Критерий Манна-Уитни — самый главный враг A/B-тестов
Всем привет! Меня зовут Дима Лунин, я аналитик в компании Авито. В этой статье я расскажу про критерий Манна-Уитни и проблемы при его использовании.
Этот критерий очень популярен. Во многих компаниях и на обучающих курсах рассказывают про два его важных преимущества:
Манн-Уитни — непараметрический собрат T-test. Если данные в A/B-тесте не из нормального распределения, то T-test использовать нельзя. На помощь приходит Манн-Уитни.
Манн-Уитни — робастный критерий. В данных часто бывает много шумов и выбросов, поэтому T-test неприменим по соображениям мощности, чувствительности или ненормальности данных. А Манн-Уитни в этот момент отлично срабатывает и более вероятно находит статистически значимый эффект.
Если вы анализировали A/B-тест, где вас интересовал прирост или падение какой-то метрики, то наверняка использовали критерий Манна-Уитни. Я хочу рассказать про подводные камни этого критерия, и почему мы в компании его не используем. А в конце вы поймёте, откуда взялся такой холиварный заголовок:)
План статьи такой:
Я теоретически покажу, что проверяет Манн-Уитни и почему это не имеет ничего общего с ростом медиан и среднего значения. А ещё развею миф, что Манн-Уитни проверяет эту гипотезу:
C) = ½» src=«https://habrastorage.org/getpro/habr/upload_files/497/c4f/b46/497c4fb4626a0fd50652ab7a413cc674.svg» />
Например, у нас в A/B-тесте две выборки:
U[−1, 1] — равномерное распределение от −1 до 1
U[−100, 100] — равномерное распределение от −100 до 100
Про эти два распределения мы знаем, что у них равны средние и медианы, и что они симметричны относительно 0. Кроме того, вероятность, что сгенерированное значение в первой выборке будет больше значения во второй выборке, равна ½. Или, если сформулировать математически, P (T > C) = ½, где T и C — выборки теста и контроля.
Я хочу проверить, работает ли здесь корректно Манн-Уитни. Для этого запустим эксперимент 1000 раз и посмотрим на количество отвержений нулевой гипотезы у критерия. Подробнее про этот метод можно прочесть в моей статье про улучшение A/B тестов. Если бы критерий Манна-Уитни работал как надо и проверял одну из гипотез, то по определению уровня значимости он бы ошибался на этих тестах в 5% случаев, с некоторым разбросом из-за шума.
Проверим корректность примера на уровне значимости для T-test критерия:
# Подключим библиотеки
import scipy.stats as sps
from tqdm.notebook import tqdm # tqdm – библиотека для визуализации прогресса в цикле
from statsmodels.stats.proportion import proportion_confint
import numpy as np
# Заводим счетчики количества отвергнутых гипотез для Манна-Уитни и для t-test
mann_bad_cnt = 0
ttest_bad_cnt = 0
# Прогоняем критерии 1000 раз
sz = 1000
for i in tqdm(range(sz)):
# Генерируем распределение
test = sps.uniform(loc=-1, scale=2).rvs(1000) # U[-1, 1]
control = sps.uniform(loc=-100, scale=200).rvs(1000) # U[-100, 100]
# Считаем pvalue
mann_pvalue = sps.mannwhitneyu(control, test, alternative='two-sided').pvalue
ttest_pvalue = sps.ttest_ind(control, test, alternative='two-sided').pvalue
# отвергаем критерий на уровне 5%
if mann_pvalue < 0.05:
mann_bad_cnt += 1
if ttest_pvalue < 0.05:
ttest_bad_cnt += 1
# Строим доверительный интервал для уровня значимости критерия (или для FPR критерия)
left_mann_level, right_mann_level = proportion_confint(count = mann_bad_cnt, nobs = sz, alpha=0.05, method='wilson')
left_ttest_level, right_ttest_level = proportion_confint(count = ttest_bad_cnt, nobs = sz, alpha=0.05, method='wilson')
# Выводим результаты
print(f"Mann-whitneyu significance level: {round(mann_bad_cnt / sz, 4)}, [{round(left_mann_level, 4)}, {round(right_mann_level, 4)}]")
print(f"T-test significance level: {round(ttest_bad_cnt / sz, 4)}, [{round(left_ttest_level, 4)}, {round(right_ttest_level, 4)}]")Результат:
Mann-whitneyu significance level: 0.114, [0.0958, 0.1352]
T-test significance level: 0.041, [0.0304, 0.0551]T-test здесь корректно работает: он ошибается в 5% случаев, как и заявлено. А значит, пример валиден.
