[recovery mode] Как я создаю базу данных для своих приложений
Забыл сказать самое главное, можно сказать что это моя проба пера тут. И так поехали.
Если в нашем приложении больше 5 таблиц, то уже было бы не плохо использовать какой-нибудь инструмент для визуального проектирования архитектуры БД. Поскольку для меня это хобби, то и использую я абсолютно бесплатный инструмент под названием Oracle SQL Developer Modeler (скачать его можно тут).

Данная программа позволяет визуально рисовать таблицы, и строить взаимосвязи с ними. Многие ошибки проектирования архитектуры БД можно избежать при таком подходе проектирования (это я уже вам говорю как профессиональный программист БД). Выглядит это примерно так:
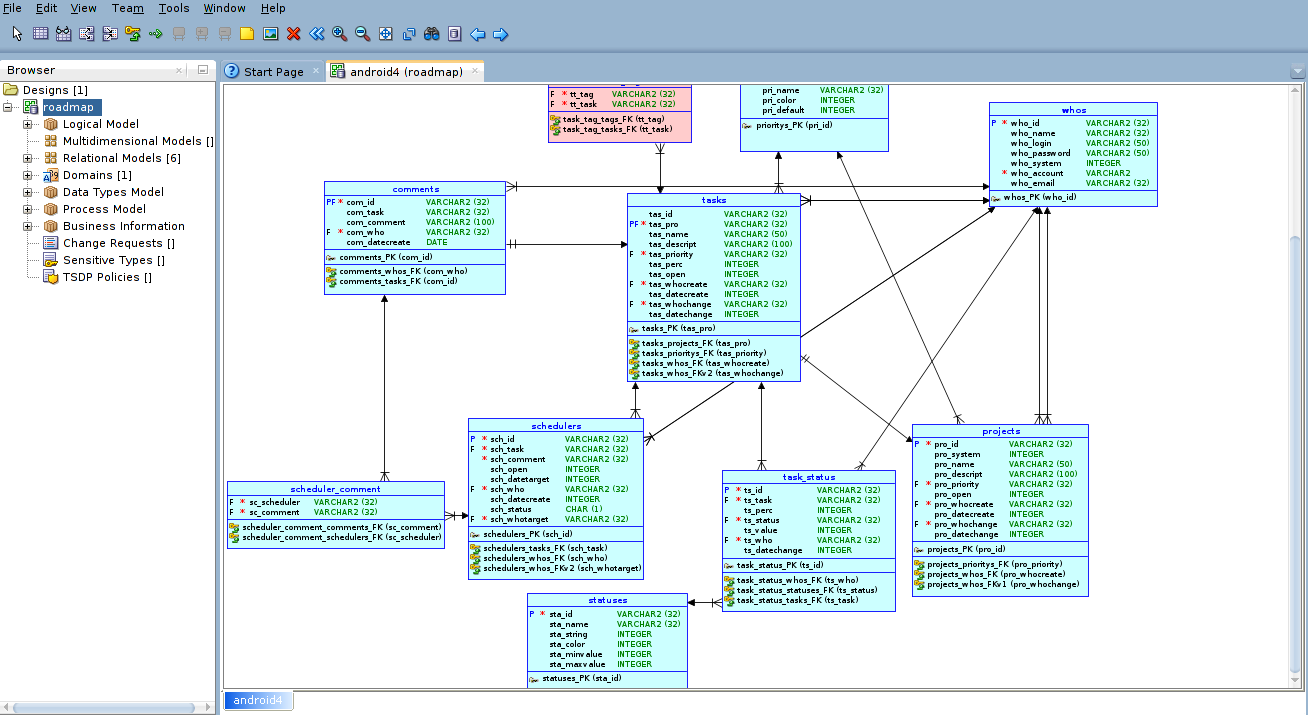
Спроектировав саму архитектуру, приступаем к более нудной части, заключающийся в созданий sql кода для создания таблиц. Для помощи в этом вопросе, я уже использую инструмент под названием SQLiteStudio (его в свою очередь можно скачать тут тут).
