Кошелек с нуля в 2020 году: технологии, вызовы, решения
Большую часть своей рабочей биографии я занимаюсь различными финтех продуктами — Яндекс.Деньги, 1ЦУПИС и так далее. Последние два года я разрабатываю очередное платежное решение и хочу рассказать о некоторых задачах, с которыми мы встретились. Но мне интересно рассказать не только про появившиеся решения, но и, в первую очередь, про то, как вообще можно думать про архитектуру сложных систем.

Что мы делаем
В бумажном кошельке мы обычно храним банковские карты, какие-то деньги, проездной и скидочные карты соседних магазинов. Цифровой кошелек (Digital Wallet) позволяет хранить примерно то же самое, но внутри вашего мобильного телефона. По сути, цифровой кошелек дает пользователю возможность использовать все богатство инструментов финансовой системы, от банков до магазинов.
Компания OpenWay Group уже давно лидер рынка по созданию платежных (карточных и не только) решений и именно в ее рамках мы с командой начали создавать кошелек как продукт.
Понятно, что у подобного продукта могу быть очень разные заказчики:
Государственные платежные системы и крупные банки, с сотней миллионов пользователей, тысячами платежей в секунду, огромными бюджетами и опытной командой;
Небольшие региональные банки, мечтающие о миллионе клиентов и нескольких десятках платежей в секунду и не имеющие денег даже на нормального DBA.
Клиенты из Европы, где GDPR и много других регуляций, каждый шаг прописан и более-менее соответствует законам;
Заказчики из третьего мира, где законы пишутся на ходу, иногда — под конкретный кошелек или банк;
Давно существующие компании со своей сложившейся инфраструктурой, несколькими дата центрами и консервативным подходом к новым технологиям
Стартапы, которые еще даже не думали о том, какая им нужна инфраструктура.
Поэтому было нужно дешевое, неприхотливое, но при этом масштабируемое и кастомизируемое решение.
Проект создавался как внутренний стартап, небольшой командой, которую легко можно было накормить парой пицц, но зато со свободой в выборе технологий и бизнес-процессов, а также мы могли пользоваться всей накопленной экспертизой OpenWay.
Архитектура
Есть множество разнообразных определений архитектуры, но мне больше всего нравится цитата с сайта Мартина Фаулера:
Architecture is about the important stuff. Whatever that is.© Ralph Johnson
Т.е. архитектора — это про важные штуки, чем бы они ни были. Прекрасное определение, но не очень применимое на практике. Дальше я опишу несколько подходов к тому, что такое архитектура для меня и как можно смотреть на системную архитектуру для довольно сложного проекта.
Архитектура как необходимые выборы
В первую очередь архитектура — это про выбор. Мы выбираем технологии, архитектурные стили, конкретные шаблоны и решения. Выбираем, что хотим делать и что делать точно не хотим. Выборы, конечно, уникальны для каждого продукта, но есть несколько основных технических решений, которые приходится делать почти в каждом проекте. Одно из них — выбор базы данных.
Обычно базы данных нужны для двух различных сценариев использования, и я не рекомендую их путать друг с другом:
OLTP — как быстро обработать и надежно сохранить происходящие прямо сейчас события;
OLAP — как дать аналитикам всю нужную им информацию.
Это два разных мира, они требуют разных технологий.
В нашем случае в OLTP нам были нужны:
Надежность, потому что это финтех, нас всегда спрашивают, а насколько у нас все хорошо с надежностью.
Масштабируемость, потому что одно дело — бедный клиент, у которого миллион пользователей. Другое — большой банк, у которого 100 миллионов пользователей и 5 тысяч платежей в секунду. Нужно как-то решать проблемы и того, и другого.
Бесплатность, потому что не все готовы платить за энтерпрайзный Oracle со всеми его опциями.
Простота эксплуатации, потому что клиенты разные и не у всех есть DBA
Поэтому у нас было не так уж много вариантов:
Oracle дороговат;
PostgreSQL почему-то не очень любят банки. Возможно, из-за требований к безопасности или по старой памяти, но этот риск нужно учитывать. Как и то, что опыт эксплуатации PostgreSQL встречается в банках нечасто.
