Делаем спеллчекер на фонетических алгоритмах своими руками
Машинный спеллчекинг — это целое искусство и не зря поисковые гиганты нанимают талантливых математиков работать над этой задачей. Но существуют и простые механизмы автокоррекции, основанные на фонетических принципах, которые уже способны давать результат и улучшать пользовательский опыт. О них и поговорим в статье. Тем более, что они так или иначе являются фундаментом для более сложных решений.
В конце статьи приводится ссылка на открытый датасет с ошибками и опечатками. Можно собрать по нему ценную статистику и потестировать свои алгоритмы спеллчекинга.
Орфографические ошибки и опечатки
Все ошибки при наборе текста можно разделить на два больших класса — орфография и опечатки. Про причины возникновения первых мы поговорим ниже, а опечатки люди делают понятно почему — пальцы толстые, клавиатура непривычная, не выспался (-лась, -лось, -лись) и т.д.
С точки зрения построения системы автокоррекции можно разделять эти ошибки, а можно строить универсальный механизм. Но вот с позиций пользовательского опыта эти два типа ошибок имеют принципиально разный вес. Если опечатку пользователь способен быстро увидеть и исправить самостоятельно, то вот орфографическую ошибку, тем более если мест неуверенности несколько, человеку исправить намного сложнее. Скорее всего он пойдёт гуглить спорное слово, вы упустите внимание пользователя и, возможно, потеряете посетителя сайта.
Откуда берутся орфографические ошибки
Русское письмо — фонетическое. Принцип простой: буквы привязаны к определённым звукам и на письме мы передаём звучание слова. (В сильно упрощённом варианте, конечно.) Казалось бы делов, выучил соответствие букв и звуков и пошёл строчить текст. Собственно изначально так и было — разные люди писали одни и те же слова по-разному. Проблем тут две. Во-первых, все особенности произношения передаются на письме. И если понять чужой говор ещё можно — ведь при говорении мы используем интонацию, в словах есть ударение, добавляется невербалика и т.д. — то читать такой текст довольно-таки сложно. Ниже приведу пример из Янко крУль албАнскай:
…за нажи дируцца врываюца разнимают аркестрам
N.B. Обратите внимание! Особенно сложно распознать короткие слова — количество вариантов начинает расти с большой скоростью. Эта особенность и при машинном спеллчекинге присутствует.
Вторая проблема при «свободном письме» возникает с юридическими документами, в которых любая неоднозначность смерти подобна. Попробуй докажи, что ты имел ввиду то, что имел ввиду, если каждый пишет и трактует написанное по-своему.
В общем необходимость унификации письма люди стали понимать довольно давно. И, надо отдать должное, огромную работу в этом направлении проделали при советской власти. Собственно современная орфография русского языка не такая уж и современная. С некоторыми поправками мы все изучаем и пользуемся системой 1956 года.
Итак, подведём итог. Орфография — это договорённость между людьми, закреплённая на официальном уровне, которая позволяет в любой ситуации однозначно передать на письме некий смысл, выраженный словами. В редких ситуациях существуют равнозначные варианты написания слов (тоннель и туннель), но их можно по пальцам пересчитать.
Любая договорённость подразумевает кривую обучения и, в случае с русским языком, она довольно-таки длинная. В силу этого все люди владеют грамотным письмом в разной степени и, будем уж честными с собой, сейчас ситуация с грамотностью не самая оптимистичная.
Фонетический принцип
Хорошая новость состоит в том, что отражение слова на письме связано с его звуковым воплощением. Следовательно существует ограниченное число способов понаделать орфографических ошибок в одном слове.
Дальше — больше. Все буквы можно разбить на классы эквивалентности по принципу фонетической близости звуков, которым они соответствуют. В границах каждого класса существует некоторая не очень маленькая вероятность того, что на месте одной буквы класса пользователь, совершив ошибку, напишет другую. Выбрав из каждого класса одного представителя и заменив все буквы в слове на представителя их класса, получаем фонетическую метку.
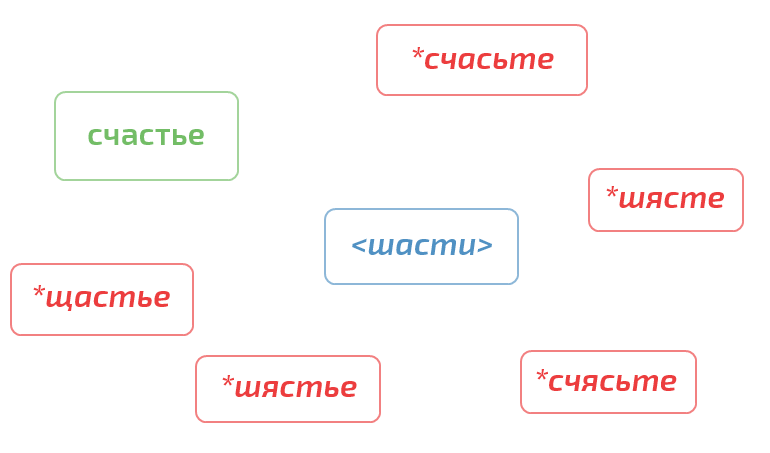
Чем-то напоминает фонетические разборы, которые делают школьники младших классов. Только теперь эта техника находит вполне себе практическое применение.
