перед запуском отредактируйте файл certs/env.sh, указав ваши настройки. Пример:
$ cd certs
#: генерируем сертификаты
certs$ ./generate-keys.sh
# ... certificate generate output
#: генерируем kubeconfig файлы на основе сертификатов
certs$ ./generate-configkube.sh
Если вы воспользовались env.sh и корректно указали все параметры, то необходимости трогать сгенерированные сертификаты нет. Если вы ошиблись на каком-то этапе, то сертификаты можно перегенерировать по частям. Приведенные bash скрипты тривиальны, разобраться в них не составит сложности.
Важное замечание — не стоит часто пересоздавать ca.pem и ca-key.pem сертификаты, так как они являются корневыми для всех последующих, иными словами, вам придется пересоздать все сопутствующие сертификаты и доставить их на все машины и во все нужные директории.
Мастер
Нужные сертификаты для запуска сервисов на мастер-узле следует положить в /var/lib/kubernetes/:
- ca.pem — этот сертификат используется везде, его можно сгенерировать всего один раз и далее использовать без изменений, — поэтому будьте аккуратны. При повторной генерации потребуется его копирование на все узлы, а также обновление использующих его kubeconfig файлов (также на всех машинах).
- ca-key.pem — то же самое, кроме копирования по узлам.
- kube-controller-manager.pem — нужен только для kube-controller-manager.
- kube-controller-manager-key.pem — нужен только для kube-controller-manager.
-
kubernetes.pem — необходим для flannel, coredns при подключении к etcd, kube-apiserver.
Теоретическое отступлениеДанная особенность выполнена по логике конфигурации Kubernetes the hard way.
Исходя из этого, данный файл нужен будет везде — и на мастере, и на рабочих узлах. Я не стал менять подход, предоставленный оригинальным руководством, так как с его помощью можно быстрее и нагляднее организовать работу кластера и понять весь ворох зависимостей.Моё личное мнение состоит в том, что для etcd нужны отдельные сертификаты, никак не пересекающиеся с сертификатами, использующимися для работы kubernetes.
- kubernetes-key.pem — остается на master серверах.
- service-account.pem — нужен только для kube-controller-manager демонов.
- service-account-key.pem — аналогично.
Рабочие узлы
- ca.pem — нужен для всех сервисов, задействованных на рабочих узлах (kubelet, kube-proxy), а также для flannel, coredns. Помимо прочего, его содержимое включается в kubeconfig файлы при их генерации с помощью kubectl.
- kubernetes-key.pem — нужен только для flannel и coredns, чтобы подключиться к etcd, который располагается на api master узле.
- kubernetes.pem — аналогично предыдущему, нужен только для flannel и coredns.
- kubelet/node-1.pem — ключ для авторизации node-1.
- kubelet/node-1-key.pem — ключ для авторизации node-1.
Важно! Если у вас больше одного узла, то каждый узел будет включать node-X-key.pem, node-X.pem и node-X.kubeconfig файлы внутри kubelet.
Отладка сертификатов
Иногда может потребоваться посмотреть, как именно сконфигурирован сертификат, чтобы узнать, какие IP/DNS узлы были использованы при его генерации. В этом нам поможет команда cfssl-certinfo -cert . Например, узнаем данную информацию для node-1.pem:
$ cfssl-certinfo -cert node-1.pem
{
"subject": {
"common_name": "system:node:node-1",
"country": "RU",
"organization": "system:nodes",
"organizational_unit": "Infrastructure Unit",
"locality": "Moscow",
"province": "Moscow",
"names": [
"RU",
"Moscow",
"Moscow",
"system:nodes",
"Infrastructure Unit",
"system:node:node-1"
]
},
"issuer": {
"common_name": "Kubernetes",
"country": "RU",
"organization": "Kubernetes",
"organizational_unit": "Infrastructure",
"locality": "Moscow",
"province": "Moscow",
"names": [
"RU",
"Moscow",
"Moscow",
"Kubernetes",
"Infrastructure",
"Kubernetes"
]
},
"serial_number": "161113741562559533299282037709313751074033027073",
"sans": [
"w40k.net",
"node-1",
"178.79.168.130",
"192.168.164.230"
],
"not_before": "2019-01-04T14:24:00Z",
"not_after": "2029-01-01T14:24:00Z",
"sigalg": "SHA256WithRSA",
"authority_key_id": "6:C8:94:67:59:55:19:82:AD:ED:6D:50:F1:89:B:8D:46:78:FD:9A",
"subject_key_id": "A1:5E:B3:3C:45:14:3D:C6:C:A:97:82:1:D5:2B:75:1A:A6:9D:B0",
"pem": ""
}
Все остальные сертификаты для kubelet и kube-proxy вшиты непосредственно в соответствующие kubeconfig’и.