Данный инструмент является аналогом таких известных продуктов как SQL Naviagator, Toad etc. Но как следует из названия, заточен он под работу с SQLite. Он позволяет визуально создать БД и получить DDL код создаваемых таблиц. Кстати, он также позволяет создавать представления (View), которые вы тоже при желании можете использовать в своем приложении. Не знаю насколько правильный подход использования представлений в программах для Android, но в одном из своих приложений я использовал их.
Собственно говоря я больше не каких сторонних инструментов не использую, и дальше начинается магия с Android Studio. Как я уже писал выше, если начать внедрять SQL код в Java код, то на выходе мы получим плохочитаемый, а значит и плохо расширяемый код. Поэтому я выношу все SQL инструкции во внешние файлы, которые у меня находятся в директории assets. В Android Studio выглядит это примерно так:
 »
»
Теперь давайте посмотрим на код внутри моего DBHelper который я использую в своих проектах. Сначала переменные класса и конструктор (тут без каких либо неожиданностей):
private static final String TAG = "RoadMap4.DBHelper";
String mDb = "db_";
String mData = "data_";
Context mContext;
int mVersion;
public DBHelper(Context context, String name, int version) {
super(context, name, null, version);
mContext = context;
mVersion = version;
}
Теперь метод onCreate и тут становится уже интереснее:
@Override
public void onCreate(SQLiteDatabase db) {
ArrayList tables = getSQLTables();
for (String table: tables){
db.execSQL(table);
}
ArrayList> dataSQL = getSQLDatas();
for (HashMap hm: dataSQL){
for (String table: hm.keySet()){
Log.d(TAG, "insert into " + table + " " + hm.get(table));
long rowId = db.insert(table, null, hm.get(table));
}
}
}
Логически он разделен на два цикла, в первом цикле я получаю список SQL — инструкций для создания БД и затем выполняю их, во втором цикле я уже заполняю созданные ранее таблицы начальными данными. И так, шаг первый:
private ArrayList getSQLTables() {
ArrayList tables = new ArrayList<>();
ArrayList files = new ArrayList<>();
AssetManager assetManager = mContext.getAssets();
String dir = mDb + mVersion;
try {
String[] listFiles = assetManager.list(dir);
for (String file: listFiles){
files.add(file);
}
Collections.sort(files, new QueryFilesComparator());
BufferedReader bufferedReader;
String query;
String line;
for (String file: files){
Log.d(TAG, "file db is " + file);
bufferedReader = new BufferedReader(new InputStreamReader(assetManager.open(dir + "/" + file)));
query = "";
while ((line = bufferedReader.readLine()) != null){
query = query + line;
}
bufferedReader.close();
tables.add(query);
}
} catch (IOException e) {
e.printStackTrace();
}
return tables;
}
Тут все достаточно просто, мы просто читаем содержимое файлов, и конкатенируем содержимое каждого файла в элемент массива. Обратите внимание, что я произвожу сортировку списка файлов, так как таблицы могут иметь внешние ключи, а значит таблицы должны создаваться в определенном порядке. Я использую нумерацию в название файлов, и с помощью нею и произвожу сортировку.
