Когда и CRA мало. Доклад Яндекса
За интерфейсами поиска Яндекса скрывается большой проект со сложной инфраструктурой. У нас десятки мегабайт кода, который должен быстро работать и быстро собираться. Когда нам понадобилось перевести проект на React и TypeScript, мы начинали с Create React App, CRA. И достаточно быстро поняли, что многое нужно дорабатывать.
В докладе на Я.Субботнике Pro я вспомнил, что и как мы доделывали в сборке и архитектуре «стандартного современного проекта» и какие результаты у нас получились.
— В последние полтора года я работаю в команде архитектуры Серпа. Мы там разрабатываем runtime и сборку нового кода на React и TypeScript.
Давайте поговорим о нашей общей боли, которой будет посвящен этот доклад. Когда вы хотите сделать маленький проект на React, вам достаточно использовать стандартный набор инструментов, которые называются тремя буквами — CRA. Сюда входят скрипты сборки, скрипты для прогона тестов, настройки dev-окружения и для продакшена тоже уже все сделано. Все делается очень просто через NPM-скрипты, и все про это, наверное, знают, кто имел опыт работы с React.
Но предположим, проект становится большой, у него становится много кода, много разработчиков, появляются продакшен-особенности, такие как переводы, про которые Create React App ничего не знает. Или у вас какой-нибудь сложный конвейер CI/CD. Тогда начинаются мысли сделать eject, чтобы использовать Create React App как основу и донастроить под ваш собственный проект. Но абсолютно не понятно, что там ждет, за этим eject. Потому что когда вы делаете eject, там пишется, что это очень опасная операция, нельзя будет вернуть назад и прочее, очень страшное. Те, кто нажимали eject, знают, что там вываливается очень много конфигов, в которых надо разбираться. В общем, очень много рисков, и непонятно, что делать.
Расскажу, как было у нас. Для начала про наш проект. Наш фронтенд-проект — это Серп, Search Engine Results Pages, страницы поисковых результатов Яндекса, которые все видели. С 2018 года мы переезжаем не React и TypeScript. На Серпе в прошлом году уже было написано порядка 12 мегабайт кода. Здесь немножечко стилей и очень много TS- и SCSS-кода. Сколько в начале, в 2018 году, было, я не стал писать, там совсем мало, очень резкий скачок был.
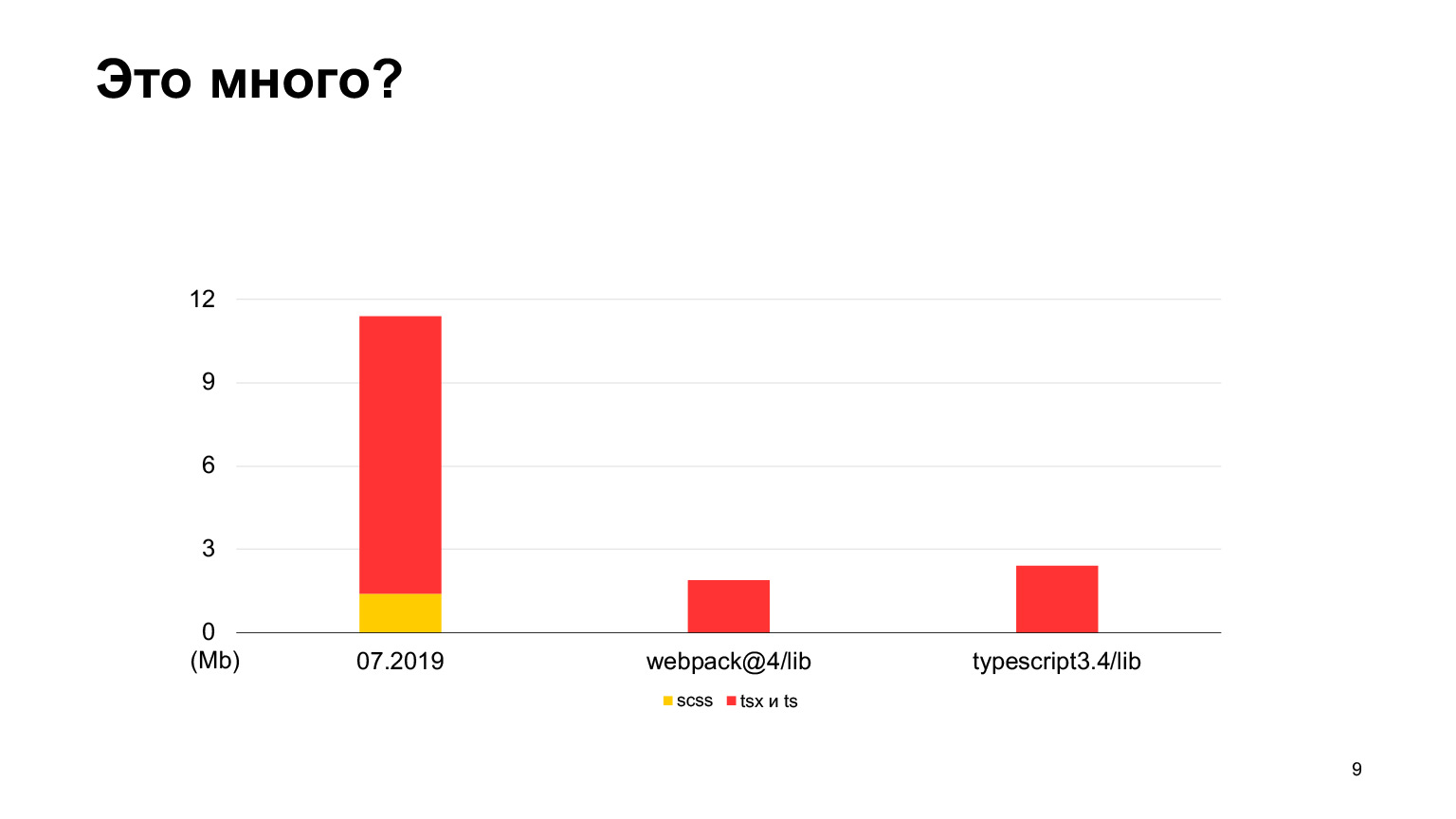
Давайте разберемся, много это кода или мало. Если сравнить с исходным кодом webpack-4, то в webpack-4 гораздо меньше кода. Даже в репозитории TypeScript меньше кода.
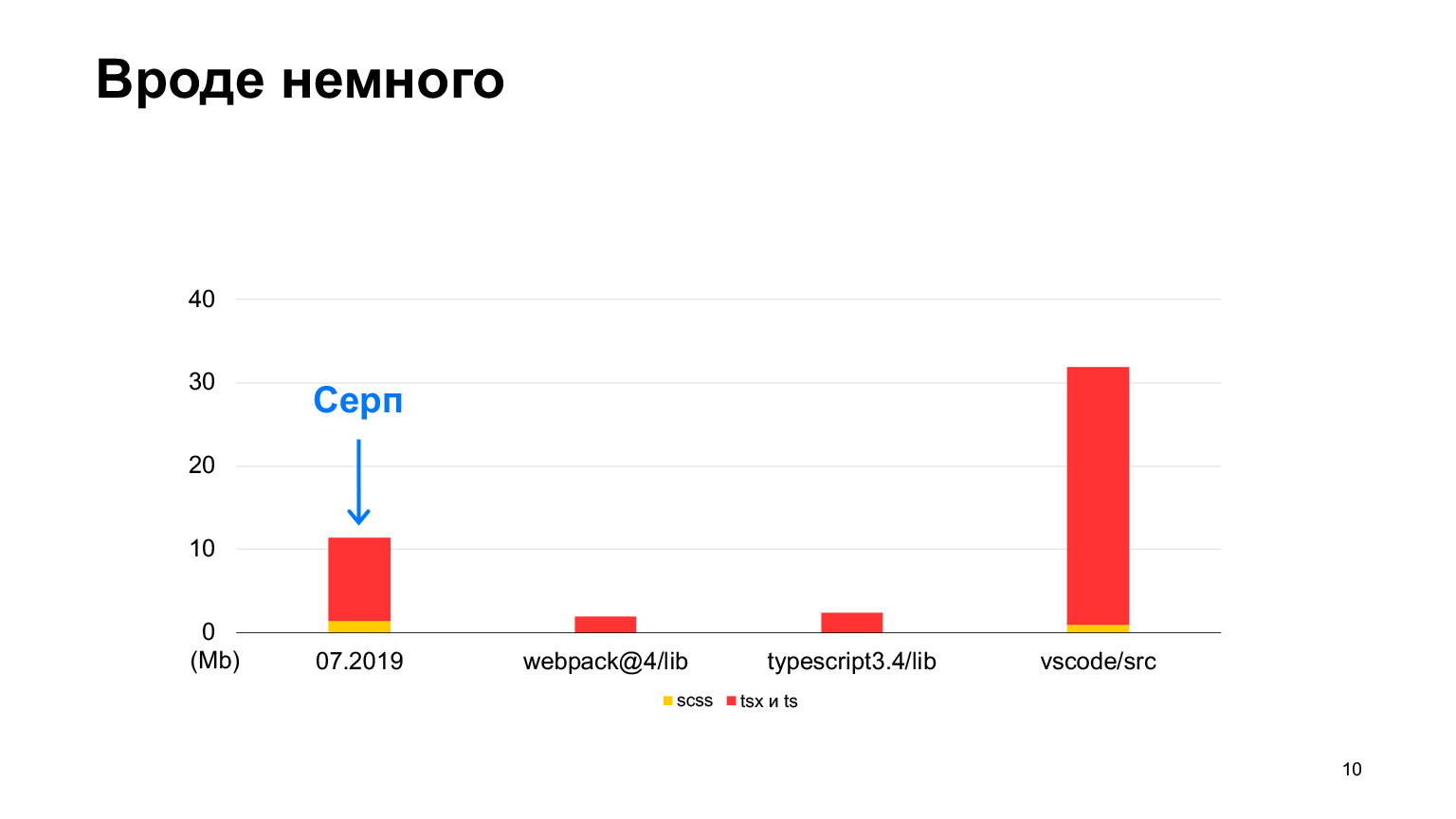
А вот в vs-code больше кода, хороший проект, в котором аж 30 мегабайт TypeScript-кода. Да, он тоже написан на TypeScript, и Серп кажется поменьше. В 2018-м мы начали, в 2019-м было 12 мегабайт, и 70 наших разработчиков работали, делали по 100 влитых пул-реквестов в неделю. За один год они утроили этот размер, получили ровно 30 мегабайт. Я делал замеры в этом месяце, всего у нас кода сейчас на 30 мегабайт, и это уже больше, чем в vs-code.
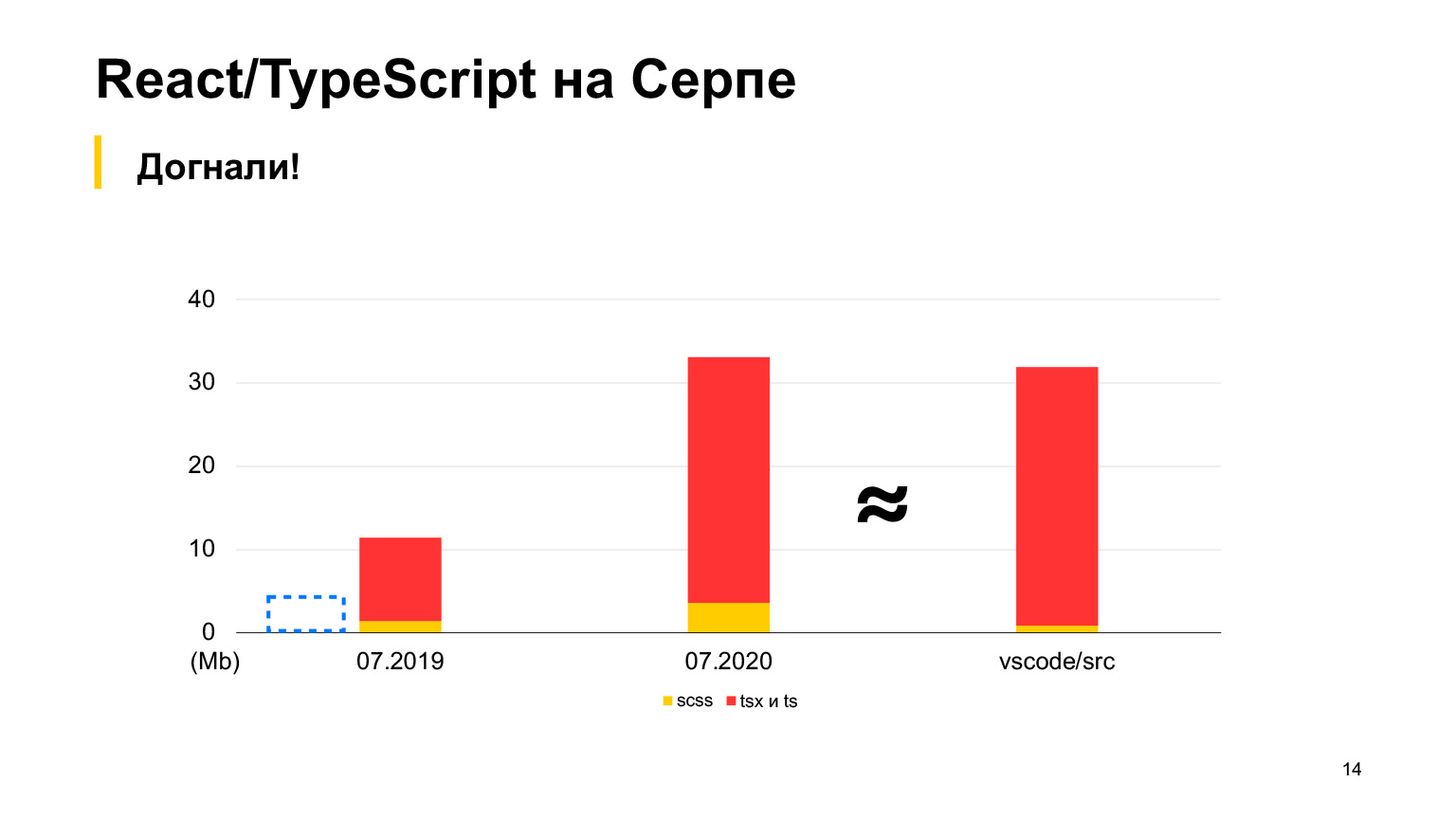
Примерно равно, но чуть больше. Вот такого порядка у нас проект.
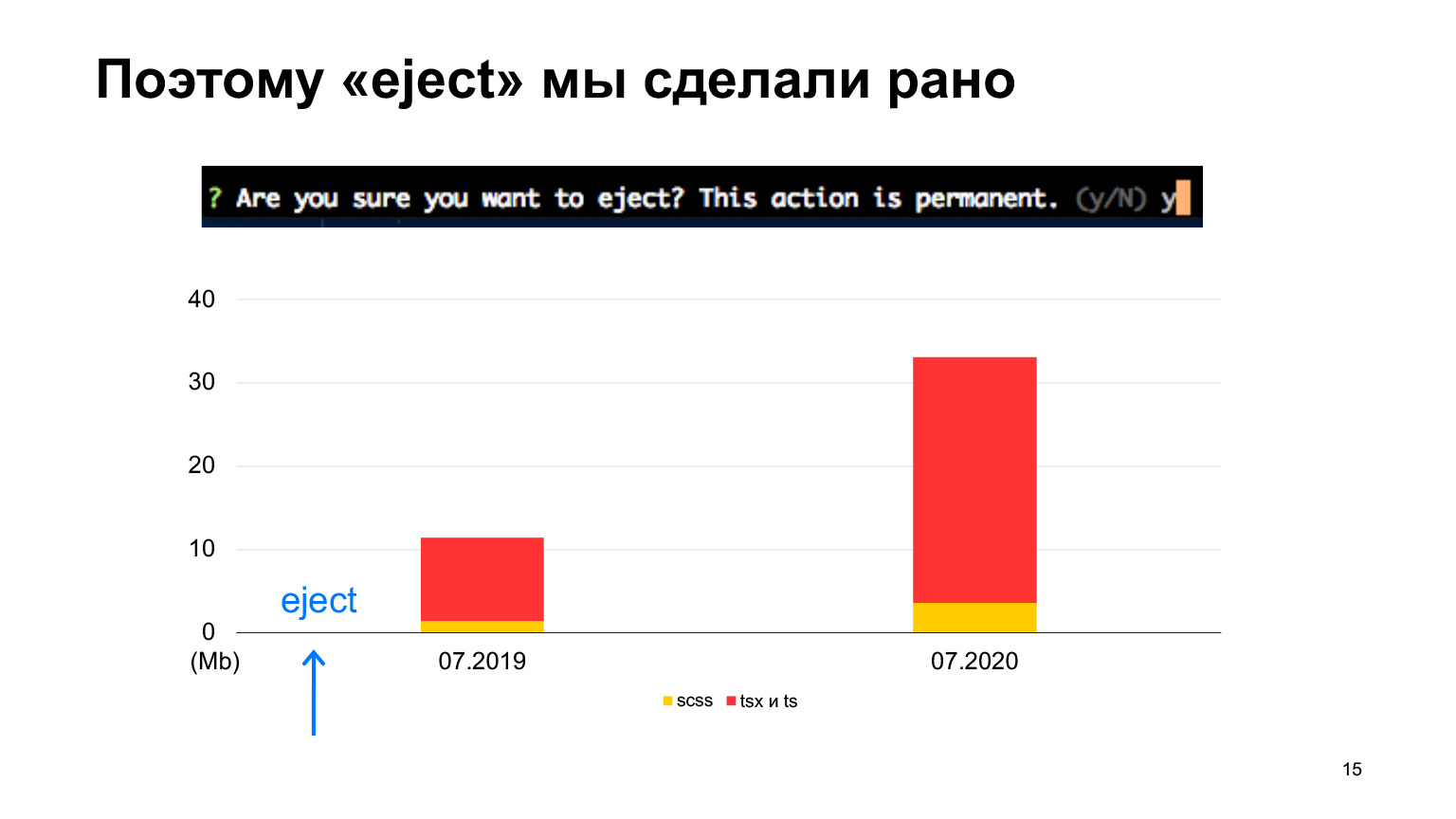
И eject мы сделали в самом начале, потому что сразу знали, что кода у нас будет много и, скорее всего, исходные конфиги, которые есть в Create React App, нам не подойдут. Но начинали мы точно так же, с Create React App.
Так вот, о чем будет рассказ. Мы хотим поделиться опытом, рассказать, что пришлось сделать с Create React App, чтобы Серп Яндекса на нем нормально заработал. То есть, как мы получали быструю загрузку и инициализацию в браузере, и как мы при этом старались не замедлить сборку, какие настройки, плагины и прочие вещи мы использовали для этого. И естественно, результаты, которых у нас получилось добиться, будут в конце.