kubeconfig
Все нужные kubeconfig’и можно сделать с помощью Kubernetes the hard way, однако, здесь и начинаются некоторые отличия. Руководство использует kubedns и cni bridge конфигурацию, здесь же рассматривается coredns и flannel. Эти два сервиса, в свою очередь, используют kubeconfig для авторизации в кластере.
$ cd certs
#: генерируем kubeconfig файлы на основе сертификатов
certs$ ./generate-configkube.sh
Мастер
Для мастера необходимы следующие kubeconfig файлы (как упомянуто выше, после генерации их можно взять в certs/kubeconfig):
master /var/lib/kubernetes/$ tree -L 2
.
+-- kube-controller-manager.kubeconfig
L-- kube-scheduler
L-- kube-scheduler.kubeconfig
Данные файлы потребуются для запуска каждого из компонентов-сервисов.
Рабочие узлы
Для рабочих узлов необходимы следующие kubeconfig файлы:
node-1 /var/lib/kubernetes/$ tree -L 2
.
+-- coredns
¦ L-- coredns.kubeconfig
+-- flanneld
¦ L-- flanneld.kubeconfig
+-- kubelet
¦ L-- node-1.kubeconfig
L-- kube-proxy
L-- kube-proxy.kubeconfig
Запуск сервисов
Несмотря на то, что на моих рабочих узлах используются разные системы инициализации, в примерах и в репозитории даны варианты с использованием systemd. С их помощью проще всего понять, какой процесс и с какими параметрами необходимо запустить, кроме того, они не должны вызвать больших проблем при изучении сервисов с флагами назначений.
Для запуска сервисов необходимо скопировать service-name.service в /lib/systemd/system/ или любой другой каталог, где размещаются сервисы для systemd, и после этого включить и запустить сервис. Пример для kube-apiserver:
$ systemctl enable kube-apiserver.service
$ systemctl start kube-apiserver.service
Разумеется, все сервисы должны быть зелеными (то есть запущенными и функционирующими). Если вдруг вы столкнулись с какой-либо ошибкой, команды journalct -xe или journal -f -t kube-apiserver помогут понять, что именно пошло не так.
Не торопитесь запускать все серверы сразу, для начала достаточно будет включить etcd и kube-apiserver. Если все прошло удачно, и у вас сразу заработали все четыре сервиса на мастере, запуск мастера можно считать успешным.
Мастер
Можно воспользоваться systemd настройками или сгенерировать init скрипты для конфигурации, которую вы используете. Как уже было сказано, для мастера вам необходим:
— systemd/etcd
— systemd/kube-apiserver
— systemd/kube-controller-manager
— systemd/kube-scheduler
Рабочие узлы
— systemd/containerd
— systemd/kubelet
— systemd/kube-proxy
— systemd/coredns
— systemd/flannel
Клиент
Для работы клиента достаточно скопировать certs/kubeconfig/admin.kubeconfig (после того, как вы сгенерируете его или напишете самостоятельно) в ${HOME}/.kube/config
Скачайте kubectl и проверьте работу kube-apiserver. Еще раз напомню, что на данном этапе для работы kube-apiserver должен функционировать только etcd. Остальные компоненты понадобятся для полноценной работы кластера несколько позже.
