Как взломать антиплагиат? — Безопасность и уязвимости NLP -классификаторов. Часть 1
Всем привет! Меня зовут Артём Семенов, я занимаюсь пентестами в компании RTM Group.
Известная поговорка гласит: «Словом можно ранить, а словарём — убить». Это особенно актуально для темы, которую мы сегодня рассмотрим, ведь для атак мы будем использовать либо слово, либо огромный текст. В начале 2023 года ChatGpt произвёл фурор. Эта языковая модель может генерировать машинные тексты и писать стихи, которые максимально приближены к «авторскому» (человеческому) стилю. Казалось бы, при помощи систем антиплагиата проблему подделок можно было бы решить, но уже известно, что и их реально взломать — автор диплома, написанного с помощью ChatGPT, в своём твиттере описывает, как это сделать.
В этой статье я расскажу о том, какие недостатки содержат классификаторы, и как этим может воспользоваться реальный злоумышленник. Мы рассмотрим теоретические аспекты, а также проведем анализ безопасности текстовых классификаторов, — как распространёнными методами, так и нестандартными способами, с целью обхода систем классификации текста, а также обмана систем определения машинного текста.
Дисклеймер
Данная статья носит исключительно образовательный характер и не призывает использовать описанные методы для нарушения академической честности. Наша цель — определить недостатки систем антиплагиата и возможности для их исправления специалистами в соответствующих областях.
Как мы готовились к проведению исследования?
В качестве систем для тестирования нашего текста мы взяли самые распространённые системы классификации естественного языка:
· Классификатор от OpenAI
· Антиплагиат
· https://detectgpt.com/
· Zerogpt
· https://detectgpt.ericmitchell.ai/
Этот текст мы возьмём для тестирования:
Экономика — это наука, которая исследует, как люди, компании и государства используют ресурсы для производства, распределения и потребления товаров и услуг в определенной стране или регионе. Она имеет широкий диапазон интересов, включающий макро и микроэкономику, теорию и практику, национальную и международную экономику.
Макроэкономика исследует экономические тенденции на уровне всей страны или региона, такие как инфляция, безработица и рост ВВП. Микроэкономика фокусируется на решении проблем на уровне отдельных компаний и потребителей, таких как ценообразование и производство.
Экономика играет важную роль в жизни людей. Она определяет стабильность и процветание страны, влияет на уровень безработицы, доход и покупательскую способность граждан. Также экономика может бывать сильной или слабой, и это влияет на финансовый рынок и инвестиции.
В целом, экономика является ключевым элементом в жизни людей и человеческого общества в целом. Понимание экономических процессов и явлений помогает принимать обоснованные решения в финансовых вопросах, управлять бизнесом и даже личными финансами.
Одним из важных аспектов экономики является управление ресурсами, такими как финансы и трудовые ресурсы. Оптимизация использования ресурсов может привести к увеличению производительности, повышению экономического роста, сокращению затрат и улучшению жизни людей.
Кроме того, экономика может иметь влияние на природную среду, так как производство и потребление товаров и услуг означает использование ресурсов и энергии. Из этого следуют вопросы экономической устойчивости, которые подразумевают балансирование потребности людей в ресурсах с сохранением природных ресурсов для будущих поколений.
Современная экономика также включает в себя новые технологии, такие как цифровая и глобальная экономика. Эти технологии позволяют быстро обмениваться информацией, создавать новые бизнес-модели и продукты, что в свою очередь ведет к появлению новых рынков и возможностей для развития экономики.
Таким образом, экономика играет важную роль в жизни людей и определяет процветание страны в целом. Понимание процессов экономики помогает принимать разумные решения и успешно управлять ресурсами в динамичном мире.
Одним из важных направлений в экономике является международная экономика. Она исследует экономические отношения крупных государств и международные организации, а также транснациональные корпорации, участвующие во внешнеторговых и инвестиционных операциях. Международная экономика имеет большое значение для глобальной экономической стабильности, развития торговых отношений и улучшения жизни людей в различных странах.
