Всегда ли хорош Index Only Scan?
Среди применяемых в PostgreSQL методов доступа к данным Index Only Scan стоит особняком, считаясь у многих разработчиков «волшебной пилюлей» для ускорения работы запроса — мол,»Index Scan — плохо, Index Only Scan — хорошо, как только получим его в плане — все станет замечательно».
Как минимум, это утверждение неверно. Как максимум, при определенных условиях может вызвать проблемы чуть ли не на ровном месте.
Как PostgreSQL хранит данные
Для начала, вспомним, что в PostgreSQL данные таблицы и индексы для нее лежат одинаково, хотя и в разных файлах. Организация физического хранения данных в PostgreSQL, в предельно упрощенном виде выглядит так:
каждая таблица или индекс — отдельный файл данных (
pg_class.relfilenode)каждый файл делится на физические сегменты, не превышающие 1GB
каждый сегмент состоит из последовательности страниц данных по (обычно) 8KB
страница данных содержит непосредственно набор записей
дополнительно к файлу данных используются два файла с картами: Free Space Map (FSM) и Visibility Map (VM)
Вот как раз с последней и могут возникать проблемы:
Карта может отражать реальные данные с запаздыванием в том смысле, что мы уверены, что в случаях, когда установлен бит, известно, что условие верно, но если бит не установлен, оно может быть верным или неверным. Биты карты видимости устанавливаются только при очистке, а сбрасываются при любых операциях, изменяющих данные на странице.
Как работает Index Scan
Для поиска необходимой записи Index Scan:
переходит по записям структуры btree-дерева в файле индекса, пока не дойдет до «листа», указывающего на файл таблицы
извлекает запись из файла таблицы необходимую запись, удостоверяясь в ее «видимости» для текущей транзакции (по значениям
xmin/xmax)

Схема работы Index Scan
Как работает Index Only Scan
Index Only Scan может быть выбран в качестве способа извлечения записей в случае чтения запросом только полей, которые присутствуют в самом индексе — его ключах или INCLUDE-списке.
По этой причине использование
SELECT * FROM ...почти всегда «ломает» возможность использованияIndex Only Scan.
Для поиска необходимой записи Index Only Scan:
переходит по записям структуры btree-дерева в файле индекса, пока не дойдет до «листа», указывающего на файл таблицы
проверяет бит «видимости» всех записей нужной страницы с помощью Visibility Map
если бит не взведен, ровно как «обычный»
Index Scan, извлекает запись из файла таблицы необходимую запись, удостоверяясь в ее «видимости» для текущей транзакции (по значениямxmin/xmax)
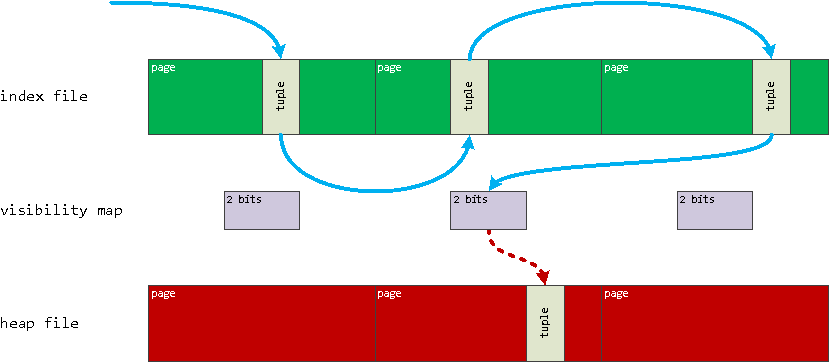
Схема работы Index Only Scan
Понятно, что со временем для большинства страниц данных в базе бит полной видимости будет взведен, и «в среднем» проверка одного бита VM существенно дешевле, чем извлечение целой записи из файла таблицы.
Проблемы Index Only Scan
Однако, в силу алгоритма заполнения VM, существуют ситуации, когда Index Only Scan всегда придется извлекать запись из таблицы, постоянно проигрывая «обычному» Index Scan на необходимости проверки данных VM.
Процитирую документацию еще раз:
Биты карты видимости устанавливаются только при очистке, а сбрасываются при любых операциях, изменяющих данные на странице.