Как мы рассуждали? Исходная идея была такая, что Серп у нас — это такая страница, которая должна очень быстро отрисовываться, потому что, в основном, там очень простые текстовые результаты, поэтому нам необходима серверная шаблонизация, потому что это единственный способ получить быструю отрисовку. То есть мы еще до того, как что-то начало инициализироваться на клиенте, мы уже должны что-то нарисовать.
При этом хотелось сделать минимальный размер статики, чтобы не грузить ничего лишнего и инициализация тоже происходила быстро. То есть мы хотим и первую отрисовку быструю, и инициализацию быструю.

Что нам предлагает Create React App? К сожалению, он нам не предлагает ничего про серверный рендеринг.
Там прямо так и написано, что серверный рендеринг не поддерживается в Create React App. Кроме того, в Create React App есть всего один entry на все приложение. То есть по умолчанию собирается один большой бандл на все ваше огромное разнообразие страниц. Это очень много. Понятно, что из 30 мегабайт примерно половина TS-типов, но все равно кода очень много поедет сразу в браузер.
При этом в Create React App есть некоторые хорошие настройки, например, runtime вебпачный там в отдельном чанке едет. Отдельно загружается, может быть закэширован, потому что он не меняется обычно.
Кроме того, модули из node_modules тоже в отдельных чанках собираются. Они тоже редко меняются, и поэтому они тоже кэшируются браузером, это здорово, это надо сохранить. Но в то же время в Create React App нет ничего про переводы.
Соберем наш список, как в нашем случае должен был бы выглядеть список возможностей у нашей платформы. Во-первых, мы хотим северный рендеринг, как я уже сказал, чтобы сделать быструю отрисовку. Кроме того, мы хотели бы получить отдельный entry-файл для каждого поискового результата.

