Как устроен парсер Python, и как втрое уменьшить потребление им памяти

В Python всё немного сложнее: парсеров два. Первый парсер руководствуется грамматикой, заданной в файле Grammar/Grammar в виде регулярных выражений (с не совсем обычным синтаксисом). По этой грамматике при помощи Parser/pgen во время компиляции python генерируется целый набор конечных автоматов, распознающих заданные регулярные выражения — по одному КА для каждого нетерминала. Формат получающегося набора КА описан в Include/grammar.h, а сами КА задаются в Python/graminit.c, в виде глобальной структуры _PyParser_Grammar. Терминальные символы определены в Include/token.h, и им соответствуют номера 0…56; номера нетерминалов начинаются с 256.
Проиллюстрировать работу первого парсера проще всего на примере.
Пусть у нас есть программа if 42: print("Hello world")
single_input: NEWLINE | simple_stmt | compound_stmt NEWLINE
compound_stmt: if_stmt | while_stmt | for_stmt | try_stmt | with_stmt | funcdef | classdef | decorated | async_stmt
if_stmt: 'if' test ':' suite ('elif' test ':' suite)* ['else' ':' suite]
suite: simple_stmt | NEWLINE INDENT stmt+ DEDENT
simple_stmt: small_stmt (';' small_stmt)* [';'] NEWLINE
small_stmt: expr_stmt | del_stmt | pass_stmt | flow_stmt | import_stmt | global_stmt | nonlocal_stmt | assert_stmt
expr_stmt: testlist_star_expr (annassign | augassign (yield_expr|testlist) | ('=' (yield_expr|testlist_star_expr))*)
testlist_star_expr: (test|star_expr) (',' (test|star_expr))* [',']
test: or_test ['if' or_test 'else' test] | lambdef
or_test: and_test ('or' and_test)*
and_test: not_test ('and' not_test)*
not_test: 'not' not_test | comparison
comparison: expr (comp_op expr)*
expr: xor_expr ('|' xor_expr)*
xor_expr: and_expr ('^' and_expr)*
and_expr: shift_expr ('&' shift_expr)*
shift_expr: arith_expr (('<<'|'>>') arith_expr)*
arith_expr: term (('+'|'-') term)*
term: factor (('*'|'@'|'/'|'%'|'//') factor)*
factor: ('+'|'-'|'~') factor | power
power: atom_expr ['**' factor]
atom_expr: [AWAIT] atom trailer*
atom: '(' [yield_expr|testlist_comp] ')' | '[' [testlist_comp] ']' | '{' [dictorsetmaker] '}' |
NAME | NUMBER | STRING+ | '...' | 'None' | 'True' | 'False'
trailer: '(' [arglist] ')' | '[' subscriptlist ']' | '.' NAME
arglist: argument (',' argument)* [',']
argument: test [comp_for] | test '=' test | '**' test | '*' test
static arc arcs_0_0[3] = {
{2, 1},
{3, 1},
{4, 2},
};
static arc arcs_0_1[1] = {
{0, 1},
};
static arc arcs_0_2[1] = {
{2, 1},
};
static state states_0[3] = {
{3, arcs_0_0},
{1, arcs_0_1},
{1, arcs_0_2},
};
//...
static arc arcs_39_0[9] = {
{91, 1},
{92, 1},
{93, 1},
{94, 1},
{95, 1},
{19, 1},
{18, 1},
{17, 1},
{96, 1},
};
static arc arcs_39_1[1] = {
{0, 1},
};
static state states_39[2] = {
{9, arcs_39_0},
{1, arcs_39_1},
};
//...