Про Mongo лучше вообще не упоминать — там не всё хорошо и с надежностью (было не прекрасно, но финтех злопамятен), и с производительностью.
Казалось бы, нормального выбора нет. Но после долгих поисков мы нашли довольно странное, но устраивающее нас решение: FoundationDB
FoundationDB
Мало кто слышал про эту базу не от меня. Что это такое?
Open-source distributed scalable transactional (ACID) key-value database with crazy thorough testing
Это бесплатная БД с поддержкой полноценных транзакций была куплена Apple, но осталась открытой. Внутри Apple очень многое на ней крутится — тысячи серверов, миллионы транзакций в секунду. Используется она и в других крупных компаниях, например, в Snowflake.
База проста в развертывании и сопровождении, довольно быстрая и, главное —очень надежная. Ведущий специалист по распределенным системам и создатель популярных Jepsen тестов на вопрос о тестировании Foundation DB» ответил: «Haven’t tested foundation in part because their testing appears to be waaay more rigorous than mine» © Kyle Kingsbury (@aphyr). Сложно придумать рекламу лучше. Конечно, Jepsen-тесты прогонялись командой FoundationDB, и мы тоже ее протестировали. Эта база данных действительно работает надежно.
Итак, мы взяли надежное, масштабируемое и легкое в поддержке решение. Но, увы, ленчей даром не бывает и у FoundationDB, куча своих проблем.
Нет платной поддержки
Вы не можете пойти к большому и богатому дяде и сказать: «Возьми деньги, поддерживай ее за меня». Поэтому поддержку нашим клиентам мы предоставляем самостоятельно. Пришлось вырастить специалистов, наладить контакт с разработчиками и разобраться в продукте достаточно, чтобы участвовать в его развитии.
Низкоуровневый и довольно сложный API
Это key-value база данных, которая работает на уровне «возьми байтики в качестве ключа и положи туда еще байтики в качестве значений» — и всё! Поэтому мы написали свою библиотеку с поддержкой асинхронного доступа, типизацией, сериализацией в CBOR (потому что это компактней, чем в JSON и быстрее) и поддержкой house-keeping.
Вообще, функция удаления устаревших данных для key-value баз данных реализуется не очень тривиально, нужно хитрым образом организовывать ключи, но про это, надеюсь, расскажу как-нибудь потом
Нет ограничений доступа в многопользовательских системах
Мы добавили в библиотеку криптографию и управление ключами — и шифруем все данные, которые попадают в БД. Этот способ надежнее, чем ограничения прав доступа для отдельных пользователей.
Слабый инструментарий
Мы сделали свой движок миграций типа Flyway, но более навороченный, с поддержкой параллельных и сверхдолгих миграции, управлением зависимости между версиями БД и так далее.
По опыту эксплуатации этим выбором мы довольны, хотя иногда и мечтаем об открытом, надежном и горизонтально масштабируемом PostgreSQL;)
С выбором БД для задач OLAP все гораздо проще, так как есть Clickhouse, который решает все наши задачи. Разумеется, это не все технологические выборы, которые мы сделали. Прочий стек проще перечислить: Kotlin, ktor, Flutter, React, Rest level 1. Каждый выбор мы так или иначе обосновывали и фиксировали.
Архитектура как язык
Архитектура — это не только про выбор, на архитектуру можно смотреть и как на язык описания системы. Таких языков накопилось в IT довольно много, самый показательный пример — design patterns. Любому разработчику в мире можно сказать: «Я хочу, чтобы здесь был singleton, а вот здесь — стратегия», он вас поймет и всё сделает.
Но, к сожалению, для более высокого уровня архитектуры таких языков мало. Onion Architecture или Clean Architecture дает терминологию, но очень нечеткую, а «у нас микросервисная архитектура» вообще не значит ничего конкретного.
