Когда старый MapReduce лучше нового Tez

Как всем известно, количество данных в мире растёт, собирать и обрабатывать поток информации становится всё сложнее. Для этого служит популярное решение Hadoop c идеей упрощения методов разработки и отладки многопоточных приложений, использующее парадигму MapReduce. Эта парадигма не всегда удачно справляется со своими задачами, и через некоторое время появляется «надстройка» над Hadoop: Apache Tez с парадигмой DAG. Под появление Tez подстраивается и HDFS-SQL-обработчик Hive. Но не всегда новое лучше старого. В большинстве случаев HiveOnTez значительно быстрее HiveOnMapReduce, но некоторые подводные камни могут сильно повлиять на производительность вашего решения. Здесь я хочу рассказать, с какими нюансами столкнулся. Надеюсь, это поможет вам ускорить ETL или другой Hadoop UseCase.
Как я сказал ранее, данных в мире всё больше и больше. И для их хранения и обработки придумывают всё более хитрые решения, среди них и Hadoop. Чтобы процесс обработки хранящихся на HDFS данных был прост даже для рядового аналитика, есть несколько SQL-надстроек над Hadoop. Самая старая и «простая» из них — Hive. Суть Hive такова: мы имеем данные в каком-либо внятном column-store формате, заносим информацию о них в метаданные, пишем стандартный SQL с рядом ограничений, и он генерирует цепочку MapReduce-job«ов, которые решают нашу задачу. Здорово, удобно, но медленно. Например, вот простой запрос:
select
t1.column1,
t2.column2
from
table1 t1
inner join table2 t2 on t1.column1 = t2.column1
union
select
t3.column1,
t4.column2
from
table3 t3
inner join table4 t4 on t3.column1 = t4.column1
order by
column1;
Этот запрос порождает четыре джоба:
- table1 inner join table2;
- table3 inner join table4;
- union;
- sort.

Шаги выполняются последовательно, и каждый из них завершается записью данных на HDFS. Это выглядит весьма неоптимальным. Например, шаги 1 и 2 могли бы выполняться параллельно. А бывают и такие ситуации, когда у нескольких шагов разумно применить один и тот же Mapper, а потом уже на результаты этих Mapper«ов наложить несколько видов Reducer«ов. Но концепция MapReduce в рамках одного job«а не позволяет так делать. Для решения этой проблемы достаточно быстро появляется Apache Tez с концепцией DAG. Суть DAG сводится к тому, что вместо пары Mapper-Reducer (+epsilon) мы строим нецикличный направленный граф, каждая вершина которого является Mapper.Class«ом или Reduser.Class«ом, а ребра означают потоки данных / порядок выполнения. Кроме DAG, Tez предоставил еще несколько бонусов: ускоренный запуск job«ов (можно посылать DAG-job«ы через уже запущенный Tez-Engine), возможность удерживать ресурсы в памяти ноды между шагами, самостоятельно запускать распараллеливание и т. д. Естественно, вместе с Tez вышла и соответствующая надстройка над Hive. С этой надстройкой наш запрос превратится DAG-job примерно следующей структуры:
- Mapper считывает table1.
- Mapper считывает table2 и джойнит её с результатом шага 1.
- Mapper считывает table3 и фильтрует column1 IS NOT NULL.
- Mapper считывает table4 и фильтрует column1 IS NOT NULL.
- Reducer джойнит результаты шагов 3 и 4.
- Reducer, делающий union.
- Reducer Group By и Sort.
- Собирает результат.
