Книга «System Design. Машинное обучение. Подготовка к сложному интервью»
 Привет, Хаброжители!
Привет, Хаброжители!
Собеседования по проектированию систем машинного обучения — самые сложные. Если нужно подготовиться к такому, книга создана специально для вас.
Также она поможет всем, кто интересуется проектированием систем МО, будь то новички или опытные инженеры.
Что внутри?
- О чем на самом деле спрашивают на собеседовании по System Design в МО и почему (инсайдерская информация!).
- 7 основных шагов для решения любой задачи МО, предлагаемой на собеседовании.
- 10 вопросов из реальных собеседований по System Design в МО с подробным разбором ответов.
- 211 диаграмм, которые наглядно объясняют, как работают различные системы.
Для кого эта книга
Книга будет ценным источником информации для всех, кто интересуется проектированием систем МО, будь то новички или опытные инженеры. А если вам нужно подготовиться к собеседованию по МО, то эта книга написана специально для вас.
Чего нет в книге
Эта книга — не пособие по основам машинного обучения. Она написана для дата-сайентистов, инженеров данных и инженеров МО, которым нужна помощь, чтобы подготовиться к собеседованию по проектированию систем МО. Книга предназначена в первую очередь для инженеров МО в бизнесе и в меньшей степени для ученых в области МО в образовательных учреждениях или НИИ.
ПОИСК ВИДЕО НА YOUTUBE
На платформах видеохостинга, таких как YouTube, количество видеороликов быстро возрастает до миллиардов. В этой главе мы спроектируем систему поиска видео, которая может эффективно работать с таким объемом контента. Как показано на рис. 4.1, пользователь вводит текст в поле поиска, а система выводит список видеороликов, которые лучше всего соответствуют этому запросу.

Прояснение требований
Вот типичный диалог между соискателем и экспертом:
Соискатель: В поле поиска можно вводить только текст или пользователи могут искать по изображениям и видео?
Эксперт: Только текстовые запросы.
Соискатель: Контент на платформе представлен только в формате видео? Как насчет изображений или аудиофайлов?
Эксперт: На платформе размещается только видео.
Соискатель: Система поиска YouTube очень сложна. Можно ли предположить, что релевантность видео определяется исключительно его визуальным содержанием и сопутствующими текстовыми данными — например, названием и описанием?
Эксперт: Да, это справедливое допущение.
Соискатель: Доступны ли обучающие данные?
Эксперт: Да, будем считать, что доступны 10 миллионов пар типа ⟨видео, текстовый запрос⟩.
Соискатель: Должна ли система поиска поддерживать другие языки?
Эксперт: Для простоты будем считать, что поддерживается только один язык.
Соискатель: Сколько видеороликов доступно на платформе?
Эксперт: Один миллиард.
Соискатель: Нужно ли персонализировать результаты? Должны ли они ранжироваться по-разному для разных пользователей в зависимости от их предыдущих взаимодействий?
Эксперт: В отличие от рекомендательных систем, где персонализация абсолютно необходима, в поисковых системах персонализировать результаты не обязательно. Чтобы упростить задачу, будем считать, что персонализация не нужна.
Резюмируем описание проблемы. Требуется спроектировать систему поиска видео. На вход подается текстовый запрос, а на выходе отображается список видеороликов, которые соответствуют запросу. Чтобы найти релевантные ролики, мы будем использовать как их визуальное содержание, так и текстовые данные. Для обучения модели доступен датасет из 10 миллионов пар типа ⟨видео, текстовый запрос⟩.
Формулировка проблемы в виде задачи МО
Определение цели МО
Пользователи ожидают, что поисковые системы выдают релевантные и полезные результаты. Один из способов преобразовать эти ожидания в цель МО заключается в том, чтобы ранжировать видеоролики в зависимости от их релевантности текстовому запросу.
Определение входных и выходных данных системы
Как показано на рис. 4.2, система поиска принимает на вход текстовый запрос и выдает список видеороликов, отсортированных по релевантности этому запросу.

Выбор категории МО
Чтобы установить релевантность между видео и текстовым запросом, мы будем использовать как визуальное содержание, так и текстовые данные видео. Общий обзор архитектуры представлен на рис. 4.3.
