Кэширование
Всем привет! Меня зовут Илья Денисов, я занимаюсь backend разработкой уже более пяти лет и сейчас пишу на языке go. Сегодня я предлагаю вам поговорить о кэшировании. Постараюсь рассказать о базовых концепциях, а также затронуть ряд особенностей, неочевидных на первый взгляд.

Что такое кэширование?
Кэширование — это способ хранения данных как можно ближе к месту их использования. Как правило, для этого используется быстродействующая память (RAM).
Для чего нужно кэширование?
Кэширование появилось давно и использовалось для ускорения работы процессора с оперативной памятью. Наверняка каждый из вас слышал об иерархии кэша L1, L2 и L3, применяемого в процессорах. Добавление кэша значительно ускорило работу с памятью, но и принесло дополнительные проблемы. Самая известная и сложная из них — это инвалидация данных. Мы уделим ей особое внимание чуть позже.
С этой проблемой (и рядом других, о которых мы тоже поговорим) связан главный принцип работы с кэшем. Он очень прост: если вы можете обойтись без кэширования, то именно так и сделайте.
Например, если у вас простое приложение или небольшая нагрузка, то кэширование вам не нужно. Важно понимать, что кэширование само по себе »не бесплатное», оно привносит в систему дополнительную сложность: появляются дополнительные компоненты, которые надо сопровождать, усложняется структура кода.
Но если у вас большая частота запросов (Requests per Second, RPS), если запросы эти «тяжелые », если вам слишком дорого масштабировать основное хранилище — любой из этих причин и, тем более, их сочетания достаточно, чтобы задуматься о кэшировании всерьез. При грамотном подходе оно поможет уменьшить в разы время ответа при обращении к данным.
Поэтому более продвинутый вариант принципа работы с кэшем можно сформулировать, перефразируя знаменитую цитату немецкого богослова XVIII века Карла Фридриха Этингера: «Дай мне удачу, чтобы без кэша можно было обойтись, дай мне сил, если обойтись без него нельзя — и дай мне мудрости отличить одну ситуацию от другой».
Как работает кэширование?
Логически кэш представляет из себя базу типа ключ-значение. Каждая запись в кэше имеет «время жизни», по истечении которого она удаляется. Это время называют термином Time To Live или TTL. Размер кэша гораздо меньше, чем у основного хранилища, но этот недостаток компенсируется высокой скоростью доступа к данным. Это достигается за счет размещения кэша в быстродействующей памяти ОЗУ (RAM). Поэтому обычно кэш содержит самые «горячие» данные.
Вот самый базовый пример работы кэша:
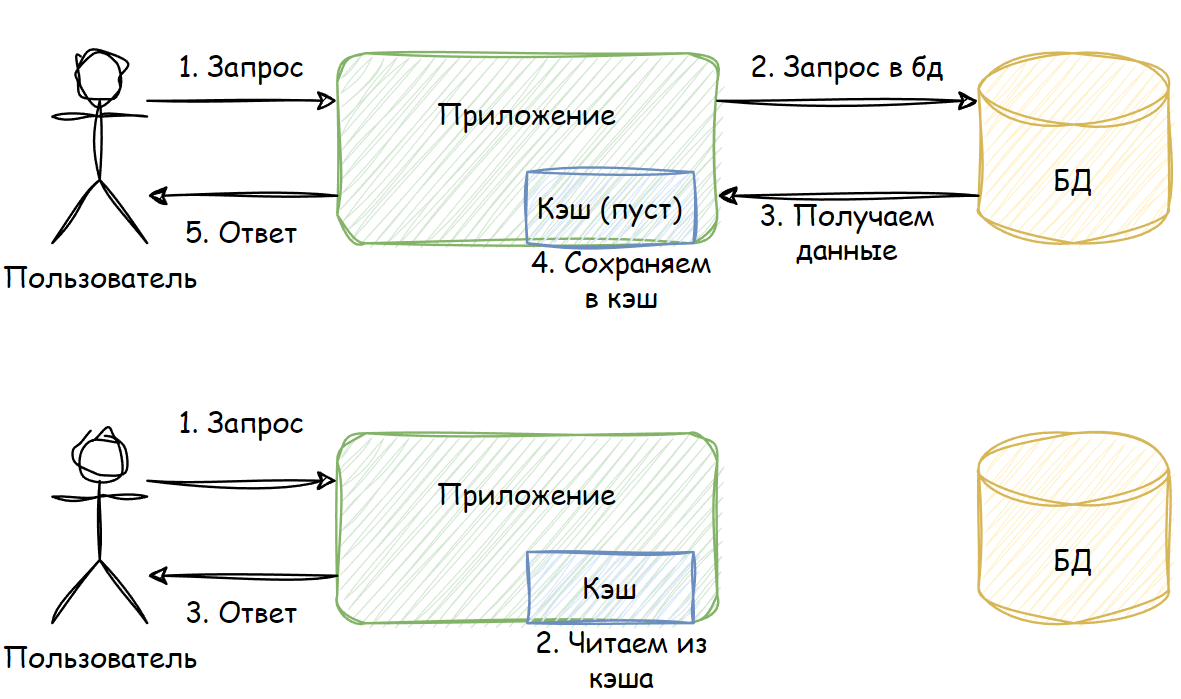