Если, например, на Серпе есть калькулятор, то мы бы хотели, чтобы был доставлен бандл с калькулятором, а бандл с переводчиком не нужно быстро доставлять. Если же это у нас все собирается в один большой бандл, то всегда все поедет, даже если на конкретной выдаче половины из этих вещей нет.
Дальше общие модули хотелось бы в отдельных чанках поставлять, чтобы не загружать то, что уже загружено.
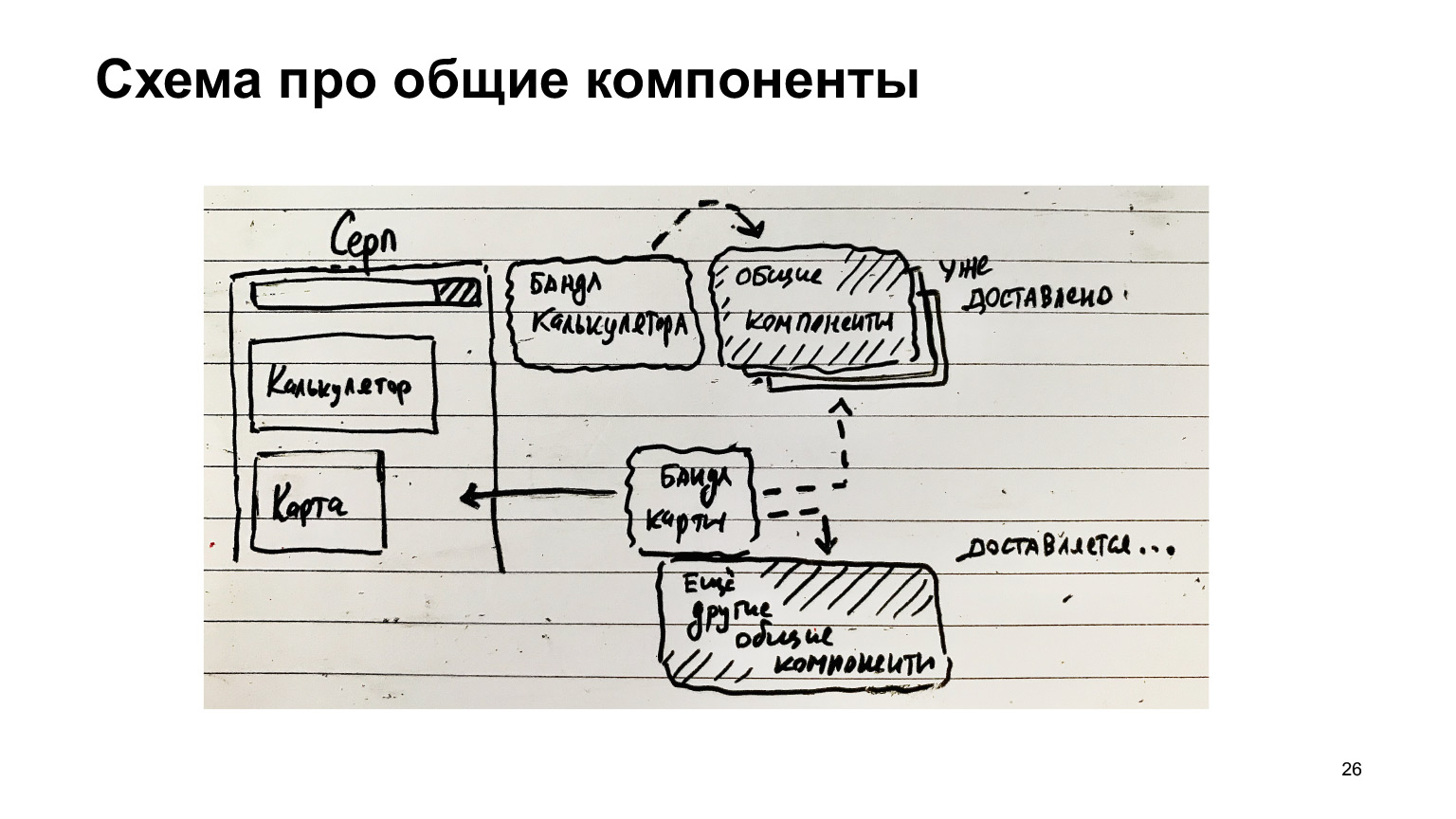
Вот еще пример с Серпом. На нем есть калькулятор, есть бандл калькулятора. Есть общие компоненты. Они были доставлены на клиента. Потом появилась еще фича — карта. Поехал бандл карты, и поехали другие общие компоненты, за вычетом тех, которые уже были доставлены.
Если компоненты общие собирать отдельно, то появляется такая замечательная возможность для оптимизации и доставляется только то, что надо, только diff. И самые популярные модули, которые всегда бывают на странице, например, runtime вебпачный, который всегда нужен вот этой всей инфраструктуре, его нужно загружать всегда.
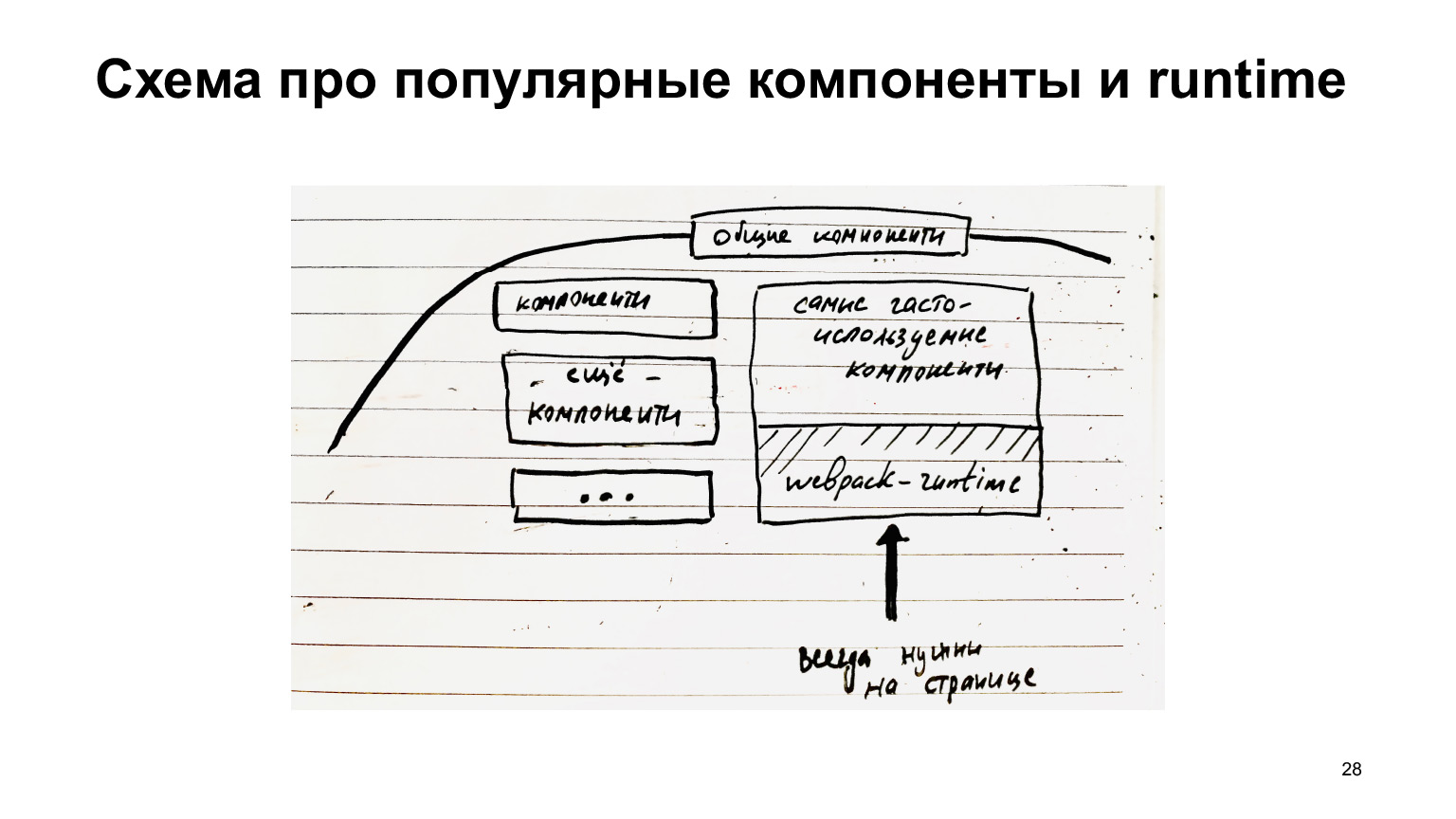
Поэтому есть смысл собирать в отдельном чанке. То есть вот эти общие компоненты можно тоже разбить на те компоненты, которые не всегда нужны, и компоненты, которые всегда нужны. Их можно собирать в отдельный файлик и загружать всегда, и тоже кэшировать, потому что эти общие компоненты, типа кнопок/ссылок, не так уж часто изменяются, в общем, получить профит от кэширования.

И при этом нужно сделать решение про сборку переводов.