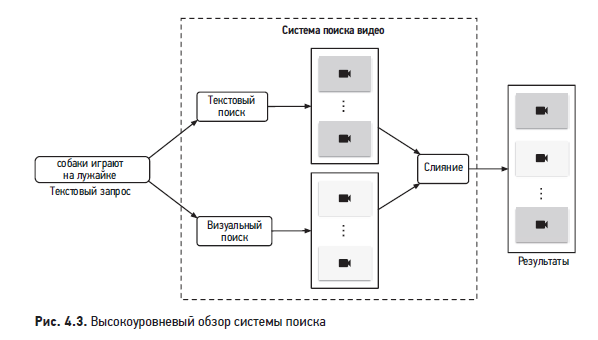
Кратко рассмотрим каждый из этих компонентов.
Визуальный поиск
Этот компонент принимает на вход текстовый запрос и выдает список видеороликов. Результаты ранжируются по степени сходства между текстовым запросом и визуальным содержанием.
Для поиска видеороликов по их визуальному содержанию часто применяется обучение представлений. В этом методе текстовый запрос и видео кодируются по отдельности с помощью двух кодировщиков. Как показано на рис. 4.4, модель МО содержит кодировщик видео, который генерирует вектор эмбеддинга на основе содержания видео, а также текстовый кодировщик, генерирующий вектор эмбеддинга на основе текста. Метрика сходства между видео и текстом вычисляется через скалярное произведение их представлений.

Чтобы ранжировать видеоролики, которые визуально и семантически близки к текстовому запросу, мы вычисляем скалярное произведение между текстом и каждым видеороликом в пространстве эмбеддингов, а затем ранжируем видео на основании этой метрики сходства.
Текстовый поиск
На рис. 4.5 показано, как работает текстовый поиск, когда пользователь вводит текстовый запрос: «собаки играют на лужайке». В качестве результатов отображаются видеоролики, чьи названия, описания или теги наиболее похожи на текстовый запрос.
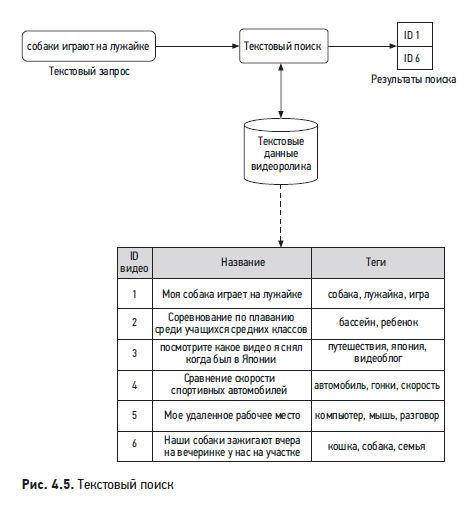
Стандартный метод создания текстового компонента поиска — обратный индекс, который позволяет эффективно проводить полнотекстовый поиск в базах данных. Поскольку обратная индексация не базируется на МО, она не требует затрат на обучение. Многие компании используют Elasticsearch — масштабируемый поисковый движок и хранилище документов. Чтобы подробнее узнать про Elasticsearch и глубже понять принципы его работы, обращайтесь к.
Подготовка данных
Инженерия данных
Поскольку у нас есть размеченный датасет для обучения и оценки модели, инженерия данных не требуется. В табл. 4.1 показано, как может выглядеть размеченный датасет.
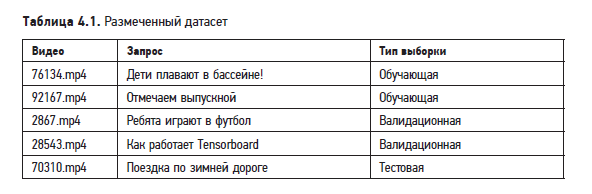
Конструирование признаков
Почти все алгоритмы МО принимают только числовые входные значения. На этапе конструирования признаков все неструктурированные данные, такие как текст и видео, должны быть преобразованы в числовое представление. Посмотрим, как подготовить текстовые и видеоданные для модели.
Подготовка текстовых данных
Как показано на рис. 4.6, текст обычно преобразуется в числовой вектор за три шага: нормализация текста, лексический анализ (токенизация) и преобразование токенов (лексем) в идентификаторы.