Пример работы кэша
На первой схеме изображено первое обращение за данными:
Пользователь запрашивает некие данные
Кэш приложения ПУСТ, поэтому приложение обращается к базе данных (БД)
БД возвращает запрошенные данные приложению
Приложение сохраняет полученные данные в кэше
Пользователь получает данные
Вторая схема иллюстрирует последующие обращения за данными:
Пользователь запрашивает данные
Приложение уже имеет эти данные в кэше (ведь они были записаны туда при первом обращении) и поэтому НЕ ОБРАЩАЕТСЯ за ними к БД
Пользователь получает данные
Из этого простого примера видно, что только первый запрос данных приводит к обращению к БД. Все последующие запросы попадают в кэш до тех пор, пока не истечет TTL. Как только это произойдет, новый запрос снова обращается к БД и заново кэширует данные. Так будет продолжаться все время, пока приложение работает.
В результате мы экономим время не только на обработке запросов в БД, но и на сетевом обмене с БД. Все это значительно ускоряет время получения ответа пользователем.
Метрики кэша
Работу кэша можно оценивать при помощи множества метрик разной степени полезности. Я опишу те, которые считаю базовыми и наиболее полезными.
Объем памяти, выделенной под кэш. Это базовый показатель, по которому можно судить, сколько используется ресурсов
RPS чтения/записи — количество операций чтения/записи за единицу времени. В обычной ситуации количество операций чтения должно быть в разы больше количества операций записи. Обратное соотношение свидетельствует о проблемах в работе кэша
Количество элементов в кэше. Его полезно знать в дополнение к объему памяти, чтобы обнаруживать большие записи
Hit rate — процент извлечения данных из кэша. Чем он ближе к 100%, тем лучше. Этот параметр буквально определяет то, насколько наш кэш полезен и эффективен
Expired rate — процент удаления записей по истечении TTL. Этот показатель помогает обнаружить проблемы с производительностью, вызванные большим количеством записей с одновременно истекшим TTL
Eviction rate — процент вытеснения записей из кэша при достижении лимита используемой памяти. Важный показатель при выборе стратегий вытеснения, о которых мы поговорим чуть позже
Что можно кэшировать?
Строго говоря, кэшировать можно что угодно, но не всегда это целесообразно. Все сильно зависит от данных и паттерна их использования.
Все данные можно условно разделить на 3 группы по частоте изменений:
Меняются часто. Такие данные изменяются в течение секунд или нескольких минут. Их кэширование чаще всего бессмысленно, хотя иногда может и пригодится.