Из этого предложения следует ровно два паттерна, когда Index Only Scan будет заведомо неэффективен:
извлечение «свежевставленных» записей, которые еще не успел пройти
[auto]VACUUMналичие даже редких
UPDATE/DELETEпо произвольно разбросанным по страницам записям
Рассмотрим на простом примере «типа-мониторинга», когда у нас есть метрика (m) и метка времени (ts):
-- создаем исходную таблицу с 1M случайных записей
CREATE TABLE ios_orig AS
SELECT
(random() * 1e3)::integer m -- метрика
, now() - (random() * '1 msec'::interval) ts -- метка времени
FROM
generate_series(1, 1e6);
-- копируем данные в тестовую таблицу
CREATE TABLE ios_test AS
TABLE ios_orig;
-- создаем индекс, по которому будем искать
CREATE INDEX ON ios_test(m, ts);Попробуем отобрать часть записей по условию, четко ложащемуся на индекс:
EXPLAIN (ANALYZE, BUFFERS, COSTS OFF)
SELECT
m
, ts
FROM
ios_test
WHERE
m > 900
ORDER BY m;Heap Fetches как признак беды
… и получаем время выполнения дольше 80ms:
Index Only Scan using ios_test_m_ts_idx on ios_test (actual time=0.032..75.224 rows=99094 loops=1)
Index Cond: (m > 900)
Heap Fetches: 99094
Buffers: shared hit=99478
Planning Time: 0.084 ms
Execution Time: 80.838 msОбратите внимание на строку Heap Fetches — ровно она показывает нам количество записей, которые пришлось «достать» из файла таблицы.
Поскольку в нашем случае записи размазаны «ровным слоем», то пришлось вычитывать по отдельной странице данных для каждой из них.
Index Only Scan vs Index Scan
Давайте попробуем заставить PostgreSQL воспользоваться «обычным» Index Scan:
SET enable_indexonlyscan = FALSE;Index Scan using ios_test_m_ts_idx on ios_test (actual time=0.028..64.810 rows=99094 loops=1)
Index Cond: (m > 900)
Buffers: shared hit=99478
Planning Time: 0.091 ms
Execution Time: 70.010 msМы вычитали ровно столько же данных, но сделали это почти на 15% быстрее! А ведь вся разница — лишь в необходимости проверки VM.
Когда Index Only Scan все-таки выигрывает
Давайте все-таки приведем Visibility Map в порядок — для для этого нам необходимо прогнать VACUUM:
VACUUM ios_test;
RESET enable_indexonlyscan;Index Only Scan using ios_test_m_ts_idx on ios_test (actual time=0.026..15.500 rows=99094 loops=1)
Index Cond: (m > 900)
Heap Fetches: 0
Buffers: shared hit=400
Planning Time: 0.080 ms
Execution Time: 20.831 msВот теперь все отлично Heap Fetches: 0, а время выполнения запроса сократилось в 4 раза!
Подведем промежуточные итоги:
Exec Time | Buffers | |
Index Only Scan + bad VM | 80.838 ms | 99 478 |
Index Scan | 70.010 ms | 99 478 |
Index Only Scan + good VM | 20.831 ms | 400 |
То есть при актуальном состоянии VM мы получаем кратный прирост производительности запроса, а ее неактуальное состояние мы можем контролировать с помощью метрики Heap Fetches.
А чтобы вы могли быстро понять причину подобной проблемы в своем запросе, мы добавили в наш сервис анализа планов explain.tensor.ru в набор автоматических рекомендаций еще и эту проверку:
 INSERT INTO ios_test
TABLE ios_orig;
INSERT INTO ios_test
TABLE ios_orig;
Index Only Scan using ios_test_m_ts_idx on ios_test (actual time=0.036..86.064 rows=198188 loops=1)
Index Cond: (m > 900)
Heap Fetches: 99102
Buffers: shared hit=99660
Planning Time: 0.133 ms
Execution Time: 96.159 msЗаписей теперь отбирается вдвое больше, но в Heap Fetches попала только «новая» часть — поэтому в наших интересах заставить VACUUM выполняться как можно чаще на нашей таблице.
Для этого существует несколько способов, игнорирование которых может вызвать проблемы:
autovacuum_naptime — этот параметр определяет как часто должен стартовать autovacuum-процесс
Если вдруг вы решили сэкономить на «паразитной» активности PostgreSQL и выкрутили значение до
'1d'(раз в день), а потом массово что-то записали в таблицу, то будете получатьHeap Fetchesвсе это время.Поэтому нелишним может оказаться «ручной» запуск
VACUUMпосле каких-то больших импортов или по таймеру — например, мы таким способом по ночам актуализируем данные в секции прошедших суток.autovacuum_vacuum_threshold и autovacuum_vacuum_insert_threshold (плюс autovacuum_vacuum_scale_factor и autovacuum_vacuum_insert_scale_factor) отвечают за автоматический запуск VACUUM на таблице после изменения/вставки определенного количества (или процента) записей
Они могут быть определены как для всего сервера в целом, так и заданы для определенных, наиболее «горячих», таблиц с помощью команды
ALTER TABLE ... SET ( autovacuum_vacuum_threshold = ... );
