Как запилить джентльменский релиз

Релизы не выходят точно в срок? Множество багов на регрессе? Сам регресс занимает несколько дней? Много жалоб на баги? Релизом занимаются сразу все и продуктовая разработка полностью останавливается? Узнали? Согласны? Мне кажется, многие сталкивались с этим, в том числе и мы.
Всем привет, меня зовут Даниил, я — QA-лид в мобильном направлении hh.ru. Сегодня я расскажу, как из нестабильных и нерегулярных релизов мы пришли к классному и быстрому релизному процессу мобильных приложений. Наши релизы стали выходить раз в неделю, а число жалоб уменьшилось в разы. Еще расскажу, с какими проблемами мы сталкивались и как их решали.
Это текстовая расшифровка выпуска нашего влога, посему если вам удобнее смотреть, а не читать, добро пожаловать на наш Youtube-канал.

Хьюстон, у нас проблемы
Начнем с того, какие проблемы у нас были с релизами вообще:
Огромный и непредсказуемый набор фичей
Заранее неизвестна точная дата выхода релиза
Долгий и полностью ручной регресс
Непрогнозируемая дата выхода новых фич
Интерфейс слишком сильно менялся от релиза к релизу
Между долгими релизами, приложение сильно менялось как внешне, так и внутри, что очень мешало нашим пользователям. Если три месяца назад у них был один интерфейс и определенный набор функций, то в новом релизе юзеры могли получить совершенно новое приложение, с новыми функциями, новым интерфейсом и отсутствием каких-то старых и привычных всем штук. Такое резкое изменение ничего кроме негатива от пользователей не вызывало.
К чему мы хотим прийти
Исходя из проблем, которые мы определили, мы решили, к чему хотим прийти в итоге. Нам необходимо делать стабильные, регулярные и небольшие релизы. Чем чаще релиз, тем меньше туда попадает функционала, а следовательно обновление будет проще для юзера. При релизах раз в неделю мы сможем выдавать новый функционал часто и в небольших количествах. У пользователей не будет возникать ощущение, что перед ними новое приложение при каждом обновлении. Из-за небольшого количества изменений сам релиз будет максимально стабильным и протестированным. Команде тестировщиков будет намного проще провести регресс такого релиза, да и чем меньше изменений, тем меньше вероятность попадания бага в прод.
Также благодаря этому мы получим быстрый time-to-market и сможем планировать доставку той или иной функциональности до юзеров.
Предпосылки
Три года назад у нас было две небольшие платформенные команды: iOS и android + несколько QA, но также были планы и по увеличению числа разработчиков и тестировщиков. Если бы мы не начали решать перечисленные проблемы, все могло стать сильно хуже. Пока вас мало и вы находитесь рядом, можно просто спросить друг у друга, что сейчас происходит с релизом, в каком он статусе и что в него попало. Но, если число команд растет и сами они становятся распределенными, то жить с хаосом в релизах становится намного труднее.
Будем решать проблемы
Проблемы понятны, цели поставлены, теперь можно попробовать их решить.
Для начала мы выделили для себя основную техническую проблему именно в процессах разработки —нестабильный девелоп. В нашем понимании «нестабильный» значит, что там есть непротестированный или даже неработающий функционал, а появление нового может испортить существующий.
Дежурство
Первое что мы решили — просто исправить это с помощью процессов!. Выделим людей, которые будут ответственны за стабильность девелопа. Они будут исправлять баги, краши с прода, создавать релиз и следить чтобы ничего не падало. Так у нас появилось дежурство: на неделю-две выделялось несколько разработчиков и тестировщик, которые только и занимались тем, что затыкали дыры в нашем бесконечном пожаре из багов и крашей. И, казалось бы, идея нормальная, но не совсем. Такой подход выключал команду из продуктовой разработки почти полностью, фокус на текущих задачах терялся, а сотрудники демотивировались, так как вся работа сводилась к исправлению чужих багов.
