Kubernetes: как выбрать между self-hosted и managed-решением
Привет, Хабр! Сергей Бондарев, архитектор Southbridge и спикер в Слёрме, недавно провёл вебинар «Kubernetes'22: выбор между self-hosted и managed-решением». Сегодня публикуем текстовую версию вебинара.
Для наглядности сравним self-hosted и managed-решения по двум аспектам:
Трудозатраты и компетенции специалистов.
Железо и инфраструктура.
Специалисты
Для поддержания кластера Kubernetes, не важно — собственного или арендованного, понадобятся люди с определёнными компетенциями.
Self-hosted
Инфраструктурная команда. Люди, которые будут заниматься железом, сетью и дата-центром. Они есть в компании, когда вы держите свои собственные сервера или даже целый дата-центр. Но чаще всего сейчас компании арендуют сами серверы, а за железо отвечает хостер. В таком случае нужно заниматься только мониторингом серверов и заказом новых в случае необходимости. Отдельная команда для этого не нужна — справятся и обычные администраторы.
Администраторы Kubernetes. Собственно те, кто работают с кластером: разворачивают его, настраивают, обслуживают, расширяют и мониторят нагрузку. Именно им можно поручить инфраструктуру, которая держится на арендованных серверах.
Также они будут интегрировать кластер с внешними сервисами, например, системами хранения данных или балансировщиками нагрузки. И следить, чтобы работал централизованный сбор логов, системы бэкапов, системы мониторинга, CNI, CSI, DNS и сontrol plane.
Команда автоматизации. Эти ребята занимаются DevOps — помогают разработчикам деплоить приложения в Kubernetes, настраивают CI/CD, совместно с командой администраторов k8s не допускают деплоя манифестов, которые могут привести к проблемам. Например, деплойментов, у которых количество реплик подов равно единице и которые совершенно не отказоустойчивы.
Managed
Команда по работе с облаком. Команда инфраструктурщиков есть у хостера — именно они обеспечивают работоспособность «железа». Но в компании нужны люди, которые понимают, как облако работает и как с ним обращаться. Без них не обойтись, пускай большинство облаков и говорят, что они простые и дружелюбные с пользователями. Это поможет избежать ситуаций, когда вам в конце месяца приходит счет на десяток тысяч у.е. за мощности, которые вы случайно заказали и не использовали.
Администраторы Kubernetes. Да, устанавливать Kubernetes, настраивать его и масштабировать не понадобится. Но задачи по поддержанию мониторинга, сбору логов, валидации манифестов и пресеканию неправильных деплоев остаются. Их будет меньше, чем на собственных серверах, но команда по автоматизации с ними не справится — понадобятся отдельные люди.
Команда автоматизации. DevOps вам нужен в любом случае, и облачный провайдер его не обеспечит.
Если вы не маленький стартап, который пилит MVP, а нормальный продакшн, то разница будет только в областях знаний. Команды понадобятся плюс-минус одинаковые, но в первом случае нужны будут администраторы-железячники, а во втором — облачные инженеры. Что будет дороже — зависит от ситуации на рынке.
Железо и инфраструктура
Self-hosted
В первую очередь нам понадобятся обычные железные серверы с Linux, объединённые в локалку. Но есть проблема — мощность одного такого сервера избыточна для узла Kubernetes. На узле по умолчанию мы запускаем 110 подов, в поде 2 (редко 3–4) контейнера, каждый под — отдельный микросервис. В итоге у нас на 12-ядерный 128-гиговый сервер всего 110 микросервисов, которые не могут его утилизировать на 100%.
В качестве решения обычно разбивают один железный сервер на несколько KVM-виртуалок. В итоге есть узлы, где работают какие-то тяжелые приложения вроде Legacy Java — им отдан целый сервер. А для небольших выделяется один узел на KVM, часть большого сервера.
Такую систему можно создать на собственном железе либо в облаке. Облако здесь не managed Kubernetes, а только серверы. Посмотрим, какие плюсы и минусы есть у каждого решения.
На своем железе
Плюсы:
Локальные диски намного быстрее любого сетевого хранилища.
Аренда (и даже покупка) серверов обойдется дешевле, чем managed-решение в облаке.
Минусы:
Железо нужно иногда обслуживать и чинить: заменять системы охлаждения, патч-корды и диски. Для этого нужны люди и отдельный бюджет на запчасти.
Чтобы добавить новый узел, нужно заказать сервер, привезти, разместить в стойке, провести первичные настройки.
Если вашему приложению нужны persistent volumes, потребуются отдельные системы хранения данных, которые можно подключить к любому узлу.
Нужно поднимать отказоустойчивый балансировщик с резервированием IP-адресов.
В облаке
Плюсы:
У большинства облачных провайдеров сейчас есть услуга локального SSD. Когда всё запускают не на внешнем сетевом диске, а прямо на диске внутри гипервизора. Так теряется возможность миграции виртуалки с одного гипервизора на другой, зато появляется скорость, как на железных серверах.
Облачные диски можно использовать как систему хранения данных, всё настроено и работает.
Для добавления новых узлов можно в любой момент нарезать новую виртуалку, не нужно ничего докупать и настраивать.
Облачный балансировщик нагрузки, в котором о резервировании уже позаботились.
Минусы:
Интеграцию нашего кластера Kubernetes с облаком все равно придётся настраивать самостоятельно: читать документацию, создавать пользователей с нужными правами в облаке, прописывать ключи пользователей в драйвера CSI, запускать и настраивать Cloud controller, чтобы можно было создавать балансировщики.
На мой взгляд, виртуалки в облаке выглядят немного предпочтительнее, чем железные серверы. По скорости локальных дисков у нас паритет, а по настройке и работе с СХД облако определённо выигрывает — ничего не нужно реализовывать самостоятельно.
Managed
Здесь у нас кластер работает под управлением хостера. И существует три варианта:
Нормальный, когда control plane работает снаружи облака, и мы его не видим. Всем занимается хостер: настраивает, обслуживает, следит за работоспособностью.
Странный, когда всё managed-решение состоит из кнопки в веб-интерфейсе, где мы задаём количество и размеры узлов, чтобы через 10 минут получить кластер. А control plane запущен на точно такой же виртуалке, и мы сами должны им управлять.
Усреднённый. Например, когда control plane в облаке, но есть зачатки автоматизации. Или когда нам control plane вообще недоступен, но и автоматизации минимум. Тут всё зависит от хостера.
Приведу пример. Два года назад мы смотрели managed-решения от Selectel. У них был вариант с control plane в облаке. По сути это была автоматизация запуска Kubernetes с интеграцией СХД, но control plane запускали в том же облаке, и им никто не управлял. А недавно я снова изучал предложение Selectel и увидел, что они полностью переделали предлагаемое managed-решение к нормальному варианту. Control plane скрыт от пользователя, а за рабочими узлами следит watchdog и, если рабочий узел перестаёт отвечать, он убивается и автоматически поднимается новый.
Перейдём к особенностям managed-решений и отличиям от собственноручно поднятого кластера Kubernetes.
Сначала поговорим о плюсах:
Простая установка. Мы говорим: «Хочу 2 группы узлов. Одну на spot-серверах, вторую с автоскейлингом, размером 4 ядра, 16 памяти. Включите мне сразу PSP или ещё какие-то доп. настройки». Всё это достаточно натыкать мышкой в графическом интерфейсе или задать в Terraform — и кластер появляется.
Облачные диски как СХД. Можно подключать системы хранения к узлам как persistent volume. Правда есть ограничения — в зависимости от облака это может быть не больше 16 или 64 дисков на узел.
Быстрое добавление узлов. Выросла нагрузка — можно заказать себе еще десяток виртуалок. Причем легко настроить, чтобы автоскейлер это делал автоматически.
Облачный балансировщик. Мы просто говорим: «Хотим получать запрос из интернета. Облако, сделай балансировщик и поклянись, что он будет отказоустойчивым». И не нужно думать, использовать Cloudflare или как-то перекидывать IP между своими виртуалками.
Интеграция с облаком уже готова. Есть все Storage class, можно быстро подключить нужный диск к любому узлу.