Проверяем, что kube-apiserver и kubectl работают:
$ kubectl version
Client Version: version.Info{Major:"1", Minor:"13", GitVersion:"v1.13.0", "extra info": "..."}
Server Version: version.Info{Major:"1", Minor:"13", GitVersion:"v1.13.0", "extra info": "..."}
В качестве конфигурации flannel я остановился на vxlan бэкенде. Подробнее о бэкендах можно почитать тут.
Сразу скажу, что запуск kubernetes кластера на VPS скорее всего ограничит вас в использовании host-gw бэкенда. Не являясь опытным сетевым инженером, я потратил примерно два дня на отладку, чтобы понять, в чем крылась проблема с его использованием на популярных VDS/VPS провайдерах.
Были протестированы linode.com и digitalocean. Суть проблемы заключается в том, что провайдеры не предоставляют честную L2 для частной сети (private networking). Это, в свою очередь, делает невозможным хождение сетевого трафика между узлами в такой конфигурации:
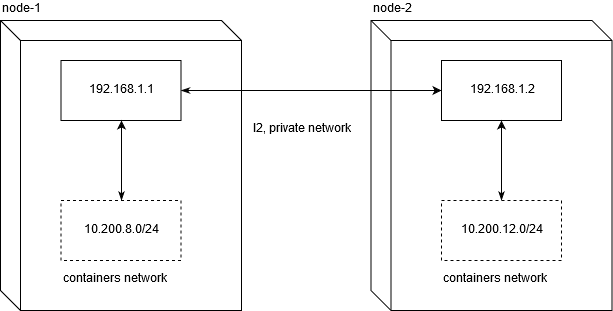
Для того чтобы работал сетевой трафик для подов между нодами, хватит обычной маршрутизации. Не забудьте, что net.ipv4.ip_forward должен быть установлен в 1, а FORWARD цепочка в filter таблице не должна содержать для узлов запрещающих правил.
node1$ ip route add 10.200.12.0/24 via 192.168.1.2
node2$ ip route add 10.200.8.0/24 via 192.168.1.1
[10.200.80.23 container-1]->[192.168.1.1 node-1]->[192.168.1.2 node-2]->[10.200.12.5 container-2]
Именно это и не работает на указаных (а, скорее всего, и вообще на всех) VPS/VDS.
Поэтому, если вам важна конфигурация решения с высокой сетевой производительностью между узлами, вам все же придется потратить больше $20 на организацию кластера.
Для установки нужной конфигурации flannel можно воспользоваться set-flannel-config.sh из etc/flannel. Важно помнить: если вы решите поменять backend, необходимо будет удалить конфигурацию в etcd и перезапустить все flannel демоны на всех узлах, — поэтому выбирайте его с умом. По умолчанию используется vxlan.
master$ export ETCDCTL_CA_FILE='/var/lib/kubernetes/ca.pem'
master$ export ETCDCTL_CERT_FILE='/var/lib/kubernetes/kubernetes.pem'
master$ export ETCDCTL_KEY_FILE='/var/lib/kubernetes/kubernetes-key.pem'
master$ export ETCDCTL_ENDPOINTS='https://127.0.0.1:2379'
master$ etcdctl ls /coreos.com/network/subnets/
/coreos.com/network/subnets/10.200.8.0-24
/coreos.com/network/subnets/10.200.12.0-24
master$ etcdctl get /coreos.com/network/subnets/10.200.8.0-24
{"PublicIP":"178.79.168.130","BackendType":"vxlan","BackendData":{"VtepMAC":"22:ca:ac:15:71:59"}}
После того как вы прописали нужную конфигурацию в etcd, необходимо настроить сервис для его запуска на каждом из рабочих узлов.
