Концепция Tibbo AggreGate – платформы для Интернета вещей
Развитие Интернет быстро достигает уровня, когда он «просто есть». Нам все чаще не приходится задумываться, как именно мы сейчас подключены к сети, кто наш оператор связи, и, тем более, как подключение организовано технически. Повсеместное проникновение беспроводных сетей и постепенное распространение IPv6 позволяет тысячам простых устройств и датчиков беспрерывно общаться друг с другом и отправлять свои данные «в облако». Быстрое усложнение инфраструктуры привело к замене термина «Машина-к-машине» (Machine-to-Machine, M2M) на более актуальный термин «Интернет вещей» (Internet of things, IoT).
Формируя что-то вроде распределенного интеллекта, устройства Интернета вещей тем не менее нуждаются в централизованном управлении, в системе или сервисе для их настройки, хранения и интерпретации собранных данных. Являясь центральным «мозгом» инфраструктуры облака устройств, система управления также пополняет машинные базы знаний подключенных устройств и обновляет их программное обеспечение.
Операторы изучают агрегированные по группам устройств и временным периодам данные, визуализируя их в различных разрезах. Эти же данные передаются для более детального анализа в различные системы класса Business Intelligence. Любопытно, что даже если речь идет об персональных устройствах (например, фитнес-трекерах), мало какой оператор облачного сервиса отказывает себе в возможности проведения анонимного анализа статистики использования и использования собранных данных для дальнейшего совершенствования устройств и сервисов.
Разработка устройств для Интернета вещей постоянно упрощается и становится все дешевле, позволяя небольшим компаниям входить на этот рынок. Осознавая необходимость создания управляющей системы, многие компании недооценивают сложность ее разработки, не принимают во внимание необходимость использования промышленных серверных технологий (таких как кластеризация для обеспечения отказоустойчивости или мульти-серверная распределенная архитектура). Часто разработка начинается собственными силами, «in house». Успех выпущенных IoT устройств на рынке приводит к быстрому росту числа пользователей, создавая не решаемые быстро проблемы с масштабированием сервиса и обеспечением его производительности.
Опасаясь дальнейших проблем и не имея возможности быстро создать отдел разработки серверного ПО, IoT-операторы часто отдают разработку центральной системы на аутсорсинг, концентрируясь на самих устройствах. Но и это не решает проблемы — сторонние разработчики точно так же начинают создание системы с нуля и не имеют достаточных ресурсов и времени для внедрения в ее основу серьезных технологий.
Наша платформа AggreGate родилась в 2002-м году. В те годы мы активно занимались производством конвертеров Serial-over-IP, и нам нужен был некий центральный сервер, передающий данные между конвертерами, спрятанными за файрволлами или NAT и не имеющими возможности пообщаться напрямую. Первая версия продукта называлась LinkServer, была написана на C++ и доступна только как сервис. LinkServer просто прокачивал через себя потоки данных без какой-либо обработки.
Немного позднее наши конвертеры превратились в свободно-программируемые контроллеры. Они стали «понимать» проходящие через них данные и возникло логичное желание научить центральный сервер тому же самому. Примерно в это же время мы осознали, что 90 процентов работы по созданию системы мониторинга и управления устройствами для любой отрасли являются «изобретением велосипеда», и лишь небольшое количество усилий тратится на уникальные для конкретного бизнеса задачи.
В 2004-м году система была портирована на Java с этого момента развивалась как «фреймворк для управления устройствами». Несколько лет мы двигались практически вслепую, не до конца понимая, что именно хотим получить в результате. К великому счастью нам удалось избежать монозаказчиков, не уйти «с головой» в какую-то определенную индустрию и сохранить универсальность системы.