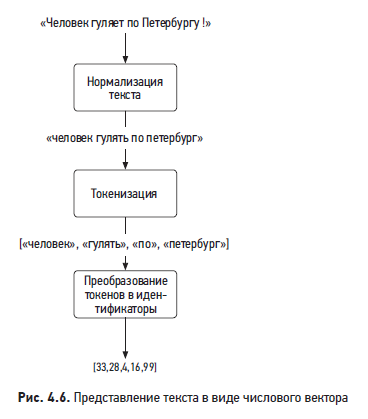
Рассмотрим каждый шаг подробнее.
Нормализация текста
Нормализация текста обеспечивает единообразие слов и предложений. Например, слова «собака», «собаке» и «СОБАКА!» обозначают одно и то же, но записываются по-разному. То же можно сказать и о предложениях. Для примера возьмем такие два предложения:
- «Человек гуляет с собакой по Петербургу!»
- «человек, гуляющий со своей собакой в Санкт-Петербурге».
Оба предложения имеют одинаковый смысл, но различаются знаками препинания, формами слов и другими деталями. Вот распространенные методы нормализации текста.
- Приведение к нижнему регистру: все буквы переводятся в нижний регистр, потому что от этого не меняется смысл слов или предложений.
- Удаление знаков препинания: из текста удаляются все знаки препинания: точки, запятые, вопросительные и восклицательные знаки и т. д.
- Усечение пробелов: из текста удаляются начальные, конечные и сгруппированные пробельные символы.
- Нормализация NFKD (совместимая декомпозиция): комбинированные графемы раскладываются на комбинации простых графем.
- Удаление диакритики: из слов удаляются диакритические знаки: Màlaga → Malaga, Noël → Noel
- Лемматизация и выделение основ: для набора взаимосвязанных форм слова определяется каноническая форма: гуляет, гуляющий, гуляли → гулять.
Токенизация
Лексический анализ (токенизация) — процесс разбиения текста на меньшие единицы, называемые лексемами (токенами). В общем случае применяются три разновидности токенизации.
- По словам: текст разбивается на отдельные слова по заданным ограничителям. Например, фраза вида «У меня завтра собеседование» превращается в [«У», «меня», «завтра», «собеседование»].
- По подсловам.
- По символам.
На собеседовании по проектированию систем МО обычно не вдаются в подробности алгоритмов токенизации. Если вам захочется узнать больше, обращайтесь к.
Преобразование лексем в идентификаторы
После того как мы получили лексемы, их надо преобразовать в числовые значения (идентификаторы). Это можно сделать двумя способами:
- таблица сопоставления;
- хеширование.
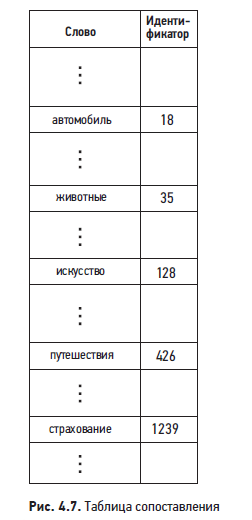
Таблица сопоставления. Каждой уникальной лексеме ставится в соответствие идентификатор, и все эти взаимно-однозначные соответствия сохраняются в таблице сопоставления. На рис. 4.7 показано, как она может выглядеть.
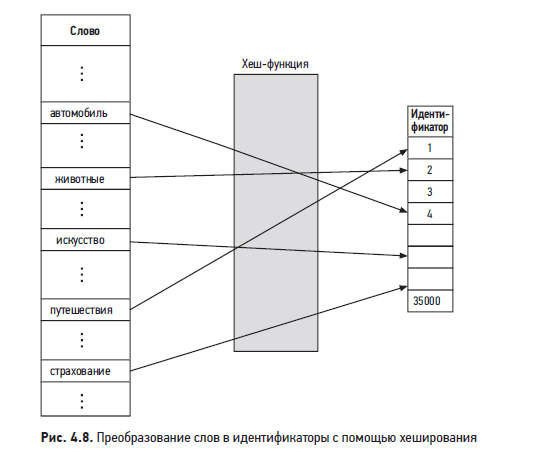
Хеширование. Этот метод вырабатывает идентификаторы с помощью хеш-функции, что позволяет обойтись без таблицы сопоставления и таким образом сэкономить память. На рис. 4.8 представлен пример преобразования слов в идентификаторы с помощью хеш-функции.