Еще одним важным аспектом экономики является роль государства в экономике. Государство влияет на экономические процессы при помощи налоговой политики, фискальной политики и монетарной политики. Роль государства в экономике может быть различной, в том числе варьироваться от свободного рынка до государственного планирования. Большинство стран выбирают среднюю линию, совмещая элементы свободной рыночной экономики и государственного регулирования.
Экономика также связана с многими другими областями, такими как социология, политика, экология, инновации и технологии. Изучение экономики помогает понять многие аспекты жизни людей, а также дает возможность создавать новые бизнес-модели, технологии и продукты, которые могут сделать жизнь людей лучше.
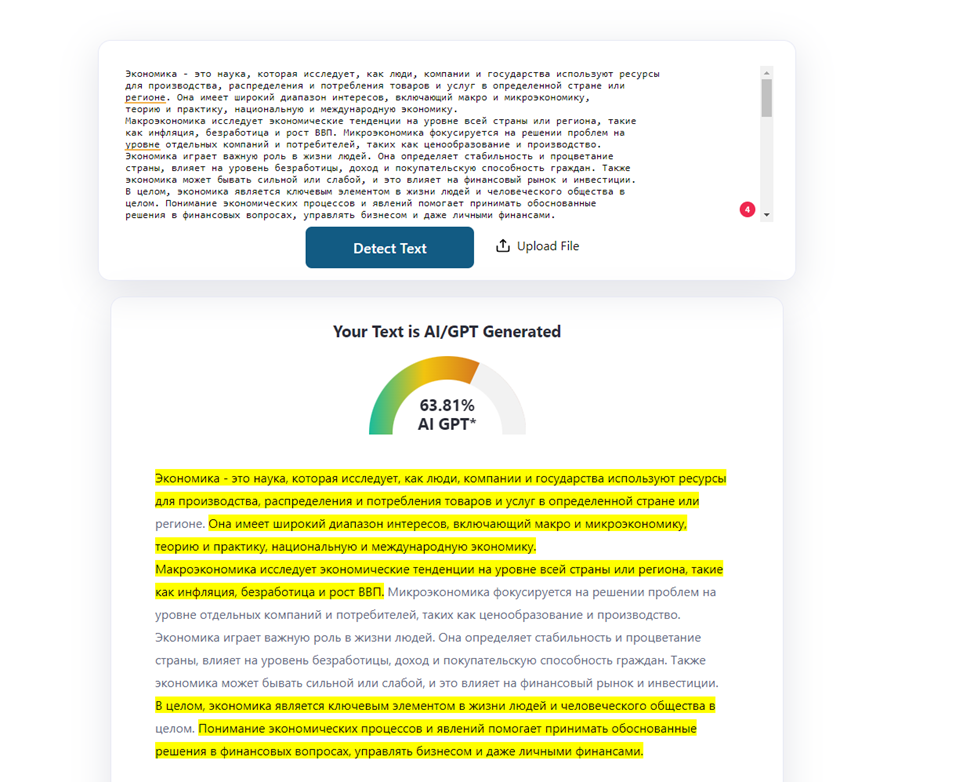
Этот текст сгенерирован при помощи GPT3.5. Мы взяли эту модель за основу, потому что она является самой популярной. Кроме того, сегодня существует огромное количество детекторов, позволяющих определить созданный ею текст. После генерации текста было принято решение сразу прогнать его через сервисы. Мы получили следующие результаты:

Результат, полученный при проверке текста при помощи Antiplagiat.ru
Стоит сразу отметить, что сервис также может определять тексты, написанные с использованием языковой модели. Эту возможность сервис получил в мае. Антиплагиат отметил весь текст, как написанный машиной.
