Кто победит: средненагруженный Kubernetes или простой list-запрос?
В статье мы расскажем, как столкнулись со множественными запросами к API-серверу Kubernetes от одного из приложений, к чему это привело и каким образом проблема была решена.

Предыстория
Вечер обещал быть томным. Однако в очередной раз перезагрузив kube-apiserver, мы получили практически троекратный рост потребления памяти etcd. Взрывной рост приводил к каскадной перезагрузке всех master-узлов. Оставлять production клиента в такой опасности было нельзя.

График 1.1. Общее потребление памяти на master-узле в момент проблемы.
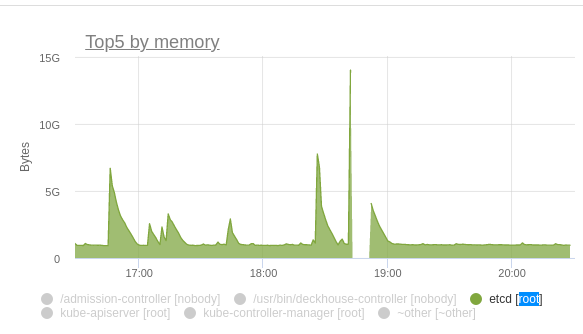
График 1.2. Потребление памяти etcd.
Изучив audit-логи, мы поняли, что виноват один из наших DaemonSet«ов, Pod«ы которого при перезагрузке kube-apiserver начинали заново слать в него list-запросы, чтобы наполнить свои кэши объектами (стандартное поведение для infromer«ов из Kubernetes client-go).
Масштаб проблемы был следующим: каждый Pod при старте делал 60 list-запросов, а всего узлов в кластере было ~80.
Разбираемся с etcd

Запрос, который отправляли Pod«ы нашего приложения выглядел так:
/api/v1/pods?fieldSelector=spec.nodeName=$NODE_NAMEИли, по-русски, «покажи мне все Pod«ы, которые находятся со мной на одном узле». В нашем понимании количество вернувшихся объектов не должно превышать 110, но с точки зрения etcd это не совсем так.
{
"level": "warn",
"ts": "2023-03-23T16:52:48.646Z",
"caller": "etcdserver/util.go:166",
"msg": "apply request took too long",
"took": "130.768157ms",
"expected-duration": "100ms",
"prefix": "read-only range ",
"request": "key:\"/registry/pods/\" range_end:\"/registry/pods0\" ",
"response": "range_response_count:7130 size:13313287"
}Выше видно, что range_response_count равен 7130. Но мы же просили 110! Почему так? Дело в том, что etcd — очень простая база, которая хранит все данные в формате »ключ: значение». При этом все ключи формируются по шаблону /registry/. Ни про какие field— и label-селекторы база не знает. Следовательно, чтобы вернуть наши 110 Pod«ов, kube-apiserver должен достать из etcd все (!) Pod«ы.
В этот момент стало понятно: несмотря на эффективные запросы к kube-apiserver, приложения все равно генерировали невероятную нагрузку на etcd. Так может быть, есть способ в каких-то случаях избежать запросов к базе?
Resource Version
Способ, о котором мы вспомнили первым — указать в качестве параметров запроса resourceVersion. У каждого объекта в Kubernetes указана версия, которая увеличивается каждый раз, когда объект изменяется. Используем это свойство.
На самом деле, параметров два: resourceVersion и resourceVersionMatch. Как именно их крутить, с подробностями и умным языком описано в документации Kubernetes. Поэтому давайте сфокусируемся на том, какую версию объекта мы можем получить в итоге.
Самая последняя версия (MostRecent) — версия по умолчанию. Если не указаны никакие опции, мы получаем самую последнюю версию объекта. Чтобы убедиться, что это САМАЯ последняя версия, нужно ВСЕГДА отправлять запрос в etcd.
Любая версия (Any) — если мы попросили вернуть нам версию не старше »0», то получим ту версию, которая лежит у kube-apiserver в кэше. В этом случае etcd нам нужен только в тех случаях, когда кэш пуст.
Важный момент: если у вас более чем один экземпляр kube-apiserver, то есть риск получить разные данные при запросах в разные kube-apiserver.
Версия не старше, чем (NotOlderThan) — требует указания конкретной версии, поэтому при старте приложения мы это использовать не можем. Запрос попадает в etcd, если подходящей версии нет в кэше.
Точная версия (Exact) — то же самое, что и NotOlderThan, только в etcd запросы попадают чаще.