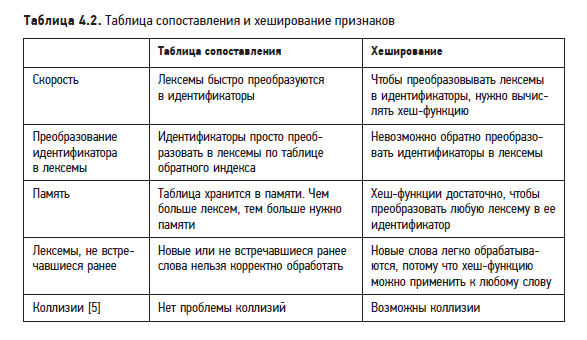
Сравним таблицу сопоставления с методом хеширования.
Подготовка видеоданных
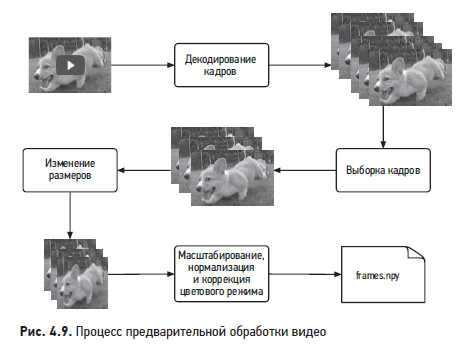
На рис. 4.9 показан типичный процесс предварительной обработки видеоматериала.
Разработка модели
Выбор модели
Как упоминалось в разделе «Формулировка проблемы как задачи МО», текстовые запросы преобразуются в эмбеддинги кодировщиком текста, а видеоданные — кодировщиком видео. В этом разделе мы рассмотрим возможные архитектуры моделей для каждого кодировщика.
Кодировщик текста
Входные и выходные данные типичного кодировщика текста изображены на рис. 4.10.
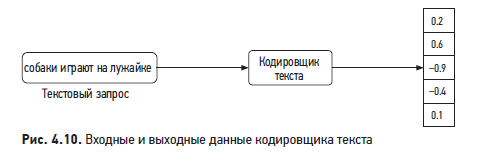
Кодировщик текста преобразует текст в векторное представление. Например, если два предложения имеют сходный смысл, то их эмбеддинги более похожи. Кодировщики текста создаются либо статистическими методами, либо на основе МО. Рассмотрим оба варианта.
Статистические методы
Эти методы преобразуют предложения в векторы эмбеддингов с помощью статистики. Два самых популярных статистических метода:
- мешок слов (BoW, Bag of Words);
- TF–IDF (Term Frequency — Inverse Document Frequency, «частота слова — обратная частота документа»).
Мешок слов. Этот метод преобразует предложение в вектор фиксированной длины. Вхождения слов в предложения моделируются с помощью матрицы, строки которой представляют предложения, а столбцы — индексы слов. Пример BoW показан на рис. 4.11.
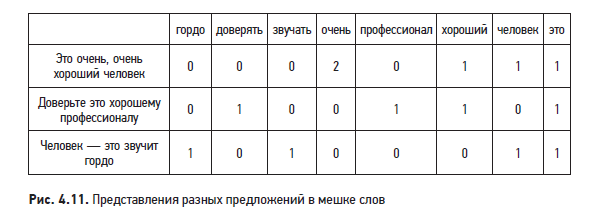
Мешок слов — простой метод, который быстро вычисляет представления предложений, но у него есть ряд недостатков.
- Не учитывается порядок слов в предложении. Например, у предложений «утром деньги, вечером стулья» и «утром стулья, вечером деньги» в мешке слов будут одинаковые представления.
- Полученное представление не отражает семантического и контекстного смысла предложения. Например, у двух предложений с одинаковым смыслом, но разными словами будут совершенно разные представления.
- Вектор представления является разреженным. Его размерность равна общему количеству уникальных лексем. Обычно оно очень велико, так что каждое представление в основном заполнено нулями.
TF–IDF. Это числовая статистика, которая должна отражать важность слова в документе, принадлежащем коллекции или корпусу текстов. TF–IDF создает такую же матрицу предложений и слов, как и мешок слов, но эта матрица нормализуется на основании частоты слов. Чтобы больше узнать о математических основах этого метода, обращайтесь к.
Поскольку TF–IDF назначает меньший вес часто встречающимся словам, представления этого метода обычно лучше, чем мешка слов. Однако здесь тоже есть свои ограничения:
- когда добавляется новое предложение, нужно выполнить нормализацию, чтобы заново вычислить частоты слов;
- порядок слов в предложении не учитывается;
- полученное представление не отражает семантический смысл предложения;
- представления получаются разреженными.