flannel.service
Пример для сервиса можно взять тут: systemd/flannel
[Unit]
Description=Flanneld overlay address etcd agent
After=network.target
[Service]
Type=notify
#: current host ip. don't change if ip have not changed
Environment=PUBLIC_IP=178.79.168.130
Environment=FLANNEL_ETCD=https://192.168.153.60:2379
ExecStart=/usr/bin/flanneld \
-etcd-endpoints=${FLANNEL_ETCD} -etcd-prefix=${FLANNEL_ETCD_KEY} \
-etcd-cafile=/var/lib/kubernetes/ca.pem \
-etcd-certfile=/var/lib/kubernetes/kubernetes.pem \
-etcd-keyfile=/var/lib/kubernetes/kubernetes-key.pem \
-etcd-prefix=/coreos.com/network \
-healthz-ip=127.0.0.1 \
-subnet-file=/run/flannel/subnet.env \
-public-ip=${PUBLIC_IP} \
-kubeconfig-file=/var/lib/kubernetes/config/kubeconfig/flanneld.kubeconfig \
$FLANNEL_OPTIONS
ExecStartPost=/usr/libexec/flannel/mk-docker-opts.sh -k DOCKER_NETWORK_OPTIONS -d /run/flannel/docker
Restart=on-failure
RestartSec=5
[Install]
RequiredBy=docker.service
Настройка
Как было описано ранее, нам необходимы ca.pem, kubernetes.pem и kubernetes-key.pem файлы для авторизации в etcd. Все остальные параметры не несут в себе какого-то сакрального смысла. Единственное, что действительно важно — это сконфигурировать глобальный ip адрес, через который будут ходить сетевые пакеты между сетями:
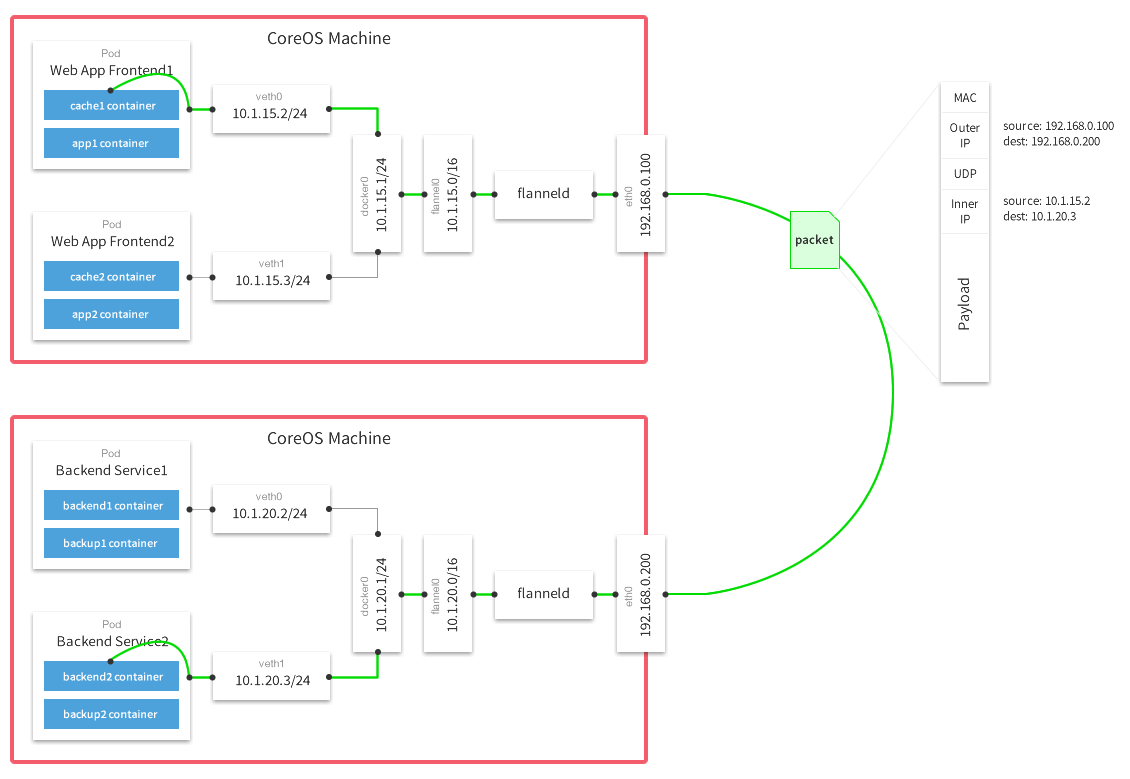
(Multi-Host Networking Overlay with Flannel)
#: включаем сервис
node-1$ systemctl enable flanneld.service
#: стартуем
node-1$ systemctl start flanneld
После успешного запуска flannel вы должны обнаружить сетевой интерфейс flannel.N в своей системе:
node-1$ ifconfig
flannel.100: flags=4163 mtu 1450
inet 10.200.8.0 netmask 255.255.255.255 broadcast 0.0.0.0
inet6 fe80::20ca:acff:fe15:7159 prefixlen 64 scopeid 0x20
ether 22:ca:ac:15:71:59 txqueuelen 0 (Ethernet)
RX packets 18853 bytes 1077085 (1.0 MiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 11856 bytes 264331154 (252.0 MiB)
TX errors 0 dropped 47 overruns 0 carrier 0 collisions 0
Проверить, что ваши интерфейсы работают корректно на всех узлах, достаточно просто. В моем случае node-1 и node-2 имеют 10.200.8.0/24 и 10.200.12.0/24 сети соответственно, поэтому обычным icmp запросом проверяем их доступность:
#: доступность node-2 с node-1
node-1 $ ping -c 1 10.200.12.0
PING 10.200.12.0 (10.200.12.0) 56(84) bytes of data.