private class QueryFilesComparator implements Comparator{
@Override
public int compare(String file1, String file2) {
Integer f2 = Integer.parseInt(file1.substring(0, 2));
Integer f1 = Integer.parseInt(file2.substring(0, 2));
return f2.compareTo(f1);
}
}
С заполнением таблиц все веселей. Таблицы у меня заполняются не только жестко заданными значениями, но также значениями из ресурсов и UUID ключами (я надеюсь когда-нибудь прийти к сетевой версии своей программы, что бы мои пользователи могли работать с общими данными). Сама структура файлов с начальными данными выглядит так:
 »
»
Несмотря на то, что файлы у меня имеют расширение sql, внутри не sql код, а вот такая штука: prioritys
pri_id:UUID:UUID
pri_object:string:object_task
pri_name:string:normal
pri_color:color:colorGreen
pri_default:int:1
prioritys
pri_id:UUID:UUID
pri_object:string:object_task
pri_name:string:hold
pri_color:color:colorBlue
pri_default:int:0
prioritys
pri_id:UUID:UUID
pri_object:string:object_task
pri_name:string:important
pri_color:color:colorRed
pri_default:int:0
prioritys
pri_id:UUID:UUID
pri_object:string:object_project
pri_name:string:normal
pri_color:color:colorGreen
pri_default:int:1
prioritys
pri_id:UUID:UUID
pri_object:string:object_project
pri_name:string:hold
pri_color:color:colorBlue
pri_default:int:0
prioritys
pri_id:UUID:UUID
pri_object:string:object_project
pri_name:string:important
pri_color:color:colorRed
pri_default:int:0
Структура файла такая: я выполняю вызов функции split (»:») применительно к строчке и если получаю что ее размер равен 1 то значит это название таблицы, куда надо записать данные. Иначе это сами данные. Первое поле это название поля в таблице. Второе поле тип, по которому я определяю что мне надо в это самое поле записать. Если это UUID — это значит мне надо сгенерировать уникальное значение UUID. Если string значит мне надо из ресурсов вытащить строковое значение. Если color, то опять-таки, из ресурсов надо вытащить код цвета. Если int или text, то я просто преобразую данное значение в int или String без каких либо телодвижений. Сам код выглядит вот так:
private ArrayList> getSQLDatas() {
ArrayList> data = new ArrayList<>();
ArrayList files = new ArrayList<>();
AssetManager assetManager = mContext.getAssets();
String dir = mData + mVersion;
try {
String[] listFiles = assetManager.list(dir);
for (String file: listFiles){
files.add(file);
}
Collections.sort(files, new QueryFilesComparator());
BufferedReader bufferedReader;
String line;
int separator = 0;
ContentValues cv = null;
String[] fields;
String nameTable = null;
String packageName = mContext.getPackageName();
boolean flag = false;
HashMap hm;
for (String file: files){
Log.d(TAG, "file db is " + file);
bufferedReader = new BufferedReader(new InputStreamReader(assetManager.open(dir + "/" + file)));
while ((line = bufferedReader.readLine()) != null){
fields = line.trim().split(":");
if (fields.length == 1){
if (flag == true){
hm = new HashMap<>();
hm.put(nameTable, cv);
data.add(hm);
}
// наименование таблицы
nameTable = line.trim();
cv = new ContentValues();
continue;
} else {
if (fields[1].equals("UUID")){
cv.put(fields[0], UUID.randomUUID().toString());
} else if (fields[1].equals("color") || fields[1].equals("string")){
int resId = mContext.getResources().getIdentifier(fields[2], fields[1], packageName);
Log.d(TAG, fields[1] + " " + resId);
switch (fields[1]){
case "color":
cv.put(fields[0], resId);
break;
case "string":
cv.put(fields[0], mContext.getString(resId));
break;
default:
break;
}
} else if (fields[1].equals("text")){
cv.put(fields[0], fields[2]);
} else if (fields[1].equals("int")){
cv.put(fields[0], Integer.parseInt(fields[2]));
}
}
flag = true;
}
bufferedReader.close();
}
} catch (IOException e) {
e.printStackTrace();
}
return data;
}
Ну и в качестве постскриптума: я повторюсь сказав что я любитель в программировании под Android, что пол-беды. Вторая беда, что в моем окружении нет программистов под Android и собственно говоря не с кем не посоветоваться не устроить мозговой штурм как лучше что-то сделать. Приходится идти методом научного тыка, по пути наступая на грабли. Иногда бывает больно, но в целом круто. Проект над которым я сейчас работаю, уже переживает 4 реинкарнацию. Поэтому просьба не стреляйте в пианиста, я играю как умею. Если напишите как сделать лучше, буду благодарен и рад.
