Кластер PostgreSQL внутри Kubernetes: что нужно знать для успешного внедрения
В этой статье расскажу про PostgreSQL и его работу внутри кластера Kubernetes. Небольшое превью, о чем поговорим: как появился PostgreSQL, какие у него есть High Availability обвязки, как обеспечивается отказоустойчивость внутри Kubernetes и какие существуют Kubernetes-операторы.

Будут схемы-примеры для наглядности и обзор возможных кейсов, начнем!
Для погружения — (совсем) краткая история PostgreSQL
Postgre вышел в opensource из университета Беркли в 1996 году. Следующие два года шла стабилизация его работы и разрабатывалась базовая функциональность. Дальше возник вопрос: как сделать совместимой эту систему со стандартными SQL? И вот уже в 1998 году началось развитие самого ядра. Позже появилась необходимость в разработке возможностей enterprise уровня. Одной из таких возможностей, о которой мы в подробностях поговорим далее, является потоковая репликация. Именно она лежит в ядре отказоустойчивости PostgreSQL и без нее не было бы данной статьи.

Потоковая репликация
Она появилась в 2010 году вместе с релизом PostgreSQL 9.0. Прошло уже более 10 лет, однако, пока ни один релиз не включил в себя штатные механизмы переключения между мастером и репликой. Из-за этого могут возникать различные проблемы. Рассмотрим, какие они бывают, на типичных кейсах.
Кейс №1 — идеальный (без потери данных)
Тут все просто: у нас есть мастер и полностью синхронизированная с мастером реплика. В какой-то момент мы «аккуратно» останавливаем мастер и делаем standby новым мастером. В итоге мы, не теряя данные, корректно продолжаем работу.
Кейс №2 — более проблемный (часть данных потеряна)
Представим, у нас работал мастер, но по каким-то причинам он аварийно завершил работу, и часть данных не успела «доехать» до standby. Мы принимаем решение сделать standby новым мастером. В этом случае теряется небольшая часть данных, которая не успела передаться с мастера до standby.
Кейс №3 — самый неприятный (split brain)
В этом случае у нас также есть мастер и standby, но в какой-то момент, допустим, мастер перестал быть доступным по сети. И мы приняли решение активировать standby на запись и сделать его мастером. Но вот мастер опять вернулся в строй, он работает, а мы находимся в ситуации, когда в системе находятся одновременно два мастера, и приложение может также записывать данные в оба мастера.
Проблема заключается в том, что нам каким-то образом нужно свести все данные обратно в один мастер, однако сделать это, как правило, становится очень сложно. А если у вас в дополнение к этому есть какая-то сложная структура данных, то сделать это становится практически невозможно. Такую ситуацию принято называть split brain.
Есть ли решение?
Тут мы не забываем, что PostgreSQL — opensource-продукт, и его можно дорабатывать. Сторонние компании разрабатывали свои утилиты для обеспечения high availability и автоматического переключения между master и standby. Самые популярные из них:
- Corosync/pacemaker. С помощью Corosync мы можем соединить ряд серверов в один кластер, а pacemaker позволяет управлять PostgreSQL как одним из сервисов внутри кластера.
- Stolon. Создает дополнительные компоненты как proxy, являющийся точкой входа для пользователей и приложений, keeper, который управляет PostgreSQL, и sentinel, который, в свою очередь, управляет keeper и proxy.
- repmgr. Утилита для управления реплицией и переключениями, использующая встроенный протокол репликации PostgreSQL.
- Patroni. На мой взгляд, самый интересный продукт. В отличие от других продуктов и утилит Patroni является шаблоном для построения high availability для PostgreSQL. В качестве компонентов для обеспечения того или иного функционала можно использовать различные решения, что очень положительно сказывается на гибкости и возможности кастомизации построения high availability. Поэтому именно на patroni предлагаю взглянуть внимательнее.
Знакомство с Patroni
Patroni показал себя как тот самый вожак стада, который с течением времени проявил себя как самый сильный и выносливый слон. Данная утилита сейчас является де-факто стандартом для обеспечения high availability для PostgreSQL.

Остановимся подробнее на архитектуре утилиты: у нас есть сервера, на которых установлен PostgreSQL. Между собой они связаны потоковой репликацией. Рядом с PostgreSQL установлен Patroni, который умеет управлять PostgreSQL, — останавливать, запускать, перезапускать, автоматически создавать и пересоздавать standby, если это требуется.

Теперь появляется следующий компонент — DCS (distributed consensus system).