static arc arcs_41_0[1] = {
{97, 1},
};
static arc arcs_41_1[1] = {
{26, 2},
};
static arc arcs_41_2[1] = {
{27, 3},
};
static arc arcs_41_3[1] = {
{28, 4},
};
static arc arcs_41_4[3] = {
{98, 1},
{99, 5},
{0, 4},
};
static arc arcs_41_5[1] = {
{27, 6},
};
static arc arcs_41_6[1] = {
{28, 7},
};
static arc arcs_41_7[1] = {
{0, 7},
};
static state states_41[8] = {
{1, arcs_41_0},
{1, arcs_41_1},
{1, arcs_41_2},
{1, arcs_41_3},
{3, arcs_41_4},
{1, arcs_41_5},
{1, arcs_41_6},
{1, arcs_41_7},
};
//...
static dfa dfas[85] = {
{256, "single_input", 0, 3, states_0,
"\004\050\340\000\002\000\000\000\012\076\011\007\262\004\020\002\000\300\220\050\037\102"},
//...
{270, "simple_stmt", 0, 4, states_14,
"\000\040\200\000\002\000\000\000\012\076\011\007\000\000\020\002\000\300\220\050\037\100"},
//...
{295, "compound_stmt", 0, 2, states_39,
"\000\010\140\000\000\000\000\000\000\000\000\000\262\004\000\000\000\000\000\000\000\002"},
{296, "async_stmt", 0, 3, states_40,
"\000\000\040\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000"},
{297, "if_stmt", 0, 8, states_41,
"\000\000\000\000\000\000\000\000\000\000\000\000\002\000\000\000\000\000\000\000\000\000"},
// ^^^
//...
};
static label labels[176] = {
{0, "EMPTY"},
{256, 0},
{4, 0}, // №2
{270, 0}, // №3
{295, 0}, // №4
//...
{305, 0}, // №26
{11, 0}, // №27
//...
{297, 0}, // №91
{298, 0},
{299, 0},
{300, 0},
{301, 0},
{296, 0},
{1, "if"}, // №97
//...
};
grammar _PyParser_Grammar = {
86,
dfas,
{176, labels},
256
};
Парсер начинает разбор с КА для single_input; этот КА задан массивом states_0 из трёх состояний. Из начального состояния выходят три дуги (arcs_0_0), соответствующие входным символам NEWLINE (метка №2, символ №4), simple_stmt (метка №3, символ №270) и compound_stmt (метка №4, символ №295). Входной терминал "if" (символ №1, метка №97) входит во множество d_first для compound_stmt, но не для simple_stmt — ему соответствует бит \002 в 13-том байте множества. (Если во время разбора оказывается, что очередной терминал входит во множества d_first сразу для нескольких исходящих дуг, то парсер выводит сообщение о том, что грамматика неоднозначна, и отказывается продолжать разбор.) Итак, парсер переходит по дуге {4, 2} в состояние №2, и одновременно переключается к КА compound_stmt, заданному массивом states_39. В этом КА из начального состояния выходят сразу девять дуг (arcs_39_0); выбираем среди них дугу {91, 1}, соответствующую входному символу if_stmt (№297). Парсер переходит в состояние №1 и переключается к КА if_stmt, заданному массивом states_41. 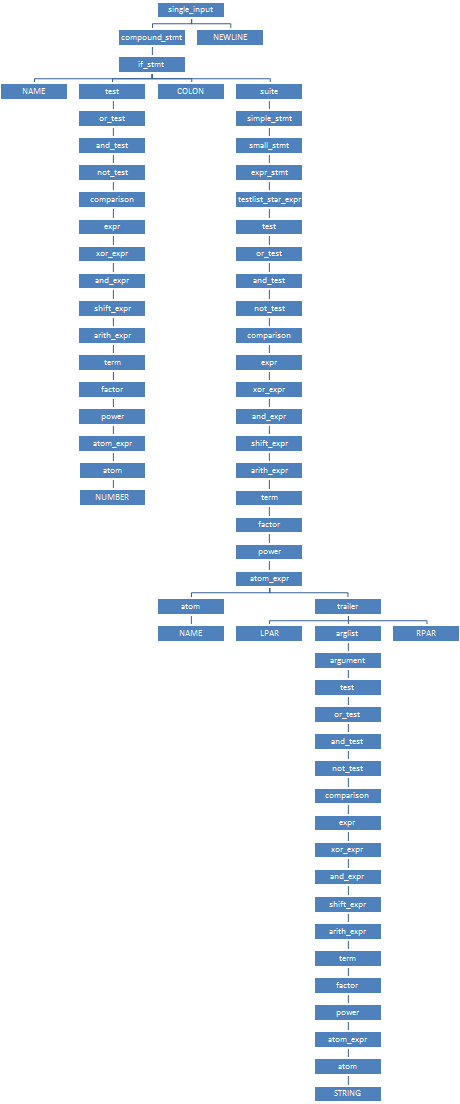 Из начального состояния этого КА выходит всего одна дуга
Из начального состояния этого КА выходит всего одна дуга {97, 1}, соответствующая нашему входному терминалу "if". По ней парсер переходит в состояние №1, откуда опять выходит единственная дуга {26, 2}, соответствующая нетерминалу test (№305). По этой дуге парсер переходит в состояние №2 и переключается к КА test, и так далее. После долгого-предолгого превращения числа 42 в нетерминал test, парсер вернётся в состояние №2, из которого выходит единственная дуга {27, 3}, соответствующая терминалу COLON (символ №11), и продолжит разбор нетерминала if_stmt. В качестве результата его разбора парсер создаст узел конкретного синтаксического дерева (структура node), у которого будет тип узла №297, и четыре ребёнка — типов №1 (NAME), №305 (test), №11 (COLON) и №304 (suite). В состоянии №4 создание узла для if_stmt завершится, парсер вернётся в состояние №1 КА compound_stmt, и вновь созданный узел для if_stmt станет единственным ребёнком узла, соответствующего compound_stmt. Целиком КСД нашей программы будет выглядеть так, как показано справа. Заметьте, как короткая программа из семи терминалов
NAME NUMBER COLON NAME LPAR STRING RPARpython исходные файлы размером всего в несколько десятков мегабайт приводят к фатальной MemoryError.Для работы с КСД в Python есть стандартный модуль parser:
$ python
Python 3.7.0a0 (default:98c078fca8e0, Oct 31 2016, 08:33:23)
[GCC 4.7.3] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import parser
>>> parser.suite('if 42: print("Hello world")').tolist()
[257, [269, [295, [297, [1, 'if'], [305, [309, [310, [311, [312, [315, [316, [317, [318, [319, [320, [321, [322, [323, [324, [2, '42']]]]]]]]]]]]]]]], [11, ':'], [304, [270, [271, [272, [274, [305, [309, [310, [311, [312, [315, [316, [317, [318, [319, [320, [321, [322, [323, [324, [1, 'print']], [326, [7, '('], [334, [335, [305, [309, [310, [311, [312, [315, [316, [317, [318, [319, [320, [321, [322, [323, [324, [3, '"Hello world"']]]]]]]]]]]]]]]]]], [8, ')']]]]]]]]]]]]]]]]]]], [4, '']]]]]], [4, ''], [0, '']]
>>>
В его исходном коде (
Modules/parsermodule.c) для проверки КСД на соответствие грамматике Python были >2000 рукописных строк, которые выглядели примерно так: //...
/* simple_stmt | compound_stmt
*
*/
static int
validate_stmt(node *tree)
{
int res = (validate_ntype(tree, stmt)
&& validate_numnodes(tree, 1, "stmt"));
if (res) {
tree = CHILD(tree, 0);
if (TYPE(tree) == simple_stmt)
res = validate_simple_stmt(tree);
else
res = validate_compound_stmt(tree);
}
return (res);
}
static int
validate_small_stmt(node *tree)
{
int nch = NCH(tree);
int res = validate_numnodes(tree, 1, "small_stmt");
if (res) {
int ntype = TYPE(CHILD(tree, 0));
if ( (ntype == expr_stmt)
|| (ntype == del_stmt)
|| (ntype == pass_stmt)
|| (ntype == flow_stmt)
|| (ntype == import_stmt)
|| (ntype == global_stmt)
|| (ntype == nonlocal_stmt)
|| (ntype == assert_stmt))
res = validate_node(CHILD(tree, 0));
else {
res = 0;
err_string("illegal small_stmt child type");
}
}
else if (nch == 1) {
res = 0;
PyErr_Format(parser_error,
"Unrecognized child node of small_stmt: %d.",
TYPE(CHILD(tree, 0)));
}
return (res);
}
/* compound_stmt:
* if_stmt | while_stmt | for_stmt | try_stmt | with_stmt | funcdef | classdef | decorated
*/
static int
validate_compound_stmt(node *tree)
{
int res = (validate_ntype(tree, compound_stmt)
&& validate_numnodes(tree, 1, "compound_stmt"));
int ntype;
if (!res)
return (0);
tree = CHILD(tree, 0);
ntype = TYPE(tree);
if ( (ntype == if_stmt)
|| (ntype == while_stmt)
|| (ntype == for_stmt)
|| (ntype == try_stmt)
|| (ntype == with_stmt)
|| (ntype == funcdef)
|| (ntype == async_stmt)
|| (ntype == classdef)
|| (ntype == decorated))
res = validate_node(tree);
else {
res = 0;
PyErr_Format(parser_error,
"Illegal compound statement type: %d.", TYPE(tree));
}
return (res);
}
//...
Легко догадаться, что такой однообразный код можно было бы и автоматически генерировать по формальной грамматике. Немногим сложнее догадаться, что такой код уже генерируется автоматически — именно так работают автоматы, используемые первым парсером! Выше я затем в подробностях объяснял его устройство, чтобы пояснить, каким образом я в марте этого года предложил заменить все эти простыни рукописного кода, которые нужно править каждый раз, когда меняется грамматика, — на прогон всех тех же самых автоматически сгенерированных КА, которыми пользуется сам парсер. Это к разговорам о том, нужно ли программистам знать алгоритмы.
В июне мой патч был принят, так что в Python 3.6+ вышеприведённых простыней в Modules/parsermodule.c уже нет, а зато есть несколько десятков строк моего кода. 
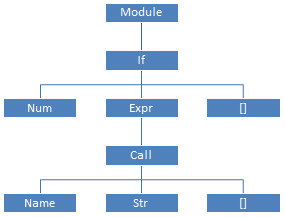 Работать с таким громоздким и избыточным КСД, как было показано выше, довольно неудобно; и поэтому второй парсер (
Работать с таким громоздким и избыточным КСД, как было показано выше, довольно неудобно; и поэтому второй парсер (Python/ast.c), написанный целиком вручную, обходит КСД и создаёт по нему абстрактное синтаксическое дерево. Грамматика АСД описана в файле Parser/Python.asdl; для нашей программы АСД будет таким, как показано справа.
Вместо работы с КСД при помощи модуля parser, документация советует использовать модуль ast и работать с абстрактным деревом:
$ python
Python 3.7.0a0 (default:98c078fca8e0, Oct 31 2016, 08:33:23)
[GCC 4.7.3] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import ast
>>> ast.dump(ast.parse('if 42: print("Hello world")'))
"Module(body=[If(test=Num(n=42), body=[Expr(value=Call(func=Name(id='print', ctx=Load()), args=[Str(s='Hello world')], keywords=[]))], orelse=[])])"
>>>
Как только АСД создано — КСД больше низачем не нужно, и вся занятая им память освобождается; поэтому для «долгоиграющей» программы на Python нет большого значения, сколько памяти занимало КСД. С другой стороны, для больших, но «скорострельных» скриптов (например, поиск значения в огромном
dict-литерале) — размер КСД как раз и будет определять потребление памяти скриптом. Всё это впридачу к тому, что именно размер КСД определяет, хватит ли памяти для того, чтобы загрузить и запустить программу.Необходимость прохода по длинным «бамбуковым ветвям» делает код Python/ast.c просто отвратительным:
static expr_ty
ast_for_expr(struct compiling *c, const node *n)
{
//...
loop:
switch (TYPE(n)) {
case test:
case test_nocond:
if (TYPE(CHILD(n, 0)) == lambdef ||
TYPE(CHILD(n, 0)) == lambdef_nocond)
return ast_for_lambdef(c, CHILD(n, 0));
else if (NCH(n) > 1)
return ast_for_ifexpr(c, n);
/* Fallthrough */
case or_test:
case and_test:
if (NCH(n) == 1) {
n = CHILD(n, 0);
goto loop;
}
// обработка булевых операций
case not_test:
if (NCH(n) == 1) {
n = CHILD(n, 0);
goto loop;
}
// обработка not_test
case comparison:
if (NCH(n) == 1) {
n = CHILD(n, 0);
goto loop;
}
// обработка comparison
case star_expr:
return ast_for_starred(c, n);
/* The next five cases all handle BinOps. The main body of code
is the same in each case, but the switch turned inside out to
reuse the code for each type of operator.
*/
case expr:
case xor_expr:
case and_expr:
case shift_expr:
case arith_expr:
case term:
if (NCH(n) == 1) {
n = CHILD(n, 0);
goto loop;
}
return ast_for_binop(c, n);
// case yield_expr: и его обработка
case factor:
if (NCH(n) == 1) {
n = CHILD(n, 0);
goto loop;
}
return ast_for_factor(c, n);
case power:
return ast_for_power(c, n);
default:
PyErr_Format(PyExc_SystemError, "unhandled expr: %d", TYPE(n));
return NULL;
}
/* should never get here unless if error is set */
return NULL;
}
Многократно повторяющиеся на всём протяжении второго парсера
if (NCH(n) == 1) n = CHILD(n, 0); — иногда, как в этой функции, внутри цикла — означают «если у текущего узла КСД всего один ребёнок, то вместо текущего узла надо рассматривать его ребёнка».Но разве что-то мешает сразу во время создания КСД удалять «однодетные» узлы, подставляя вместо них их детей? Ведь это и сэкономит кучу памяти, и упростит второй парсер, позволяя избавиться от многократного повторения goto loop; по всему коду, от вида которого Дейкстра завращался бы волчком в своём гробу!
В марте, вместе с вышеупомянутым патчем для Modules/parsermodule.c, я предложил ещё один патч, который:
- Добавляет в первый парсер автоматическое «сжатие» неветвящихся поддеревьев — в момент свёртки (создания узла КСД и возврата из текущего КА в предыдущий) «однодетный» узел подходящего типа заменяется на своего ребёнка:
diff -r ffc915a55a72 Parser/parser.c --- a/Parser/parser.c Mon Sep 05 00:01:47 2016 -0400 +++ b/Parser/parser.c Mon Sep 05 08:30:19 2016 +0100 @@ -52,16 +52,16 @@ #ifdef Py_DEBUG static void s_pop(stack *s) { if (s_empty(s)) Py_FatalError("s_pop: parser stack underflow -- FATAL"); - s->s_top++; + PyNode_Compress(s->s_top++->s_parent); } #else /* !Py_DEBUG */ -#define s_pop(s) (s)->s_top++ +#define s_pop(s) PyNode_Compress((s)->s_top++->s_parent) #endif diff -r ffc915a55a72 Python/ast.c --- a/Python/ast.c Mon Sep 05 00:01:47 2016 -0400 +++ b/Python/ast.c Mon Sep 05 08:30:19 2016 +0100 @@ -5070,3 +5056,24 @@ FstringParser_Dealloc(&state); return NULL; } + +void PyNode_Compress(node* n) { + if (NCH(n) == 1) { + node* ch; + switch (TYPE(n)) { + case suite: case comp_op: case subscript: case atom_expr: + case power: case factor: case expr: case xor_expr: + case and_expr: case shift_expr: case arith_expr: case term: + case comparison: case testlist_star_expr: case testlist: + case test: case test_nocond: case or_test: case and_test: + case not_test: case stmt: case dotted_as_name: + if (STR(n) != NULL) + PyObject_FREE(STR(n)); + ch = CHILD(n, 0); + *n = *ch; + // All grandchildren are now adopted; don't need to free them, + // so no need for PyNode_Free + PyObject_FREE(ch); + } + } +} - Соответствующим образом исправляет второй парсер, исключая из него обход «бамбуковых ветвей»: например, вышеприведённая функция
ast_for_exprзаменяется на
С другой стороны, у многих узлов в результате «сжатия ветвей» дети теперь могут быть новых типов, и поэтому во многих местах кода приходится добавлять новые условия.static expr_ty ast_for_expr(struct compiling *c, const node *n) { //... switch (TYPE(n)) { case lambdef: case lambdef_nocond: return ast_for_lambdef(c, n); case test: case test_nocond: assert(NCH(n) > 1); return ast_for_ifexpr(c, n); case or_test: case and_test: assert(NCH(n) > 1); // обработка булевых операций case not_test: assert(NCH(n) > 1); // обработка not_test case comparison: assert(NCH(n) > 1); // обработка comparison case star_expr: return ast_for_starred(c, n); /* The next five cases all handle BinOps. The main body of code is the same in each case, but the switch turned inside out to reuse the code for each type of operator. */ case expr: case xor_expr: case and_expr: case shift_expr: case arith_expr: case term: assert(NCH(n) > 1); return ast_for_binop(c, n); // case yield_expr: и его обработка case factor: assert(NCH(n) > 1); return ast_for_factor(c, n); case power: return ast_for_power(c, n); case atom: return ast_for_atom(c, n); case atom_expr: return ast_for_atom_expr(c, n); default: PyErr_Format(PyExc_SystemError, "unhandled expr: %d", TYPE(n)); return NULL; } /* should never get here unless if error is set */ return NULL; } - Поскольку «сжатое КСД» уже не соответствует грамматике Python, то для проверки его корректности в