Здесь все достаточно понятно. Если мы заходим на турецкий Серп, мы хотели бы загружать только турецкие переводы, а все остальные переводы не загружать, потому что это лишний код.
Что мы делали? Сначала по поводу серверного кода. По поводу него у нас будет два направления — сборка для продакшена и запуск для dev.
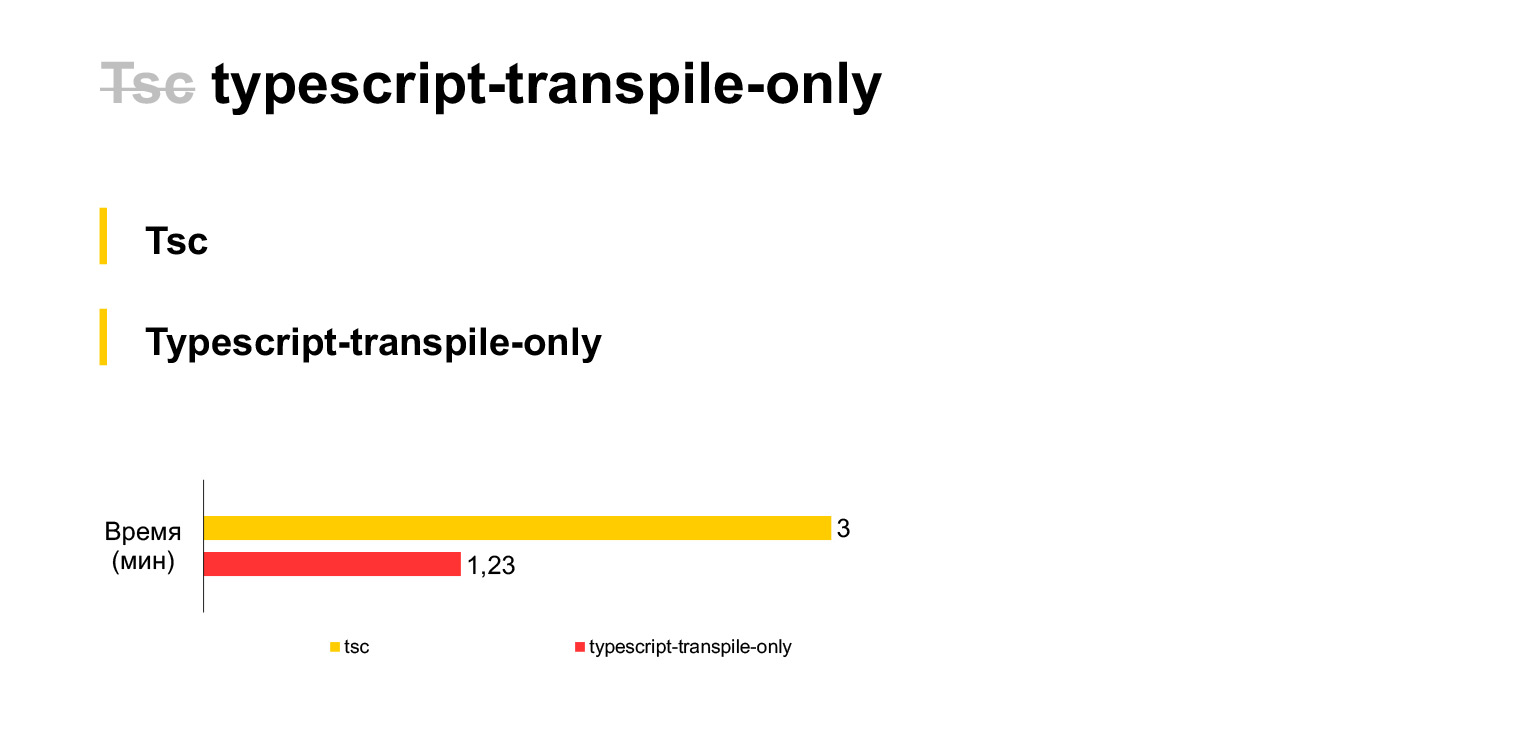
Вообще про TypeScript нужно сначала сделать такое отдельное заявление. Обычно в проектах, как я слышал, используют babel. Но мы сразу решили использовать стандартный TypeScript компилятор, потому что верили, что в него новые фичи TypeScript доезжают быстрее. Поэтому мы от babel сразу отказались и использовали tsc.
Так вот, этот наш текущий размер кода, вот эти наши 30 мегабайт компилируются на ноутбуке за три минуты. Довольно много. Если отказаться от проверки типов, во время каждой компиляции использовать форк tsc (к сожалению, у TSC нет настройки, которая бы отключала проверку типов, пришлось использовать форк), то время можно сэкономить в два раза. Всего полторы минуты будет занимать компиляция нашего кода.
Почему мы можем не проверять типы при компиляции? Потому что мы, например, можем проверять их в pre-commit-хуках. Сделать линтер, который будет запускать только проверку типов, а саму сборку можно делать без проверки типов. Такое решение мы приняли.
Как мы запускаем в dev? В dev обычно тоже используется связка babel с webpack, но мы используем такой инструмент, как ts-node.

Это очень простой инструмент. Для того чтобы его запустить, достаточно во входном JavaScript файле написать вот такой require (ts-node), и он переопределит require-ы всего TS-кода далее в этом процессе. И если по ходу в этот процесс загружается TS-код, то он будет на лету компилироваться. Очень простая штука.
Естественно, здесь есть небольшие накладные расходы, связанные с тем, что если файл еще не был загружен в этом процессе, то его надо перекомпилировать заново. Но на деле эти накладные расходы минимальны и, в общем, приемлемы.
Кроме того, в этом листинге есть еще несколько интересных строчек. Первое — игнорирование стилей, потому что стили нам не нужны при серверной шаблонизации. Нам нужно только HTML получить. Поэтому используем еще вот такой модуль — ignore-styles. И, кроме того, мы отключаем точно также проверку типов (transpile-only), как мы и делали в TSC для того, чтобы ускорить работу ts-node.
Переходим к клиентскому коду. Как мы собираем ts-код в webpack? Мы используем ts-loader и опцию transpileOnly, то есть примерно та же самая связка. Вместо babel-loader более-менее стандартные инструменты ts-loader и transpileOnly.
Но к сожалению, в ts-loader не работает инкрементальная сборка. То есть все-таки ts-loader не совсем стандартный инструмент, и его не делают те же ребята, которые делают TypeScript. Поэтому не все опции компилятора там поддержаны. Вот например, инкрементальная сборка не поддержана.
Инкрементальная сборка это такая штука, которая может быть очень полезна при разработке. Точно также можно эти кэши и в конвейер добавить. В общем, когда ваши изменения небольшие, можно не целиком все перекомпилировать, весь TypeScript, а только то, что поменялось. Это достаточно эффективно работает.
В общем, чтобы обойтись без инкрементальной сборки, мы используем cache-loader. Это стандартное решение из webpack. Вполне все понятно. Когда пытается подключиться во время вебпачной сборки TypeScript-код, он обрабатывается компилятором, складывается в кэш, и в следующий раз, если изменений не было в исходных файлах, то cache-loader не запустит ts-loader и заберет из кэша. То есть тут все достаточно просто.
Может быть использован для чего угодно, но конкретно для TypeScript это удобная штука, потому что ts-loader достаточно тяжелый loader, поэтому cache-loader здесь очень даже уместен.

Но у cache-loader есть один недостаток, — он работает со временем модификации файлов. Вот можно посмотреть кусочек исходного кода. И нам это не подошло.

Нам пришлось форкнуть и переделать алгоритм кэширования на хеше от контента файлов, потому что нас это не устроило для использования cache-loader в конвейере.
Дело в том, что когда хочется переиспользовать результаты сборки между несколькими пул-реквестами, то такой механизм не сработает. Потому что если сборка была, например, давно. Потом вы пытаетесь сделать новый pull request, который не поменял файлы, которые были собраны в предыдущий раз.
Но mtime у них уже более свежий. Соответственно, cache-loader будет думать, что файлики обновились, а на самом деле, — нет, потому что это время не модификации, а время чекаута. А если сделать вот так, то будут сравниваться кэши от контента. Контент не поменялся, то старый результат будет использован.
Тут надо заметить, что если бы мы использовали babel, у babel-loader по умолчанию есть внутри механизм кэширования, и он уже сделан на хешах от контента, не на mtime. Поэтому, может быть, мы еще подумаем и посмотрим в сторону babel.
Теперь про сборку чанков.

Давайте немножко поговорим о том, что webpack по умолчанию все это делает. Если у нас есть входной индекс-файл, в него подключаются компоненты. В них еще компоненты и т. д. Кроме того, подключаются общие модули: React, React-dom и lodash, к примеру.
Так вот, по умолчанию webpack, как, наверное, все знают, но на всякий случай повторю, собирает все зависимости в один большой бандл.
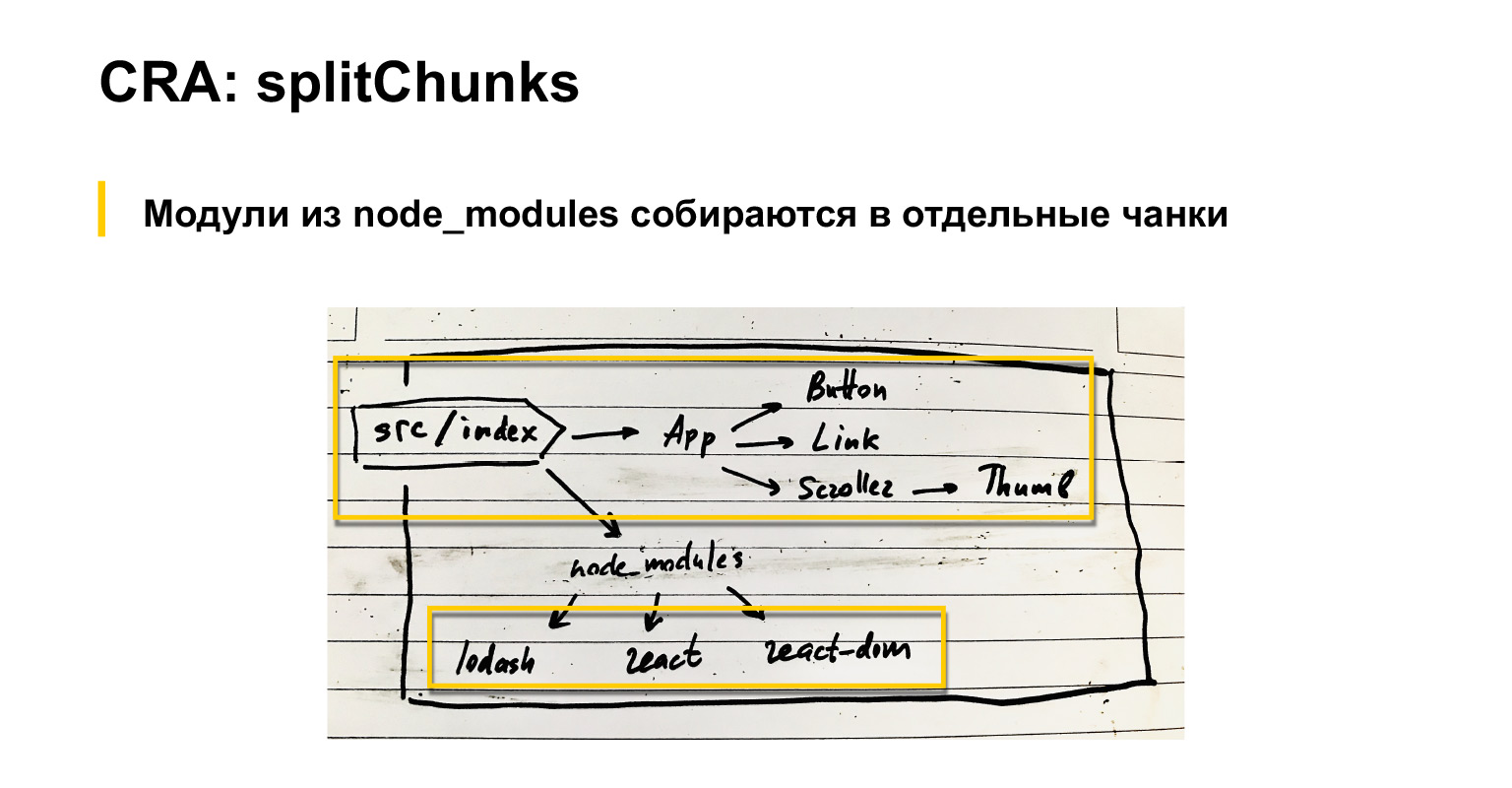
При этом все, что подключается через node_modules, можно собирать либо как externals, отдельными скриптами загружать, либо в отдельный чанк, настроив специальную настройку optimization.splitChunks в webpack. По-моему, даже по умолчанию вот эти вендор-модули собирают в отдельный чанк. В CRA есть немного донастроенная вересия этого splitChunks.