Из названия уже понятно, что эта система нужна для обеспечения консенсуса. С помощью DCS мы однозначно можем определить, где у нас мастер. И если у нас возникают с ним какие-то проблемы, то этот компонент позволяет нам выбрать новый мастер и продолжить работу с ним. В качестве компонента DCS могут выступать: etcd, протокол raft, Kubernetes, zookeeper, aws callbacks и так далее. Самые интересные для нас — первые три.
- etcd: это распределенное хранилище типа «ключ-значение», объединенное в кластер. Оно может быть установлено как на отдельно стоящих серверах, так и на серверах, где уже установлен PostgreSQL вместе с Patroni.
- протокол raft: отмечу, что сам etcd работает на протоколе raft, и вместе с релизом версии Patroni 2.0 появилась возможность не устанавливать целую базу etcd, а использовать чистый протокол raft. Это очень упрощает эксплуатацию решения и позволяет использовать на один компонент меньше.
- Kubernetes: этот компонент как раз нам и нужен для разворачивания Patroni внутри кластера Kubernetes, где уже есть своя etcd-база. С помощью API вызовов к этой etcd-базе мы можем обеспечивать консенсус в нашем Patroni кластере.
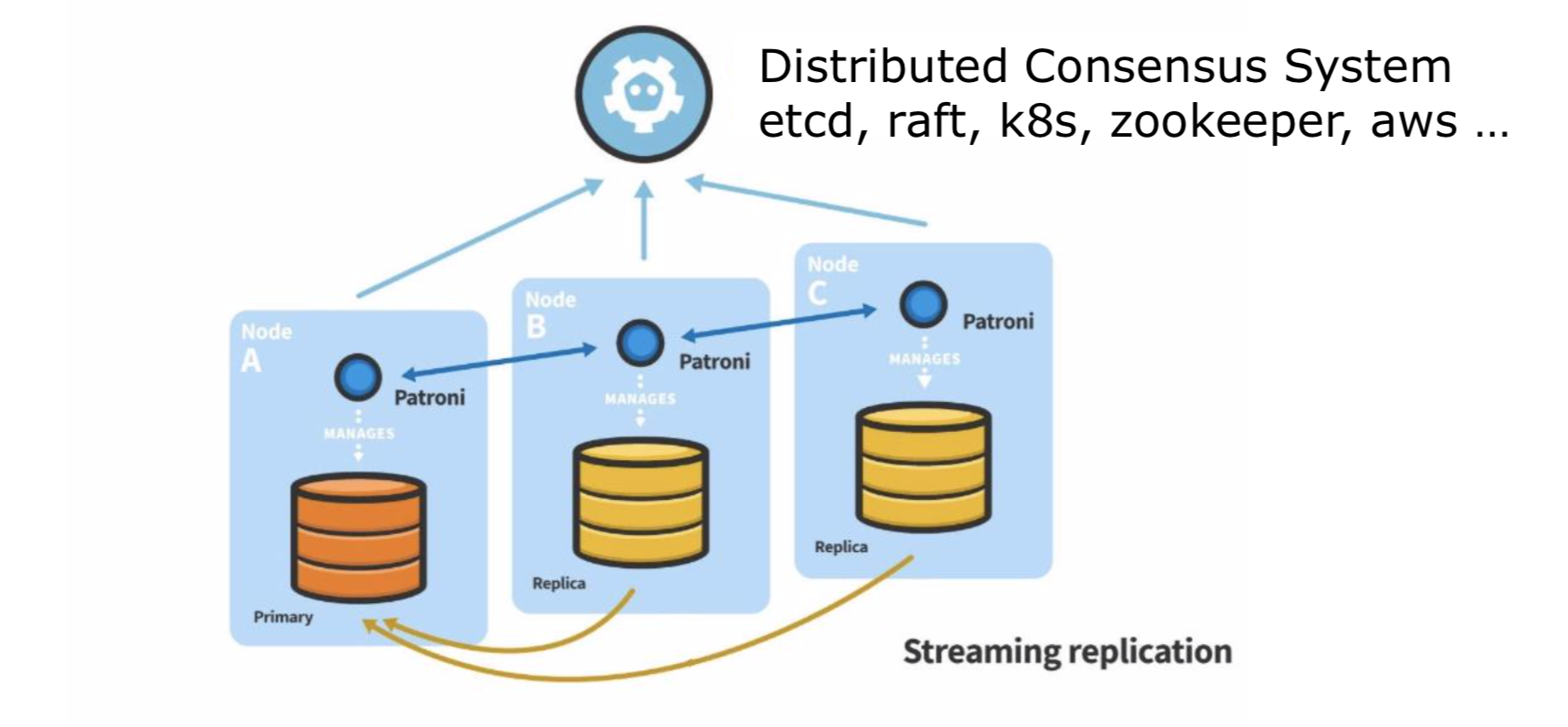
Еще один компонент — Load balancer, он опциональный в архитектуре Patroni. Может быть полезен для балансировки нагрузки на primary или на standby. Еще один случай применения Load balancer — необходимость единой точки входа к нашим PostgreSQL-базам. Вы всегда можете подключиться к одному и тому же IP, который, в свою очередь, уже будет прикреплен к серверу, где у нас располагается мастер. Внутри Райффайзенбанка в качестве Load balancer для Patroni мы используем vip-manager.