Манн-Уитни ошибается в 11% случаев. Если бы он проверял равенство средних, медиан или P (T > C) = ½, то должен был ошибиться только в 5%, как T-test. Но процент ошибок оказался в два раза больше. А значит, что эти гипотезы неверны для Манна-Уитни:
 T и C — выборки теста и контроля
T и C — выборки теста и контроля
Этот метод можно использовать для проверки только такой гипотезы:
 F — функция распределения метрики у пользователей в контроле и в тесте, T и C — выборки теста и контроля
F — функция распределения метрики у пользователей в контроле и в тесте, T и C — выборки теста и контроля
Этот критерий проверяет, что выборки теста и контроля взяты из одного распределения. Если он считает, что выборки из разных распределений — отвергает гипотезу. Это обычный критерий однородности.
Для демонстрации корректности я предлагаю снова запустить 1000 раз тесты, но выборки теста и контроля в этот раз взяты из одного распределения: U[-100, 100] (равномерное распределение от -100 до 100).
Проверка
# Подключим библиотеки
import scipy.stats as sps
from tqdm.notebook import tqdm # tqdm – библиотека для визуализации прогресса в цикле
from statsmodels.stats.proportion import proportion_confint
import numpy as np
# Заводим счетчики количества отвергнутых гипотез для Манна-Уитни и для t-test
mann_bad_cnt = 0
ttest_bad_cnt = 0
# Прогоняем критерии 1000 раз
sz = 1000
for i in tqdm(range(sz)):
# Генерируем распределение
test = sps.uniform(loc=-100, scale=200).rvs(1000) # U[-100, 100]
control = sps.uniform(loc=-100, scale=200).rvs(1000) # U[-100, 100]
# Считаем pvalue
mann_pvalue = sps.mannwhitneyu(control, test, alternative='two-sided').pvalue
ttest_pvalue = sps.ttest_ind(control, test, alternative='two-sided').pvalue
# отвергаем критерий на уровне 5%
if mann_pvalue < 0.05:
mann_bad_cnt += 1
if ttest_pvalue < 0.05:
ttest_bad_cnt += 1
# Строим доверительный интервал для уровня значимости критерия (или для FPR критерия)
left_mann_level, right_mann_level = proportion_confint(count = mann_bad_cnt, nobs = sz, alpha=0.05, method='wilson')
left_ttest_level, right_ttest_level = proportion_confint(count = ttest_bad_cnt, nobs = sz, alpha=0.05, method='wilson')
# Выводим результаты
print(f"Mann-whitneyu significance level: {round(mann_bad_cnt / sz, 4)}, [{round(left_mann_level, 4)}, {round(right_mann_level, 4)}]")
print(f"T-test significance level: {round(ttest_bad_cnt / sz, 4)}, [{round(left_ttest_level, 4)}, {round(right_ttest_level, 4)}]")
Результаты:
Mann-whitneyu significance level: 0.045, [0.0338, 0.0597]
T-test significance level: 0.043, [0.0321, 0.0574]Манн-Уитни не может проверить ничего, кроме равенства распределений. Этот критерий не подходит для сравнения средних или медиан.