Давайте еще вспомним про то, что такое runtimeChunks. Я про него упоминал. Это такой код, который содержит в себе такую «шапку» загрузочных скриптов и функций, которые обеспечивают работу модульной системы на клиенте. А дальше массив (или кэш), который, собственно, в себе модули содержит.

Зачем я про это рассказал? Потому что в Create React App еще используется такая настройка, которая вот этот runtimeChunks собирает в отдельный файл. Вот этот файлик будет прилеплен не в исходный здоровый бандл, а в отдельный файлик. Его можно будет закэшировать в браузере и все такое.
Так вот, что нам не подходит в Create React App?

Этот splitChunks, который по умолчанию там используется, он в отдельные чанки собирает только то, что node_modules. Но, на самом деле, есть общие компоненты, общие библиотеки, которые на уровне проекта. Их бы тоже хотелось собирать в отдельные чанки, потому что они, может быть, тоже редко изменяются. Почему мы ограничиваемся только тем, что в node_modules лежит?
Кроме того, по поводу runtimeChunks тоже можно сказать, что было бы здорово, как мы изначально обсуждали, кроме самого runtime, еще собирать модули туда же, в этот же чанк, которые всегда нужны. Те же кнопки/ссылки. На Серпе всегда есть ссылки. Вот ссылки всегда бы хотелось собирать. То есть не только вебпачный runtime, а еще какие-то суперпопулярные компоненты.
Этого нет в Create React App. Как мы сделали у нас?

Мы донастроили splitChunks таким образом, что мы отключили все стандартное поведение и попросили собирать в общий код не только то, что лежит в node_modules, но еще то, что является общими компонентами нашего проекта и библиотечный код нашего проекта, то, что в src/lib, в src/components лежит.
Кроме того, в отдельные чанки мы собираем то, что подключается через динамический импорт, и то, что обычно называется асинхронными чанками.
Тут нужно обратить еще внимание на две опции. Одна — это enforce, а вторая это initial. В общем, enforce — это такая достаточно удобная настройка, которая отключает всякие сложные эвристики в splitChunks.
По умолчанию splitChunks пытается понять, насколько модули востребованы и учитывать эту статистику в разбиении. Но за этим сложно следить, и востребованность модуля может меняться время от времени, и модуль будет «скакать» между чанками. Из общего чанка попадать в бандл фичи и обратно. То есть это очень непредсказуемое поведение, поэтому мы его отключаем.
То есть мы всегда говорим все, что удовлетворяет условия в поле test, у нас попадает в common чанки. Никаких эвристик мы не хотим.
А вот chunks: initial тоже хорошая штука, она про то, что вот эти синхронные модули, модули, которые подключаются через динамические импорты, они могут в разных местах могут подключаться разными способами. То есть можно один и тот же модуль подключить либо динамическим импортом, либо обычным импортом.
И значение initial позволяет один и тот же модуль собирать в двух вариантах. То есть он собирается, как асинхронный, так и синхронный, позволяя, таким образом, использовать его и так, и так. Достаточно удобно. Это немножечко раздувает размеры собранной статики, но зато позволяет использовать любые импорты.
Из документации, кстати, это достаточно трудно понять. Я недавно перечитывал документацию webpack и про initial там ничего нормального не написано.

Это то, что мы сделали со splitChunks. Теперь что мы сделали с runtimeChunks. Вместо того, чтобы в runtimeChunks собирать только runtime, мы туда хотим добавлять еще супер популярные компоненты.
Вот мы написали свой плагин, который называется MainChunkPlugin. И у него очень тривиальная настройка. Там просто список модулей, которые нужно туда собрать, которые мы посчитали популярными.
Просто с помощью наших инструментов A/B-тестирования, разных офлайн-инструментов поняли, какие компоненты чаще всего бывают на выдаче. Вот туда их и записали просто таким плоским списком. И в итоге, наш плагин собирает по списку эти компоненты, а также библиотеки, а также runtime вебпачный, который собирает этот optimization.splitChunks стандартный.

Здесь, кстати, кусочек кода, который приклеивает runtime. Тоже такой не тривиальный, чтобы показать, что плагины писать не так уж и просто, но потом посмотрим, что это дало.

Нужно еще заметить, что вообще говоря, в webpack есть стандартный механизм для таких вещей, называется DLLPlugin. Он тоже позволяет собирать отдельный чанк по списку зависимостей. Но у него есть ряд недостатков. Например, он не включает runtimeChunks. То есть runtimeChunks у вас всегда будет отдельный чанк, и будет собранный DLLPlugin-ом чанк. Это не очень удобно.
Также DLLPlugin требует отдельной сборки. То есть, если бы вот этот отдельный чанк с самыми ударными компонентами мы хотели бы собирать с помощью DLLPlugin, нам пришлось бы запускать две сборки.
То есть одна собрала вот этот отдельный чанк с манифест-файлом, а остальная сборка собрала бы все остальное, просто с помощью вычитания через манифест-файл, она бы не собирала то, что уже попало в чанк с популярными компонентами. И это замедляет сборку, потому что DLLPlugin реализация у нас занимала локально семь секунд. Это достаточно много. И это невозможно оптимизировать, потому что тут строгое последовательное выполнение.
Кроме того, в определенный момент нам нужно было собирать вот этот наш мейн-чанк с популярными компонентами без CSS, только JS. А DLLPlugin так не умеет. Он всегда собирает все, что доступно через require, через импорты. То есть, если вы подключаете CSS, он тоже всегда попадает. Нам это было неудобно. Но если для вас это не проблема, а писать вот такой хитрый код вам не хочется, то DLLPlugin вполне себе нормальное решение. Основную проблему он решает. То есть он доставляет самые популярные компоненты в отдельном файлике. Его можно использовать.
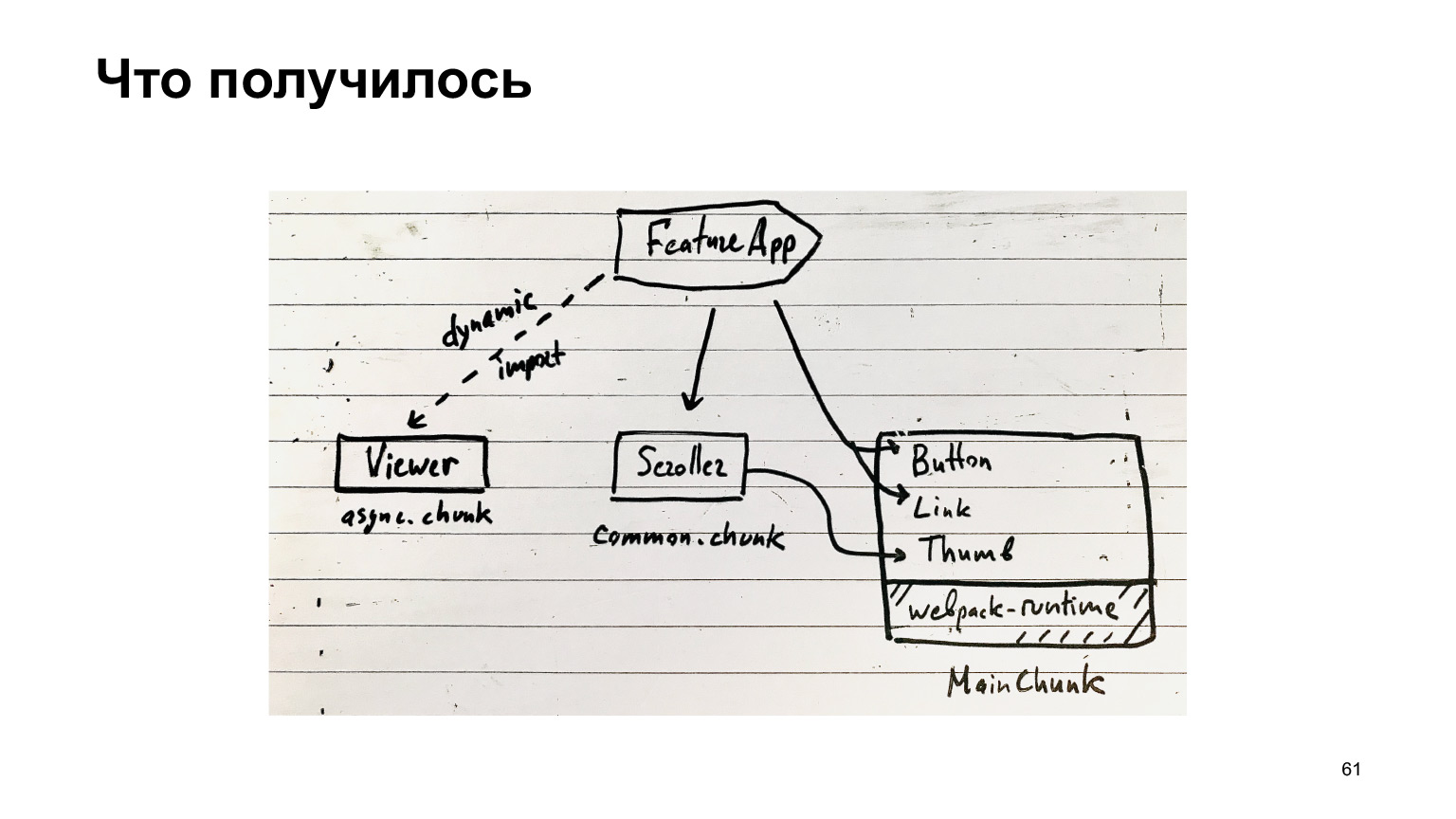
Итак, что у нас получилось? Наша фича может использовать суперпопулярные компоненты из этого нашего MainChunk, которые собираются специальным одноименным плагином. Кроме того, есть common чанки, которые включают в себя всякие общие компоненты, и есть асинхронные чанки, которые загружаются через динамические импорты.
Весь остальной код находится вот в бандлах фичей. В принципе, такая у вас структура чанков.
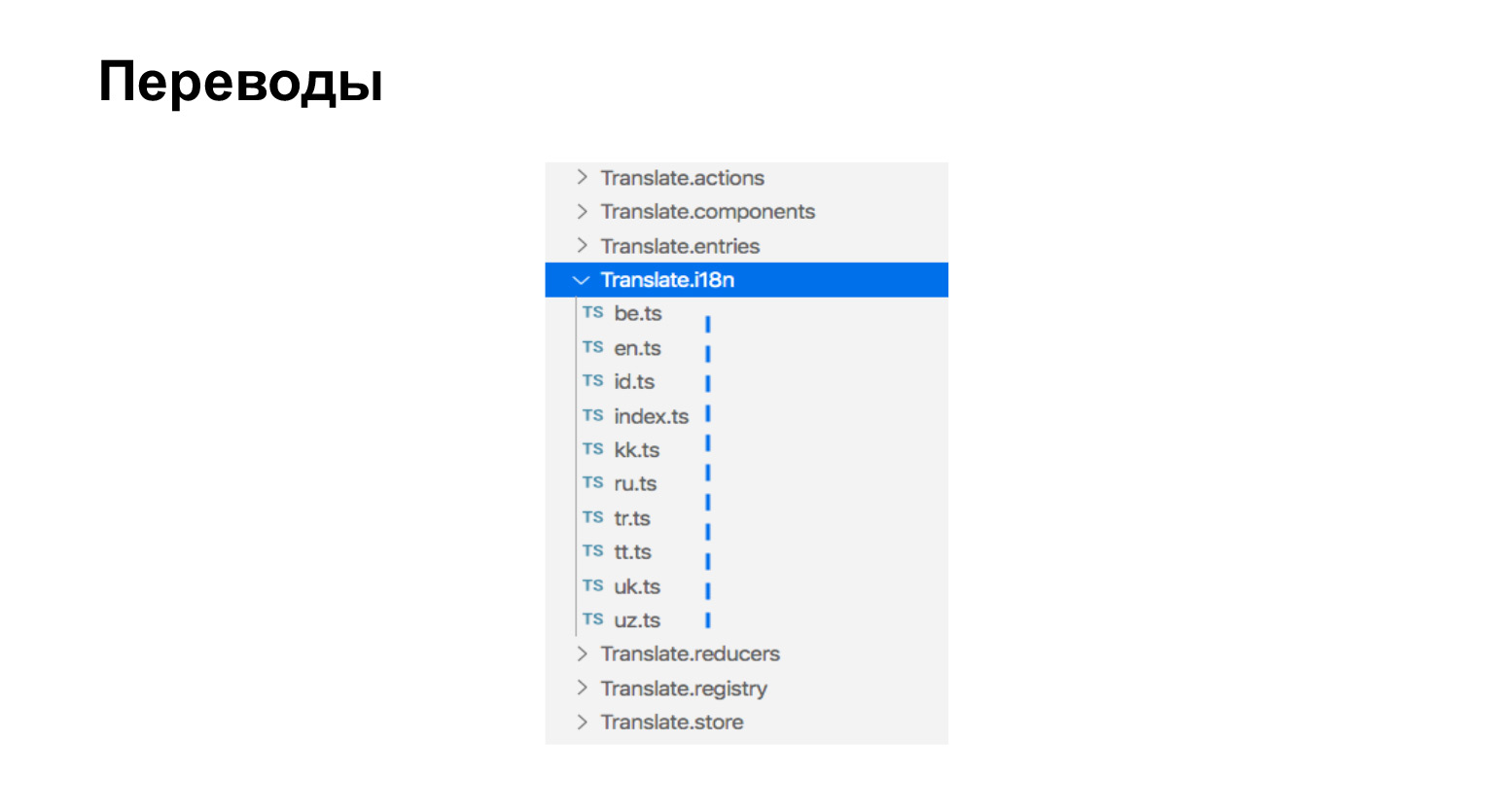
Про сборку переводов. Переводы у нас это просто ts-файлы, которые лежат рядом с компонентами, которым нужны переводы. Вот у нас девять языков, вот девять файликов.