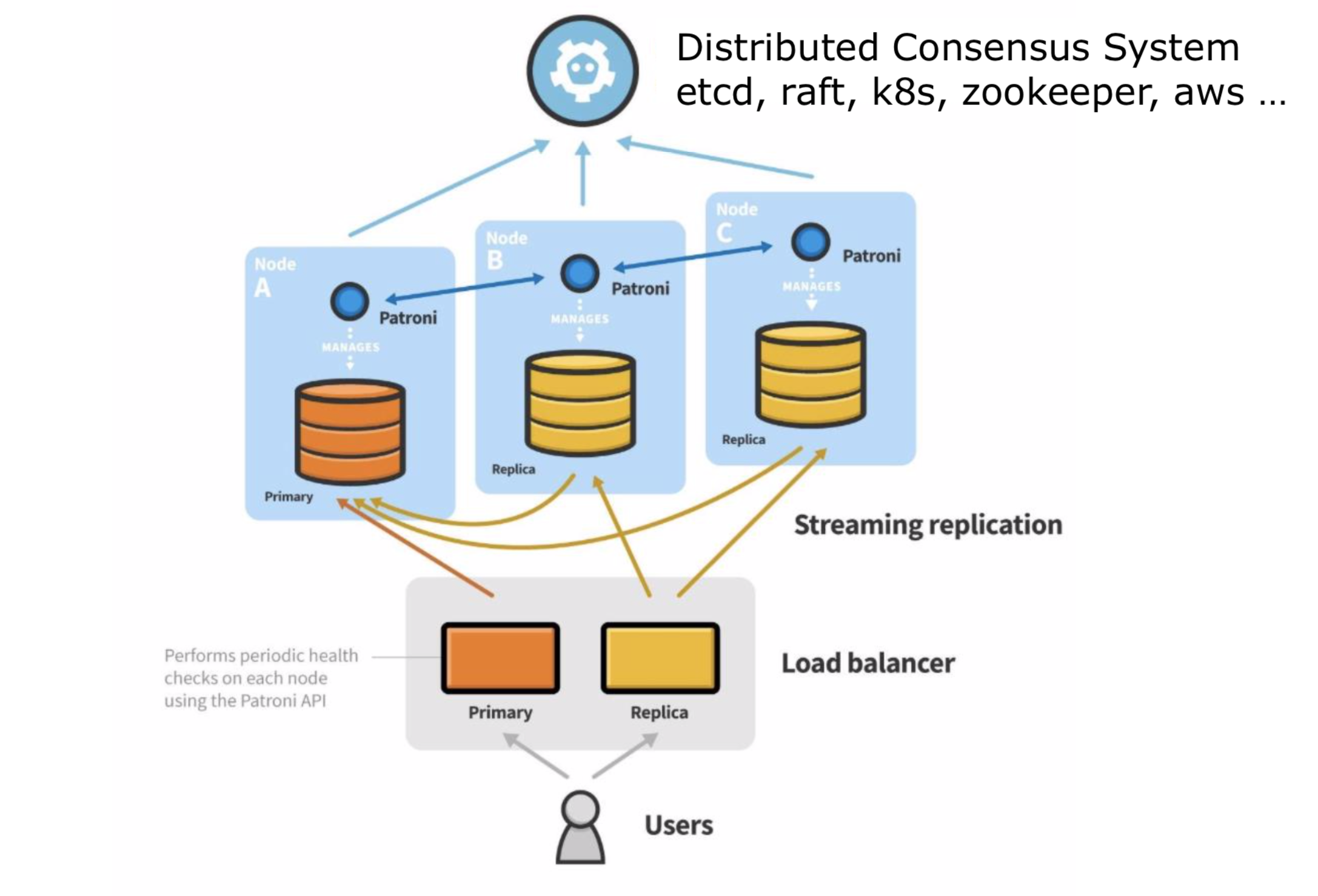
Гладя на такую архитектуру, с высокой доступностью и отказоустойчивостью, возникла идея —, а что если перенести ее в Kubernetes?