Результат, полученный при проверке текста при помощи https://www.zerogpt.com/
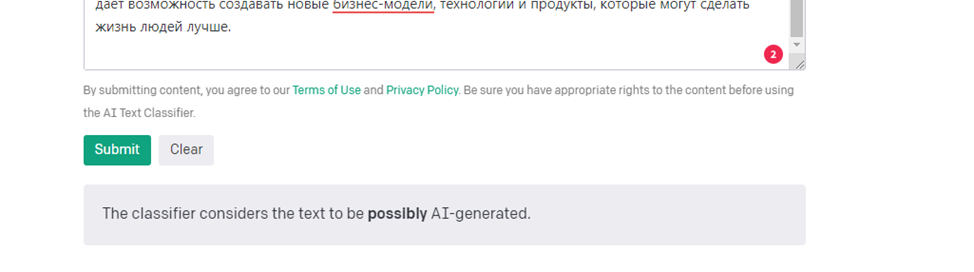
Классификатор от OpenAI распознал этот текст как «возможно сгенерированный при помощи ИИ». И это кажется невероятно странным, потому что мы точно знаем, что текст является машинным. Возможно, он сомневается из-за того, что он слабо обучен на других языках. Это мы проверим позже.

Результат, полученный при проверке текста при помощи классификатора от detectgpt от Эрика Митчелла (https://detectgpt.ericmitchell.ai/)
Данный ресурс определил, что 3694 токена, которые использовались при генерации текста, являются токенами GPT.
В ходе написания статьи было обнаружено, что множество из доступных детекторов машинного текста не определяют текст на русском или других языках. Им доступен лишь английский, поэтому было принято решение попросить ChatGPT перевести текст, который мы сгенерировали раннее. Вот что получилось:
Economics is a science that studies how people, companies, and governments use resources to produce, distribute, and consume goods and services in a particular country or region. It has a wide range of interests, including macro and microeconomics, theory and practice, national and international economics.
Macroeconomics examines economic trends at the level of an entire country or region, such as inflation, unemployment, and GDP growth. Microeconomics focuses on solving problems at the level of individual companies and consumers, such as pricing and production.
Economics plays an important role in people’s lives. It determines the stability and prosperity of a country, affects the level of unemployment, income and purchasing power of citizens. Also, the economy can be strong or weak, which affects the financial market and investments.
Overall, economics is a key element in the life of people and human society as a whole. Understanding economic processes and phenomena helps to make informed decisions on financial matters, manage businesses, and even personal finances.
One important aspect of economics is resource management, such as finances and labor resources. Optimizing resource usage can lead to increased productivity, economic growth, cost reduction and improvements in people’s lives.
In addition, economics can have an impact on the natural environment, as production and consumption of goods and services means using resources and energy. This leads to questions of economic sustainability, which involve balancing people’s resource needs with preserving natural resources for future generations.
Modern economics also includes new technologies, such as digital and global economics. These technologies allow for quick information exchange, creation of new business models and products, which in turn leads to the creation of new markets and opportunities for economic development.
Thus, economics plays an important role in people’s lives and determines the prosperity of a country as a whole. Understanding economic processes helps to make sensible decisions and successfully manage resources in a dynamic world.
One important area in economics is international economics. It studies economic relations between large countries and international organizations, as well as transnational corporations involved in foreign trade and investment operations. International economics is of great importance for global economic stability, development of trade relations and improvement of people’s lives in different countries.
Another important aspect of economics is the role of the state in the economy. The government influences economic processes through tax policy, fiscal policy, and monetary policy. The role of the state in the economy can vary from a free market to state planning. Most countries choose a middle ground, combining elements of a free market economy with government regulation.
Economics is also related to many other areas, such as sociology, politics, ecology, innovation, and technology. Studying economics helps to understand many aspects of people’s lives, as well as creates opportunities to develop new business models, technologies, and products that can make people’s lives better.
После перевода мы попросили определить текст на критерий «машинности».


Большинство из доступных детекторов также сообщили о том, что текст сгенерирован ИИ. Однако, антиплагиат.ру пока что не научился определять машинные тексты на английском.
Как образовалось направление классификации текста.

Потребность в классификации текста возникла ещё в конце 20-го века, когда с массовым распространением интернета и развитием отрасли информационных технологий стало возможным создание, накопление и обработка огромного объёма информации, включая текст.
Со временем было реализовано множество алгоритмов, однако они также могут быть применимы при классификации других типов данных. Рассмотрим некоторые из них:
1. Naive Bayes — вероятностный классификатор, основанный на предположении о независимости признаков. Он базируется на теореме Байеса, описывающей вероятность того, что событие А произойдет при условии, что случится событие B. Каждый объект рассматривается как набор характеристик или признаков, а каждый признак описывается вероятностной моделью. Алгоритм определяет вероятность того, что объект относится к определенному классу, основываясь на вероятности каждого признака по данному классу.