Таким образом, статистические методы обычно работают быстро, но не отражают контекстного смысла предложений, а представления разрежены. Методы на основе МО решают эти проблемы.
Методы на основе МО
В этих методах модель МО преобразует предложения в осмысленные эмбеддинги слов, так что расстояние между двумя эмбеддингами отражает семантическую близость соответствующих слов. Например, если два слова (скажем, «богатый» и «благосостояние») семантически близки, то их эмбеддинги располагаются близко в пространстве эмбеддингов. На рис. 4.12 представлена простая визуализация эмбеддингов слов в двухмерном пространстве эмбеддингов. Как видите, похожие слова группируются.

Существуют три распространенных метода преобразования текста в эмбеддинги, основанных на МО:
- слой сопоставления эмбеддингов;
- Word2vec;
- архитектуры на базе Transformer.
Слой сопоставления эмбеддингов
В этом методе добавляется слой, который ставит в соответствие каждому идентификатору вектор эмбеддинга. Пример показан на рис. 4.13.
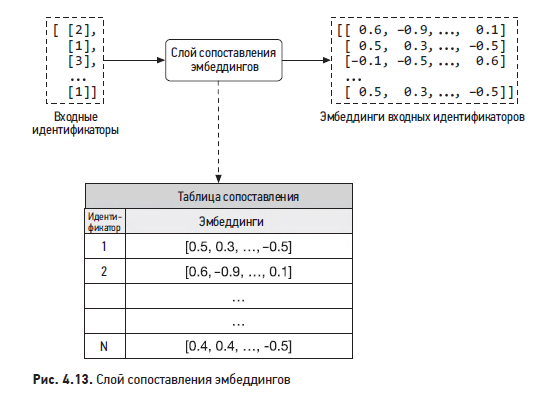
Слой сопоставления эмбеддингов — простое и эффективное решение, чтобы преобразовывать разреженные признаки (такие, как идентификаторы) в эмбеддинги фиксированной размерности. Примеры его использования еще встретятся в следующих главах.
Word2vec
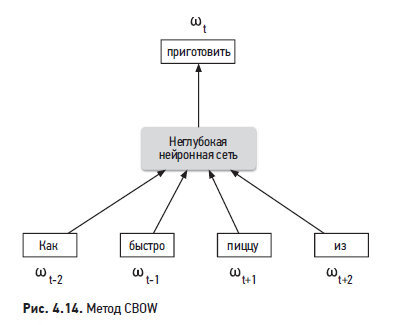
Word2vec — семейство взаимосвязанных моделей, с помощью которых создаются эмбеддинги слов. Эти модели базируются на архитектуре неглубокой нейронной сети и используют совместное вхождение слов в локальном контексте, чтобы обучаться на эмбеддингах слов. В частности, модель учится предсказывать центральное слово по окружающим словам. После фазы обучения модель способна преобразовывать слова в содержательные эмбеддинги.
На Word2vec базируются две основные модели: CBOW (Continuous Bag of Words, «непрерывный мешок слов») Система PYMK в LinkedIn и Skip-gram. На рис. 4.14 изображена высокоуровневая схема работы CBOW. Если вам захочется больше узнать об этих моделях, обращайтесь к.
Хотя Word2vec и слой сопоставления эмбеддингов просты и эффективны, свежие архитектуры на базе Transformer показывают многообещающие результаты.
Модели на базе Transformer
Преобразовывая слова в эмбеддинги, эти модели учитывают контекст слов в предложении. В отличие от моделей Word2vec, они производят разные эмбеддинги для одного и того же слова в зависимости от контекста.
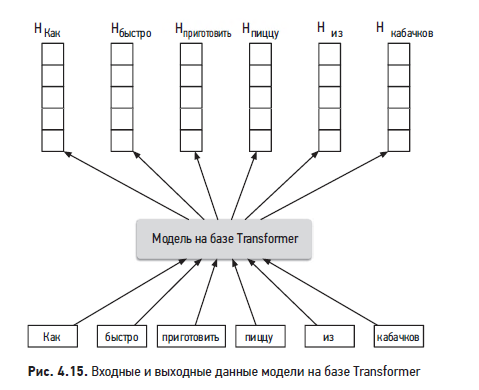
На рис. 4.15 показана модель на базе Transformer, которая принимает на вход предложение (набор слов) и генерирует эмбеддинг для каждого слова.