64 bytes from 10.200.12.0: icmp_seq=1 ttl=64 time=4.58 ms
#: доступность node-1 с node-2
node-2 $ ping -c 1 10.200.8.0
PING 10.200.8.0 (10.200.8.0) 56(84) bytes of data.
64 bytes from 10.200.8.0: icmp_seq=1 ttl=64 time=1.44 ms
В случае возникновения каких-либо проблем рекомендуется проверить, нет ли каких-либо режущих правил в iptables по UDP между хостами.
Разместите etc/containerd/config.toml в /etc/containerd/config.toml или где вам удобно, главное — не забудьте поменять путь к файлу конфигурации в сервисе (containerd.service, описан ниже).
Конфигурация с некоторыми модификациями стандартной. Важно не устанавливайть enable_tls_streaming = true, если вы не понимаете, зачем вы это делаете. В противном случае kubectl exec перестанет работать и будет выдавать ошибку о том, что сертификат был подписан неизвестной стороной.
containerd.service
[Unit]
Description=containerd container runtime
Documentation=https://containerd.io
After=network.target
[Service]
; uncomment this if your overlay module are built as module
; ExecStartPre=/sbin/modprobe overlay
ExecStart=/usr/bin/containerd \
-c /etc/containerd/config.toml
Restart=always
RestartSec=5
Delegate=yes
KillMode=process
OOMScoreAdjust=-999
LimitNOFILE=1048576
LimitNPROC=infinity
LimitCORE=infinity
[Install]
WantedBy=multi-user.target
Настройка
Для проверки, работает ли сервис, можно воспользоваться cri-tools.
Скопируйте etc/crictl.yaml в /etc/crictl.yaml. После этого можно позапускать доступные команды:
node-1$ CONTAINERD_NAMESPACE=k8s.io crictl ps
CONTAINER ID IMAGE CREATED STATE NAME ATTEMPT POD ID
После того, как у вас что-то появится внутри вашего kubernetes кластера, crictl станет более полезным и начнет отображать поды, контейнеры, образы и так далее.
Про CNI уже писали на Хабре, поэтому просто сошлюсь на подходящую статью по теме и, не вдаваясь в подробности, перейду к делу.
Для каждого из рабочих узлов скачиваем cni plugins для нужной нам платформы и распаковываем в /opt/cni/bin/
в /etc/cni/net.d кладем следующие файлы с указанным содержанием:
{
"cniVersion": "0.3.0",
"name": "cbr0",
"plugins": [
{
"type": "flannel",
"name": "kubenet",
"delegate": {
"hairpinMode": true,
"isDefaultGateway": true
}
},
{
"type": "portmap",
"capabilities": {
"portMappings": true
},
"externalSetMarkChain": "KUBE-MARK-MASQ"
}
]
}
{
"cniVersion": "0.3.0",
"type": "loopback"
}
Описания проверки этого сетапа перегрузит эту статью, поэтому его я пропущу. Но тем, кто привык рисковать и не боится сложностей, советую к прочтению Red Hat заменяет Docker на Podman, Intro to Podman
Самое важное в установке kubelet сервиса (помимо указания корректных ключей и cni) — корректно указать имя узла. По умолчанию kubelet возьмет значение из hostname. Так как большое количество запросов идет через шифрование сертификатами, то некорректное имя узла может «поломать» вам команды kubectl logs, kubectl exec, kubectl port-forward.