Пример: ошибки (кэширование ошибок может быть настолько важным, что мы посвятили ему целую главу ближе к концу статьи)
Меняются нечасто. Такие данные изменяются в течение минут, часов, дней. Именно в этом случае вы чаще всего задаетесь вопросом «Стоит ли мне кэшировать это?»
Примеры: списки товаров на сайте, описания товаров
Меняются крайне редко или не меняются никогда. Такие данные меняются в течение недель, месяцев и лет. В этом случае данные можно спокойно кэшировать. НО! Ни в коем случае нельзя усыплять бдительность верой в то, что какие-либо данные никогда не изменятся. Рано или поздно они изменятся, поэтому всегда выставляйте всем данным разумный TTL. ВСЕГДА!
Пример: картинки, DNS
Типы кэшей
С точки зрения архитектуры, можно выделить два типа кэшей: встроенный кэш (inline) и отдельный кэш (sidecar).
Встроенный кэш — это кэш, который «живет» в том же процессе, что и основное приложение. Они делят один сегмент памяти, поэтому за данными можно обращаться напрямую. В качестве такого кэша может выступать map — обычный инструмент из арсенала go — или другие структуры данных (подробнее об этом можно почитать здесь: https://github.com/hashicorp/golang-lru). Вот принципиальная схема работы inline cache:

Встроенный кэш (inline)
Отдельные кэши (sidecar) — это обособленный процесс со своей выделенной памятью. Как правило, это хранилище типа ключ-значение, которое используется как кэш для основного. Примеры такого типа кэша — Redis, Memcached и другие хранилища типа ключ-значение. Вот принципиальная схема их работы:

Отдельные кэши (sidecar)
Сравнение двух типов кэшей:
Характеристика | Встроенный кэш (inline) | Отдельные кэши (sidecar) |
Скорость ответа | Выше: обращаемся напрямую к памяти | Ниже: есть сетевые вызовы, а также оверхед на работу самого хранилища |
Память | Кэш и приложение делят одну область памяти, поэтому ее тратится меньше | Под кэш выделена отдельная память, поэтому ее тратится больше |
Согласованность данных | Плохая: каждая копия приложения содержит только свои данные | Хорошая: все копии приложения обращаются к единому хранилищу |
Масштабирование | Кэш нельзя масштабировать отдельно от приложения | Кэш и приложение можно масштабировать независимо друг от друга |
Ресурсы (память, ЦПУ и т.д.) | Общие, поскольку «живут» в одном процессе | Выделенные, поскольку «живут» в разных процессах |
Простота сопровождения | Проще: кэш — просто структура данных, предоставляемая библиотекой | Сложнее: кэш — отдельно разворачиваемый компонент, требующий отдельного мониторинга и экспертизы |
Изолированность | Низкая: проводить отдельно работы над кэшем крайне сложно | Высокая: мы можем проводить любые работы над кэшем независимо от приложения |
Горячий старт | Сложнее: приложение обычно не общается с диском напрямую | Проще: например, redis может периодически сбрасывать данные на диск и восстанавливать состояние после рестарта |
Не стоит думать, что один тип кэша хуже другого. У каждого из них свои достоинства и недостатки и каждый из них нужно применять с умом. Более того, их можно комбинировать. Например, вы можете использовать встроенный кэш как L1, а отдельный кэш как L2 перед основным хранилищем. В результате, такая схема может в разы сократить время ответа и снизить нагрузку на основное хранилище.
Стратегии работы с кэшем
Рассмотрим стратегии чтения и записи при работе с кэшем. В приведенных далее примерах кэш может быть как встроенным, так отдельным. Под «приложением» подразумевается некая бизнес-логика. Упор делается на описание взаимодействия компонентов друг с другом.
Cache through (Сквозное кэширование)
В рамках этой этой стратегии все запросы от приложения проходят через кэш. В коде это может выглядеть как связующее звено или «декоратор» над основным хранилищем. Таким образом, для приложения кэш и основная БД выглядят как один компонент хранилища.