Воплощаем задуманное: PostgreSQL кластер внутри Kubernetes
Механизмы для обеспечения high availability
Начнем с контроллеров — Deployment, позволяет управлять stateless-приложениями, и StatefulSet, позволяет управлять statefull-приложениями. Возможно, непонятно, что это за слова.
Statefull-приложения. Они уже как раз должны хранить свое состояние. Самым популярным примером statefull-приложения является база данных.
Следующий механизм — PodAntiAffinity, который нужен для того, чтобы pod«ы не размещались на одних и тех же серверах или, к примеру, на одних и тех же серверных площадках. Таким образом мы обеспечиваем высокую доступность. Представим, есть pod«ы с базами данных, и если все они расположатся на одном и том же сервере и с сервером возникнут проблемы, то база данных станет недоступна, и в этой ситуации уже не получится переключить мастер базы данных на другой pod, так как попросту не будет доступного пода, куда можно будет переключить мастер.
PodDisruptionBudget тоже используется во благо high availability. Этот механизм задает в штуках или процентах количество pod«ов, которые могут быть недоступны в единый момент времени.
Опять же, наглядно, есть задача — вывести в режим обслуживания два сервера. Pod«ы, которые крутятся на этих серверах, будут недоступны. Kubernetes требуется решить такую проблему. Что делаем: задаем PodDisruptionBudget в количестве одной штуки. И, соответственно, в этой ситуации сначала у нас переедет один pod на другой сервер. Ждем, пока он станет доступен. И теперь второй pod тоже переедет на другой сервер. Приложение будет корректно продолжать свою работу.

Хранение данных
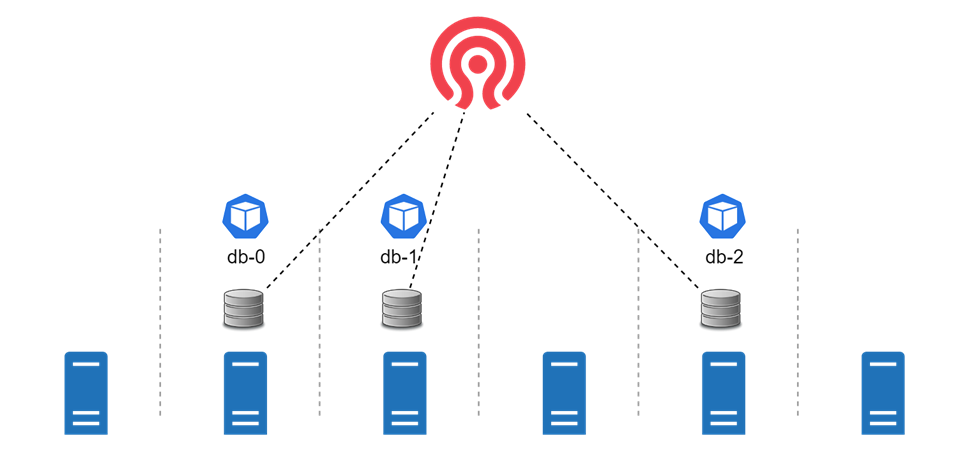
Один из вариантов — хранить данные в сетевом блочном устройстве Network Block Device. В нашем случае в Kubernetes кластере создаем StatefulSet, с базой данных. Kubernetes умеет создавать по шаблону диски для pod«ов из Network Block Device. Соответственно, оттуда выделились диски и прикрепились к pod«ам, и наш StatefulSet корректно начал работать.