Перед тем, как скопировать etc/kubelet-config.yaml в нужное место, необходимо отредактировать его в соответствии с вашими настройками, как и все конфигурационные файлы. Ниже я отмечу данные опции:
systemReserved:
cpu: 200m
memory: 600Mi
К сожалению, о них можно прочитать только в декларация GO файлов kubernetes, поэтому гуглите, исходя из собственного опыта и желания разобраться. Конкретно эти опции отвечают за резервирование системных ресурсов. При такой конфигурации из ресурсов вашего реального кластера будет зарезервировано 0.2 vCPU и 600 MB памяти для использования хостовой системой.
Это могут быть, к примеру, kubelet, kube-proxy, coredns, flannel или другие системные процессы. Разумеется, данные настройки не являются универсальными и указаны в соответствии с конфигурацией моих рабочих узлов — в моём случае это 2 vCPU / 4G ram, плюс на обоих узлах у меня все еще крутятся старые проекты, которые не переведены в kubernetes + postgresql сервера.
В случае использования микро-узлов (micro nodes) я бы вообще удалил данную часть конфигурационного файла.
kubelet.service
Пример service файла можно взять тут: systemd/kubelet
[Unit]
Description=Kubernetes Kubelet
Documentation=https://github.com/kubernetes/kubernetes
Requires=containerd.service
[Service]
#Environment=NODE_IP=192.168.164.230
Environment=NODE_IP=178.79.168.130
#: node name given by env
Environment=NODE_NAME=w40k.net
ExecStart=kubelet \
--allow-privileged \
--root-dir=/var/lib/kubernetes/kubelet \
--config=/var/lib/kubernetes/kubelet/kubelet-config.yaml \
--kubeconfig=/var/lib/kubernetes/kubelet/node-1.kubeconfig \
--cni-bin-dir=/opt/cni/bin \
--cni-conf-dir=/etc/cni/net.d/ \
--network-plugin=cni \
--container-runtime=remote \
--container-runtime-endpoint=unix:///var/run/containerd/containerd.sock \
--image-pull-progress-deadline=10m \
--node-ip=${NODE_IP} \
--hostname-override=${NODE_NAME} \
--v=1
Restart=on-failure
RestartSec=5
[Install]
WantedBy=multi-user.target
Настройка
Я не уделял особенного внимания сущностям, которые обслуживают RBAC, поэтому в текущей конфигурации требуется выделение прав для корректного функционирования каждого из узлов под управлением kubelet.
Примените etc/kubelet-default-rbac.yaml для того, чтобы kubelet имел необходимые права для манипулирования ресурсами на узле:
user$ kubectl apply -f etc/kubelet-default-rbac.yaml
После того, как ресурсы были созданы, можно приступить к конфигурации и запуску самого сервиса.
#: включаем сервис
node-1$ systemctl enable kubelet.service
#: стартуем
node-1$ systemctl start kubelet
Если все прошло успешно, то вы должны как минимум увидеть узел через запрос узлов api сервера:
$ kubectl get nodes -o wide
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
w40k.net Ready 5m v1.13.1 178.79.168.130 Gentoo/Linux 4.18.16-x86_64-linode118 containerd://1.2.1
Сервис: systemd/kubelet. Тут все просто, особой магии нет, kube-proxy-config.yaml можно взять опять же тут: etc/kube-proxy
kube-proxy.service
[Unit]
Description=Kubernetes Proxy
Documentation=https://github.com/kubernetes/kubernetes
After=network.target
[Service]
ExecStart=kube-proxy \
--config=/var/lib/kubernetes/kube-proxy/kube-proxy-config.yaml
Restart=on-failure
RestartSec=5
[Install]
WantedBy=multi-user.target
Настройка
#: включаем сервис
node-1$ systemctl enable kube-proxy.service
#: стартуем
node-1$ systemctl start kube-proxy
Так как kube-proxy отвечает за «проделываение» маршрутов внутири iptables, то проверить его работу можно будет только после того, как вы что-то запустите внутри kubernetes кластера (какой-нибудь сервис). Об этом ниже.