Github-flow
Затем мы решили разобраться, почему у нас в девелоп постоянно попадает что-то недоделанное или сломанное. Разобрались. Мы работали по так называемому «trunk-based development», только в нашем случае это был грязный trunk-based. Мы никогда не тестировали то, что попадало в девелоп, а тестировали какой-то промежуточный вариант, например когда фича полностью сделана или пофикшено несколько багов.
Такой подход нам не нравился, и мы решили изменить схему работы. Мы перешли на github-flow: решили, что каждая новая фича будет делаться в своей отдельной ветке. То есть все мелкие задачки, на которые декомпозирована фича, будут мерджиться в эту ветку. Когда вся фича доделана, тестировщик возьмет эту ветку, соберет приложение и протестирует. И если все хорошо, тогда можно смерджить уже целиком готовую фичу в девелоп. Таким образом мы избавились от ситуации, когда в девелопе есть что-то непротестированное или недоделанное.
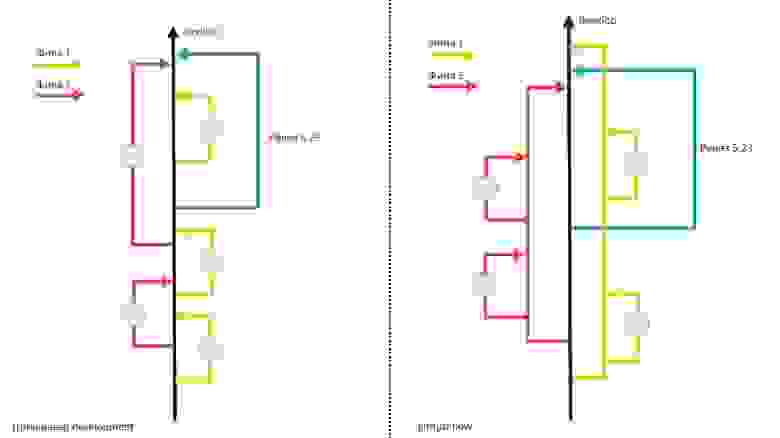
Конечно, у такого подхода есть свои минусы. Пока разработка ведется в отдельной ветке, в девелопе может появляться новый функционал, и разработчик периодически синхронизирует свою ветку с девелопом. Из-за этого получается, что тестировщику надо заново перепроверить какой-то функционал, если из девелопа прилетело то, что его затрагивает. Но мы смирились с этим, и, если честно, не особо страдаем.
Такой подход безусловно сильно нам помог стабилизировать девелоп, но при этом он сильно загрузил тестировщиков. На тестировщике замыкался весь процесс: пока он не протестирует и не даст добро на мердж в девелоп новый фичи, ничего не мерджилось. А ведь помимо тестирования самой фичи необходимо убедиться, что ничего не развалилось из того, что уже было сделано. Мы поняли, что надо спасать наших QA.
Автотесты
Пожалуй, самый простой способ избавить тестировщика от рутины бесконечных регрессионных проверок — это автотесты. Не вопрос, давайте начнем их писать.
Мысли вслух
Тут хочу сделать небольшое отступление: может сложиться впечатление, что все эти процессные изменения и внедрение автотестов происходило моментально, быстро и безболезненно. Конечно нет. Переход на github-flow был долгим процессом, который постоянно улучшался, скоуп обязанностей дежурных постоянно пересматривается и изменяется. А написание автотестов — это вообще большая, сложная и долгая задача. Все было постепенно и размеренно.
Мы начали изучение подходов и фреймворков для написания тестов. В iOS мы остановились на XCUITests, в Android выбрали Kaspresso. Подробнее узнать о том, как выбрать фреймворк для автотестов мы рассказывали в серии наших видео про вопросы автоматизации.
Параллельно с написанием автотестов мы сразу же начали интегрировать их в наш CI. Мы используем build-сервер Bamboo — это инструмент из стэка Atlassian. Для параллельного запуска android-тестов мы используем утилиту marathon, а в iOS — нативные решения от xcode.
