Кластеризация текстовых документов по семантическим признакам (часть вторая: описание моделей)
Модели Word2Vec
Как было упомянуто в первой части публикации, модели получаются из classes — представления результата текста word2vec виде ассоциативно-семантических классов путем сглаживания распределений.
Идея сглаживания в следующем.
- Получаем частотный словарь обучающего материала, где каждому слову приписана его частота встречаемости по документам (т.е. в скольких документах это лексема встретилась).
- На основе этого частотного распределения для каждого слова класса считается его среднеквадратичное отклонение (или дисперсия, в данном случае не имеет принципиальной разницы).
- Для каждого класса считаем среднее по всем отклонениям его составляющих.
- Из каждого класса убираем «выбросы» — слова с большим среднеквадратичным отклонением:

Где SDw — среднеквадратичное отклонение каждого слова, avr (SDcl) — среднее среднеквадратичное по классу, k — коэффициент сглаживания.
Очевидно, что результат будет зависеть от коэффициента k. Его выбор — задача эмпирическая, он зависит от языка, объема обучающей выборки, ее однородности и пр. Но все-таки какие-то общие вещи попробуем выявить.
Построение и тестирование моделей
Для моделей использовался материал, собранный из дневного потока интернет, собранный по спискам наиболее частотных ключевых слов. Английский текст содержал около 170 млн. словоформ, русский — чуть менее миллиарда. Диапазон количества классов был от 250 до 5000 классов с шагом 250. Остальные параметры были использованы по умолчанию.
Тестирование проводилось на русскоязычном и англоязычном материале.
Методика тестирования в двух словах следующая: брались эталонные тестовые корпуса для классификации и прогонялись через модели кластеризации с различными параметрами: меняя количество классов и сглаживающий коэффициент можно продемонстрировать динамику изменения результата, а, следовательно, качества модели.
Английские пять корпусов взяты из открытого источника:
- 20NG-TEST-ALL-TERMS — 20 тем (10555K)
- MINI20-TEST — 20 тем (816K)
- R52-TEST-ALL-TERMS — 52 темы (1487K)
- R8-TEST-ALL-TERMS — 8 тем (1167K)
- WEBKB-TEST-STEMMED — 4 темы (1271K)
Русские корпуса пришлось использовать из закрытых разработок, поскольку открытых источников обнаружить не удалось:
- Ru1 — Корпус коротких сообщений — 13 тем (76K)
- Ru2 — Новостной корпус — 10 тем (577K)
При тестировании использовался простейший метод сравнения, без использования каких-либо сложных метрик. Выбор в пользу такой простейшей классификации (Dumb classifier) был сделан в виду того, что целью исследования было не улучшение результата классификации, а сравнительный анализ результатов при разных входящих параметрах. То есть был интересен не сам результат, а его динамика.
При этом на некоторых моделях кластеризации были проведены тесты с использованием логарифмической меры TFiDF, чтобы проверить, насколько в принципе эти результаты на этих моделях могут отличаться от результатов на моделях, обученных на лексических униграммах. Такие тесты показали, что результаты на моделях с ассоциативно-семантическими классами почти не уступают моделям на униграммах: наблюдалось небольшое ухудшение качества от 1 до 10%, в зависимости от тестового корпуса. Что говорит о конкурентоспособности полученных моделей кластеризации, учитывая, что они изначально не «заточены» под тематики.
Зависимость качества модели от количества классов
Со всеми корпусами были проведены тесты с разным количеством семантических классов: от 250 до 5000 с шагом 250 классов.
На рисунках 1 и 2 продемонстрированы зависимости точности классификации от количества классов моделей для русского и английского языков.

Рис. 1. Зависимость точности классификации от количества семантических классов word2vec для русскоязычных корпусов. По оси абсцисс — количество классов, по оси ординат — значения точности.