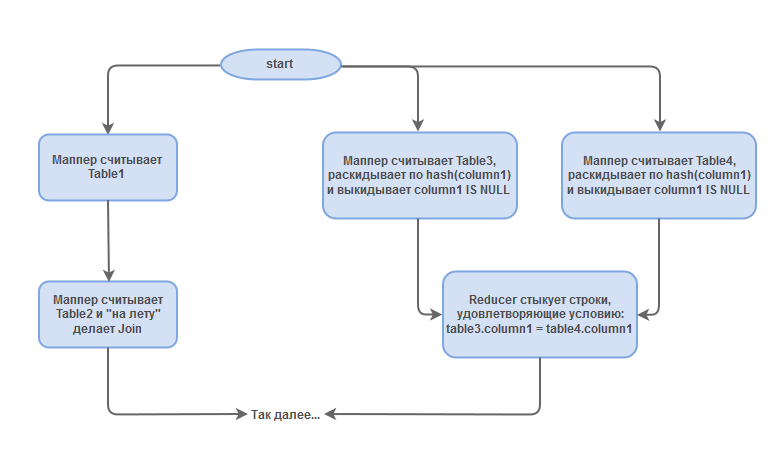
Фактически шаги 1 и 2 — это первый join, а 2, 3 и 4 — это второй join (я специально подобрал таблицы разных размеров, чтобы join«ы обрабатывались по-разному). При этом два блока друг от друга не зависят и могут выполняться параллельно. Это уже очень здорово. Tez действительно даёт значительный прирост в скорости обработки сложных запросов. Но иногда Tez может быть хуже MapReduce, и поэтому перед отправкой в production стоит попробовать запрос как с set hive.execution.engine=tez, так и с set hive.execution.engine=mr.
Всё, что надо знать о Tez: он меняет логику MapReduce на логику DAG (directed acyclic graph — направленного ациклического графа), предоставляя возможность в рамках одного DataFlow параллельно выполнять несколько разных процессов, будь то Mapper или Reducer. Главное, чтобы его входные данные были готовы. Хранить данные можно локально на нодах между шагами, а иногда и просто в оперативной памяти ноды, не прибегая к дисковым операциям. Можно оптимизировать количество и местоположение Mapper«ов и Reducer«ов, чтобы минимизировать передачу данных по Сети даже с учётом многошаговых расчётов, переиспользовать контейнеры, которые уже отработали в соседних процессах в рамках одного Tez-Job«а, и подстраивать параллельное выполнение под статистику, собранную на предыдущем шаге. Кроме того, движок позволяет конечному пользователю создавать DAG-задачи с той же простотой, что и MapReduce, при этом он сам будет заниматься ресурсами, перезапусками и управлением DAG на кластере. Tez очень мобилен, добавление поддержки Tez не ломает уже работающие процессы, а тестирование новой версии возможно локально «на клиентской стороне» тогда, когда во всех задачах кластера будет работать старая версия Tez. Last but not least: отметим, что Tez может запускаться на кластере как служба и работать в «фоновом режиме», что позволяет ему отправлять задачи на выполнение значительно быстрее, чем это происходит при стандартном запуске MapReduce. Если вы ещё не пробовали Tez и у вас остались сомнения, то посмотрите на сравнение скорости, опубликованное в презентации HortonWorks:

И в паре с Hive:

Но при всей этой красоте графиков и описаний в HiveOnTez есть и проблемы.
Tez менее устойчив к неравномерному распределению данных, чем MapReduceПервая и самая большая проблема лежит в разнице создания DAG-job и MapReduce-job. У них один принцип: количество Mapper«oв и Reducer«ов рассчитывается в момент запуска job«а. Только когда запрос выполняется цепочкой MapReduce-job«ов, Hadoop рассчитывает необходимое количество задач на основе результата предыдущих шагов и собранной аналитики по источникам, а в случае DAG-job это происходит до вычисления всех шагов, только на основе аналитики.
Поясню на примере. Где-то в середине запроса по мере выполнения вложенных запросов у нас появляются две таблицы. По оценкам статистики, в каждой по n строк и по k уникальных значений join-ключа. На выходе ожидаем примерно n*k строк. И допустим, это количество хорошо укладывается в один контейнер, и Tez выделит на следующий шаг (допустим, сортировка) один Reducer. И это число Reducer«ов уже в процессе выполнения не поменяется независимо ни от чего. Теперь допустим, что на самом деле у этих таблиц очень плохой skew: на одно значение приходится n — k + 1 строка, а все остальные — по одной строке. Таким образом, на выходе мы получим n^2 + k^2 — 2kn — k + 2n строк. То есть (n + 2 — 2k)/k + (k — 1)/n больше n/k в два раза. И уже такое количество один Reducer будет выполнять вечность. А в случае с MapReduce, получив на выходе этого шага n^2 + k^2 — 2kn — k + 2n, Hadoop объективно оценит свои силы и выдаст нужное количество Mapper«ов и Reducer«ов. В результате c MapReduce всё отработает гораздо быстрее.