Вообще автотесты, которые гоняются только локально и не запускаются регулярно на CI — это очень плохая практика. Тесты начнут приносить пользу лишь тогда, когда любой заинтересованный человек сможет легко их запустить и посмотреть результаты прогона.
Когда первые автотесты были написаны, а запуск налажен, мы сразу же интегрировали их в наш процесс разработки. На Bamboo был настроен план прогона тестов (план — это пул задач для выполнения), где каждую ночь запускались тесты на всех ветках фичей и девелопе. Теперь в начале каждого рабочего дня разработчики могут видеть, как вообще идут дела.
Кроме того, теперь обязательным условием попадания новой фичи в девелоп стали зеленые тесты. После того как тестировщик протестировал фичу, разработчик открывает pull request в девелоп и на этом pr запускает прогон тестов. Если все успешно — мердж, если нет, соизволь поправить.
Таким образом мы сильно разгрузили тестировщиков, и добавили еще одну степень защиты нашего девелопа от нестабильности.
Release train, который смог
Итак, мы добились стабильного девелопа, но оставалась еще одна проблема — нестабильная дата релиза. Даже если мы договаривались об определенной дате, это вовсе не значило, что релиз выйдет точно в срок. Постоянно поступали просьбы в формате «а подождите нас», «ну пока там регресс идет мы еще докинем?» и так далее. Одной из причин таких просьб было отсутствие четкого понимания сроков следующего релиза. Если не попал в этот релиз, был риск прождать следующего слишком долго.
Так жить нам не нравилось, и мы решили гарантировать коллегам дату каждого релиза, чтобы у них не было страха надолго зависнуть в пустоте. Мы ввели такую практику как «релиз трейн». Мы договорились, что раз в две недели, в определенный день и час мы делаем ветку релиза и никого не ждем. Если не успел — сорри, жди следующего поезда. Разработчик, не попавший в релиз, не сильно расстраивался, так как четко знал, когда будет следующий релиз, и что в него он точно успеет.
Конечно, это всё равно оставалось лишь устной договоренностью Мы старались быть гибкими: вникать в отдельные ситуации и даже кого-то ждать. Но в целом всё шло к серьезному закручиванию гаек. В какой-то момент мы начали строго следовать релизному расписанию, и релизы стали уходить еженедельно без каких-либо задержек. Со временем нас вообще перестали просить подождать какой-то недоработанный функционал.
Подведем небольшой итог
Что у нас было:
Большие и нестабильные релизы
Отсутствие четкой даты релиза
Долгий регресс
Непонятный состав релиза
Какие практики ввели:
Github-flow
Автотесты
Дежурство
Релиз трейн
С помощью этого мы укротили хаос релизов, релизы стали регулярными и небольшими. Также существенно сократился и time-to-market.
Многие задаются вопросом, неужели всё стало прямо вот так хорошо? В основном — да. С таким подходом можно спокойно жить. Мы так функционируем уже больше года и проблем особо не испытываем. Однако, в процессе релиза присутствует множество рутинных действий, от которых хотелось бы избавиться.
Всю рутину релизов можно разделить на две части: техническая и менеджерская.
Техническая часть включает в себя следующие вещи:
Создать руками ветку релиза
Поднять там версию
Собрать сборку
Запустить автотесты
Выложить в стор
Оповестить всех об этом
Менеджер же во время релиза создавал страницу в Confluence, на которой указаны ответственный за релиз, состав релиза, даты выкладки в прод, прогона тестов etc. Кроме того, нужно было заказать тексты для раздела «Что нового», а у каждой платформы он еще и свой.
Хоть это и не сложные операции, но они занимают время, требуют человеческого участия, следовательно, всегда остается риск ошибиться или что-то забыть. С этим можно не заморачиваться, но мы в hh.ru любим все автоматизировать. Если какую-то рутину можно автоматизировать за разумное время, то мы это сделаем.
Как мы автоматизировали всё это добро и что из этого получилось, читайте в следующей статье.
Stay tuned!