Сейчас платформа применяется в разных областях, таких как удаленный мониторинг и обслуживание, управление ИТ-инфраструктурами и мониторинг сетей, СКАДА и автоматизация технологических процессов, контроль физического доступа, автоматизация зданий, управление транспортным парком, управление торговыми и платежными автоматами, мониторинг сенсорных сетей, подсчет посетителей и автомобилей, централизованное управление событиями и инцидентами, управление рекламными и информационными панелями и управление мобильными устройствами.
Образно говоря, AggreGate — это конструктор «Лего» для быстрого создания интерфейсов к облаку устройств. Позволяя архитекторам IoT-решения больше концентрироваться на оборудовании и «бизнес –логике», она решает инфраструктурные задач:
Поддержание коммуникаций между серверами и устройствами в случае работы через ненадежные сотовые и спутниковые каналы связи Унификация работы с данными устройств вне зависимости от их физического смысла Хранение больших объемов собранных событий и исторических данных в БД различного типа (реляционные, кольцевые, NoSQL) Визуальное построение сложных цепочек анализа исходных данных и корреляции событий Моделирование процессов объединения данных множества устройств и вычисления KPI всей инфраструктуры Быстрое построение интерфейсов операторов и системных инженеров из готовых «кубиков», без программирования Реализация интеграционных сценариев путем использования готовых универсальных коннекторов (SQL, HTTP/HTTPS, SOAP, CORBA, SNMP, и т.д.) Являясь универсальной, платформа помогает объединять различные системы мониторинга и управления. Это позволяет избежать лишних точек интеграции и снизить количество интеграционных сценариев. Например, объединенная система мониторинга имеет единственную точку интеграции с системой Service Desk/ITSM/Maintenance Management для доставки инцидентов (тревог), а также единую интеграцию с системой Inventory/Asset Management для получения информации об имеющихся физических активах и степени их влияния на бизнес-сервисы.
Организация ролевого доступа позволяет в таких случаях обеспечить разным департаментам индивидуальные сценарии использования системы и уникальность операторского интерфейса.
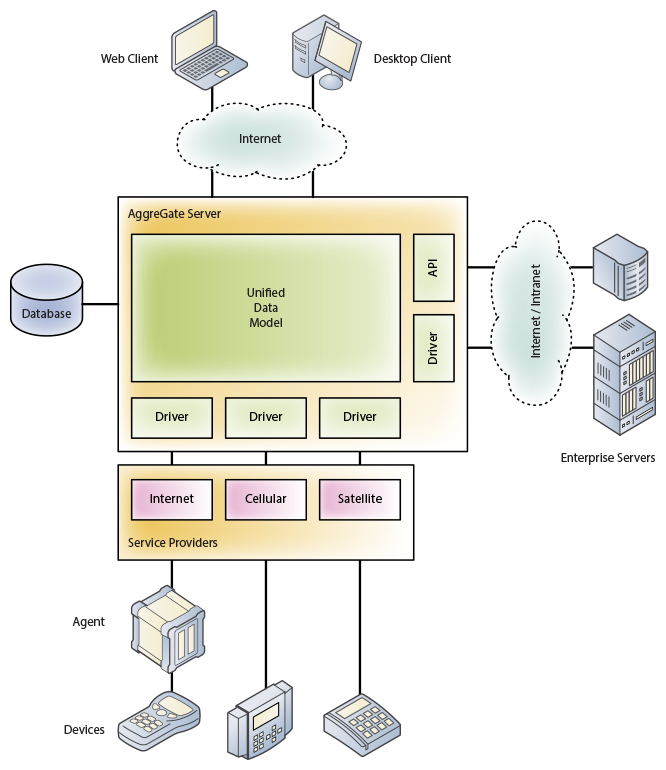
Основными компонентами платформы являются:
Сервер — Java-приложение, обеспечивающее коммуникации с устройствами, хранение данных и их автоматизированную обработку. Сервера могут объединяться в кластер для обеспечения высокой доступности и поддерживать пиринговые отношения друг с другом в распределенных инсталляциях. Сервер AggreGate управляет встроенным веб-сервером, обеспечивающим поддержку веб-интерфейсов.