Переводы выглядят вот так. Это просто объект, в котором есть ключик-фраза и значение переведенная фраза.

Вот таким образом переводы подключаются в компонент, и дальше используется уже специальный хелпер.

Как можно было бы собирать эти переводы? Мы думаем: нам нужно собирать переводы, посмотрим в интернете, чего пишут, как можно это делать.
В интернете говорят: используйте мультикомпиляцию. То есть вместо того, чтобы запускать одну сборку webpack, просто запустите сборку webpack на каждый язык отдельную. Но, говорят, все будет нормально, потому что там cache-loader он вот эту всю общую работу с TypeScript, или что там у вас, закэшируют, и поэтому будет недолго.
Не расстраивайтесь, не думайте, что это будет девять реальных запусков webpack. Будет не так, будет хорошо.
Единственное, нужно поправить немножечко, добавить модуль ReplacementPlugin, который вместо индекс-файла, который подключает все языки, заменит его на подключение конкретного языка. Все достаточно тривиально, и да, output надо поправить. Теперь у нас, получается, нужно для каждого языка отдельный бандл собирать.

Схема для этого рецепта вот такая. Был переводчик. Он подключал переводы переводчика. Он подключал языки, и мы, вместо того, чтобы собирать вот эту одну структуру, мы ее растиражировали для каждого языка, получили отдельную, и собираем каждую как отдельную компиляцию.
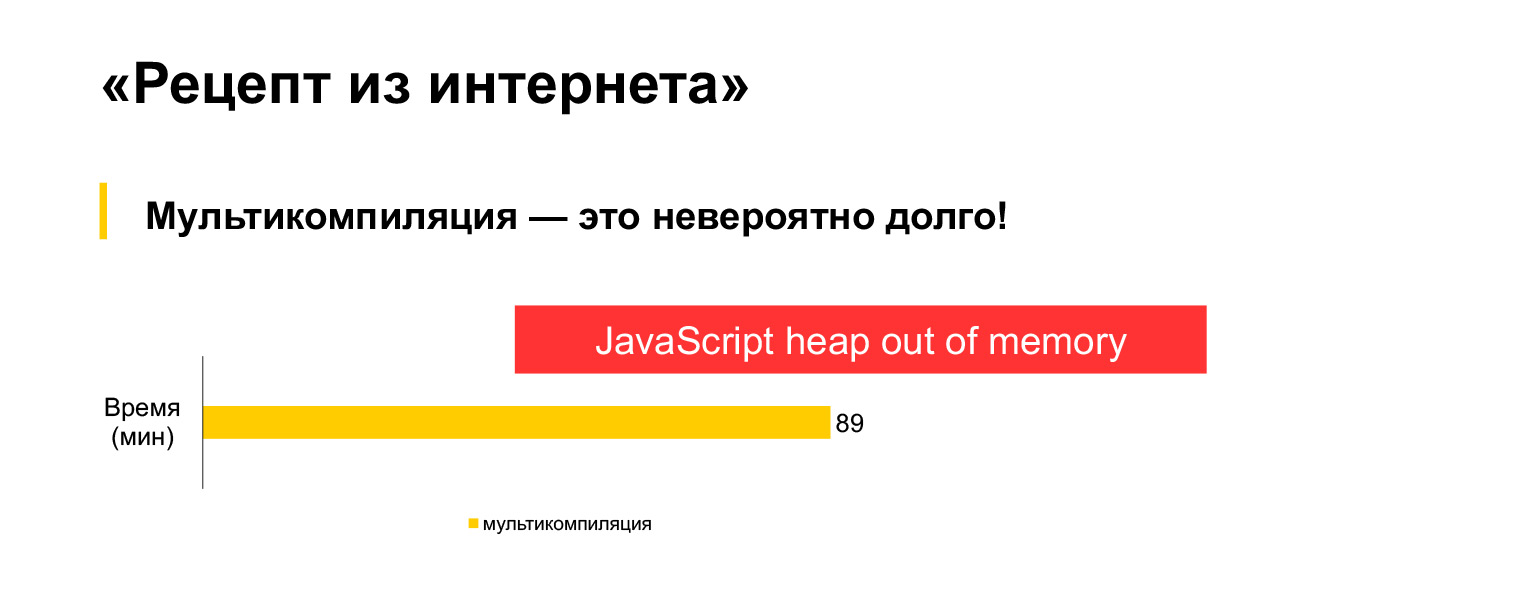
Но, к сожалению, это не работает. Я попробовал запустить этот вариант с мультикомпиляцией для нашего текущего 30-мегабайтного кода, и подождал полтора часа, и получил вот такую ошибку.