Поэтому язык архитектуры приходится придумывать самому — на основании тех параметров, которые нужны для конкретного продукта. Мы взяли картинку с нашими сервисами, и описали «какие задачи решают сервисы», «какие паттерны кастомизации используем», «какие требования по безопасности нужны» и, в результате, получили простой язык, на котором можно легко просить разработчика «сделай сценарный сервис, с конфигурацией логики через DSL», и дальше уже не требуется дополнительных пояснений.
Выглядит это так (хотя для другого продукта будут совсем другие типы сервисов и другой язык описания архитектуры):

Архитектура как управление сложностью
Все программирование — это про управление сложностью, и архитектура тоже про это. Когда у вас маленькая команда и нужно довольно быстро что-то делать, сложность становится вашим самым главным врагом, с которым приходится бороться.
Какие самые интересные сложности, с моей точки зрения, есть в финтехе?
Бизнес-сценарии
Например, онбординг. Пришел новый пользователь и хочет зарегистрироваться в системе. Нужно зарегистрировать его логин и пароль в системе управления identity, его персональные данные занести в систему хранения персональных данных, ему нужно создать счет в ABS, проверить в какой-нибудь государственной структуре, правильный ли у него паспорт, а в другой системе проверить, не террорист ли он. Это около десяти шагов, полдюжины подсистем и десятки сервисов. Все эти шаги нужно гарантированно пройти. Если где-то что-то упало, надо подумать, что с этим делать.
В современных системах платеж — это тоже сложная логика. У пользователя может быть кошелек одного банка, в нем карточка другого банка, с нее нужно снять деньги, выплатить нужные комиссии, перевести остаток денег на PayPal, сдачу отправить на благотворительность, и так далее. Получается тоже десятки шагов, несколько подсистем и дюжина участвующих сервисов.
Блокировки, KYC management, возвраты — все это требует довольно сложных распределенных бизнес-процессов, которые нужно делать быстро (потому что их много) и максимально надежно (потому что это финтех). Пользователь не поймет, если его деньги где-то застрянут — лучше пусть платеж не пройдет, чем неизвестность.
Как обычно решаются такие задачи?
Саги
Слово сага — примерно как микросервис, перестало значить что бы то ни было. Есть некоторое более-менее нормальное определение и оригинальная статья 1986 года. Если коротко, то:
Разбиваем бизнес-процесс на множество отдельных шагов;
Для каждого шага проектируем компенсацию, то есть обратную операцию;
При выполнении сценария фиксируем список выполненных шагов;
В случае ошибки запускаем все компенсации на пройденные шаги с конца в начало.
Но у саг есть много проблем.
Обычно нужно не отменить процесс, а дожать его другим способом. Мне, скорее, нужно, чтобы мой платеж все-таки завершился, например, если упал Сбербанк, то заплатить через Альфа-Банк или еще как-то, лишь бы завершить оплату мобильного телефона.
Компенсации не всегда возможны. До сих пор довольно много сервисов предоставляют однофазный API, в результате компенсировать запрошенный платеж невозможно.
Компенсация часто нужна не для операции, а для всего процесса. Например, вместо компенсаций, обратных транзакций и так далее часто можно просто послать сообщение оператору: «Тут что-то пошло не так, разберись руками, пожалуйста». Оператор справится лучше.
Сложно учитывать ограничения всей бизнес-транзакции (время выполнения, бюджет транзакции и т.п.) У бизнес-транзакций обычно есть довольно сложный набор ограничений: сколько времени можно на них потратить, сколько параллельных запросов какому-то внешнему сервису можно сделать и так далее. Соблюдать эти ограничения при реализации компенсации непросто.
Код получается довольно сложный. Я знаю, что многие любят делать саги через хореографию. На мой взгляд, это лучший способ сделать категорически нечитаемый код уже буквально через полгода, в котором потом не разберется никто.
Но даже саги с оркестрацией выглядят довольно печально. Нужно думать о том, какие события формируешь, зарегистрировать в каком-то обработчике обратные шаги и критерии запуска компенсаций. Сам код операции становится расплывчатым, и никто, кроме программистов, не в состоянии его нормально читать.