Единая консоль — кросс-платформенное десктопное клиентское ПО, обеспечивающее одновременную работу с одним или несколькими серверами в режиме администратора, системного инженера или оператора.
Агент — библиотека, которая может быть внедрена в микропрограмму IoT устройства с целью обеспечения коммуникаций с серверами, унификации настройки устройства, выполнения операций с ним, и асинхронной отправки событий. Имеется множество реализаций библиотеки (Java, .NET, C/C++, Android Java, и т.д.) Внедрение агента не требуется, если коммуникации с сервером осуществляются по стандартному или проприетарному протоколу, в последнем случае для сервера разрабатывается отдельный драйвер устройства. Агент также может быть оформлен как отдельное аппаратное устройство (гейтвей).
API с открытым исходным кодом для расширения функционала всех остальных компонентов и реализации сложных сценариев интеграции
Сервер заведует чтением данных из устройств и записью изменений, этот процесс называется двухсторонней синхронизацией. На стороне сервера создается так называемый снимок устройства содержащий копии последних значений метрик устройства и изменения, произведенные операторами и системными модулями и не записанные в устройство из-за отсутствия связи. Изменения конфигурации доставляются в устройства по принципу первой возможности, позволяя производить групповые изменения конфигурации устройств не дожидаясь их одновременного появления онлайн.
Сервер также обеспечивает прием и обслуживание входящих соединений устройств, не имеющих статических «белых» IP адресов. Эта возможность является важной для IoT платформы.
Данные и события устройств становятся частью единой модели данных. В рамках этой модели, каждое устройство представлено так называемым контекстом, являющимся частью иерархической структуры контекстов. Каждый контекст включает формализованные элементы данных трех типов: переменные (свойства, настройки, атрибуты), функции (методы, операции), и события (оповещения). Контекст также содержит метаданные, описывающие все имеющиеся элементы. Таким образом, все данные и метаданные контекста полностью сосредоточены внутри него самого. Эта технология называется нормализацией устройств. Нормализованная презентация различных типов устройств создается драйверами устройств и агентами.
Можно провести параллели с объектно-ориентированным программированием, где объекты также предоставляют свойства, методы и события. Свойства — это внутренние переменные устройства, методы — это операции, которые оно может выполнять, а события — это способ устройства оповестить сервер об изменениях внутренних данных или внешней среды.
Практически каждое устройство может быть описано набором свойств, методов и событий. Например, дистанционно-контролируемый резервуар для воды может иметь свойство «уровень воды», а также методы «открыть задвижку» и «закрыть задвижку» для контроля поступления жидкости. Интеллектуальный резервуар может также генерировать оповещения, например «практически пустой», «практически полный», и «переполнение». Мы разработали более ста драйверов коммуникационных протоколов на Java и идея нормализации доказала свою состоятельность. Более того, многие современные «универсальные» протоколы (такие как OPC UA, JMX или WMI) используют очень похожие модели данных.
Все контексты сервера располагаются в иерархической структуре под названием контекстное дерево. Несмотря на то, что контексты соответствуют разным объектам (устройствам, пользователям, отчетам, тревогам и т.д.), все они имеют общий интерфейс и могут взаимодействовать внутри контекстного дерева сервера, обеспечивая высокий уровень гибкости. Тот же принцип позволяет различным серверам взаимодействовать друг с другом в рамках распределенной инсталляции.
Каждое подключенное устройство позволяет операторам производить прямую настройку (чтение и редактирование конфигурации устройства), прямое управление (ручное форсирование выполнения устройством различных операций) и прямой мониторинг (просмотр поступающих от устройства событий в логе в режиме псевдо-реального времени).