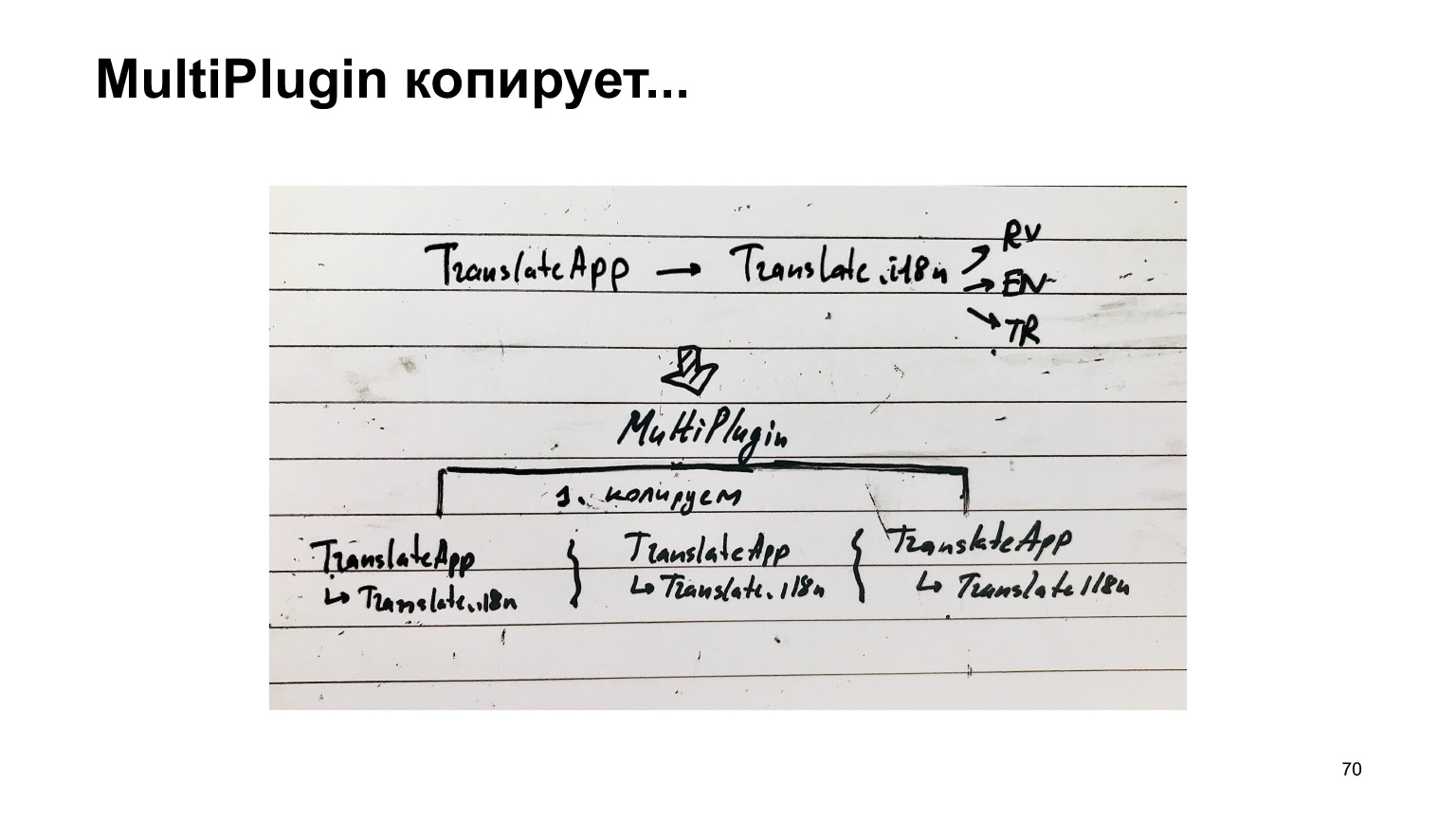
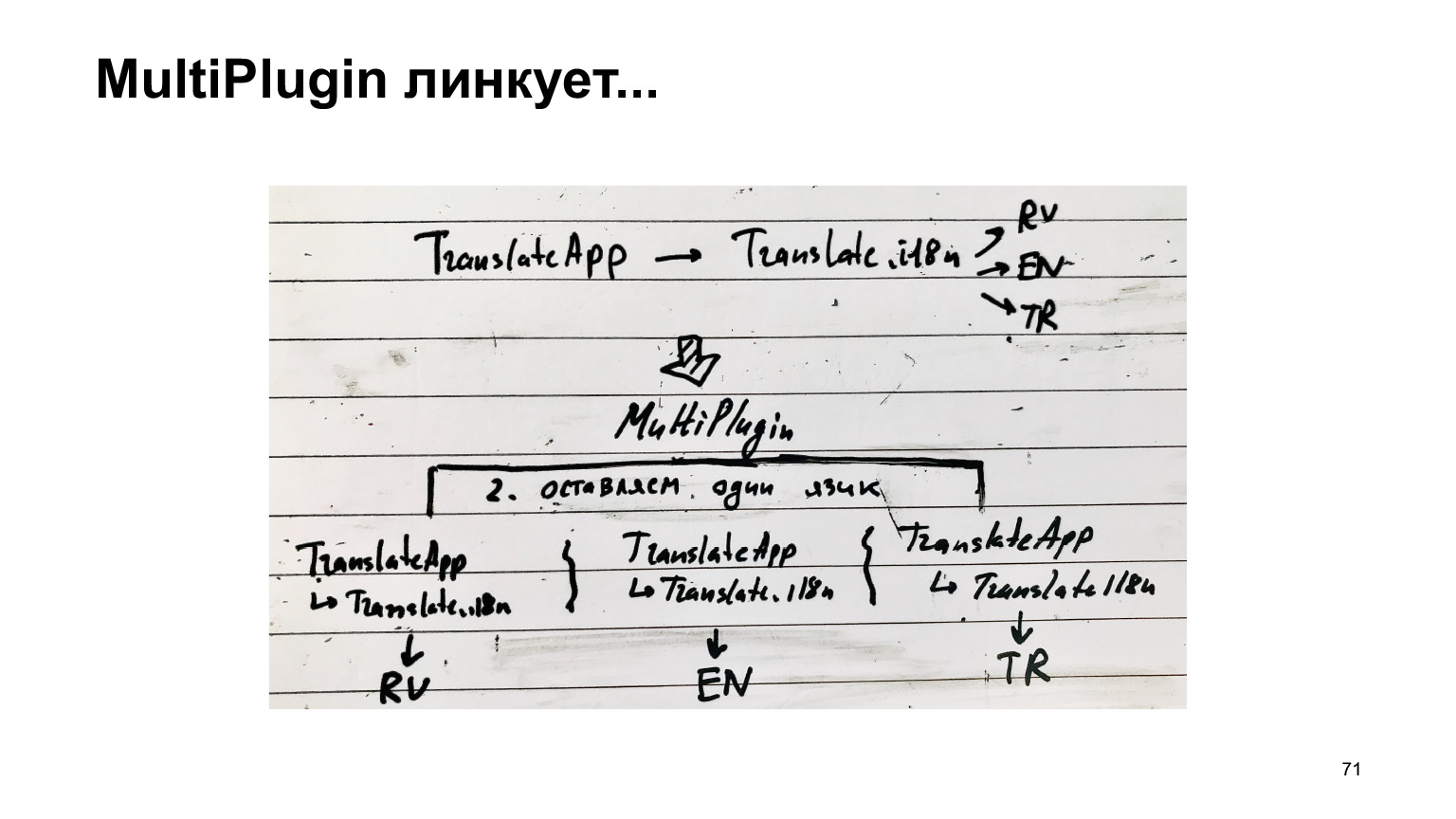
Это очень долго и невозможно. Что мы с этим сделали? Мы сделали еще один плагин. Берем ту же самую структуру и вклиниваемся в работу webpack, когда он собирается уже сохранять выходные файлы на диск. Копируем вот эту структуру столько раз, сколько у нас языков, и к каждому приклеиваем один язык. И только потом создаем файлы.

При этом основная работа, которая делает webpack по обходу зависимостей компиляций, она не повторяется. То есть мы вклиниваемся на самом последнем этапе, и поэтому можем надеяться на то, что это будет быстро.

Но код плагина получился сложный. Вот это буквально одна восьмая часть нашего плагина. Просто демонстрирую, насколько это сложно. И там у нас там регулярно находятся маленькие-неприятные баги. Но проще не получилось это реализовать. Зато работает очень хорошо.
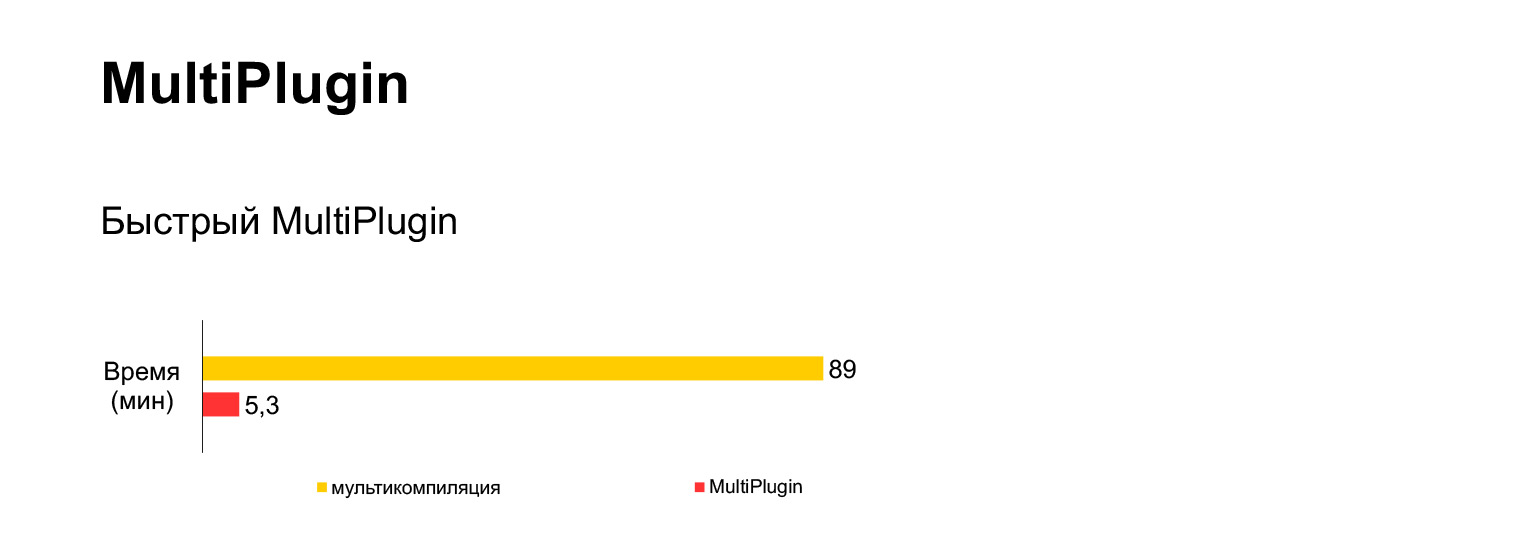
То есть вместо полутора часов с ошибкой, мы получаем пять минут сборки с этим нашим плагином.
Теперь доставка и инициализация.

Про доставку и инициализацию все просто. То, что мы загружаем в отдельных ресурсах, мы используем preload, так же, как и все, наверное. Потом мы подключаем CSS, JS, собственно, HTML для наших компонентов, и загружаем эти наши ресурсы, но без async.
Мы экспериментировали. Если использовать async, то отдаляется время наступления интерактивности, чего мы бы не хотели. Поэтому просто используем preload и загрузку в конце страницы. В общем, ничего особенного.

При этом все остальное мы инлайним. То есть вот этот наш MainChunk, его CSS мы инлайним. Общие компоненты, стили, в общем, все, что написано на слайде, мы инлайним. Это тоже был ряд экспериментов, которые показали, что «инлайн» дает наилучший результат для первой отрисовки и наступления интерактивности.
И теперь к цифрам. Чтобы рассказать про цифры, надо два слова сказать про метрики.

У нас есть специальная команда скорости, цель которой сделать так, чтобы весь фронтенд-код эффективно работал. Это касается серверной шаблонизации, и загрузки ресурсов, и инициализации на клиенте, в общем, всего вот этого.
У нас целая куча метрик, которые отправляются из продакшена в нашу специальную систему логов. Мы можем это контролировать в A/B экспериментах. У нас есть офлайн-инструменты, в общем, мы очень активно за этим всем следим.
И этими инструментами мы пользовались, когда внедряли вот этот наш новый код на React и TypeScript.

Давайте теперь отследим с помощью, офлайн-инструментов (потому что я не смог собрать, честный онлайн-эксперимент, который бы использовал все-все наши метрики). Давайте посмотрим, что будет, если мы откатимся от этого нашего текущего решения к Create React App по вот этим ключевым метрикам.
Инструмент работает очень просто. Берется срез запросов, в данном случае берется запрос с фичами на React, потому что не весь Серп еще переписан на React. Потом обстреливаются наши шаблоны, собираются замеры, засовываются в специальную утилиту, которая сравнивает и находит эти результаты и метрики. При этом остаются только статистически значимые результаты. В общем, там все разумно.
Смотрим, что получается.