Read through (Сквозное чтение)

Read through (Сквозное чтение)
Приходит запрос на получение данных
Пытаемся прочитать данные из кэша
В кэше нужных данных нет, происходит промах (miss)
Кэш перенаправляет запрос в БД. Это важный нюанс стратегии: к БД обращается именно кэш, а не приложение
Хранилище отдает данные
Сохраняем данные в кэш
Отдаем запрошенные данные приложению. Для приложения это выглядит так, как если бы хранилище просто вернуло ему данные, то есть шаги 3–6 скрыты от основной бизнес-логики
Возвращаем результат запроса
Write through (Сквозная запись)

Write through (Сквозная запись)
Приходит запрос на вставку каких-либо данных
Отправляем запрос на запись через кэш. В этот момент кэш выступает только как прокси и сам по себе ничего не делает
Сохраняем данные в БД
БД возвращает результат запроса
Сохраняем данные в кэш. Делаем мы это специально после вставки, чтобы кэш и БД были консистентны. Если бы мы писали данные в кэш на шаге 2, а при этом на шаге 3 произошла бы ошибка, то кэш содержал бы данные, которых нет в БД, что может привести к печальным последствиям
Отдаем запрошенные данные приложению
Возвращаем результат запроса
Преимущества:
Очень простая схема работы с точки зрения организации кода
В коде легко добавить/убрать кэш, так как обычно это простая «обертка» над основным хранилищем
Недостатки:
Схема негибкая, поскольку записывать в кэш мы можем строго после выполнения основного запроса и в целом кэш скрыт от бизнес-логики
Cache aside (Кэширование на стороне)
В этой стратегии, приложение координирует запросы в кэш и БД и само решает, куда и в какой момент нужно обращаться. В коде это выглядит как два хранилища: одно постоянное, второе — временное.
Read aside (Чтение на стороне)

Read aside (Чтение на стороне)
Приходит запрос на получение данных
Пытаемся читать из кэша
В кэше нужных данных нет, происходит промах (miss)
Приложение само обращается к хранилищу. В этом главное отличие от сквозного подхода: бизнес-логика в любой момент времени сама решает, куда обращаться — к кэшу или к БД
БД отдает данные
Сохраняем данные в кэш
Возвращаем результат запроса
Write aside (Запись на стороне)

Write aside (Запись на стороне)
Приходит запрос на вставку каких-либо данных
Сохраняем данные в БД
БД возвращает результат запроса
Сохраняем данные в кэш. Опять-таки, мы намеренно делаем это после вставки, чтобы кэш и БД были консистентны. Сохранение данных в кэше перед шагом 2 и ошибка на шаге 2 привели бы к появлению в кэше данных, которых нет в БД. Результат был бы все тот же — печальные последствия
Возвращаем результат запроса
Преимущества:
Гибкость. Управление полностью в руках приложения. Оно может сохранить данные в кэш сразу после обращения к БД, а может предварительно сделать еще ряд манипуляций с данными и только затем сохранить их в БД
Недостатки:
Схема работы немного сложнее с точки зрения организации кода
В коде сложнее добавить/убрать кэш, поскольку это отдельный компонент, с которым взаимодействует бизнес-логика. Изменить этого взаимодействие может быть сложно
Cache ahead (Опережающие кэширование)
Эта стратегия предназначена только для запросов на чтение. Они всегда идут только в кэш, никогда не попадая в БД напрямую. По факту мы работаем со снимком состояния БД и обновляем его с некоторой периодичностью. Для приложения это выглядит просто как хранилище, как и в случае со сквозным кэшированием.

Cache ahead (Опережающие кэширование)
Входящие запросы на чтение:
Приходит запрос на получение данных
Читаем из кэша. Если в кэше нет нужных данных, то возвращаем ошибку. К БД в случае промаха не обращаемся
Если данные есть, то отдаем их приложению
Возвращаем результат запроса
Обновление кэша:
Периодически запускается фоновый процесс, который читает данные из БД.