Разберёмся, почему Манна-Уитни нельзя применять для сравнения средних, медиан и P (T > C) = ½. Для начала посмотрим на статистику, которая считается внутри критерия:
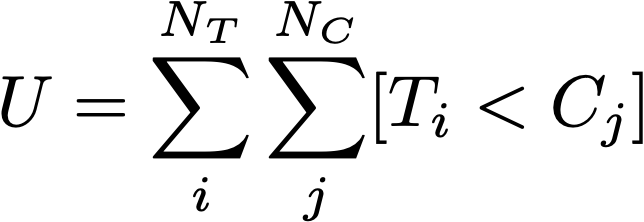
Для неё считаются те критические области, при попадании в которые статистики U критерий отвергнется.
Отсюда видно, что:
Манн-Уитни учитывает расположение элементов выборок относительно друг друга, а не значения элементов. Поэтому он не может сравнивать математические ожидания, даже если не знает абсолютные значения элементов выборки.
Гипотеза H_0: P (T > C) = ½ неверна для данного критерия. Если P (T > C) = ½, то мат. ожидание EU = (произведение размера выборок) / 2. Но при равенстве распределений мат ожидание статистики U будет точно таким же. Почему критерий не сработал на примере с 2 разными равномерными распределениями U[-1, 1] VS U[-100, 100], но сработал при сравнении распределений U[-100, 100] VS U[-100, 100]? Суть в том, что мы не знаем распределение статистики U. Когда тест и контроль из одного распределения, мы знаем, что статистика U распределена нормально. Но если это не так, то теорема перестаёт работать. Тогда мы не знаем, как распределена статистика U, и не можем посчитать p-value.
По этой же причине критерий не может проверять равенство медиан.
Мы рассмотрели, почему Манна-Уитни не следует применять для проверки равенства средних, медиан и смущённости распределений. Но на практике его все равно часто применяют для этих гипотез, особенно для равенства средних. Что плохого может случиться в этом случае? Правда ли, что в таком случае мы завысим ошибку 1 рода в 2 раза и будем ошибаться в 11% вместо 5%?
Манн-Уитни при анализе реальных A/B-тестов: подводные камни
На реальных задачах проблемы Манна-Уитни будут куда серьёзнее, чем завышение alpha в два раза. Все последующие примеры будут основаны на кейсах, которые встречаются на практике в Авито. Я продемонстрирую работу критерия Манна-Уитни на искусственно сгенерированных данных, моделирующих один из наших экспериментов, а потом продемонстрирую результаты на настоящих данных из Авито.
Допустим, мы проводим A/B-тест с целью улучшить какую-то метрику. Тогда наше изменение чаще всего приводит к двум ситуациям:
Части пользователей понравилось наше воздействие и нулей в выборке стало меньше. Например, мы дали скидки на услуги, платящих пользователей стало больше.
Другой части пользователей не понравилось наше изменение и они оттекли по метрике — стало больше нулей.
В обоих этих случаях я покажу, как может работать критерий.
Кейс 1: прирост количества пользователей
Я разберу этот кейс на примере выдачи скидки. Количество платящих пользователей увеличилось, но ARPPU упал. Наша ключевая метрика — выручка. Мы хотим понять: начнём ли мы больше зарабатывать со скидками. Или выросло ли ARPU, математическое ожидание выручки — что эквивалентно.
Сразу зафиксируем проверяемую гипотезу о равенстве средних: H0 — средний чек не изменился или упал vs. H1 — средний чек вырос. Мы уже знаем, что Манн-Уитни может ошибаться в этой задаче. Но насколько?
Искусственно насимулируем эксперимент, который мог бы произойти в реальности. В этот раз это будут не два равномерных распределения, а что-то более приближенное к реальности, и что вы сможете проверить самостоятельно, запустив код.
Пусть распределение ненулевой части метрики подчиняется экспоненциальному распределению. Для выручки это хорошее приближение.