Отключение MultiPlugin, который, по сути, собирает вместо только нужного перевода все переводы, не показал статистически значимых изменений.
Я сначала немножко расстроился, потом понял, что, на самом деле, это не проблема, потому что у нас сейчас не так много фичей, у которых много переводов переведены на React. Поэтому, когда таких фичей станет больше, эти значимые изменения обязательно появятся. Просто сейчас фичи, которые, в основном, в России показываются и у них нет переводов. Да и тот объем кода, который есть в компонентах, сильно превышает объем переводов. Поэтому то, что все переводы едут, это незаметно.
Может быть, это было бы заметно на более честных экспериментах, если проводить честный эксперимент. Но офлайн-инструмент не показал этих изменений.

Если мы отключаем MainChunkPlugin, то у нас замедляется время наступления интерактивности, и загрузка HTML тоже сильно замедляется. Поэтому штука достаточно нужная.
Почему загрузка замедляется HTML, потому что весь тот код, который раньше загружался в этом отдельном чанке отдельным ресурсом, он теперь инлайнится в HTML. Это как мы все это инлайним, но интерактивность тоже замедляется. В принципе, достаточно ожидаемо.
А теперь вопрос: что произошло бы, если все собирать в один бандл, не использовать никаких чанков с общими компонентами? Получается вот такая совсем не радостная картина.

Первая отрисовка замедляется катастрофически. Интерактивность тоже, почти в два раза. При этом HTML становится меньше, так как весь код начинает доставляться отдельным ресурсом. Но интерактивности, как вы видите, это не помогает.
И сборка. Последние слайды.
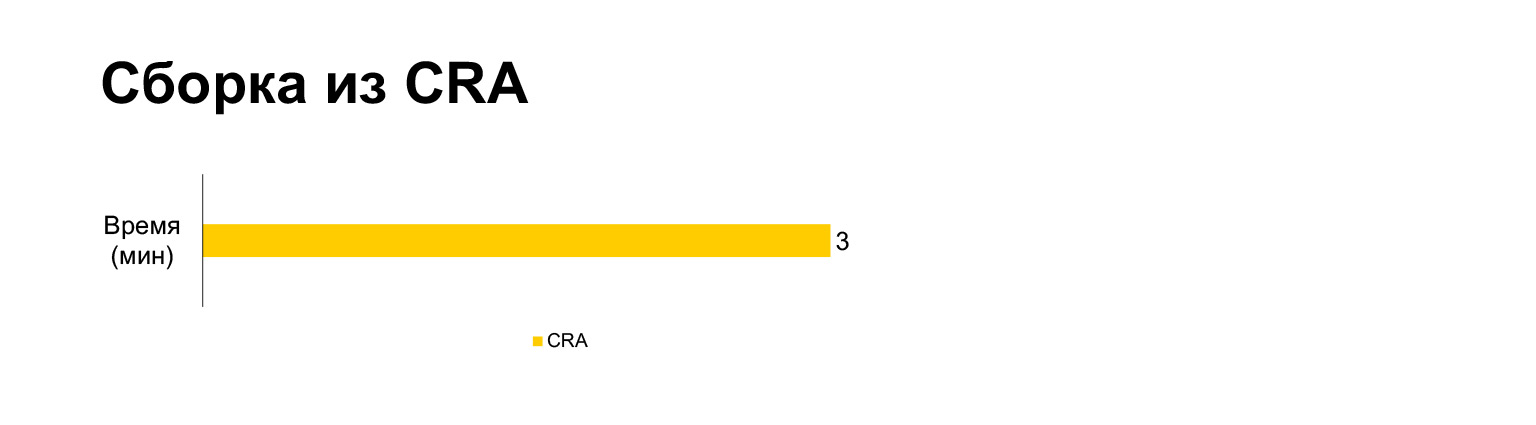
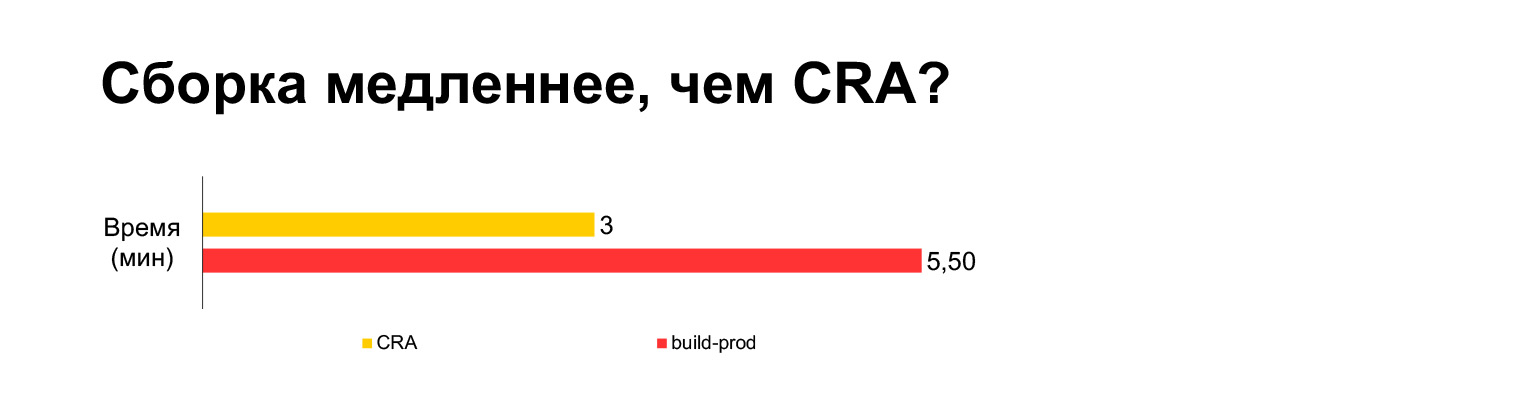
Время сборки Create React App текущего проекта занимает на ноутбуке три минуты. А со всеми нашими наворотами — пять минут. Долго?
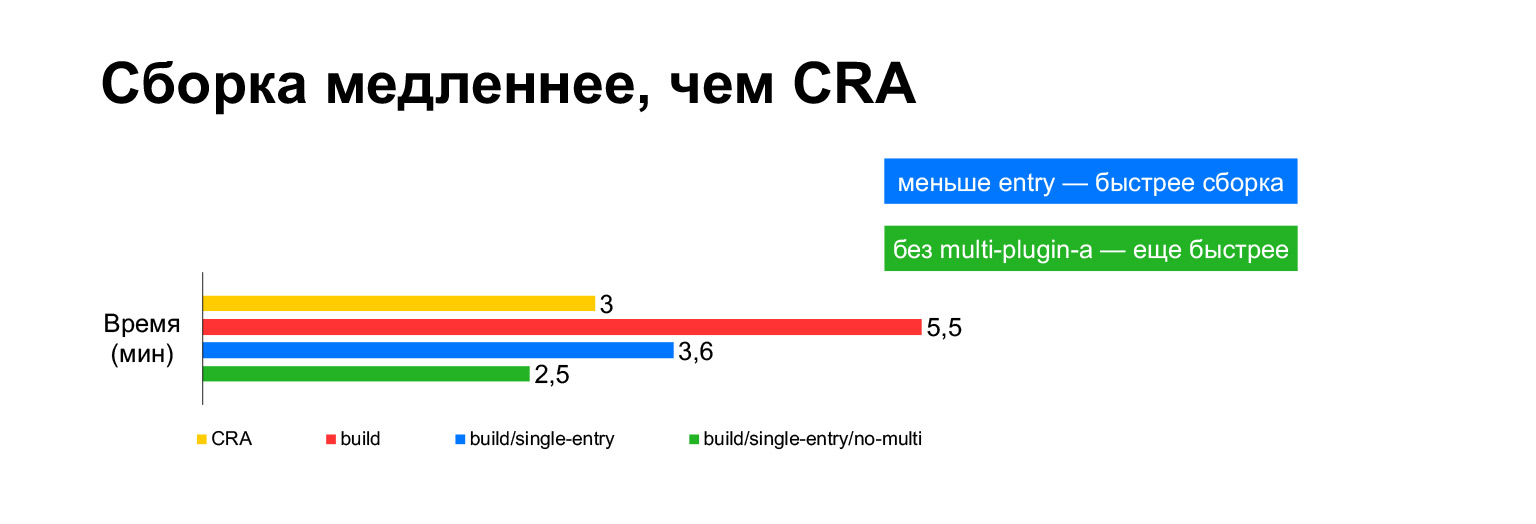
Однако на самом деле если собирать в один бандл, получается три минуты. Если собирать без MultiPlugin, то получается даже быстрее, чем в Create React App. Но как я показал на предыдущих слайдах, мы не можем отказаться от этих доработок исходных скриптов сборки, потому что без них со скоростными метриками станет совсем плохо.
Теперь пробежимся по тому, что полезного можно извлечь из этого доклада.

Babel — не единственный способ работы с TypeScript. Можно использовать TSC, ts-node и ts-loader. Вполне работает.
При этом TypeScript-проверки, проверки типов, не обязательно выполнять при сборке каждый раз. Это сильно замедляет — как вы помните, в два раза. Поэтому лучше такие штуки выносить в отдельные проверки, pre-commit-хуки, например.
Часто используемые компоненты лучше собирать в отдельный чанк. Общие компоненты тоже желательно собирать в отдельные чанки, потому что это позволяет дозагружать только то, что нужно, только diff.
При этом самое главное — наверное, то, что если у вас не весь код используется на всех страницах, нужно разбивать это на отдельные entry, собирать отдельные бандлы и загружать по мере того, как пользователь видит соответствующие типы поиска (овых результатов. Загружать только те файы, которые нужны. Это, как вы видели, и дает самый большой результат. Довольно очевидная вещь, но не уверен, что все так делают, потому что по-прежнему остаются на Create React App.
Мультикомпиляция очень долгая. Не верьте, если кто-то скажет, что мультикомпиляция — это нормально и кэши где-то внутри со всем этим справятся. Использование preload и inline тоже дает свои результаты.
Несколько ссылок про Серп:
- clck.ru/PdRdh и clck.ru/PdRjb — два доклада, которые про переписывание Серпа на React, это первый этап, про то, как мы пришли к этому и зачем начали это делать. Второй доклад про то, как мы с менеджерской точки зрения все это планировали и делали, какие были этапы.
- clck.ru/PdRnr — доклад про наши скоростные метрики. Он для тех, кому вдруг стало интересно, что там есть еще, как устроены онлайн-инструменты.
Всем спасибо.