Комментарии (14)
 alix_ginger
alix_ginger
2 апреля 2017 в 11:47
+3↑
↓
На мой взгляд, и я думаю, многие согласятся, можно достичь результата быстрее и с меньшим количеством потенциальных ошибок, если использовать какой-нибудь ORM-фреймворк. Plesser
Plesser
2 апреля 2017 в 11:51
0↑
↓
Я читал несколько статей про ORM-фрейморвки, и несмотря на ряд проблем, описываемых там, думаю когда нибудь перейти на них. А может и Google к тому времени включит какой нибудь фреймворк в свой официальный SDK.
2 апреля 2017 в 13:45
0↑
↓
>Почему в книгах и в статьях не описываются инструменты для проектирования архитектуры базы данных и какие-нибудь паттерны для работы с базами данных на этапе их создания я честно говоря не знаю.Между «я не знаю» и «этого нет» на самом деле очень большая разница. Этой теме уже лет 20, как минимум, и книг написано полно. Вы где-то не там ищете видимо.
-
Plesser
2 апреля 2017 в 13:50
0↑
↓
Наверное мне стоило уточнить, что я говорю про книги по программированию под Android2 апреля 2017 в 14:02
–1↑
↓
А какая разница? Вы же сами говорите про проектирование архитектуры базы и паттерны?Я знаю примерно один существенный фактор, который реально влияет именно на проектирование, когда мы говорим про Андроид — что у вас обычно очень мало ресурсов. И в общем-то довольно узкий выбор самих СУБД.
-
Plesser
2 апреля 2017 в 14:12 (комментарий был изменён)
+2↑
↓
Как бы правильно выразить мою мысль… Вот откройте любую книгу или статью посвященную работе с БД под Android. Во всех книгах и статьях разбираются простые примеры (что логично) с внедрением SQL кода в код написанный на Java. С моей точки зрения, это как минимум дискуссионый вопрос.
Сам подход создания таким образом БД очень не удобный. Причем ладно я, Я зарабатываю на хлеб программированием на PL/SQL и я знаю инструменты для работы с БД и как они работают. Я могу найти способы как использовать уже имеющиеся знания для помощи при написания приложения (правильный или не правильный у меня подход это другой разговор). Собственно говоря, этой теме как раз и посвященна моя статья.
А вот новичку в программировании вынос мозга при проектировании своего приложения (при внедрения sql кода в java код), которое использует БД, гарантирован (это мое имхо).То есть эта статья, не что иное как выработка подхода проектирования БД и внедрения его в приложение, которое будет работать на устройстве.
2 апреля 2017 в 15:11
0↑
↓
Как вы боритесь с миграцими? особенно если апдейт идет через несколько версий? (с версии 3 до версии 6 например) К сожалению в более менее среднем приложении этот вопрос всплывает не редко и это один из самых больных вопросов.-
Plesser
2 апреля 2017 в 15:15 (комментарий был изменён)