Автовосстановление. Не просто узлов, которые были убиты, но и системных штук, которые невозможно спрятать в сontrol plane. Например, это настройки Calico: уровень логов, debug и прочее. Система автовосстановления раз в минуту может пушить в кластер оригинальные манифесты, чтобы случайно не сломать CNI, CSI, kube proxy и прочие компоненты, к которым есть доступ.
Теперь перейдем к минусам:
Техподдержка рассчитана на массового пользователя. Первая линия часто не обладает большим техническим бэкграундом и может сказать только: «Пожалуйста, проверьте, правильно ли вы деплоите». Нужно ещё убедить их, что проблема не у вас, а в облаке, и ждать, пока попадёте на вторую линию. Плюс иногда ответа на тикеты ждать приходится несколько недель.
Усреднённые настройки. Нет тонкого тюнинга под ваш профиль нагрузки, из-за чего приходится переплачивать за мощности.
Явные и неявные ограничения. Часто есть ресурсные квоты, но их можно попросить увеличить. А есть «секретики» — например, может быть доступно только 50 тысяч сетевых соединений на одну виртуалку. Большинству этого хватает, но в Kubernetes много DNS-запросов по UDP, и вы запросто выжрете эти 50 тысяч соединений. Это легко починить с помощью NodeLocal DNS, но нужно знать о том, что подобное может произойти. А указана информация про 50 тысяч соединений мелким шрифтом в дальнем углу документации. И это только пример — таких неявных ограничений может быть много.
Сложная инфраструктура облака. Облако поддерживают люди, и они бывают разные. Сверху могут прийти какие-то изменений или проблемы, и пока их решают — ваше приложение будет страдать. А повлиять на это вы не сможете.
Упрощённое автовосстановление. Мы не можем тонко настроить вещи, которые нам недоступны. Например, была ситуация с логами Calico. У нас был кластер разработчиков, которые раз в пять минут выкатывали новые микросервисы. В итоге появлялись десятки новых подов, и поды Calico достаточно сильно нагружали процессоры на узлах, тщательно записывая все свои действия в логи, со включенным дебагом. А потом это всё ещё и передавалось в Elasticsearch. Получалось, что Elastic распухал, хранил никому не нужные дебаг-логи и тратил процессорное время и диски на бесполезную работу. А техподдержка отвечала, что возможности исправить это нет — только отключать автовосстановление полностью.
Что в итоге
Managed — отличное решение для малонагруженных проектов. Создать облако, чтобы проверить концепцию — идеально, потому что можно не заморачиваться с технической инфраструктурой и уйти с головой в задачи деплоя.
Нагруженный продакшн — уже другая история. В случае с Managed вам потребуется очень быстрая реакция от техподдержки, и у многих провайдеров за это нужно доплачивать. Это уже чем-то напоминает аутсорс — вы нанимаете у провайдера команду, и она решает проблемы. Вот только в облаке эта команда может быть вовлечена в проблемы других пользователей, и может быть разумнее взять её не у провайдера, а на стороне. И решать для себя, готовы вы к недостаткам managed-облака или всё-таки развернёте собственный Kubernetes сами для более тонкой настройки.
На что обратить внимание в managed-решениях: очевидное, но важное
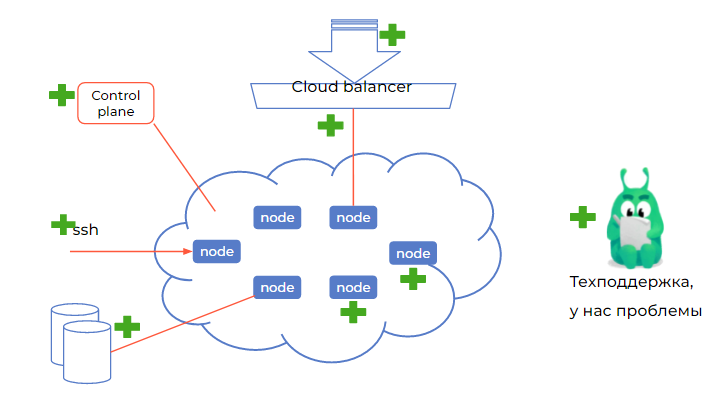 Общая инфраструктура системы обычно выглядит так
Общая инфраструктура системы обычно выглядит так
Обязательное
Control plane под управлением хостера. Именно хостер должен отвечать за его работоспособность и иметь системы автоматического восстановления. Если видите сontrol plane внутри своего облака, провайдера можно сразу менять.