Corefile можно взять тут: etc/coredns/Corefile, выглядит он следующим образом:
.:53 {
errors
log stdout
health :8081
kubernetes cluster.local 10.200.0.0/16 {
endpoint https://178.79.148.185:6443
tls /var/lib/kubernetes/kubernetes.pem /var/lib/kubernetes/kubernetes-key.pem /var/lib/kubernetes/ca.pem
pods verified
upstream /etc/resolv.conf
kubeconfig /var/lib/kubernetes/config/kubeconfig/coredns.kubeconfig default
}
proxy . /etc/resolv.conf
cache 30
}
Вам необходимо будет скопировать coredns.kubeconfig и pem-сертификаты (процесс их генерации описан выше) на все worker узлы. Вдобавок, coredns сервис я запускал без работающего systemd-resolved. Поэтому, если вы захотите запустить данный конфиг на стоковом Ubuntu сервере, то он, скорее всего, не заработает, как нужно. Но исправить его не так уж и сложно.
coredns.service
[Unit]
Description=CoreDNS
Documentation=https://coredns.io/
After=network.target
[Service]
ExecStart=/usr/bin/coredns -conf /etc/coredns/Corefile
Restart=on-failure
RestartSec=5
[Install]
WantedBy=multi-user.target
Настройка
#: включаем сервис
node-1$ systemctl enable coredns.service
#: стартуем
node-1$ systemctl start coredns
Проверить, что все ок, можно следующим образом:
node-1$ dig kubernetes.default.svc.cluster.local @127.0.0.1
#: вывод чуток порезан
;kubernetes.default.svc.cluster.local. IN A
;; ANSWER SECTION:
kubernetes.default.svc.cluster.local. 5 IN A 10.32.0.1
Как мы видим, coredns вернул нам ip адрес стандартного kubernetes сервиса.
Важно, kubernetes.default сервис будет зарегистрирован работающим kube-controller-manager, поэтому стоит убедиться в его наличии:
$ kubectl get svc -n default
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.32.0.1 443/TCP 26h
Чтобы запустить приложение, необходимо определить его ресурсы. А перед этим следует сконфигурировать и установить nginx-ingress и cert-manager.
— nginx kubernetes ingress (master), минимальный сетап:
user$ git clone https://github.com/nginxinc/kubernetes-ingress.git
user$ cd kubernetes-ingress/deployments
user$ kubectl apply -f common/ns-and-sa.yaml
user$ kubectl apply -f common/nginx-config.yaml
user$ kubectl apply -f common/default-server-secret.yaml
user$ kubectl apply -f daemon-set/nginx-ingress.yaml
user$ kubectl apply -f rbac/rbac.yaml
— cert manager (v0.5.2)
user$ git clone https://github.com/jetstack/cert-manager.git
user$ cd cert-manager && git co v0.5.2
user$ cd contrib/manifests/cert-manager
user$ kubectl apply -f with-rbac.yaml
После того, как все успешно запустилось, стоит проверить, работают ли процессы приложения:
NAMESPACE NAME READY STATUS RESTARTS AGE
cert-manager cert-manager-554c76fbb7-t9762 1/1 Running 0 3h38m
nginx-ingress nginx-ingress-sdztf 1/1 Running 0 10h
nginx-ingress nginx-ingress-vrf85 1/1 Running 0 10h
Если cert-manager и nginx-ingress поды находятся в running state, то можно считать, что все успешно запустилось. В ходе различных экспериментов с кластерами приложения могут перестать работать, при этом состояние пода будет продолжать определяться как Running. Обычно в таких ситуациях помогает только исследование логов пода и рестарт подов.