Я вообще давно мучаюсь вопросом, как именно делать сложные бизнес-транзакции. Года 2–3 назад я рассказывал про персистентные акторы, как прекрасное решение этой ситуации. Но сейчас предпочитаю оркестрацию через workflow.
Workflow
Лучше всего известна реализация этого подхода в проекте Cadence от Uber. Это очень похоже на сагу:
Описываем процесс как императивный простой код из отдельных шагов;
При выполнении каждого шага сохраняем его результат куда-то в persistence;
При проблемах с шагом стараемся его повторять, дожимая до конца;
При падении сервера, выполняющий бизнес-процесс, повторяем весь процесс с начала на другом сервере. А поскольку у нас шаги сохраненные, то подкладываем их результаты, чтобы лишний раз нагрузку не увеличивать.
Для исключительных ситуаций пишем такой же workflow, состоящий из тех же шагов.
Workflow позволяет описывать бизнес-процесс максимально понятным образом. Я вообще люблю тупой, простой, последовательный код без каких-либо сложностей, потому что такой код легче тестировать и исправлять, к тому же проще найти разработчика на поддержку. Его можно даже отдать на проверку аналитику.
У Cadence есть опенсорсная версия temporal.io. К сожалению, она нам не очень подошла, потому что она весьма сложная в эксплуатации. Поэтому мы написали свой велосипед.
Haydn4k
Это библиотека на Kotlin, использующая FoundationDB в качестве хранилища, названа в честь композитора Гайдна, создателя симфонической музыки. Это библиотека, а не сервис, и ее можно подключать в любом месте, где нужно выполнить бизнес-транзакции.
При разработке библиотеки мы думали про удобство и производительность. Удобство обеспечивается DSL на котлине. Мы собираем обратную связь с разработчиков и стараемся сделать написание бизнес-сценариев (пьес) как можно удобнее и проще.
Производительность вполне обеспечивается FoundationDB. Нам нужно уметь выполнять более 100 000 одновременных сценариев и до 20 000 шагов в секунду.
Выглядит это так:
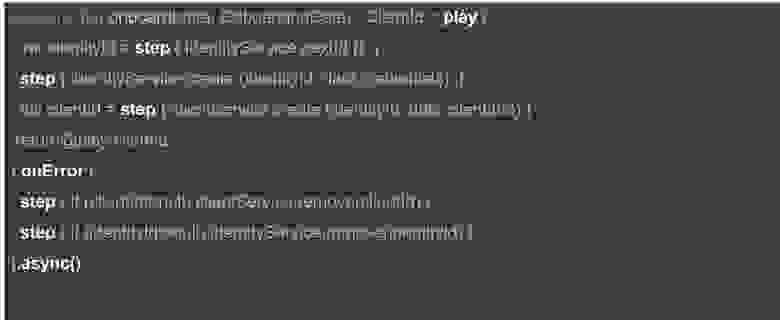 Haydn4k. Сценарий онбординга
Haydn4k. Сценарий онбординга
Это очень простенький сценарий онбординга: на вход берём некий набор данных и начинаем пьесу. Сначала получаем код следующего пользователя, затем создаем пользователя в рамках шага, после чего возвращаем его код обратно.
Если что-то произошло не так (в случае ошибки), мы удаляем данные из используемых сервисов.
Кстати, отдельный шаг не обязательно должен быть идемпотентным (т.е. при повторном применении давать тот же результат, что и при первом), достаточно просто возможности повторять операцию без нежелательных последствий. Например, взять следующий номер из последовательности — это не идемпотентная, но безопасная операция.