Собственно идея не новая — похожие алгоритмы, только для английского языка, были предложены ещё в начале XX века и продолжают развиваться и совершенствоваться. См. Soundex, Metaphone.
Детали реализации
С высоты птичьего полёта алгоритм выглядит так:
- К каждому слову в словаре применяем ряд правил и получаем на выходе фонетическую метку — условно-упрощённое звучание слова.
- Проверяемое слово компилируется в метку по ТЕМ ЖЕ ПРАВИЛАМ и поиск по словарю осуществляется по метке.
- Пользователю предлагается на выбор несколько вариантов исправлений.
- Для автокоррекции многословных последовательностей слов (например запросов на поиск) алгоритм применять можно, но без дополнительной информации о сочетаемости слов качество может страдать на длинных запросах.
- Алгоритм предназначен для предоставления пользователю вариантов исправлений, встраивать его в саму систему поиска не стоит.
Правила компиляции фонетической метки
N.B. Здесь и ниже, фонетические метки на любой стадии обработки будут заключаться в угловые скобки. Ошибочное написание слов будет предваряться звёздочкой и выделяться курсивом. Это позволяет снизить негативный эффект, оказываемый работой с ошибочными написаниями слов.
1. Слитно, раздельно, через дефис
Большой класс орфографических ошибок — написание раздельно/слитно/через дефис. Поэтому при компиляции фонетической метки все символы, кроме русских букв, удаляются. Этот пункт применим к словарным записям, представляющих собой устойчивые группы из нескольких слов (потому что; в следствие; за границу).
по-разному → <поразному>
потому что → <потомучто>
в следствие → <вследствие>
за границу → <заграницу>
2. Двойные согласные
Вторая по популярности сложность — двойные согласные. Соответственно все две и более одинаковые буквы заменяем на одну:
искуССтво → <искуСтво>
Имеет смысл повторить склеивание на последнем этапе, склеивая не буквы, а звукометки, чтобы учесть ошибки типа:
*иЗСкуЗСтво
француЗСкий (самое популярное неправильное написание *французкий).
3. Мягкий знак, твёрдый знак
Мягкий и твёрдый знаки удаляем из слова. Часто эти буквы либо забывают поставить в нужное место, либо наоборот — ставят куда не следует (*японський).
cЪедобный → <седобный>
площадЬ → <площад>
4. Упрощение групп согласных
стн → сн: местный, честный, безызвестный, искусный
ндш → нш: ландшафт, мундштук, эндшпиль
стл → сл: счастливый, жалостливый, совестливый
здн → зн: поздно, бездна, праздник
вств → ств: здравствуй, чувствовать, баловство, колдовство
А также менее продуктивные:
здц → сц: под уздцы
лнц → нц: солнце
ндц → нц: голландцы
нтг → нг: рентген
рдц → рц: сердце
рдч → рч: сердчишко
5. Характерные сочетания букв
Характерные двухбуквенные сочетания со статистически заметными случаями совершения ошибок:
сч, зч, жч, сш, сщ, тч → ш (*сЩастье, *закаЩик, *муЩина, *сумаШедший, *АЩистка)
стг → сг (*бюЗгалтер)
хг → г (*буГалтер, *двуГодичный, *трёГлавый)
тс, дц → ц (*деЦтво, *богаЦтво, *спорЦмен)
6. Гласные буквы
Гласные заменяем по принципу:
a, о, ё → а
ю, у → у
я, ы, и, е, э → и
Фонетически буква Ё может передавать два звука ЙОТ-О. И если посмотреть по статистике пользовательских ошибок, то пара Ё — О является наиболее вероятной. Но на практике, если ваш словарь не ёфицирован или пользователи не используют Ё при вводе, то лучше сводить Ё к И-классу (ы, и, е, э).
Буква Я, по аналогии, может передавать два звука ЙОТ-А. Но по статистике люди чаще, совершая ошибку, пишут Е или И вместо Я (*премая, *кипеток, *выпримлять). Так что отнесение Я к И-классу (ы, и, е, э) однозначно будет более выгодным.
N.B. Если быть совсем въедливым, то после шипящих и Ц более вероятной будет как раз ошибка А — Я. (Наоборот быть не может — в русской орфографии после этого класса согласных Я никогда не пишется.) Можно встроить это правило в алгоритм.
Какие буквы предшествуют обозначенным на тепловой карте парам эталон-ошибка.
7. Оглушение согласных
Согласные оглушаем:
б → п
з → с
д → т
в → ф
г → к
В некоторых реализациях предлагается не делать оглушение в сильной позиции (т.е. если за буквой следует одна из букв р, л, м, н, в, й или гласная). На деле получается переусложнение и алгоритм начинает работать хуже.
8. Шипящие и Ц
Отдельная история с шипящими и Ц, не зря им уделяется так много внимания при изучении правописания:
ш, щ, ч, ж, ц → ш
Применимость и сравнение с другими алгоритмами
Главное преимущество предложенного алгоритма — его можно использовать везде, где есть быстрый поиск по индексу. Т.е. с любой, даже самой древней СУБД. Второе немаловажное преимущество — пишется и внедряется такой алгоритм за пару часов (с запасом).