2. Метод опорных векторов (SVM): он делит текст на несколько категорий с помощью гиперплоскости, разграничивающей наборы данных. Этот метод является самым популярным для классификации текста. Но он имеет серьёзный недостаток, поскольку крайне неэффективен при работе с большим объёмом текста. Для этого могут потребоваться огромные вычислительные мощности.
3. Метод k-ближайших соседей (k-NN): используется для классификации на основе схожести текстов с другими наборами данных. Он работает путем поиска k ближайших соседей текста и определения наиболее часто встречающегося класса в этом множестве.
Этот метод имеет несколько недостатков. Во-первых, он чувствителен к выбору значения k и к типу метрики расстояния. Во-вторых, он может быть вычислительно дорогостоящим для больших наборов данных, поскольку требует измерения расстояния до каждого образца в обучающем наборе данных. В-третьих, он может испытывать сложности при работе с высоко размерными данными из-за «проклятия» размерности.
4. Древовидные алгоритмы классификации, включая метод случайные леса (Random Forests), применяются для многоклассовой классификации. С их помощью создаются решающие деревья на основе заданных правил для каждой категории и используются для классификации новых данных.
Однако, у Random Forests также есть некоторые недостатки. Во-первых, случайные леса могут быть довольно сложными и непрозрачными. Их часто называют «черными ящиками», поскольку они могут делать прогнозы без простого объяснения того, как пришли к этому прогнозу. Во-вторых, они могут быть вычислительно дорогостоящими и требовать много памяти, особенно при работе с большими наборами данных. В-третьих, они могут быть чувствительными к шуму и выбросам в данных.
Теперь перейдём к обзору теоретических и практических методов атак с использованием текста.
Атаки на уровне слов
Методы атаки на уровне слов генерируют состязательные примеры путем незначительных изменений отдельных слов в исходном тексте. Обычно это делается через:
1. Замену слов в тексте синонимами, чтобы трансформировать форму, но сохранить близкое значение. Например, вместо «отличный» пишут «превосходный»;
2. Перестановку близких по смыслу слов. Например, меняют местами «большой» и «огромный»;
3. Вставки, удаления или замены определенных маркеров. Например, вставляют «не» перед глаголом или убирают «очень» из прилагательного;
4. Замену предлогов и союзов. Поскольку эти части слов слабо влияют на семантику предложения, их легко заменить другими, не изменив смысла, но сбив ML-модель;
5. Расстановку запятых. Добавление, удаление или перемещение запятых может повлиять на структуру предложения и его смысловую разметку, что приводит к ошибке ML-модели.
Основная идея атак на уровне слов — вносить минимальные локальные изменения, которые незначительно влияют на человеческое понимание текста, но могут сбить ML-модель. Это позволяет генерировать более естественно звучащие и грамматически корректные состязательные примеры.
В статье Phrase-level Textual Adversarial Attack with Label Preservation был предложен метод для генерации текстов, создающий состязательные примеры через внесение изменений на уровне словосочетаний.
В предлагаемом методе авторы используют синтаксический парсинг для выделения уязвимых фраз в исходном тексте, которые затем заменяются на состязательные фразы, генерируемые моделью заполнения пропусков. Выбор наиболее эффективных состязательных фраз основан на оценке вероятности правильной классификации жертвой и соотношении правдоподобия моделей, настроенных на разные классы.
Эксперименты проводились на наборах данных Yelp Reviews, AG News, MNLI и QNLI. Предложенный метод показал лучшие результаты по сравнению с существующими методами текстовых состязательных атак по таким метрикам, как частота успешных атак, perplexity и сохранение меток.