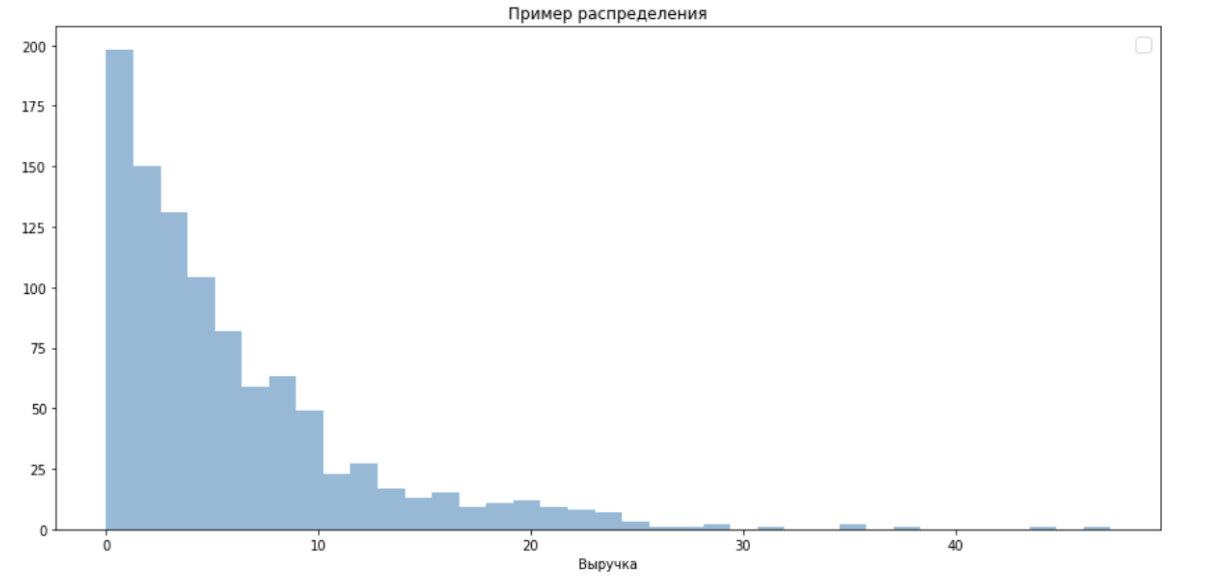
Пусть нашими скидками мы увеличили число платящих пользователей на 5%.
Изначально в контроле было 50% нулей. Половина пользователей ничего не покупали на сайте.
В тесте стало 55% платящих пользователей.
Раньше пользователь в среднем платил 7 рублей, а сейчас из-за скидки он платит 6 ₽, скидка была примерно 15%. Тогда математическое ожидание выручки в контроле было 3.5 ₽ (7×0.5), а в тесте — 3.3 ₽ (6×0.55).
То есть платящих пользователей стало больше, а средний чек упал. А значит, верна H0 и процент ложноположительных срабатываний не может быть больше 5% у корректного критерия. Для проверки мы снова запустим тест 1000 раз и проверим, что здесь покажут T-test с Манном-Уитни.
Демонстрация результатов:
# Подключим библиотеки
import scipy.stats as sps
from tqdm.notebook import tqdm # tqdm – библиотека для визуализации прогресса в цикле
from statsmodels.stats.proportion import proportion_confint
import numpy as np
# Заводим счетчики количества отвергнутых гипотез для Манна-Уитни и для t-test
mann_bad_cnt = 0
ttest_bad_cnt = 0
sz = 10000
for i in tqdm(range(sz)):
test_zero_array = sps.bernoulli(p=0.55).rvs(1000)
control_zero_array = sps.bernoulli(p=0.5).rvs(1000)
test = sps.expon(loc=0, scale=6).rvs(1000) * test_zero_array # ET = 3.3
control = sps.expon(loc=0, scale=7).rvs(1000) * control_zero_array # EC = 3.5
# Проверяем гипотезу
mann_pvalue = sps.mannwhitneyu(control, test, alternative='less').pvalue
ttest_pvalue = sps.ttest_ind(control, test, alternative='less').pvalue
if mann_pvalue < 0.05:
mann_bad_cnt += 1
if ttest_pvalue < 0.05:
ttest_bad_cnt += 1
# Строим доверительный интервал
left_mann_power, right_mann_power = proportion_confint(count = mann_bad_cnt, nobs = sz, alpha=0.05, method='wilson')
left_ttest_power, right_ttest_power = proportion_confint(count = ttest_bad_cnt, nobs = sz, alpha=0.05, method='wilson')
# Выводим результаты
print(f"Mann-whitneyu LESS power: {round(mann_bad_cnt / sz, 4)}, [{round(left_mann_power, 4)}, {round(right_mann_power, 4)}]")
print(f"T-test LESS power: {round(ttest_bad_cnt / sz, 4)}, [{round(left_ttest_power, 4)}, {round(right_ttest_power, 4)}]")Результат:
Mann-whitneyu LESS power: 0.3232, [0.3141, 0.3324]
T-test LESS power: 0.0072, [0.0057, 0.0091]Процент принятий гипотезы H1: «средний чек вырос» у T-test около 0: это нормально, так как мы знаем, что на самом деле среднее в тесте упало, а не выросло — критерий корректен. А у Манна-Уитни процент отвержений 32%, что сильно больше 11%, которые были в первом, изначальном примере.
