Кэши Tarantool и репликация из Oracle

Меня зовут Александр Деулин, я работаю в отделе развития собственной разработки «Фабрика микросервисов» в компании МегаФон. И хочу рассказать о тернистом пути появления кэшей Tarantool в ландшафте нашей компании, а также о том, как мы внедряли репликацию из Oracle. И сразу поясню, что под кэшем в данном случае подразумевается приложение с базой данных.
Мы уже много рассказывали о том, как мы в МегаФоне внедряли Единый биллинг, подробно останавливаться на этом не будем, но сейчас проект в стадии завершения. Поэтому просто немного статистики:
С чем мы подошли к нашей задаче:
- 80 млн абонентов;
- 300 млн абонентских профилей;
- 2 млрд транзакционных событий по изменению баланса в сутки;
- 250 ТБ активных данных;
- > 8 Пб архивов;
- и всё это расположено на 5000 серверов в разных ЦОДах.
То есть речь о высоконагруженной системе, в которой каждая подсистема стала обслуживать 80 млн абонентов. Если раньше у нас было 7 экземпляров и условно-горизонтальное масштабирование, то теперь мы перешли в домен. Раньше был монолит, а теперь у нас DDD. Система достаточно хорошо покрыта API, поделена на подсистемы, но не везде есть кэш. Сейчас мы сталкиваемся с тем, что подсистемы создают постоянно нарастающую нагрузку. К тому же появляются новые каналы, которые требуют обеспечить им 5000 запросов в секунду на одну операцию с задержкой 50 мс в 95% случаев, и обеспечить доступность на уровне 99,99%.
Параллельно мы начали создавать микросервисную архитектуру.

У нас есть отдельный слой кэшей, в который поднимаются данные из каждой подсистемы. Это позволяет легко собирать композиты и изолировать мастер-системы от большой нагрузки на чтение.
Как строить кэш для закрытых подсистем?
Мы решили, что нам нужно создавать кэши самостоятельно, не надеясь на вендора. «Единый биллинг» — это закрытая экосистема. Она содержит очень много паттернов микросервисов, в которых есть многочисленные API и свои базы данных. Однако из-за закрытости невозможно ничего модифицировать.
Стали думать, как нам подступиться к нашим мастер-системам. Очень популярный подход — event driven design, когда мы получаем данные из какой-то шины: либо это топик Kafka, либо exchange RabbitMQ. Ещё можно получать данные из Oracle: по триггерам, с помощью CQN (бесплатный инструмент от Oracle) или Golden Gate. Поскольку мы не можем встроиться в приложение, варианты с write-through и write-behind для нас были недоступны.
Получение данных из шины диспетчера сообщений
Нам очень нравится вариант с очередями и с диспетчерами сообщений. В «Едином биллинге» уже используются RabbitMQ и Kafka. Мы пропилотировали одну из систем и получили отличный результат. Все события мы получаем из RabbitMQ и делаем холодную загрузку, объем данных не очень большой.
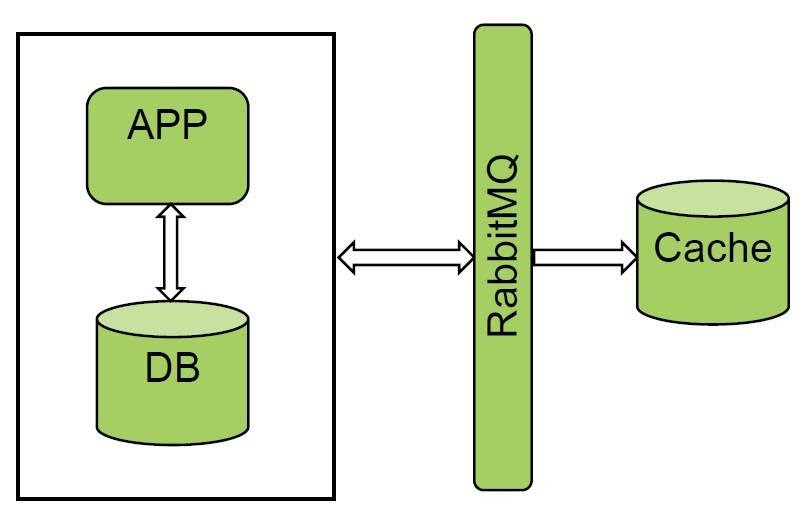
Решение работает прекрасно, но не все системы могут уведомлять шины, поэтому такой вариант нам не подошёл.
Получение данных из базы: триггеры
Оставался способ с получением данных для наполнения кэша из базы.
Самый простой вариант — это триггеры. Но для высоконагруженных приложений они не годятся, потому что, во-первых, мы модифицируем саму мастер-систему, а во-вторых, это дополнительная точка отказа. Если триггер вдруг не смог записать в какую-то временную табличку, мы получаем полную деградацию, в том числе мастер-системы.