0↑
↓
1) SQLiteStudio при изменении структуры таблицы сам генерит скрипт для изменения таблицы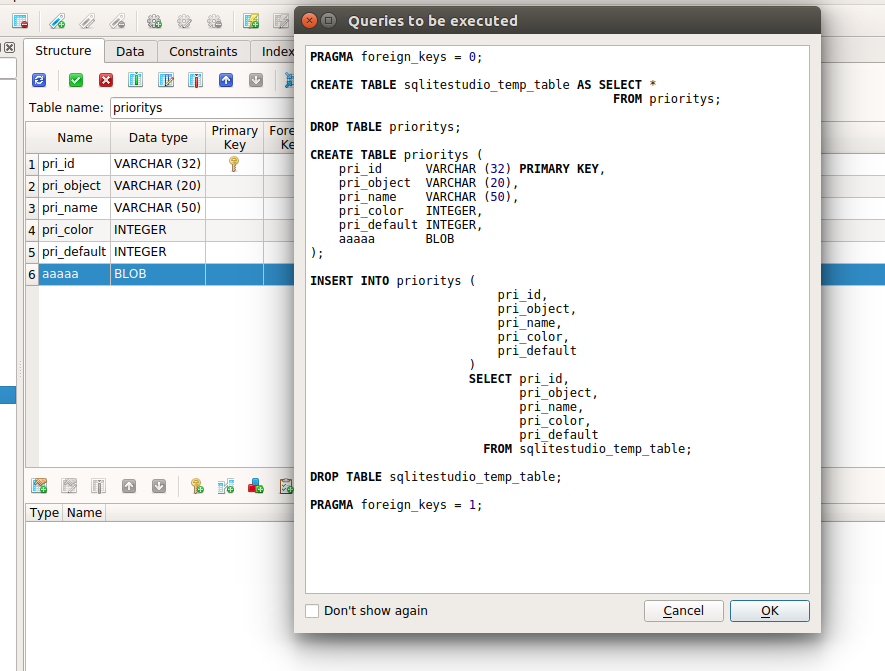 »
» 2) Что касается миграции с версии 3 на версию 6 — это хороший вопрос… пока не готов на него ответить. Спасибо что подняли его, буду думать :)
 Bringoff
Bringoff
2 апреля 2017 в 18:50
0↑
↓
По идее, если надо мигрировать через несколько версий, поочередно будут происходить миграции 3→4→5→6
2 апреля 2017 в 18:56
0↑
↓
Да, это очевидно. Я для своих проектов использую подобное. Но с недавних пор начал задумываться над подобным стилем, что привел автор: хелпер + скрипты в ассетах. Вот и стало интересно как он это делает. В моем подходе я использую массив миграций, соответственно если если первая версия базы имеет номер 1, но ее можно привести к индексу массива: версия — 1, соответственно для миграции с n на m надо взять срез n…m-1. В подходе автора не совсем очевидно как это взять. А так было бы полезно адаптировать под свои нужды.
-
Plesser
2 апреля 2017 в 19:04
0↑
↓
В подходе автора это не то что не очевидно, а вообще не реализовано… Но теперь благодаря идее Bringoff автор понял куда надо двигаться, за что он крайне благодарен и Вам и Bringoff. Правильно поставленный вопрос много-го стоит
-
Plesser
2 апреля 2017 в 18:56
0↑
↓
кстати это решение
2 апреля 2017 в 15:15
+1↑
↓
Навскидку, несколько замечаний по коду:- BufferedReader желательно закрывать в секции finally или использовать try-with-resource
- Контенкация строк в цикле — зло. В Java строки неизменяемые и это плодит новые объекты при каждой итерации. Используйте StringBuilder или StringBuffer.
- printStackTrace () в секции catch — имеет смысл только при отладке. Если исключение возникнет при работе готового приложения — есть вероятность, что вы об этом и не узнаете. Кидайте в лог или ловите/обработывайте все сразу выше.
- … файлы имеют расширение sql, внутри не sql код … — подумайте, какого будет человеку который будет поддерживать ваш код. В sql-файлах ожидаются скрипты, не нужно пихать в него сырые табличные данные. Имхо (могу ошибаться), лучше уж — csv или какой-нибудь dat-файл.
- Использование «вложенных» коллекций в довольно простых случаях (ArrayList
). Java — это объектно-ориентированный язык, лучше создать информативный объект враппер. - Обилие magic numbers — сразу бросаются в глаза индексы массивов, но и строковых литералов хватает. Выносите в константы, читаемость только улучшиться.
- Ну и классическое — раздутые методы с кучей вложенных операторов, if (flag == true), неочевидные названия переменных и прочие ошибки начинающих.
-
Plesser
2 апреля 2017 в 15:20
0↑
↓
Большое спасибо за Ваши замечания! Как мне не хватает вот таких замечаний :(