Интеграция с облаком как с СХД. Это есть почти везде, но лучше проверить, что вы можете подключать облачные диски в качестве persistent volume в свой кластер.
Рабочий облачный балансировщик. Во-первых, он должен быть. Во-вторых, должны создаваться балансировщики для сервисов типа load balancer. Лучше, если ими можно управлять, например, задавать через аннотацию внешний IP. Чтобы при случайном отключении сервиса типа load balancer потом создавать его с тем же IP-адресом и не менять адреса в ваших DNS-зонах.
Доступ на узлы по SSH. Обычно managed-решения сосредоточены на работе сontrol plane. Поэтому вам нужен прямой доступ на узлы, чтобы не просто их убивать и создавать заново, а решать проблемы с неправильными лимитами и съеденной памятью. Без доступа вы сможете просто видеть в веб-интерфейсе, что узел «красненький» и с ним что-то не так, но исправить что-то будет не в ваших силах.
Устойчивость к нагрузкам. Чтобы это проверить, можно создать два–три десятка неймспейсов, на каждом параллельно задеплоить своё приложение и сымитировать внешний трафик. Так вы поймете, справится ли кластер с пиковыми нагрузками и узнаете, откуда ждать проблем — от вашего приложения или от managed-кластера.
Работа техподдержки. В процессе всех этих тестов вам наверняка понадобится техподдержка. Это отличный повод проверить, как она работает и правильно ли отвечает. Например, они могут начать вас спрашивать, а как именно вы используете балансировщик, какой у него IP, какой ID у ваших кластеров. А могут всё посмотреть сами, что, конечно, лучше.
Работа автоскейлинга кластера. Для его проверки набейте кластер подами с реквестами, чтобы не осталось свободного места. И посмотрите, появятся ли новые узлы. Потом удалите ненужные поды и посмотрите, удалятся ли добавленные узлы. Потому что иногда автоскейлинг работает только в одну сторону — создаёт, но не удаляет. И после падения нагрузки ненужные узлы продолжают тянуть из вас деньги.
Не обязательное, но полезное
Возможность мониторинга через веб-интерфейс. Чтобы можно было смотреть загрузку ядра и памяти, а в идеале — дисков. Просматривать манифесты, особенно если вы не очень хорошо пользуетесь утилитой kubectl. В общем, наглядно видеть состояние кластеров, узлов и control plane.
Собственный прокси. Proxy registry для Docker хаба — очень удобная штука. Часто managed-решения со всех 20 узлов выходят наружу через 1 IP-адрес. И набрать 100 пулов за шесть часов очень легко. Proxy исправит эту ситуацию.
Свежие версии кластеров. Как-то я видел решение, у которого самый свежий кластер был версии 1.19. А уже существует 1.23, 1.19 даже выведена из обслуживания.
Контейнер runtime-интерфейса. Это должен быть containerd или CRI-O — никаких Docker.
Доступ к API Kubernetes снаружи. Не только через системы идентификации провайдеров, но и на всякий случай через токен сервис-аккаунтов. Иначе, если у хостера сломается система идентификации, вы просто не попадёте в свой кластер.
Ограничение по IP-адресам. Как правило, managed-решения весь интерфейс, на котором слушают API Kubernetes, выставляют наружу, в интернет. И любой злоумышленник может попробовать этот кластер взломать — в Kubernetes уже находили дыры, которые позволяли отправлять в открытый API специальные запросы и получать доступ. Так что лучше, если у провайдера есть возможность составить белый список IP.
Ответ на главный вопрос: что же выбрать
Как мы и говорили в начале, универсального ответа на этот вопрос нет — решать всё-таки придётся самостоятельно. Но если у вас небольшой бизнес, низкие нагрузки и нет отдельной команды для Kubernetes — можно выбирать managed-решение. Так вы сосредоточитесь на деплое, и всё будет хорошо.
Как только подрастёте, нагрузки станут высокими и вместо трёх микросервисов у вас будет три десятка, можно будет набрать специалистов и построить своё self-hosted решение, настроенное точно под вас.