Сухие вычисления могут показаться надуманными, но на самом деле такая ситуация реальна. И если её не произошло, то считайте, что вам повезло. С аналогичным эффектом Tez-DAG«а я сталкивался ещё при использовании lateral view в сложных запросах или кастомных Mapper«ах.
Особенности тюнинга TezПо иронии, последняя известная мне важная особенность Tez, которая может навредить, связана с его силой — DAG. Чаще всего кластер — это не просто хранилище информации. Это еще и система, в которой ведётся постобработка данных, и важно, чтобы на эту часть кластера не влияла остальная деятельность. Так как ноды — это ресурс, то обычно количество ваших контейнеров не безгранично. А значит, когда вы запускаете job, то лучше не забивать все контейнеры, чтобы сильно не тормозить регулярные процессы. И тут DAG может подложить вам свинью. DAG требуется (в среднем по палате) меньше контейнеров за счёт их переиспользования, более плавной нагрузки и т. д. Но когда быстрых шагов много, контейнеры начинают размножаться в геометрической прогрессии. Первые Mapper«ы ещё не доработали, но данные уже распространяются по другим Mapper«ам, под всё это выделяются контейнеры, и — бум! Ваш кластер забит в потолок, никто больше не может запустить ни одного job«а. Ресурсов не хватает, и вы смотрите, как медленно меняются цифры на прогресс-баре. MapReduce из-за своей последовательности от такого эффекта избавлен, но платите вы за это, как всегда, скоростью.
Мы давно знаем, как бороться с тем, что стандартный MapReduce занимает слишком много контейнеров. Регулируем параметры:
mapreduce.input.fileinputformat.split.maxsize: уменьшая — увеличиваем количество Mapper«ов;mapreduce.input.fileinputformat.split.minsize: увеличивая — уменьшаем количество Mapper«ов;mapreduce.input.fileinputformat.split.minsize.per.node,mapreduce.input.fileinputformat.split.minsize.per.rack: более тонкая настройка для контроля локальных (в смысле node или rack) партиций;hive.exec.reducers.bytes.per.reducer: увеличивая — уменьшаем количество Reducer«ов;mapred.tasktracker.reduce.tasks.maximum: выставляем максимальное количество Reducer«ов;mapred.reduce.tasks: задаём конкретное число Reducer«ов.
Осторожно! В DAG все reduce-шаги будут иметь столько процессов, сколько вы укажете тут! Но параметры Tez более хитрые, и не всегда параметры, которые мы задали для MapReduce, на него действуют. Во-первых, Tez очень чувствителен к
hive.tez.container.size, и интернет советует брать значение между yarn.scheduler.minimum-allocation-mb и yarn.scheduler.maximum-allocation-mb. Во-вторых, взгляните на параметры удержания неиспользуемого контейнера: tez.am.container.ide.release-timeout-max.millis;tez.am.container.ide.release-timeout-min.millis.
Опция
tez.am.container.reuse.enabled активирует или дезактивирует переиспользование контейнеров. Если она отключена, то предыдущие два параметра не работают. И в-третьих, посмотрите на параметры группировки: tez.grouping.split-waves;tez.grouping.max-size;tez.grouping.min-size.