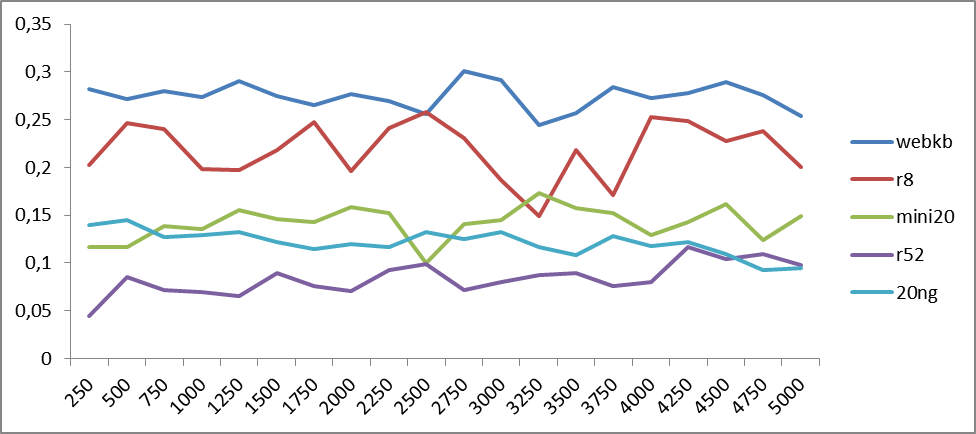
Рис. 2. Зависимость точности классификации от количества семантических классов word2vec для англоязычных корпусов. По оси абсцисс отложены количество классов, а по оси ординат — точность классификации.
Из графиков видно, что колебания точности имеют периодический характер, период которых может разниться в зависимости от тестируемого материала. Что бы определить тенденции, построим графики средних значений. 
Рис. 3. Среднее значение зависимость точности классификации от количества семантических классов word2vec для русскоязычных корпусов. По оси абсцисс — количество классов, по оси ординат — значения точности. Добавлена полиномиальная (6-ой степени) линия тренда.

Рис. 4. Среднее значение зависимость точности классификации от количества семантических классов word2vec для англоязычных корпусов. По оси абсцисс — количество классов, по оси ординат — значения точности. Добавлена полиномиальная (6-ой степени) линия тренда.
Из рисунков 3 и 4 уже видно, что качество результата в среднем растет с увеличением количества классов в диапазоне от 4 до 5 тысяч. Что, вообще говоря, не удивительно: более тонкое разбиение пространства приводит к его конкретизации. Но дальнейшее разбиение может привести к тому, что семантические классы начинают расслаиваться на однородные куски. А это уже приводит к падению точности, ибо классы перестают «зацепляться»: одному и тому же смыслу будут соответствовать разные семантические классы. Это и наблюдается в приближении к 5 тысячам классов как для русского, так и для английского языков.
Любопытны пики, имеющиеся на обоих рисунках в районе 500 классов: несмотря на то, что семантических классов мало (следовательно, классы перемешаны), тем не менее, наблюдается макро-семантическое объединение: классы в целом тяготеют к той или иной теме.
Из полученных результатов можно сделать вывод, что все-таки более оптимальное разбиение может находиться где-то между 4-ю и 5-ми тысячами классов.
Зависимость качества модели от сглаживающего коэффициента
На рисунке 5 показаны изменения точности классификации для корпуса R8 при разных коэффициентах сглаживания (для 1500 классов). Периодичность изменений для любого количества классов в пределах одного корпуса одинакова. Подобные графики наблюдаются для всех корпусов.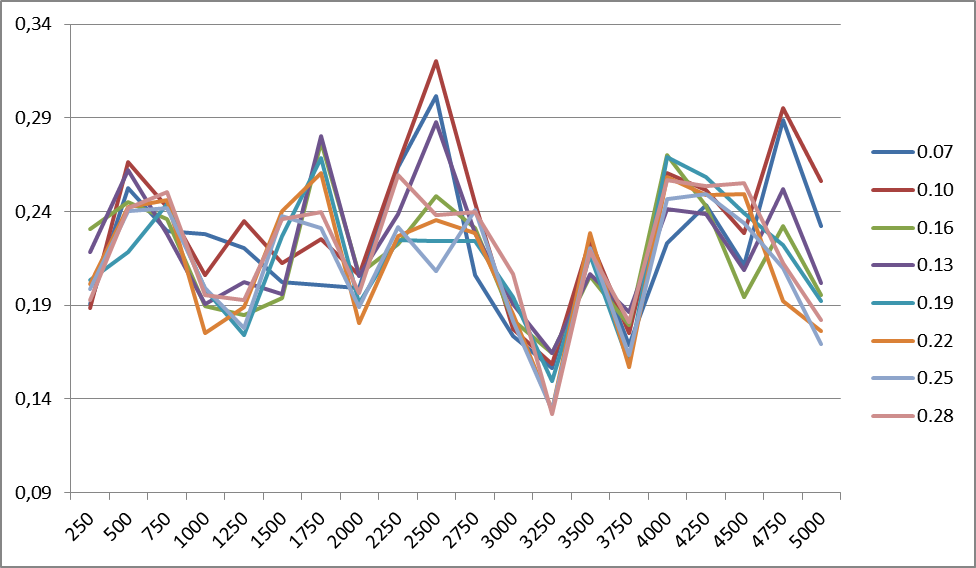
Рис. 5. Изменения точности классификации для корпуса R8 при разных значениях коэффициента сглаживания. Справа приведены значения коэффициента сглаживания.