Получение данных из базы: CQN
Второй вариант получения данных из базы. У нас используется Oracle, и вендор сейчас поддерживает лишь один бесплатный инструмент для получения данных из базы — CQN.
Этот механизм позволяет подписаться на уведомления по изменению DDL или DML операций. Там всё достаточно просто. Есть уведомления в стиле JDBC и PL/SQL.
JDBC означает, что мы уведомляем advanced queue, и это событие летит во внешнюю систему. Фактически, нужен внешний коннектор OSI. Нам этот вариант не понравился, потому что если мы теряем связанность с Oracle, то не можем прочитать наше сообщение.
Мы выбрали PL/SQL, потому что это позволяет перехватить уведомление и сохранить его во временную табличку в той же базе Oracle. То есть таким образом можно обеспечить некоторую транзакционную целостность.
Всё в начале прекрасно работало, пока мы не пропилотировали достаточно нагруженную базу. Проявились такие недостатки:
- Транзакционная нагрузка на базу. Когда мы перехватываем сообщение из очереди уведомлений, нам нужно его положить в базу. То есть нагрузка на запись возрастает вдвое.
- Также этот механизм использует внутреннюю очередь advanced queue. И если её использует и ваша мастер-система, то может возникнуть конкуренция за очередь.
- Мы получили интересную ошибку на партиционированных таблицах. Если одним коммитом закрывается более 100 изменений, то CQN не ловит такие изменения. Мы открывали тикет в Oracle, меняли системные параметры — не помогло.
Для нагруженных приложений CQN точно не подходит. Он хорош для небольших инсталляций, для работы с какими-то словарями, справочными данными.
Получение данных из базы: Golden Gate
Остался старый добрый Golden Gate. Изначально мы его не хотели использовать, поскольку это старомодное решение, нас пугала сложность самой системы.

В самом GG получалось два дополнительных экземпляра, которые нужно было поддерживать, а у нас не так много знаний по Oracle. Изначально было достаточно тяжело, хотя возможности решения нам очень понравились.
Комбинация SCN + XID позволила нам контролировать транзакционную целостность. Решение получилось универсальное, оно оказывает низкое влияние на мастер-систему, из которой мы можем получать все события. Хотя решение требует покупки лицензии, для нас это не было проблемой, поскольку лицензия уже имелась. Также к недостаткам решения можно отнести сложную реализацию и то, что GG является дополнительной подсистемой.
Выводы
Какие выводы можно сделать из вышесказанного?
Если у вас закрытая система, то нужно исследовать характер вашей нагрузки и способы использования, и выбрать подходящее решение. Оптимальным, на наш взгляд, является event driven design, когда мы уведомляем топик в Kafka, и брокер сообщений становится мастер-системой. Топик — это золотая запись, остальные данные система забирает к себе. Для закрытых систем в нашем ландшафте наиболее удачным решением оказался GG.
А теперь на примере одного из продуктов я расскажу, как мы применили это решение. PIM — продуктовая витрина, основанная на SID-модели. То есть это все продукты абонента, которые в данный момент у него подключены. На их основе ведутся начисления расходов и строится логика работы.
Архитектура
Напомню: под «кэшем» в этой статье подразумевается комбинация приложения и базы данных, это основной паттерн использования Tarantool.
Особенность проекта PIM заключается в том, что исходная мастер-система Oracle маленькая, всего 10 млрд записей. Ее надо прочитать. И самая большая проблема, которую мы решали, это прогрев кэша.
С чего мы начали?

Основные 10 таблиц дают 10 млрд записей. Мы захотели прочитать их в лоб. Поскольку в кэш мы поднимаем только горячие данные, а в Oracle хранятся, в том числе, и исторические, нам нужно было поставить условие where и вытащить эти 10 млрд. Нетривиальная задача. Oracle нам сказал, что так делать нельзя: поднял загрузку процессора до 100%. Решили пойти другим путем.
Но сначала несколько слов про архитектуру кластера.
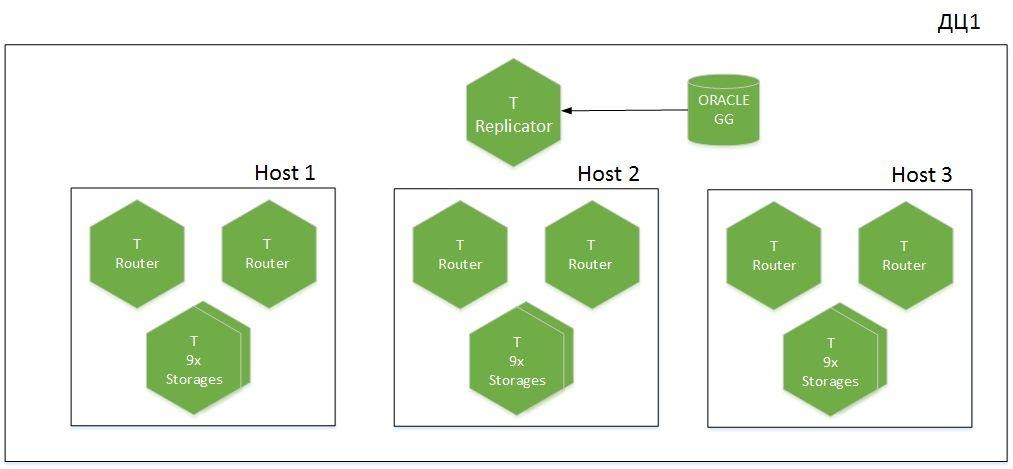
Это шардированное приложение, по 9 шардов в 6 хостах, распределенных по двум дата-центрам. У нас есть Tarantool с ролью Replicator, который получает данные из Oracle, и еще один экземпляр, который называется Importer — используется при холодной загрузке. Всего в кэш поднимается 1,1 ТБ горячих данных.
Холодная загрузка
Как мы решили проблему холодной загрузки? Всё оказалось достаточно тривиально.