Читаем актуальные данные из БД
БД отдает данные
Сохраняем данные в кэш
Преимущества:
Минимальная и полностью контролируемая нагрузка на БД. Клиентские запросы не могут повлиять на БД
В коде легко добавить/убрать кэш, поскольку можно просто заменить кэш на основное хранилище и обращаться уже к нему
Простота, так как не приходится иметь дело с двумя хранилищами
Недостатки:
Кэш отстает от основного хранилища на период между запусками обновления кэша. Нужно помнить, что на момент обращения свежие данные могут еще «не доехать» до кэша. Эта проблема может быть решена использованием сквозной записи или записи на стороне. Тогда, при обновлении данных в БД, данные будут обновляться и в кэше
Вы можете использовать описанные стратегии в любых комбинациях. Например, вы можете взять опережающие кэширование, добавить туда сквозную запись и чтение на стороне, чтобы добиться максимальный актуальности данных и избежать промахов по максимуму!
Стратегии инвалидации
Инвалидация — это процесс удаления данных из кэша или пометка их как недействительных. Делается это для того, чтобы гарантировать актуальность данных, с которыми работает приложение.
Инвалидация по TTL
TTL (Time To Live) — время жизни данных в кэше. При сохранении данных в кэш для них устанавливается TTL и данные будут обновляться с периодичностью не менее TTL.
Это самый простой способ инвалидации данных. Тем не менее, у этой стратегии есть свои подводные камни.
Самый главный из них — вопрос длительности TTL. Если TTL слишком короткий, то запись может «протухнуть» и стать недействительной раньше, чем обновление было бы необходимо, что приведет к отправке повторного запроса в источник данных. Если TTL слишком длинный, то запись может содержать устаревшие данные, что может привести к ошибкам или неправильной работе приложения. Обычно ответ на этот вопрос подбирается эмпирическим путем.
Есть, впрочем, и другой вариант. Источник данных может присылать TTL сам, тогда клиенту не придется выбирать TTL, а просто брать предлагаемый. Такой подход, например, можно использовать в HTTP.
Сложность иного рода возникает, если записи становятся недействительными одновременно в большом количестве. В таком случае возникает множество запросов в источник данных, что может привести к проблемам с производительностью, а то и вовсе «положить» его. Для избежания подобной ситуации, можно использовать jitter.
Jitter — это случайное значение, добавляемое к TTL. Если в обычном случае все записи имеют, например, TTL = 60 сек., то при использовании jitter с диапазоном от 0 до 10 сек. TTL будет принимать значение от 60 до 70 сек. Это позволит сгладить количество записей, переходящих в состояние недействительных одновременно.
Jitter позволил нам сгладить нагрузку на источник данных, когда «протухает» много записей сразу. Но что делать, если есть одна запись, которую интенсивно используют? Ее инвалидация приведет к тому, что все запросы, которые не нашли данных в кэше, одновременно обратятся к источнику. Тогда нам нужно схлопнуть все эти запросы в один. В go есть для этого отличная библиотека singleflight. Она определяет одинаковые запросы, возникающие одномоментно, выполняет лишь один запрос в источник, а затем отдает результат всем изначальным запросам. Таким образом, если у нас возникли десять запросов, библиотека выполнит только один из них, а результат вернет всем десяти. Стоит отметить, что эта библиотека работает только в рамках одного экземпляра приложения. Если у вас их несколько, то даже с использованием этой библиотеки в источник может уйти больше одного запроса.
Инвалидация по событию
При таком подходе данные инвалидируют при наступлении некоего события — обычно это обновление данных в источнике. На самом деле, мы уже рассмотрели этот способ, когда говорили про стратегии использования кэширования, а именно write through и write aside.
Также в качестве события для инвалидации данных может выступать время последней модификации данных. Такой способ используется в HTTP.
Стратегии вытеснения
Размер кэша ограничен, он гораздо меньше основного хранилища, а значит, мы не может разместить в нем все данные. Что делать, когда память, выделенная под кэш, полностью заполнена, а новые записи продолжают поступать?