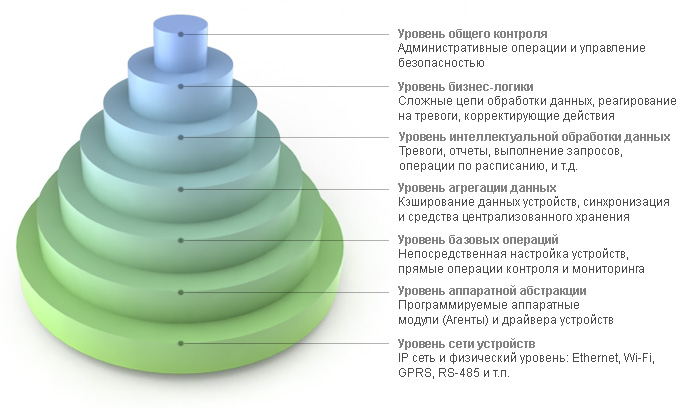
События и изменения значений метрик устройств сохраняются в хранилище сервера. В зависимости от задачи системы это может быть хранилище различных типов. Например, в случае микро-сервера работающего внутри Raspberry Pi используется простейшее файловое хранилище, а центральный сервер большой распределенной инсталляции может использовать кластер NoSQL-баз Apache Cassandra, обеспечивая сохранение десятков тысяч событий в секунду из прореженного оригинального потока в несколько сотен тысяч событий в секунду.
Тем не менее, в большинстве случаев в качестве хранилища используется обычная реляционная база данных. Использование ORM-прослойки (Hibernate) обеспечивает совместимость с MySQL, Oracle, Microsoft SQL Server, PostgreSQL и другими СУБД.
Получаемые из устройств данные и события влияют на жизненный цикл «активных» объектов сервера, позволяя ему реагировать на изменения внешней среды. К числу активных объектов относятся:
Тревоги, которые конвертируют определенное комплексное состояние объекта или определенную цепочку событий в новый тип события — Инцидент Модели, обеспечивающие при помощи бизнес-правил конвертацию исходных событий и значений в определенные пользователем типы событий и значений Планировщик, гарантирующий выполнение задач по расписанию и их выполнение даже в случае временной остановки сервера Датчики и некоторые другие типы объектов Активные объекты могут добавлять в единую модель данных новые типы переменных, функций и событий, обеспечивать отправку в хранилище изменений пользовательских переменных и событий, а также вызывать в автоматизированном режиме операции устройств и других объектов.