Код пьесы может быть и более сложным:
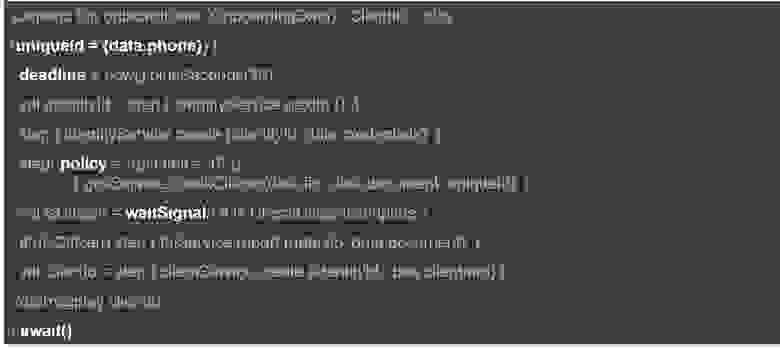 Haydn4k. Развитие пьесы
Haydn4k. Развитие пьесы
Тут мы обеспечиваем однократность всей пьесы (для каждого телефона будет выполняться только один экземпляр этой пьесы), указываем максимальное время выполнения, описываем ограничения на вызов внешних сервисов и ждем получения сообщений (сигналов) из другой пьесы. И так далее.
Queue
Раз у нас есть передача сообщений из одной пьесы в другую, то нам нужны очереди. Разумеется, для очередей есть и множество других целей:
События, отправляемые с сервера на клиент (Server Sent Messages). Очень удобно уведомлять клиента о происходящих событиях асинхронно и оперативно.
Внутренние события (отправка SMS, отчеты по расписанию и т.п.);
Очереди пользовательских задач (изменения параметров кошелька и т.п.).
При выборе решения для таких очередей возникает несколько требований. Очередей хочется много: по одной очереди на каждого пользователя, на каждый бизнес-процесс, в том числе и на каждый платеж, который еще не завершен. В результате одновременно в системе нужны несколько миллионов очередей. Впрочем, все эти очереди довольно небольшие — каждая не более тысячи событий. При этом самих событий, требующих обработки, набирается довольно много — десятки тысяч в секунду. Гарантии обработки событий нужны не очень строгие, вполне достаточно at least once.
К сожалению, эту совокупность нефункциональных требований не может обеспечить ни одно из популярных решений. У Kafka до недавнего времени было жесткое ограничение на количество партиций (независимых очередей, для которых сохраняется требование FIFO). Сейчас его сняли, но все равно поддерживать миллион партиций в Kafka очень непросто для эксплуатации.
Много одновременно живущих очередей несложно сделать на PostgreSQL или другой современной СУБД (два года назад я рассказывал, как именно), но вот обеспечить 10 тысяч событий в секунду будет уже сложно. Задача, конечно, решаемая, но требует хорошего DBA и мощный сервер, и всё равно будет очень непростой в эксплуатации.
Другие решения, вроде RabbitMQ или NATS, не обеспечивают нужных гарантий или производительности.
Поэтому нам пришлось сделать свой велосипед:
Сами очереди мы храним в FoundationDB. В одной или нескольких соседних записях хранится несколько событий, связанных с этой очередью.
Kafka используется для распределения по всем воркерам информации, что в какой-то очереди появилось новое событие.
Воркеры подписаны на Kafka, читают из неё сообщение, идут в FoundationDB, забирают всю очередь, обрабатывают событие (или несколько) и сохраняют очередь обратно — всё в одной транзакции. Нужно, конечно, аккуратно обработать ситуации перераспределения очередей по воркерам, ошибочные ситуации и так далее, но это не очень сложно. В результате получается масштабируемо, достаточно надежно, и наши требования по производительности тоже выполняются.
Теоретически, можно было бы обойтись и без Kafka, реализовав все только на FoundationDB, но это будет уже сложнее. Впрочем, может быть по опыту эксплуатации мы перейдем на использование только одной базы.
В результате от разработчика прячутся проблемы разработки надежных бизнес-транзакций в ненадежной многосервисной среде. Так как архитектура — это про управление сложностью.
Архитектура как точки зрения
Архитектура, кроме всего прочего — это множество viewpoints, множество точек зрения на вашу систему. На используемые сервисы, связи, базы данных можно смотреть с разных точек зрения. Для конкретного продукта одной из самых важных точек зрения является: «А как мы это кастомизируем».