Ничего не делать
Конечно, можно игнорировать все новые записи и ждать, пока существующие истекут по TTL. Однако в общем случае это крайне неэффективно, поскольку все запросы идут в источник данных и все преимущества кэша нивелируются. Поэтому обычно используются более эффективные стратегии вытеснения.
Random
Random — стратегия вытеснения, при которой удаляются случайные записи. Это самая простая стратегия: просто удаляем то, что первым попалось под руку. Но этот способ недалеко ушел от стратегии «ничего не делать».
TTL
TTL — стратегия вытеснения, предусматривающая удаление той записи, которой осталось меньше всего «жить», то есть у которой TTL истечет раньше всех. Как и random, эта стратегия немного лучше, чем «ничего не делать», но все еще недостаточно эффективна.
LRU
LRU (Least Recently Used) — стратегия вытеснения, которая опирается на время последнего использования записи. Она удаляет записи, у которых время последнего использования старше остальных. Таким образом, в кэше остаются записи, которые использовались недавно. Эта стратегия опирается уже не на случай, а на паттерн использования данных, поэтому она гораздо эффективнее предыдущих.
Эта стратегия хорошо подходит, когда:
недавно использованные данные, скорее всего, будут использованы снова в ближайшем будущем
нет данных, которые используются чаще остальных
вы не знаете, что именно вам нужно
LFU
LFU (Least Frequently Used) — стратегия вытеснения, опирающаяся на частоту использования записи. Она удаляет записи, которые использовались реже всего. Так в кэше остаются данные, которые использовались чаще других. Эта стратегия тоже опирается не на случай, а на паттерн использования данных, поэтому она тоже эффективнее остальных и является альтернативой LRU.
Эта стратегия хорошо подходит, когда есть данные, которые используются значительно чаще остальных. Такие данные разумно не вытеснять из кэша, чтобы избежать лишних «походов» в источник.
Кэширование ошибок
Ранее я упомянул, что мы можем кэшировать ошибки. На первый взгляд это может показаться странным: зачем нам вообще кэшировать ошибки? На самом деле, это крайне полезная штука.
Представим себе, что клиент запрашивает данные, которых нет в источнике. Пусть это будем информация о товаре по id. Казалось бы, нет данных и ладно: просто сходим в источник, ничего не получим и сообщим клиенту. Но что, если таких запросов много? А что, если кто-то делает это специально?
Это типичная схема так называемой атаки через промахи кэша (cache miss attack). Ее суть в запрашивании данных, которых заведомо не может быть в кэше, поскольку их нет в источнике. Вал таких запросов может привести к проблемам с производительностью источника и даже к его «падению». Этого можно избежать, если кэшировать ошибку, тогда последующие запросы того же рода будут попадать в кэш и источник не пострадает.
Но тут тоже нужно быть осторожным. Если хранить в одном кэше и полезные данные, и ошибки, то в случае атаки полезные данные могут вытеснены из кэша. Поэтому я бы рекомендовал иметь выделенный кэш под ошибки. Он может быть меньшего объема, чем основной кэш.
Также кэширование ошибок полезно, если сервис, к которому вы обращаетесь, «почувствовал себя плохо». Чтобы не забивать его запросами, которые, скорее всего, не будут выполнены, а лишь усугубят проблему, лучше кэшировать ошибки на несколько секунд. Таким образом, мы перестанем оказывать негативное воздействие на сервис и дадим ему возможность нормализоваться. Но с этой задачей лучше справляется паттерн Circuit Breaker, который мы не будем рассматривать в рамках этой статьи.
Заключение
На этом пока все. Я не ставил перед собой целью раскрыть тему кэширования исчерпывающе: наверняка многие вещи остались не рассмотренными в рамках этой статьи. Я хотел лишь предоставить структурированную основу и хочу верить, что у меня это получилось.
Надеюсь, данный материал оказался вам полезен, вы открыли для себя что-то новое или структурировали уже известное.