Если вашему контроллеру важна точность полученных данных, то настройки по умолчанию (MostRecent)вас устраивают. А вот для отдельных компонентов, например, системы мониторинга, предельной точностью вполне можно пожертвовать. Похожая опция есть и в kube-state-metrics.
Решение найдено. Проверяем.
# kubectl get --raw '/api/v1/pods' -v=7 2>&1 | grep 'Response Status'
I0323 21:17:09.601002 160757 round_trippers.go:457] Response Status: 200 OK in 337 milliseconds
# kubectl get --raw '/api/v1/pods?resourceVersion=0&resourceVersionMatch=NotOlderThan' -v=7 2>&1 | grep 'Response Status'
I0323 21:17:11.630144 160944 round_trippers.go:457] Response Status: 200 OK in 117 millisecondsВ etcd видим только один запрос, который длится 100 миллисекунд.
{
"level": "warn",
"ts": "2023-03-23T21:17:09.846Z",
"caller": "etcdserver/util.go:166",
"msg": "apply request took too long",
"took": "130.768157ms",
"expected-duration": "100ms",
"prefix": "read-only range ",
"request": "key:\"/registry/pods/\" range_end:\"/registry/pods0\" ",
"response": "range_response_count:7130 size:13313287"
}Работает! Но что же могло пойти не так? Наше приложение было написано на Rust, а в библиотеке для работы с Kubernetes для Rust-параметров просто не существует настройки resource version!
Глубоко внутри грустим, делаем пометку в будущем отправить разработчикам этой библиотеки pull request и идем искать другое решение (кстати, pull request мы отправить не забыли).
Замедлиться, чтобы ускориться
Но была и еще одна особенность, которая бросилась в глаза: последовательный перекат Pod«ов никак не отражался на графиках потребления, там можно было увидеть только одновременный перезапуск. А что, если бы мы смогли каким-то образом выстроить все запросы к kube-apiserver в очередь и не давать нашим приложениям его убить? Так ведь мы и правда можем это сделать.

Для этого обратимся к API Priority & Fairness. Подробно обо всех нюансах можно прочитать в документации — нам не до этого, нам аварию чинить нужно. Остановимся на самом главном: как выстроить все запросы в очередь.
Чтобы это сделать, нужно создать два манифеста:
apiVersion: flowcontrol.apiserver.k8s.io/v1beta1
kind: PriorityLevelConfiguration
metadata:
name: limit-list-custom
spec:
type: Limited
limited:
assuredConcurrencyShares: 5
limitResponse:
queuing:
handSize: 4
queueLengthLimit: 50
queues: 16
type: Queue
PriorityLevelConfiguration по-простому назовем «настройки очереди». Они стандартные и скопированы из документации. Главная проблема здесь — настройки одной очереди влияют на работу других очередей, и понять, сколько параллельных запросов тебе дано, можно, только после применения ресурса или сложных математических расчетов в уме.
apiVersion: flowcontrol.apiserver.k8s.io/v1beta1
kind: FlowSchema
metadata:
name: limit-list-custom
spec:
priorityLevelConfiguration:
name: limit-list-custom
distinguisherMethod:
type: ByUser
rules:
- resourceRules:
- apiGroups: [""]
clusterScope: true
namespaces: ["*"]
resources: ["pods"]
verbs: ["list", "get"]
subjects:
- kind: ServiceAccount
serviceAccount:
name: ***
namespace: ***FlowSchema отвечает на вопросы «Что? Кем? Куда?», или чьи запросы каких ресурсов в какую очередь отправить.
Применяем оба в надежде на успех и смотрим графики.

Отлично! Все еще остались всплески, но уже можно идти спать. Обрабатываем инцидент, критичность снята.
Послесловие
Тем DaemonSet«ом был сборщик логов vector, который использует данные о Pod«ах для обогащения логов метаинформацией. Проблема была решена в рамках открытого нами PR«а.
Не только запросы Pod«ов являются потенциально опасными. Позднее такую же проблему мы обнаружили внутри CNI Cilium — и решили ее уже известным, проверенным способом.
Подобные нюансы в работе Kubernetes часто возникают во время эксплуатации. Один из эффективных способов решения этой проблемы — использование платформы, в которой этот и многие другие кейсы отработаны по умолчанию. Например, Deckhouse.
P.S.
Читайте также в нашем блоге:
