Как устроены пакеты для проверки качества случайных последовательностей?
Вопрос получения случайных и псевдослучайных последовательностей всегда вызывает оживленный интерес[1][2][3][и т.д.]. Часто [1],[2][и т.д.] упоминаются и пакеты статистических тестов, такие как NIST, DieHard, TestU01.
В комментариях к статьям на Хабрахабр встречаются вопросы о том, как данные пакеты получают итоговые цифры. В целом тут нет ничего сложного — это просто статистика. Если читателю интересна магия получения данных цифр, то прошу под кат, там много буков и формул.
По возможности хочется сделать изложение максимально понятным для неподготовленного пользователя, поэтому прошу простить за некоторые неточности и опущенные определения.
Общая схема
Статистический анализ последовательностей, как правило, проходит в два этапа.
- Первый этап можно назвать подготовительным, он самый трудоемкий, здесь выполняется основная масса вычислений.
1.1. При помощи исследуемого генератора формируются случайные последовательности.
1.2. Для каждой последовательности вычисляется статистика теста. Если работает батарея тестов (проводится сразу несколько тестов), то статистика по последовательности вычисляется для каждого теста.
1.3. Для каждой последовательности, вычисляется вероятность значимости.
1.4. Полученные статистики и вероятности значимости сохраняются. - На втором этапе проводится обработка, полученных результатов.
2.1. При помощи критериев согласия проверяются гипотезы о соответствии распределений статистик и вероятностей значимости гипотетическим распределениям.
2.2. Определяется, число последовательностей, прошедших тест. Строится доверительный интервал для последней величины.
2.3. Принимается решение о том, пройден ли тест.
2.4. Окончательные выводы.
Схематично этот процесс можно представить примерно так:

Формирование статистики
Целью каждого теста является проверка гипотезы о том, что исследуемая последовательность имеет равномерное распределение. Если говорить более строго, то каждый знак случайной последовательности
должен иметь равномерное распределение вероятностей:
. Эта гипотеза обозначается через
(говорят, нулевая гипотеза).
А от куда появляются формулы для статистик тестов? Давайте рассмотрим это на примере частотного теста из пакета NIST.
Каждый статистический тест проверяет некоторое предположение о том или ином свойстве, которым должна обладать случайная последовательность, удовлетворяющая гипотезе .
Для частотного теста из набора тестов NIST таким предположением является утверждение: «Если последовательность удовлетворяет гипотезе , то количество нулей и единиц в этой последовательности должно быть примерно одинаковым».
Если найти сумму знаков исследуемой последовательности, то итоговый результат будет представлять случайную величину, назовем ее :
. Согласно, центральной предельной теореме случайная величина
в наших предположениях должна иметь распределение близкое к нормальному распределению с математическим ожиданием
и среднеквадратичным отклонением
.
Так как нас интересует отклонение количества единиц (нулей) от математического ожидания, будем рассматривать случайную величину . Разделим ее на
, чтобы дисперсия полученной величины равнялась 1. И возьмем все это по модулю, так как знак отклонения нас не интересует. Что получилось?
.
Получилась случайная величина, зависящая от исследуемой последовательности. Функция распределения этой случайной величины в предположении гипотезы равна:
(нулю при остальных x),
где — функция стандартного нормального распределения.
Величину S, вычисленную по конкретной последовательности X называют «статистикой». Если заглянуть в описание тестов NIST, то можно найти именно эту формулу для вычисления статистики теста.
Пользуясь аналогичными рассуждениями появляются и формулы для других тестов.
Как отличить «хорошую» последовательность от «плохой»?
Нужно определить значимо ли отклоняется статистика S от нуля или нет.
Отклонение не должно быть «слишком» большим. Слово «слишком», не дает конкретных указаний к действию. Поэтому выберем некоторый критический уровень — вероятность ошибочно отвергнуть гипотезу
. Данному
соответствует критическое значение
, которое определяет критическую область. Продемонстрируем это на картинках:
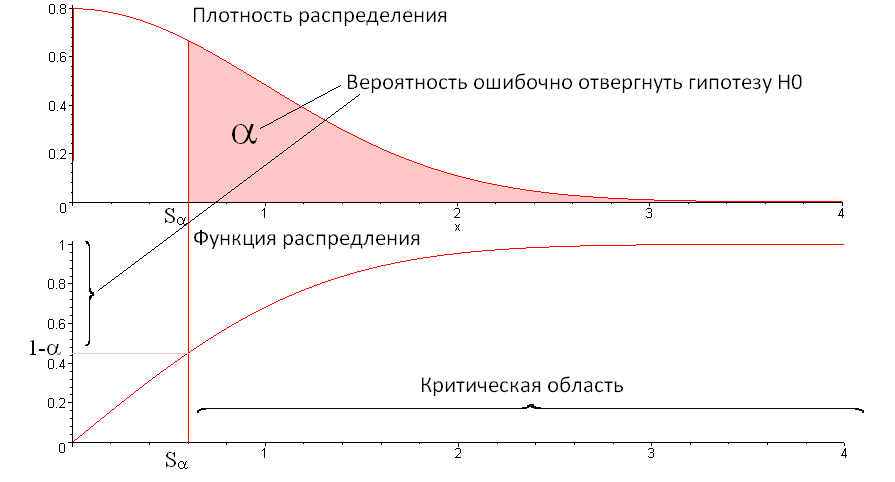
Иными словами представляет собой границу для принятия решения, прошла ли последовательность тест или нет. Если значение
, то считаем, что последовательность «хорошая» — прошла тест. Если S попало в критическую область
, то считаем последовательность плохая — не прошла тест.
В пакетах статистических исследований чаще применяется другой эквивалентный метод принятия решения. По статистике S вычисляют вероятность значимости p, которая равна: . Данное значение будет меньше или равно
, только в случае попадания S в критическую область.
Обычно выбирают в диапазоне от 0.01 до 0.001. Чем больше
, тем больше последовательностей будут отвергаться.
Дальнейшие выводы
Сразу напрашивается вопрос: «Как отбраковать генератор (псевдо)случайных чисел, если часть последовательностей плохая, а часть хорошая?»
На самом деле любой генератор случайных последовательностей всегда будет генерировать часть последовательностей, которые не пройдут тест. Я бы даже сказал, что если все последовательности пройдут тест, то это очень подозрительно.
Итак, обработка результатов.
На первом этапе генерируется V последовательностей длины n — . Для каждой последовательности
вычисляется статистика
и вероятность значимости
, т.е. получаются два набора: набор статистик
и набор вероятностей значимости
.
На втором этапе производится обработка полученных выборок и
.
Сначала к этим последовательностям применяются критерии согласия. Выборка должна иметь распределение, описанное выше, а выборка
должна иметь равномерное распределение на отрезке [0;1]. Например, я обычно для первой последовательности применяю критерий Космогорова-Смиронова, а для второй критерий Пирсона.
В целом применение этих критериев аналогично выполнению статистического теста, описанного выше. Разница состоит лишь в применяемых статистиках.
Применение критерия Пирсона
Для критерий Пирсона применяется так:
Область возможных значений P (отрезок [0,1]) делится на Т одинаковых отрезков. Значение T обычно выбирается не очень большим, например, 10 или 20. В предположении, что P имеет равномерное распределение, в среднем в каждый интервал должно попадать V/Т значений (кстати, T надо выбрать так, чтобы V/T>5).
По выборке P формируется гистограмма — количество значений, попавших в каждый интервал. Далее вычисляется статистика Пирсона
. Указанная статистика в предположении, что исходная последовательность распределена равномерно на отрезке [0,1], должна иметь распределение Хи-квадрат с Т-1 степенью свободы (пусть
— функция распределения Хи-квадрат с Т-1 степенью свободы). Значение функции
вычисляют программно или по специальным таблицам (при ручном применении критерия).
Для статистики вычисляется вероятность значимости
. Если
, то гипотеза о равномерном распределении не отвергается.
Сколько последовательностей должно пройти тест?
Далее исследуется количество последовательностей, прошедших тест.
Так как вероятностей значимости распределены равномерно на отрезке [0,1], то в среднем тест должно пройти последовательностей. Но сравнивать полученное число с
нет смысла. Вместо этого строится доверительный интервал.
Приведу доверительный интервал для доли последовательностей прошедших тест.
Последовательности соответствует последовательность V независимых испытаний Бернулли
:
Согласно центральной предельной теореме распределение числа успехов в последовательности испытаний Бернулли, совпадающее с числом последовательностей, прошедших тест, можно считать нормальным с математическим ожиданием и дисперсией
.
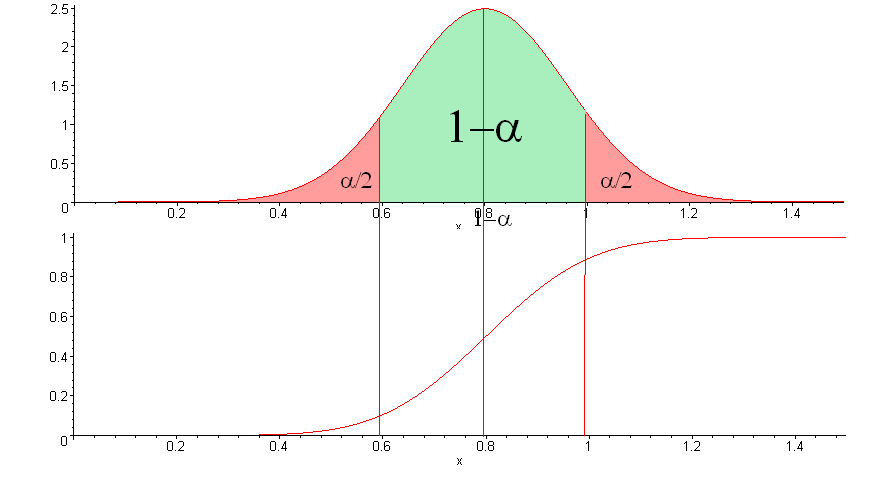
Если выбрать уровень доверия , то доверительный интервал равен:
На рисунке доверительный интервал — значения x под зеленой областью.
В предположении, что исходные последовательности имеют равномерное распределение, доля последовательностей прошедших тест с вероятностью должна попасть в этот интервал.
Если использовать «правило », то интервал будет таким:
Если рассчитанная доля последовательностей попала в доверительный интервал, то тест считается пройденным.
Как работает батарея тестов
Выше рассмотрено описание тестирования по одному тесту. Если батарея содержит несколько тестов, то описанные исследования проводятся для каждого теста.
На выходе выдается табличка, какие тесты пройдены, и процент пройденных тестов.
Литература
- NIST (a statistical test suite for random and pseudorandom number generators for cryptographic applications), http://csrc.nist.gov
- Ивченко Г.И., Медведев Ю.И. Математическая статистика: Учеб. пособие для втузов. — М.: Высш. шк., 1984.
- Кнут Д. Искусство программирования: в 3т. — М.: Мир, 1992
- Ван дер Варден Б.Л., Математическая статистика. — М.: Издательство иностранной литературы, 1960