Что бы выявить основные тенденции, построим графики средних значений точности сглаживающего коэффициента по всем корпусам для английского и русского языков.
 |
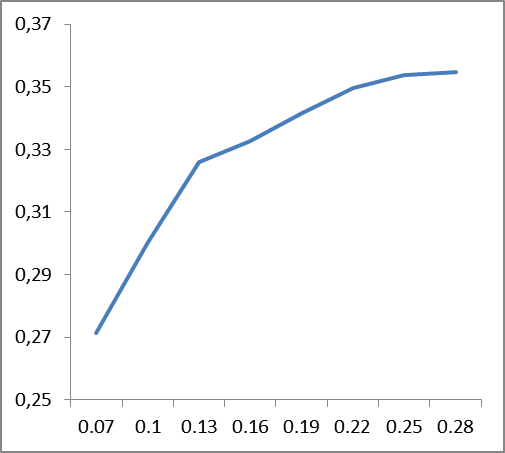 |
Рис 6. Зависимость изменения точности классификации (по вертикали) от значений сглаживающих коэффициентов (по горизонтали), усредненные данные по корпусам: слева — для английского языка, справа — для русского.
Из графиков, представленных на рис. 6 следует, что сглаживающий коэффициент языкозависим: если для английского языка стабильность наступает где-то около значения 0.22, то для русского это около 0.12. По всей видимости, это должно быть как-то связано со сложностью языка, его перплексией.
Сложно сказать, чем объясняется пик точности в начале (0.07) для английского языка. Его наличие вызвано поведением корпуса R8, и, возможно, обусловлено лексическим наполнением самого корпуса.
На самом деле, если сравнить сами данные моделей при разных коэффициентах сглаживания, то видно, что при вышеуказанных порогах часть высокочастотных слов (предлоги, союзы, артикли) фильтруется. Поэтому нет смысла вводить стоп-списки: данная лексика либо фильтруются, либо образуют отдельный ассоциативно-семантический класс с достаточно низким весом.
Зависимость вариабельности сглаживающего коэффициента от количества классов очень слабо влияет на изменение точности. При этом не удалось выявить какой-либо тенденции такого влияния для разного материала.
Выводы
Разумеется, это не единственный, и возможно, не самый лучший метод получения моделей, ибо является эмпирическим и зависит от множества факторов. К тому же сглаживание можно провести куда более хитрыми способами. Тем не менее, данный метод позволяет быстро и качественно построить модели и получать неплохие результаты кластеризации на больших объемах информации.
Приведем пример использования кластеризации на русскоязычном материале.
Пример
Кластеризация потока сообщений соц.медиа с поисковым запросом «Сбербанк».
Количество сообщений — 10 тысяч. Это примерно 10 МБ текста или 5–6 часов потока сообщений по теме Сбербанк.
В итоге получилось 285 кластеров, откуда сразу видно основные события, касающиеся Сбербанка.
Вот, к примеру, первые десять кластеров (заголовки первых сообщений):
- клиенты Сбербанка пожаловались на сбои в работе онлайн-сервиса — подобного рода 327 сообщений
- жиды хотят приватизировать Сбербанк в ближайшие 3 года — 77 сообщений
- ответы Сбербанка, типа: <имя> здравствуйте, к сожалению, в настоящий момент действительно есть перебои в работе… — 74 сообщения
- Сбербанк в 2017 году проведет тест квантовой передачи информации hi-tech — 73 сообщения
- в год своего 175-летнего юбилея Сбербанк дарит бесплатный вход в художественные музеи — 71 сообщений
- узнай о преимуществах молодежной дебетовой карты visa сбербанк и как купить толстовку за n рубль — 57 cообщений
- Минэкономразвития предложил включить Сбербанк в план приватизации — 58 сообщений
- Сбербанк сообщил о сбоях в работе своих систем — 60 сообщений
- Владимир Путин принял участие в конференции вперед в будущее роль и место России — 61 сообщение (Сбербанк так же принял участие);
- Греф опроверг информацию о приватизации сбербанка — 64 сообщения
Скорее всего, 1-ый и 8-ой кластеры можно объединить в макро кластеры на основе дополнительной информации, например, использование гео-меток, источников сообщений, предикативных отношений между объектами и пр. Но это уже другая задача, о которой расскажем в следующий раз.
Ознакомиться с примерами и демо-реализацией алгоритма можно тут.