Представим, что на ваших настоящих данных была примерно такая же картина. Только в реальности вы не симулировали эксперимент, поэтому не знаете, что ваш средний чек упал. У T-test околонулевой процент обнаружения статистически значимого эффекта. Используя его, вы видите, что он ничего не задетектировал, начинаете использовать критерий Манна-Уитни, и в одной трети случаев обнаруживаете эффект, что среднее увеличилось.
Увидев, что T-test не прокрасился, а Манн-Уитни даёт статистически значимый прирост, многие аналитики доверятся второму критерию и покатят на всех пользователей скидки. И выручка упадёт.
Кейс 2: отток части пользователей
Другой вариант: части пользователей не понравилось наше изменение и они ушли. Допустим, мы захотели нарастить количество сделок на Авито. Сделка у нас — событие, когда продавец нашёл покупателя на своё объявление. Для этого мы добавили новые обязательные параметры в объявление и процесс подачи стал сложнее. Часть продавцов отвалилась, зато остальным стало легче: теперь покупателям с помощью фильтров и поиска проще находить подходящие объявления. Осталось понять, нарастили ли мы количество сделок.
Например, у нас было 100 продавцов и в среднем они совершали 2 сделки на Авито. После того как мы ввели новые параметры, продавцов стало 70. Оставшимся 30 продавцам наша инициатива не понравилась и они ушли. Теперь на одного продавца приходится по 3 сделки, так как пользователям стало легче находить релевантный товар. Раньше было 200 сделок, а теперь 210.
В этот раз все распределения будут взяты не из теоретических соображений, а из реальных данных. Как это сделать, я подробно рассказывал в статье про улучшение A/B-тестов. Я собрал 1000 настоящих А/А-тестов на исторических данных в Авито: взял всех продавцов в разных категориях и регионах за разные промежутки времени и поделил случайно на тест и контроль. Повторил это 1000 раз.
Теперь я хочу простимулировать эффект от ввода новых обязательных параметров в тестовой группе: я моделирую отток пользователей и прирост числа сделок у оставшихся продавцов.
Как именно я это сделал:
взял в качестве метрики количество сделок;
обнулил число сделок 5 процентам случайных продавцов, как будто они ушли с площадки;
у оставшихся пользователей в тестовой группе я домножил количество сделок на некий коэффициент больше единицы. В итоге среднее число сделок на продавца стало больше даже с учетом оттока. В примере выше этот коэффициент равнялся бы 1.5: 2 сделки → 3 сделки.
На самом деле количество сделок выросло от введения новых параметров.
Замечание
Да, получились не совсем «реальные» AB-тесты, а лишь приближения к ним. Но в любом случае это наилучшее возможное приближение, где мы знаем реальный эффект.
Теперь построим таблицу процента отвержений нулевой гипотезы в зависимости от альтернативы на этих 1000 A/B-тестах:
в тесте количество сделок больше, чем в контроле | --//-- меньше, чем в контроле | |
T-test | 27% | 0.1% |
Манн-Уитни | 6% | 80%
|