Для создания форм ввода данных, таблиц, динамических карт, графиков и мнемосхем существуют виджеты. Их можно объединять в инструментальные панели, как глобальные, показывающие состояние всей инфраструктуры и опирающиеся на агрегированные KPI, так и «объектовые», отображающие состояние одного устройства или компонента инфраструктуры.
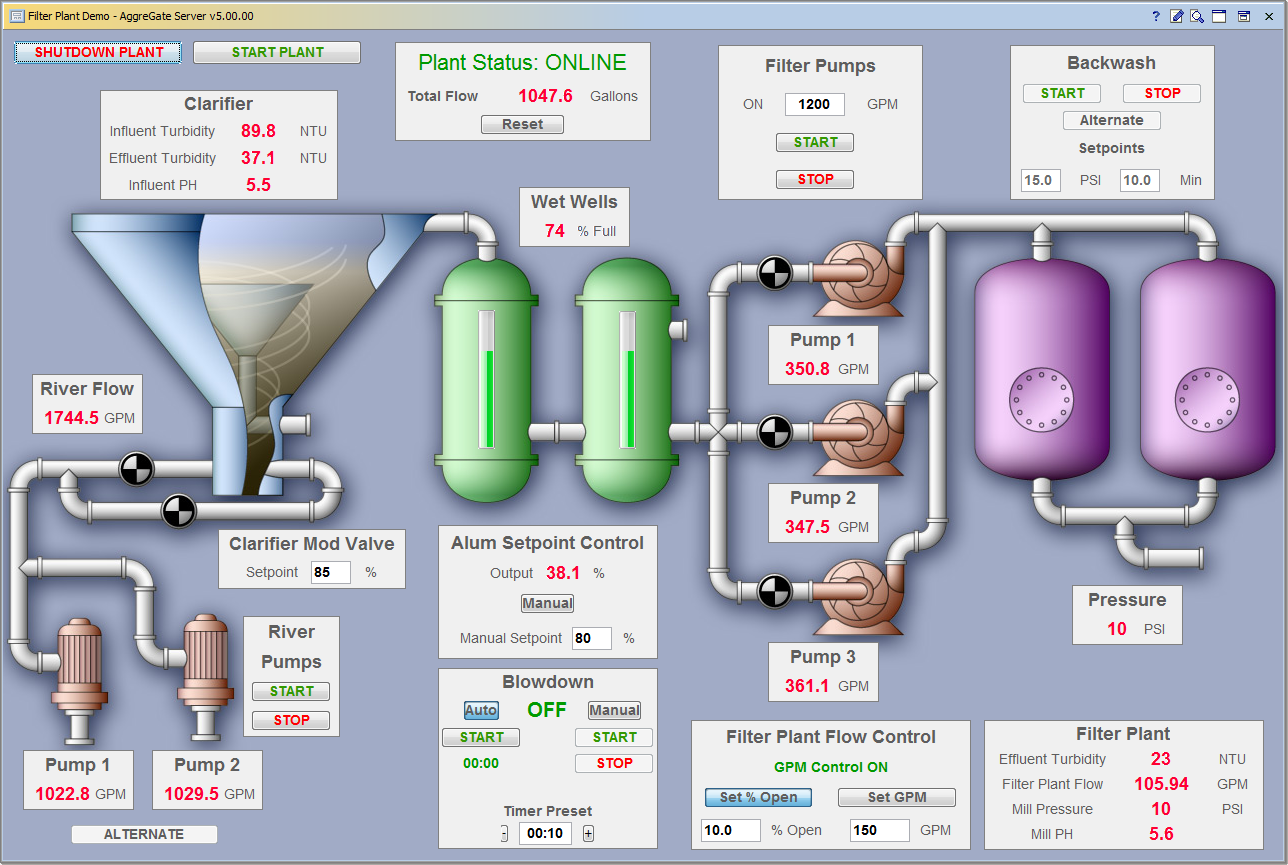
Виджеты и шаблоны отчетов редактируются в специализированных визуальных редакторах, являющихся частью платформы и тесно интегрированных в ее экосистему. Редактор виджетов позволяет строить сложные интерфейсы состоящие из множества вложенных панелей-контейнеров с располагающимися в них визуальными компонентами. В дополнение к абсолютному позиционированию, типичному для используемых в SCADA-системах редакторах, можно использовать сеточную раскладку, знакомую всем, кто сталкивался с редактированием таблиц внутри HTML-страничек. Сеточная раскладка позволяет создавать формы ввода данных и таблицы, аккуратно масштабируемые под любой размер экрана.
В результате, операторский интерфейс первой или второй линии, разработанный визуально при помощи инструментария для визуализации данных, состоит из инструментальных панелей с виджетами, формами, таблицами, диаграммами, отчетами, мнемосхемами и навигацией между ними.
Редактор интерфейсов позволяет использовать десятки готовых компонентов, таких как надписи, текстовые поля, кнопки, чекбоксы, слайдеры и спиннеры, списки, селекторы даты/времени, шкалы и указатели. Есть и более сложные компоненты, такие как деревья, видео-окна, динамические векторные SVG изображения, географические карты на основе Google Maps/Bing/Yandex/OpenStreetMap. Список типов поддерживаемых диаграмм включает как классические типа графиков, так и различные статистические графики, диаграммы Ганта, и графики в полярных координатах.