Как работает механизм в целом? Мы убрали условие where и читаем всё подряд. Сначала запускаем поток redo-логов, чтобы получать фактически онлайн-изменения из базы. Полным сканированием проходим по подразделам, забирая данные пачками с нормализацией и фильтрацией. Копим изменения, параллельно запускаем холодный прогрев кэша и выкладываем всё в CSV-файлы. В кэше работает 10 экземпляров Importer, которые после считывания из Oracle отправляют данные в экземпляры Tarantool. Для этого каждый Importer вычисляет нужный шард и сам кладет данные в необходимое хранилище, не нагружая роутеры.
После загрузки всех данных из Oracle мы проигрываем из GG поток трейлов, которые накопились за это время. Когда SCN + XID достигает приемлемых значений с мастер-системой, мы считаем, что кэш прогрет, и включаем нагрузку на чтение из внешних систем.
Немного статистики. В Oracle у нас порядка 2,5 ТБ сырых данных. Мы их считываем 5 часов, импортируем в CSV. Загрузка в Tarantool с фильтрацией и нормализацией занимает 8 часов. И шесть часов мы проигрываем накопившиеся логи, которые нам приходят из трейла. Пиковая скорость от 600 тыс. записей/с. до 1 млн в пиках. В Tarantool данные объёмом 1,1 ТБ вставляются со скоростью 200 тыс. записей/с.
Теперь холодный прогрев кэша на больших объемах стал для нас обыденностью, потому что мы не оказываем большого влияния на Oracle.

Вместо базы мы нагружаем ввод-вывод и сеть, поэтому необходимо предварительно убедиться, что у нас есть достаточный запас по сетевой пропускной способности, в пиках у нас доходит до 400 Мбит/с.
Как работает цепочка репликации из Oracle в Tarantool
При проектировании кэша мы решили экономить память. Убрали всю избыточность, объединили пяток таблиц в одну, и получили очень компактную схему хранения, но потеряли контроль за согласованностью. Пришли к выводу, что необходимо повторить DDL из Oracle. Это позволило нам контролировать SCN + XID, храня их в отдельном технологическом пространстве по каждой табличке. Периодически сверяя их, мы можем понять, где сломалась репликация, и в случае проблем перечитываем логи архивирования.
Шардинг
Немного про логическое хранение данных. Чтобы исключить Map Reduce, нам пришлось ввести дополнительную избыточность данных и разложить словари по собственным хранилищам. Мы пошли на это сознательно, потому что наш кэш работает, в основном, на чтение. Мы не можем его встроить в мастер-систему, поскольку это приложение изолирует нагрузку внешних каналов от мастер-системы. Все данные по абоненты мы считываем с одного хранилища. В этом случае мы теряем в производительности на запись, но она для нас не так важна, словари обновляются нечасто.
Что получилось в итоге?
Мы создали кэш для нашей закрытой системы. Были некоторые ошибки фильтрации, но мы их уже починили. Мы подготовились к появлению новых высоконагруженных потребителей. Прошлым летом появилась новая система, которая добавила 5–10 тыс. запросов в секунду, и мы эту нагрузку не пустили в «Единый биллинг». Также мы научились готовить репликацию из Oracle в Tarantool, отработали перегон больших объемов данных, не нагружая мастер-систему.
Что нам еще предстоит сделать?
В основном это эксплуатационные сценарии:
- Автоматический контроль согласованности данных.
- Отработать сценарий переключения Active-Standby Oracle, как switchover, так и failover.
- Проигрывание archive-логов из GG.
- Самое главное — написать автотесты контроля изменения DDL-схемы в мастер-системах. Нам необходимо контролировать каждый релиз, потому что если схема DDL не будет сохраняться, придется вносить изменения в наш кэш.