Стратегии конфигурации и кастомизации
У каждого из наших клиентов, разумеется, свое представление о том, как должна работать платежная система и как должен работать кошелек. Поэтому нам приходится использовать много разных стратегий подготовки нашего решения под клиента:
Параметры конфигурации. Например, файлик с конфигурацией, где написано, сколько знако-мест в банковском счете в данной конкретной стране.
Точки добавления функциональности. Хочется иметь заранее предусмотренные места в системе для добавления новой функциональности, точки для добавления бизнес-логики, специфичной для конкретного клиента и только для него.
Точки расширения функциональности. Иногда функциональность общая (например блокировка пользователя), но реализовывать ее нужно для каждого клиента чуть-чуть по разному. Нужно заранее предусмотреть точки для разных вариантов похожей бизнес-логики.
Кастомизации. Иногда надо просто переписать весь код — взять какой-то сервис и сделать его копию под конкретного клиента.
Но каждый раз думать, каким именно конкретным способом для каждого конкретного сервиса мы хотим обеспечивать потребности клиента — это избыточно и требует слишком много напряжения, съедая мыслетопливо. Чем меньше напряжения ума и когнитивной сложности в процессе разработки, тем быстрее она идет.
Для реализации гибкой конфигурации функциональностей мы активно используем DSL на Kotlin.
Kotlin DSL
Kotlin — это язык, на котором удобно писать DSL, а JVM позволяет взять код на Kotlin из текстового файлика прямо во время исполнения, скомпилировать на лету и использовать скомпилированный код прямо во время работы. Мы этим очень активно пользуемся, потому что получается быстро, надежно, типизировано и эффективно.
Под каждую задачу делается свой собственный маленький DSL, поскольку делать его просто. Хранятся эти кусочки кода в общем config service, компилируются при старте и выполняется при необходимости.
Разумеется, пришлось подготовить инструменты для написания таких скриптов: настроенную ide, которую используют не только программисты, но и сотрудники внедрения, а также скрипты сборки, скрипты для тестов и тому подобное.
На Kotlin DSLs сделано много. Когда вы видите в истории «Пополнили PayPal на столько-то рублей», то за этой простой строчкой описания платежа прячется много магии, потому что для разных платежей нужно показывать совсем разное. Например, когда вы переводите деньги с карточки на свой основной счёт, то для вас главное, что вы сняли деньги с этой карточки. А если вы сняли деньги с привязанной чужой карточки для оплаты за телефон, вам важно знать, что вы заплатили именно за телефон.
На самом деле магии еще больше, и она очень специфична для каждого конкретного клиента. Тем более что клиенты очень разные, у них множество различных ограничений и регуляций. Например, в некоторых странах имя пользователя и телефон пользователя вообще нельзя писать нигде в визуальной части. Поэтому приходится делать очень специфичный код, и на Kotlin он пишется в 5 строчек, что гораздо лучше, чем 25 страниц настроек.
Специфические сценарии тоже легко делаются на Kotlin DSLs — например блокировки, изменение документов, онбординг. Так как сценарии на оркестраторе — просто Koltin-код, то совсем несложно подгружать их из конфигурации. А еще с помощью подобного DSL можно легко описывать правила доступа (ABAC), но про это чуть позже.
Итак, мы создали несколько разных паттернов конфигурации, которые формируют язык и через этот язык мы можем посмотреть на нашу систему и описать, какие типы сервисов как должны конфигурироваться.
Есть много других точек зрения, с которых можно смотреть на систему:
Кастомизация;
Авторизация/Аутентификация;
Связность сервисов;
Безопасность;
Высокая доступность;
Интернационализация, что для нас очень актуально и очень очевидно;
Обеспечение качества.
Обо всем этом рассказывать не буду, в этом можно утонуть часа на 2–3. Но расскажу про авторизацию и аутентификацию.
Авторизация / Аутентификация
У нас вроде бы обычный набор задач. Довольно много (10+ млн) внешних пользователей и много (10 000) внутренних пользователей. Причем мы не знаем инфраструктуру, где эти внутренние пользователи живут. У клиентов может быть Active Directory, а может быть какой-нибудь другой Identity Provider — неизвестно.
