Классификация составляющих микроструктуры сталей с помощью компьютерного зрения
Целью данной работы является разработка модели компьютерного зрения для распознавания и классификации составляющих микроструктуры стали.
В металловедении принято называть составляющие микроструктуры фазами. Важность определения типа микроструктурных фаз продиктована влиянием размера и соотношения объемных долей фаз микроструктуры на механические свойства стали. В основном определение типа микроструктуры выполняется экспертами «на глаз», что в ряде случаев приводит к разногласиям в оценке.
В данной работе модель обучалась классифицировать такие фазы, как феррит, бейнит и перлит. Обучение модели проводилось на микроструктуре стали в состоянии после прокатки без проведения дополнительной термической обработки. Это важная оговорка, т.к. различие в специфическом «узоре» микроструктуры между фазами с термообработкой и без термообработки является существенным.
На рисунке 1 приведено изображение микроструктуры стали с выделенной фазой.

Рисунок 1. Общий вид микроструктуры стали
При подготовке данных для обучения на каждом изображении оставлено зерно только одной из фаз (феррит, бейнит или перлит). Для каждого класса микроструктуры отобрано по 100 изображений размером 224×224 в градациях серого (8 бит). Набор данных разделен на выборки train и test в соотношении 80/20. Изображения отсортированы по папкам, соответствующим каждой из фаз (классу). Функция «ImageFolder» позволяет присвоить метку для изображений, которой является название соответствующей папки.
import torchvision.datasets as datasets
import torchvision.transforms as transforms
train = datasets.ImageFolder("path/train", transform = transformations)
val = datasets.ImageFolder("path/test", transform = transformations_s)
train_loader = torch.utils.data.DataLoader(train, batch_size=4, shuffle=True)
val_loader = torch.utils.data.DataLoader(val, batch_size =4, shuffle=False)С помощью функции DataLoader были созданы загрузчики данных отдельными партиями — batch.
С целью компенсации небольшого количества данных был применен подход «Transfer Learning», использующий модель, обученную на большом количестве изображений. Последний слой предобученной модели был заменен на классификатор для 3х классов микроструктур. В качестве предобученной модели выбрана densenet161, для инициализации предварительного обучения установлен режим pretrained = True.
num_labels = 3
classifier = nn.Sequential(nn.Linear(512, num_labels),
nn.LogSoftmax(dim=1))
# Заменим последний полносвязный слой модели на наш классификатор
model.fc = classifierИзображения перед загрузкой в модель трансформированы в тензоры и тензоры в свою очередь нормализованы.
transformations = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=[0.485], std=[0.229])])Для оценки точности классификации модели была выбрана метрика «accuracy». При обучении на baseline-модели получен разброс по «accuracy» в 0,1 и отмечено, что от эпохи к эпохе эта метрика не улучшается. Сделан вывод, что модель недообучается. С целью повышения обучаемости модели было решено разнообразить набор данных с помощью аугментаций и сократить количество признаков путем бинаризации изображений. Кроме того, решено было заменить предобученную модель с densenet161 на ResNet18, использующую остаточное соединение (переброс исходного тензора через слои).
На рисунке 2 представлены бинаризованные изображения, сконвертированные обратно из тензора после наложения перспективных искажений, вертикальных и горизонтальных отражений.

Рисунок 2. Аугментации
Бинаризация проведена методом Оцу. Метод Оцу (Otsu’s Method) использует гистограмму изображения для расчета порога отнесения пикселя к 0 или 1.
Для выявления наиболее эффективного вида аугментаций они применялись по отдельности. Результаты применения различных видов аугментаций приведены в таблице 1.
Таблица 1. Применение аугментаций

Из таблицы 1 видно, что наилучшие результаты получены при применении вертикальных и горизонтальных отражений, а также от перспективных искажений. Поэтому далее для трансформации изображений будем применять только эти виды аугментаций.
Для определения оптимальной скорости обучения была применена функция lr_scheduler (далее планировщик), позволяющая менять скорость обучения каждые 2 эпохи с мультипликатором 0,1. Мультипликатор (gamma=0,1) означает, что скорость обучения будет снижаться в 10 раз.
# Зададим начальную скорость обучения = 0.01
optimizer = optim.Adam(model.fc.parameters(), lr=1e-2)
# Импортируем шедулер
from torch.optim import lr_scheduler
# Функция снижения скорости обучения встроена в данный шедулер.
exp_lr_scheduler = lr_scheduler.StepLR(optimizer, step_size=2, gamma=0.1)Апробация планировщика производилась с использованием двух предобученных моделей ResNet18 и ResNet34 отличающихся количеством слоев. Результаты апробации представлены в таблице 2.
Таблица 2. Сводные результаты
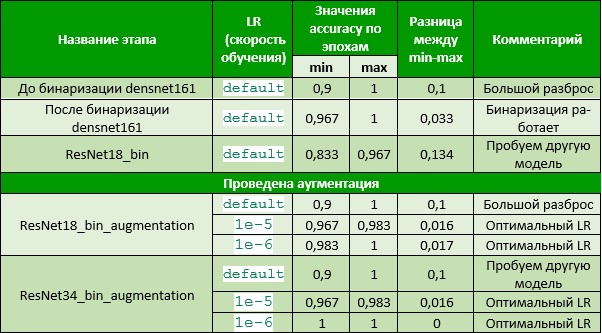
Получаем оптимальные результаты по accuracy на значениях LR 1e-5 и 1e-6.
Проверим, насколько точно модель сможет предсказать составляющую микроструктуры на реальных изображениях. Были отобраны изображения трех составляющих микроструктуры в градациях серого, которые до этого не были ни в наборе данных для обучения, ни в наборе данных для тестирования.
Результаты применения модели, основанной на предобученных моделях ResNet18 и ResNet34, представлены на рисунках 3 и 4 соответственно.

Рисунок 3. Применение модели, основанной на ResNet18

Рисунок 4. Применение модели, основанной на ResNet34
Из рисунков 3 и 4 мы видим, что в одном случае модель, основанная на ResNet34, допустила ошибку, указав, что микроструктура, фактически представляющая из себя бейнит, с вероятностью 100% является перлитом.
Проверка модели еще на одном изображении бейнита показала, что для изображений с бейнитом работа модели, основанной на Resnet34, нестабильна. Возможно, это связано с небольшой выборкой для датасета. Кроме того, специфический «узор» бейнита имеет большее разнообразие в отличии от феррита и перлита, что также указывает на необходимость в увеличении датасета.

Рисунок 5. Дополнительное изображение с бейнитом для модели, основанной на ResNet34
По результатам исследования можно сделать следующие выводы:
Предсказание составляющих микроструктуры с подачей на вход модели случайных изображений происходит с вероятностью 93 — 100%;
Учитывая, что модель, основанная на ResNet34, делает ошибки при определении фазы «бейнит», необходимо увеличить набор данных и поработать с изображениями бейнита.
В дальнейшем планируется на основе классификации составляющих микроструктуры разработать модель, определяющую тип микроструктуры на реальных снимках, состоящих из 2х и более составляющих.
Также интересной задачей выглядит обучение модели для классификации составляющих микроструктуры металла в термообработанном состоянии.
Автор выражает благодарность людям, которые дали возможность осуществить данное исследование, а именно Антону Витвицкому за помощь при подборе методов обработки изображений для компьютерного зрения и за работу над ошибками, а также Марию Тихонову, являющуюся моим первым Учителем по машинному обучению.