Эти модели чрезвычайно эффективно распознают контекст и вырабатывают содержательные эмбеддинги. Некоторые модели, включая BERT, GPT3 и BLOOM, продемонстрировали потенциал Transformer для разнообразных задач обработки естественного языка (NLP). В нашем случае для кодирования текста мы выберем архитектуру на базе Transformer — такую, как BERT.
На некоторых собеседованиях вам могут предложить рассмотреть модель на базе Transformer на более глубоком уровне. За дополнительной информацией обращайтесь к.
Кодировщик видео
Существует два архитектурных решения для кодирования видеоданных:
- модели на уровне видео;
- модели на уровне кадра.
Модели на уровне видео обрабатывают видеоролик целиком, чтобы создать эмбеддинг (рис. 4.16). Архитектура модели обычно базируется на 3D-свертках или на Transformer. Поскольку видео обрабатывается целиком, модель требует значительных вычислительных ресурсов.

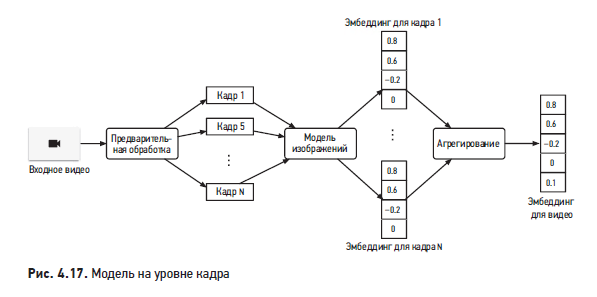
Модели на уровне кадра работают иначе. В этом случае эмбеддинг для видео вырабатывается в три шага (рис. 4.17):
- выполнить предварительную обработку видео и сформировать выборку кадров;
- запустить модель на выборочных кадрах и создать их эмбеддинги;
- агрегировать (например, усреднить) эмбеддинги кадров, чтобы получить эмбеддинг для видео.
Так как эта модель действует на уровне кадров, она часто работает быстрее и требует меньших вычислительных затрат. Однако модели на уровне кадров обычно не понимают аспектов развития во времени, таких как действия и перемещения на видео. На практике модели на уровне кадра предпочтительнее во многих случаях, когда не стоит задача анализировать развитие во времени.
В данном случае мы воспользуемся моделью на уровне кадра (такой, как ViT), чтобы обеспечить два преимущества:
- сократить скорость обучения и обслуживания запросов;
- сократить объем вычислений.
Обучение модели
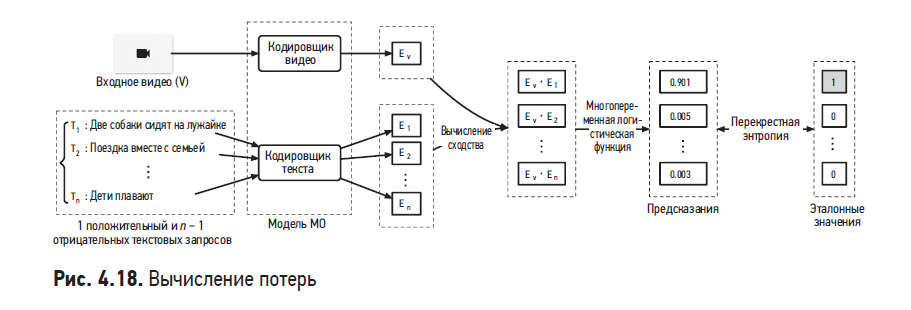
Чтобы обучить кодировщики текста и видео, мы применим метод контрастного обучения. Если вам захочется больше узнать об этом, обратитесь к разделу «Обучение модели» в главе 2.
На рис. 4.18 показано, как вычисляются потери в ходе обучения модели.
Алекс Сюй — опытный разработчик программного обеспечения и предприниматель. Ранее он работал в таких компаниях, как Twitter, Apple, Zynga и Oracle. Алекс получил степень магистра наук в Университете Карнеги-Меллона. Его страсть — проектирование и реализация сложных систем.
Более подробно с книгой можно ознакомиться на сайте издательства:
» Оглавление
» Отрывок
По факту оплаты бумажной версии книги на e-mail высылается электронная книга.
Для Хаброжителей скидка 25% по купону — Интервью
p/s идет Распродажа «Старый Новый год» в издательстве «Питер»