Все нарисованные в редакторе виджеты работают в веб-версии интерфейса, в том числе в браузерах без поддержки Java, т.е. на мобильных устройствах. Требуется лишь поддержка HTML5 и JavaScript.
Свойства серверных объектов (устройств, моделей, тревог) и компонентов пользовательского интерфейса соединяются друг с другом при помощи привязок, определяющих когда и откуда нужно взять данные, каким образом их обработать, и куда поместить результат. Обрабатывая данные, привязки используют язык выражений и язык запросов.
Привязка, использующая выражение, похожа на формулу в Microsoft Excel. Формула берет данные из нескольких ячеек, применяет к ним математические операции или различные функции по обработке данных, и кладет результат в текущую ячейку. Выражение также является формулой, описывающей откуда нужно взять данные и какие преобразования нужно к ним применить.
Язык запросов очень похож на обычный SQL. Он также позволяет объединять данные из различных таблиц в одну, применяя к ним фильтрацию, сортировку, группировку, и т.д. Отличие встроенного языка запросов от классического SQL в том, что вместо обычных таблиц источниками данных выступают виртуальные таблицы, формируемые «на лету» из различных данных единой модели. Любой запрос также автоматически учитывает права доступа выполняющего его оператора или системного объекта, что выгодно отличает его от прямого SQL запроса к базе данных сервера.
Для решения наиболее сложных задач по обработке данных можно написать скрипт на Java или даже отдельный плагин. Однако каждый написанный кем-то из партнеров скрипт для обработки данных является для нас тревожным звоночком — зачем нужна платформа, если все равно требуется классическая разработка, да еще и вне привычной среды (такой как Eclipse или Idea)?
Отдельно хочется рассказать про техническое устройство распределенной архитектуры. В рамках этой концепции настраиваются пиринговые отношения между серверами таким образом, что один сервер («поставщик») присоединяет часть своей единой модели данных к другому серверу («потребителю»). Это позволяет объектам сервера-потребителя взаимодействовать с объектами сервера-поставщика наравне со своими собственными. Количество связей одного сервера не ограничено, причем он может одновременно выступать поставщиком и потребителем по отношению к своим соседям.
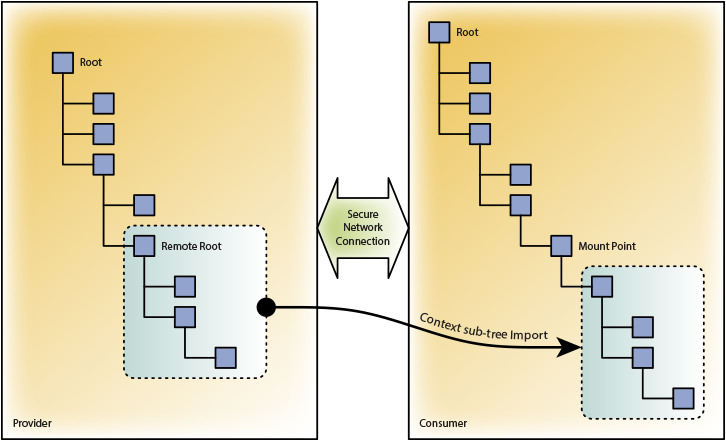
Распределенная архитектура позволяет решать многие задачи больших систем:
Горизонтальное масштабирование системы Распределенный мониторинг с установкой локальных серверов мониторинга и промежуточного хранения данных на удаленных площадках Вертикальное масштабирование, распределение функций между серверами на несколько логических уровней Этот пост — наш дебют на хабре. В следующих статьях мы планируем рассказать побольше о внутреннем устройстве платформы, наших собственных решениях, созданных на ее основе, а также нашем представлении о том, как «тяжелый PCшный софт» будет пробираться внутрь встраиваемых систем и устройств Интернета вещей.
P.S. Если вы занимаетесь разработкой серверного ПО для Интернета вещей, ответьте пожалуйста на вопрос ниже.
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