Дело в том, что ради распараллеливания чтения внешних данных Tez изменил процесс формирования задач: сначала Tez оценивает, сколько волн (w) можно запустить на кластере, потом это количество умножается на параметр
tez.grouping.split-waves, и произведение (N) делится на количество стандартных сплитов на задачу. Если результат действий находится между tez.grouping.min-size и tez.grouping.max-size, то всё хорошо и задача запускается в N задач. Если нет, то число адаптируется к рамкам. Документация по Tez советует «только в качестве эксперимента» выставлять параметр tez.grouping.split-count, который отменяет всю вышеизложенную логику и группирует сплиты в указанное в параметре количество групп. Но я этим свойством стараюсь не пользоваться, оно не дает гибкости Tez«у и Hadoop«у в целом для оптимизации под конкретные входные данные.Нюансы TezКроме крупных проблем, Tez не избавлен от маленьких недостатков. Например, если вы пользуетесь http Hadoop ResourceManager«ом, то вы не увидите в нём, сколько какой Tez-job занимает контейнеров, а тем более — в каком состоянии его Mapper«ы и Reducer«ы. Для мониторинга состояния кластера я использую этот маленький python-скрипт:
import os
import threading
result = []
e = threading.Lock()
def getContainers(appel):
attemptfile = os.popen("yarn applicationattempt -list " + appel[0])
attemptlines = attemptfile.readlines()
attemptfile.close()
del attemptlines[0]
del attemptlines[0]
for attempt in attemptlines:
splt = attempt.split('\t');
if ( splt[1].strip() == "RUNNING" ):
containerfile = os.popen("yarn container -list " + splt[0] )
containerlines = containerfile.readlines()
containerfile.close()
appel[2] += int( containerlines[0].split("Total number of containers :")[1].strip() )
e.acquire()
result.append(appel)
e.release()
appfile = os.popen("yarn application -list -appStates RUNNING")
applines = appfile.read()
appfile.close()
apps = applines.split('application_')
del apps[0]
appsparams = []
for app in apps:
splt = app.split('\t')
appsparams.append(['application_' + splt[0],splt[3], 0])
cnt = 0
threads = []
for app in appsparams:
threads.append(threading.Thread(target=getContainers, args=(app,)))
for thread in threads:
thread.start()
for thread in threads:
thread.join()
result.sort( key=lambda x:x[2] )
total = 0
for app in result:
print(app[0].strip() + '\t' + app[1].strip() + '\t' + str(app[2]) )
total += app[2]
print("Total:",total)
Несмотря на заверения HortonWorks, наша практика показывает, что когда в Hive вы делаете простой SELECT smth FROM table WHERE smth, то чаще всего MapReduce отработает быстрее, правда, ненамного. К тому же в начале статьи я вас немного обманул: распараллеливание в HiveOnMapReduce возможно, но не такое интеллектуальное. Достаточно только сделать
set hive.exec.parallel=true и настроить set hive.exec.parallel.thread.number=… — и независимые шаги (пары Mapper + Reducer) будут выполняться параллельно. Да, в нём нет возможности, что на выходе одного Mapper«а будет запускаться несколько Reducer«ов или следующих Mapper«ов. Да, распараллеливание куда более примитивно, но тоже ускоряет работу.Ещё одна интересная особенность Tez: он запускает свой движок на кластере и держит его включённым некоторое время. С одной стороны, это действительно ускоряет работу, так как задача запускается на нодах значительно быстрее. Но с другой стороны — неожиданный минус: важные процессы в таком режиме запускать нельзя, потому что TEZ-engine со временем порождает слишком много классов и падает с GC-overflow. И бывает так: вы запустили на ночь nohup hive -f ....hql > hive.log &, пришли утром, а оно где-то посередине упало, хайв завершился, temporary tables удалились, и всё надо считать заново. Неприятно.
Добавляет в копилку мелких проблем то, что старый добрый MapReduce уже вошёл в стабильный релиз, а TEZ, несмотря на популярность и прогрессивность, до сих пор находится в версии 0.8.4, и баги в нём могут встретиться на любом шагу. Самый страшный баг для меня — это удаление информации, но такого я не встречал. А вот с некорректным расчётом на Tez мы сталкивались, причём MapReduce считает корректно. Например, мой коллега использовал две таблицы — table1 и table2, имеющие уникальное поле EntityId. Сделал через Tez запрос:
select
table1.EntityId, count(1)
from
table1
left join table2 on table1.EntityId = table2.EntityId
group by
EntityId
having
count(1) > 1
И получил на выходе какие-то строки! Хотя MapReduce ожидаемо вернул пустой результат. Про похожую проблему есть bugreport.Заключение
Tez — безусловное благо, которое в большинстве случаев делает жизнь проще, позволяет писать в Hive более сложные запросы и ожидать на них быстрого ответа. Но, как и любое благо, оно требует к себе осторожного подхода, осмотрительности и знания каких-то нюансов. И как следствие, иногда использование старого, проверенного, надёжного MapReduce лучше, чем использование Tez. Я очень удивился, что не смог найти ни одной статьи (ни в рунете, ни в инглишнете) о минусах HiveOnTez, и решил восполнить этот пробел. Надеюсь, что информация окажется кому-то полезной. Спасибо! Всем удачи и пока!