Основными недостатками предложенного метода являются:
1. Медленная скорость генерации состязательных примеров. Метод использует достаточно тяжеловесные языковые модели (BART, RoBERTa) для генерации возможных замен фраз и оценки сохранения меток, что требует значительных вычислительных ресурсов. Авторы указывают, что для генерации 100 состязательных примеров требуется около 160 минут на GPU NVIDIA GTX 1080 Ti;
2. Невозможность полностью сохранить смысл исходного текста. Как показывает человеческая оценка, даже при использовании фильтра сохранения меток предложенный метод не может гарантировать 100% сохранение смысла текста после атаки. Это свойственно практически всем существующим методам текстовых состязательных атак;
3. Зависимость от размеченных данных. Метод использует языковые модели, обученные на размеченных по классам данных, для оценки вероятности сохранения метки. Это ограничивает применение метода на датасетах с небольшим количеством размеченных данных;
4. Уязвимость метода к усилению защиты моделей. Хотя он показывает хорошие результаты атаки на стандартные BERT-модели, предварительно обученные с использованием методов защиты от атак словарного уровня, его эффективность против моделей с более сильной защитой остается неизученной.
Незаметные атаки
Недавно на arxiv была опубликована статья Bad Characters: Imperceptible NLP Attacks. В ней исследователи предложили ряд атак методом чёрного ящика. Каждая из них является незаметной для человеческого глаза, но помогает обмануть NLP-системы по обработке естественного языка. Атаки, описанные в статье, работают, в том числе, на моделях с открытым исходным кодом, разработанных Microsoft, Facebook и IBM. Рассмотрим подробнее некоторые из них.
Атаки при помощи невидимых символов
Данный сценарий подразумевает использование символов, которые по спецификации не имеют глифа при отрисовке, для внесения изменений во входные данные модели. Например, символы U+200B (ZERO WIDTH SPACE), U+200C (ZERO WIDTH NON-JOINER) и U+200D (ZERO WIDTH JOINER) в Unicode.
Огромным недостатком (или преимуществом, если мы расследуем то, как был обманут классификатор) этого метода является то, что классификатор также можно обучить на поиск таких символов или, к примеру, включить в Word отображение непечатаемых символов. Это может раскрыть технику злоумышленника.
Атаки при помощи омоглифов
Ее суть состоит в использовании символов, которые отображаются одинаково или очень похоже, для внесения изменений во входные данные модели. Например, латинская A и кириллическая А могут быть взаимозаменяемыми в тексте, что позволяет обмануть машинный классификатор. У атаки при помощи омоглифов есть большое преимущество. Оно заключается в том, что на классификацию такого текста может потребоваться гораздо больше ресурсов. Чаще всего использование глифов может привести к некорректному срабатыванию классификатора, из-за которого злоумышленник получит высокие баллы.
Очевидный недостаток этого метода состоит в том, что шрифт, которым написан текст, может быть различным для букв-омоглифов. Это может быть заметно человеческому глазу. И то, что на некоторые буквы нет омоглифа –«Э» или «П» — прямо подтверждает этот факт. Но будем честны: и слов, которые состоят только из одной буквы «Э» или буквы «П», также нет. [КЮ6]
Изменение порядка
Заключается в применении символов управления направлением для изменения порядка отображения символов без изменения их кодирования. Это позволяет манипулировать порядком символов, передаваемых модели.
Удаления
Метод «Удалений» может быть использован при атаках на NLP-модели. Он основан на применении небольшого количества управляющих символов в Юникоде, таких как backspace (BS), delete (DEL) и carriage return (CR), которые могут привести к удалению соседнего текста или перезаписи его содержимого.
Атаки с использованием этого метода не зависят от шрифта или платформы, но их сложнее использовать на практике, так как большинство систем не копируют обрабатываемый текст в буфер обмена.
Авторы исследования реализовали сайт для того, чтобы можно было сгенерировать текст, который будет заведомо вредоносным: https://imperceptible.ml/generator. Им мы и воспользуемся, чтобы проверить недостатки классификаторов машинного текста.
Результаты
Метод с символами нулевой ширины
Классификатор от OpenAI (русский текст):

Антиплагиат (русский текст):

(помечает как странный)
DetectGpt (английский текст):

Не может определить текст. Возможно, это перебои сервиса.
Zerogpt (русский текст): текст полностью написан человеком (0% машинности).
detectgpt.ericmitchell (английский текст): Your text is 3571 GPT-2 tokens! To not