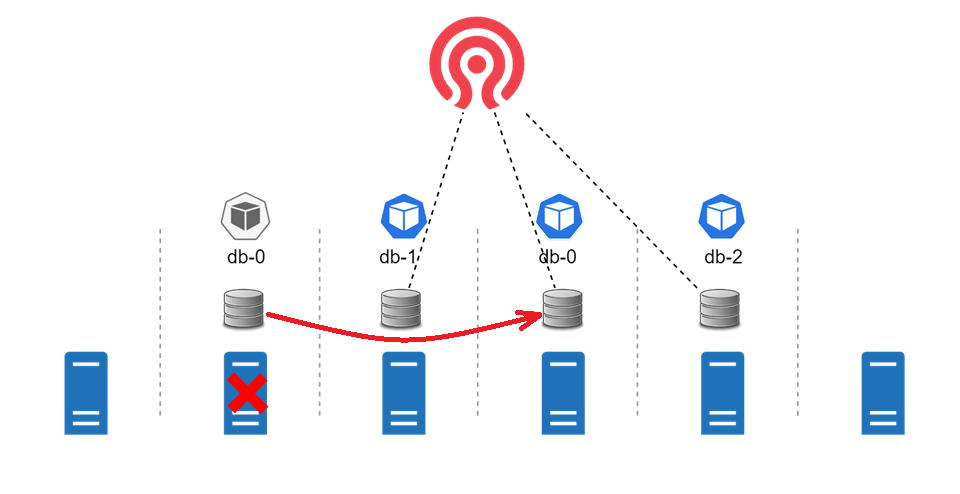
А теперь представим, что один из серверов в k8s кластере стал недоступен, и pod тоже станет недоступен. В такой ситуации pod переедет на другой сервер, а потом, так как у нас используется сетевое блочное устройство, диск переподцепится к другому pod«у. Наш StatefulSet с базой данных продолжит успешную работу.
Есть и другой вариант размещения данных — локальное хранилище непосредственно на серверах. Тут мы тоже можем создать StatefulSet. В случае, если сервер станет недоступен, pod уже не сможет переехать на другой сервер из-за того, что диски прикреплены непосредственно к серверу, на котором запускаются pod«ы. И нам нужно будет чинить сервер и разбираться, что произошло.
Kubernetes-операторы
Познакомимся с самыми популярными операторами, которые существуют для работы PostgreSQL внутри Kubernetes.
Crunchy Data
У этого оператора есть лицензия Apache 2.0, поэтому при желании можно использовать этот продукт бесплатно. Если нужна поддержка, то ее можно приобрести за плату. Кстати, из плюсов — этот продукт поддерживается и в Kubernetes, и в OpenShift, и в VMware PKS. Ну, и ключевой особенностью для этого и для других Kubernetes-операторов (которые обсудим далее) является то, что для обеспечения high availability самого PostgreSQL используется компонент Patroni. Так что он является де-факто стандартом для обеспечения high availability как внутри Kubernetes, так и на обычных серверах.
Stackgres
Особенность этого оператора в том, что он поставляется по лицензии AGPLv3. У лицензии есть ряд ограничений, а Stackgres позволяет их обойти. Например, если вы используете в своем проекте продукт с AGPLv3, то весь исходный код производного продукта должен быть также выпущен с этой же лицензией. А еще исходный код должен быть также открыто опубликован.
Zalando postgres-operator
Еще один интересный Kubernetes-оператор. И вот почему: именно компания Zalando разработала Patroni, и в продолжение своей разработки они написали этот оператор, чтобы их продукт мог также работать в кластерах Kubernetes.
У Zalando есть лицензия MIT, которая позволяет бесплатно использовать этот продукт. Но тут ребята не предоставляют платной поддержки, и если вы решите использовать именно его, то саппортить его вам нужно будет своими силами.
Все три Kubernetes-оператора предоставляют возможность использования графической утилиты, которая будет открываться у вас через браузер. Также утилита позволяет смотреть статус, логи работы вашего кластера, клонировать, править какие-то параметры или вообще удалить ваши PostgreSQL кластеры.
Также стоит отметить, что Crunchy Data и Stackgres имеют внутри себя встроенные средства для мониторинга PostgreSQL, чего, к сожалению, нет в postgres-operarot’е от Zalando.
В качестве итогов: плюсы и минусы размещения БД PostgreSQL внутри Kubernetes
Почему удобно разрабатывать:
- база данных «живет» рядом с приложением
- уменьшение time to market
- полный переход на методологию CI/CD
И что стоит иметь в виду при разработке:
- нагруженным базам данных нужны быстрые диски
- «шумные соседи»: тут нужно ограничить использование ресурсов pod«ами
- дополнительные сетевые задержки внутри Kubernetes задерживают работу базы данных
Глобальный лаконичный вывод — использовать PostgreSQL внутри Kubernetes нужно осторожно :) Учитывайте все возможные минусы и подводные камни, которые могут вам встретиться. Зная про все нюансы, вы успешно сможете использовать базу данных внутри Kubernetes!
>>> В этой статье поделился основными тезисами и добавил новые подробности из доклада на IT-конференции code/R. Посмотреть вживую и послушать все выступление можно тут.