Modules/parsermodule.cвместо «сырой»_PyParser_Grammarтеперь нужно использовать автоматы, соответствующие «транзитивному замыканию» грамматики: например, для пары продукций
—добавляются следующие «транзитивные» продукции:or_test ::= and_test test ::= or_test 'if' or_test 'else' test
test ::= or_test 'if' and_test 'else' test test ::= and_test 'if' or_test 'else' test test ::= and_test 'if' and_test 'else' test
Во время инициализации модуляparser, функцияInit_ValidationGrammarобходит автосгенерированные КА в_PyParser_Grammar, на основе них создаёт «транзитивно замкнутые» КА, и сохраняет их в структуреValidationGrammar. Для проверки корректности КСД используется именноValidationGrammar.
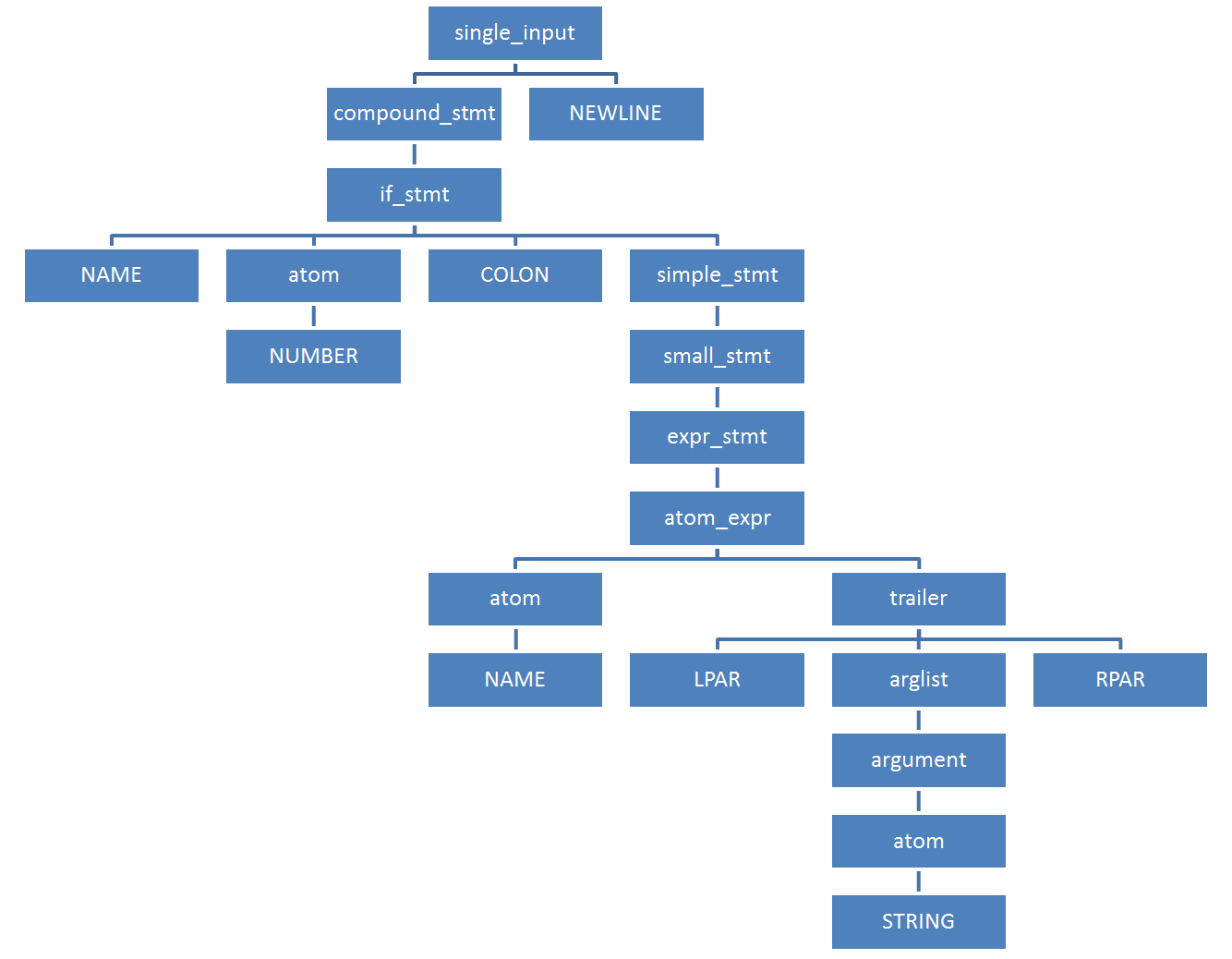
Сжатое КСД для нашего примера кода содержит всего 21 узел:
$ python
Python 3.7.0a0 (default:98c078fca8e0+, Oct 31 2016, 09:00:27)
[GCC 4.7.3] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import parser
>>> parser.suite('if 42: print("Hello world")').tolist()
[257, [295, [297, [1, 'if'], [324, [2, '42']], [11, ':'], [270, [271, [272, [323, [324, [1, 'print']], [326, [7, '('], [334, [335, [324, [3, '"Hello world"']]]], [8, ')']]]]], [4, '']]]], [4, ''], [0, '']]
>>>
 С моим патчем стандартный набор бенчмарков показывает сокращение потребления памяти процессом
С моим патчем стандартный набор бенчмарков показывает сокращение потребления памяти процессом python до 30%, при неизменившемся времени работы. На вырожденных примерах сокращение потребления памяти доходит до трёхкратного! Но увы, за полгода с тех пор, как я предложил свой патч, никто из мейнтейнеров так и не отважился его отревьюить — настолько он большой и страшный. В сентябре же мне ответил сам Гвидо ван Россум: «Раз за всё это время никто к патчу интереса не проявил, — значит, никого другого потребление памяти парсером не заботит. Значит, нет смысла тратить время мейнтейнеров на его ревью.»
Надеюсь, эта статья объясняет, почему мой большой и страшный патч на самом деле нужный и полезный; и надеюсь, после этого объяснения у Python-сообщества дойдут руки его отревьюить.