Его серьёзный недостаток — это неумение работать с опечатками, пропусками и лишними буквами.
N.B. Если сравнивать с распространённым тестом на расстояние Левенштейна, то фонетический алгоритм даёт выигрыш при наличии нескольких орфографических ошибок. В то же время алгоритм Л. позволяет отлавливать опечатки. Комбинируя сильные стороны обоих подходов, можно придти к взвешенному алгоритму Левенштейна.
Пути для улучшения
Если вы предоставляете пользователям варианты на выбор, будет лучше, с точки зрения пользовательского опыта, отранжировать их по степени соответствия исходному запросу. Сделать это несложно: после набивки вариантов алгоритмом, сравниваете их с исходным запросом, запоминая для каждой замены её вероятность. Потом вероятности отдельных замен перемножаются между собой и получается итоговая цифра.
Вторая возможность для улучшения алгоритма — делать дополнительные метки, где один из символов заменяется джокер-символом (например звёздочкой). Это даст возможность работать в том числе с опечатками или специфическими ошибками, но количество меток вырастет на порядок.
Обоснование работы алгоритма
Алгоритм представляет собой чистую эвристику, основанную на фонетических особенностях русского языка и исследовании статистики по реально совершаемым ошибкам (можете скачать датасет в конце статьи и поэкспериментировать самостоятельно). Причём замены делаются намерено грубые — при экспериментах любая попытка тонкой настройки алгоритма давала ухудшение.
Если хотите филигранные правила — смотрите в сторону машинного обучения.
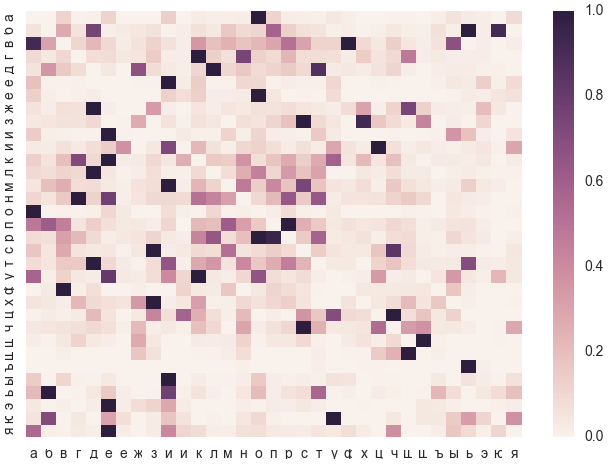
Тепловая карта читается по строкам. Например для буквы а наиболее вероятная ошибка — о. Все остальные ошибки существенно менее вероятны.
А, например, для б наиболее вероятными будут опечатки ь, ю и, реже, д. Фонетическая ошибка п уступает по частоте предыдущим трём.
а
о 469.71785203582147
и 65.14134525309888
п 56.298463123398875
в 55.03770053515469
е 54.09659475563201
я 40.64468406336955
ы 28.36510732470879
...import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
df = pd.read_csv('https://raw.githubusercontent.com/dkulagin/kartaslov/master/dataset/orfo_and_typos/letter.matrix.csv',
sep=';', index_col='INDEX_LETTER')
sns.heatmap(df)
plt.show()Оценка результатов
Оценка результатов сильно зависит от того, как мерить.
На тестовом датасете L1.5 (грубо: расстояние Левенштейна в паре слово-ошибка не больше единицы), включающем также опечатки, алгоритм даёт точность в 25%. Но это на словах любой длины. Если взять минимальную длину 5, то точность будет уже 34%. Для семи (средняя длина слова в русском языке) — 41%.
Звёзд с неба не хватает, но для простого алгоритма это более чем достойный результат. Если добавить грубый стемминг с отсечением окончаний, можно вытянуть ещё 2–3%.
На тестовом датасете L1.5+PHON (предыдущий датасет + пары слово-ошибка эквивалентные по фонетической метке), алгоритм даёт прирост точности в целых 5%. С точки зрения статистики подмешивать результат работы алгоритма в тестовый набор — смертный грех, но эта цифра говорит о том, что доля мульти-орф-ошибок, т.е. где пользователь ошибается в нескольких местах одновременно, не такая уж и маленькая. А это — конёк фонетического алгоритма.
Если приведённое качество вас не устроит — придётся вложиться в более умные алгоритмы, но их уже так просто на базе СУБДшных индексов не построить.
Датасет
Чтобы потренировать свой алгоритм автокоррекции, а также чтобы собрать ценную статистику, забирайте открытый датасет по ошибкам, допущенными реальными людьми. Включает как опечатки, так и орфографию:
Датасет: орфографические ошибки и опечатки
Ссылки
- Обзор фонетических алгоритмов на Хабре от Никиты Сметанина
- Русский MetaPhone
- Фонетика на проекте «Русский на пять»
- Soundex (Википедия)
- Metaphone (Википедия)
- Penisland, или как написать спеллчекер