Чтобы протестировать конфигурацию, можно воспользоваться уже написанным приложением. Исходники лежат в том же репозитории, вместе с kubernetes resource конфигурацией: app/k8s
user$ kube apply -f ns-and-sa.yaml
user$ kube apply -f configmap.yaml
#: отредактируйте secret-example.yaml с нужными секретами и сохраните как
#: secret.yaml
user$ kube apply -f secret.yaml
user$ kube apply -f tls-production.yaml
user$ kube apply -f deployment.yaml
user$ kube apply -f service.yaml
user$ kube apply -f ingress-production.yaml
Следует обратить внимание, что генерация сертификата займет какое-то время. Также важно, чтобы доменное имя (в случае с данным примером это kubernetes-example.w40k.net), для которого вы генерируете сертификат, существовало и было доступно, иначе cert-manager в связке с nginx-ingress не смогут принять участвие в выпуске сертификата и вы не сможете использовать текущую конфигурацию. Тем не менее, вы можете использовать ingress без tls/ssl.
Данное приложение в указанной конфигурации создаёт:
- http://no-https.kubernetes-example.w40k.net/ — без ssl; в случае, если что-то пошло не так, можно проверить состояние работы приложения.
- https://kubernetes-example.w40k.net/ — если заработало (разумеется, не данный хост, а указанный вами), то считайте, что вся полезная нагрузка выполнена, и у вас есть свой небольшой kubernetes кластер за вменяемую ежемесячную плату.
На текущий момент это вся полезная информация, необходимая для первичной настройки функционирующих мастер- и рабочих узлов. Если у вас что-то не заработало или заработало не до конца, ниже представлена краткая сопроводительная информация, которая поможет в отладке и подгонке компонентов кластера.
Информация, которую я использовал для того, чтобы настроить кластер:
— Kubernetes the hard way
— Multi-Host Networking Overlay with Flannel
— Intro to Podman
— Stateless Applications
— What is ingress
Полезно к прочтению:
— Kubernetes Networking: Behind the scenes (перевод)
— A Guide to the Kubernetes Networking Model
— Understanding kubernetes networking: services (перевод)
Данная секция к прочтению необязательна, особенно, если у вас все работает. Здесь собраны краткие инструкции, куда смотреть и как действовать в ситуации, если что-то не работает, или работает не так, как ожидается.
Api Server
В конфигурации kube-apiserver.service может указываться статический токен, который используется для упрощения отладки работы api-server’а с помощью curl или любого другого http клиента. При его использовании в целях безопасности лучше изменить значение токена на что-то уникальное.
После завершения отладки скопируйте admin.kubeconfig в ${HOME}/.kube/config, и тогда kubectl будет работать без авторизации на api-server (kube-apiserver).
Если данный запрос (замените токен на свой) возвращает HTTP 200 OK + содержимое, то api-server функционирует корректно:
curl -H "Authorization: Bearer e5qXNAtwwCHUUwyLilZmAoFPozrQwUpw" -k -L https://:6443/api/v1/
Kube Controller Manager
После того, как controller manager соединится с api сервером и начнет работать, он произведет некоторый набор стандартных действий. Для проверки результата достаточно будет убедиться в том, что были созданы service account’ы:
$ kubectl get sa
NAME SECRETS AGE
default 1 19h
Если этот список пуст, убедитесь в том, что kube-controller-manager функционирует корректно.
Kube Scheduler
Планировщик отвечает за распределение ресурсов по узлам. Чтобы убедиться, что он работает правильно, можно запустить тестовый debug/job.yaml и просмотреть список событий с помощью команды kubectl describe .
Перед отладкой планировщика важно убедиться в том, что kube controller manager функционирует.
#: регистрируем ресурс job
user$ kubectl apply -f debug/job.yaml
job.batch/app created
#: смотрим поды, ассоциированные с job
user$ kubectl get pods -l job-name=app
NAME READY STATUS RESTARTS AGE
app-9kr9z 0/1 Completed 0 54s
#: смотрим, какие события были зарегистрированы и обработаны для
#: указанного пода
user$ kubectl describe pods app-9kr9z
# ... вырезанный контент ...
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 12s default-sch