При этом есть разные механизмы подтверждения операций. Кому-то нужно какие-то платежные операции подтверждать через СМС, кому-то — через Google Authenticator, а где-то используется платежный пароль. Это тоже важная часть авторизации, про которую почти все стандартные решения забывают. Не говоря уже про разные модели доступа: ролевая, роли + атрибуты и прочие.
Увы, но популярные открытые решения вроде Keycloak не могут удовлетворить этим требованиям. У них нет поддержки подтверждений отдельных операций и они сложно масштабируются на миллионы пользователей.
Нам пришлось сделать тяжелый выбор (увы, архитектура — это про выборы) и реализовывать собственное решение для IAM/CIAM (Identity Management / Consumer Identity Management). Но так как наше решение соответствует только нашим потребностям, то это оказалось не очень сложным.
И теперь, в терминах реализованных примитивов аутентификации (сессии, ограничения на entrypoints, роли, атрибуты, примитивы работы с JWT, refresh/access/remember-me токены и т.д.), мы можем посмотреть на все сервисы и понять, где какие подходы необходимо использовать.
Если роли сервисов были выделены грамотно, то и все прочие viewpoints хорошо укладываются на эти роли. Всегда можно сказать, что для, например, доменных сервисов достаточно только конфигурации через настройки, аутентификации доступа через проверку корневого сертификата и авторизации через владение. И при разработке очередного подобного сервиса разработчик уже не тратит сил на все эти выборы.
Связность сервисов
Мы работаем в чужой инфраструктуре. У клиента может быть только голое железо, собственное облако или даже AWS —, но наверняка мы можем рассчитывать только на не очень экзотический Linux
В этих неизвестных условиях нам нужно уметь разворачивать и поддерживать всю нашу многосервисную систему, реализуя доступность, балансировку, мониторинг и управляя всем этим централизованно. Готовых решений под это нет. Почти все хорошие работают только под Kubernetes, например, Istio. А все, что работает не только под Kubernetes — не очень удобны.
Поэтому мы снова сделали свой велосипед — service-mesh, который реализует service-locator, load balancing, heartbeat, groovy scripts, etc. Написан он на Java+Netty, дает 13 000 rps на ядро и среднюю задержку примерно 0.4 ms. Для наших целей — в качестве sidecar внутри pod«а — реализованной функциональности абсолютно достаточно. При необходимости мы его дорабатываем.
Итого
Язык продукта описывает с полдюжины типов сервисов и несколько шаблонов для всех viewpoints, важных для продукта.
Основные выборы, сделанные для нашего продукта:
Kotlin + Foundation DB, и еще сбоку ClickHouse;
API first development, API описывается на Kotlin, а уже из него создаем файлы с OpenApi;
Kotlin DSLs, который мы активно используем;
Libraries over services, то есть мы предпочитаем библиотеки сервисам.
Несколько собственных велосипедов:
Все это позволило нашей команде, где меньше 10 человек, за 2 года сделать довольно сложное кошельковое решение и внедрить его нескольким клиентам.
Все (или почти все) наши технологии:

Главное
Архитектура — это не про картинки. Архитектура — это самое важное, что вы хотите сказать про систему. Некоторые подходы к размышлениям про архитектуру я вам описал:
Архитектура как необходимые выборы;
Архитектура как язык;
Архитектура как управление сложностью;
Архитектура как точки зрения.
Другие остались на будущее:
Архитектура как непрерывный процесс;
Архитектура как организация;
Архитектура как ограничения;
Архитектура как гарантии;
Описывать все возможные подходы к архитектуре можно бесконечно! Вопросы мне можно задавать в комментариях или в Telegram.
HighLoad++ 2021 — конференция для разработчиков высоконагруженных систем — пройдет 17 и 18 марта 2022 года в Крокус-Экспо в Москве. Расписание и билеты.
В ее рамках будет OPEN SOURCE трибуна, где каждый разработчик может рассказать о своем решении. Заявку вы можете оставить здесь.
