Как развивать облачный сервис: обеспечиваем бесперебойную работу и добавляем возможности
Если использовать известное сравнение, развитие облачного сервиса — задача, похожая на замену двигателя на летящем самолете. Но альтернативы нет — ты безнадежно отстанешь, если не будешь постоянно меняться. Сервис МойСклад постоянно меняется уже 7 лет. В этом посте поговорим о том, как это происходит.
НагрузкиЕсли ваш сервис работает в B2B (то есть для компаний, а не отдельных пользователей), прогнозировать его нагрузку достаточно просто. У нее не бывает неожиданных скачков наподобие хабраэффекта. Если говорить про нашу область — торговлю — в течение года есть два хорошо известных пика: перед новогодними праздниками и 8 марта. Пики составляют несколько десятков процентов (а не несколько раз).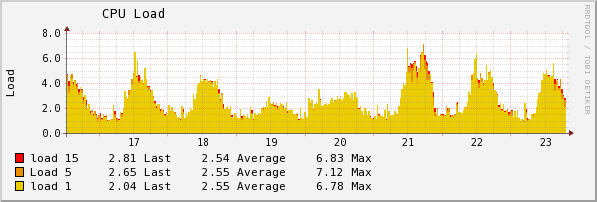
Поскольку нагрузка меняется мало (на картинке — реальный график загрузки одного из серверов), нет большой необходимости в эластичности, которую дают различные PaaS. Поэтому вместо Amazon EC2 или других облачных хостингов мы арендуем обычные физические dedicated серверы. По всей видимости, при стабильно высокой нагрузке это — оптимальное решение.
Если все идет хорошо, пользовательская база непрерывно растет. Это постоянный тренд, каждый месяц нагрузка и объем баз увеличивается на 5–10%. На практике это значит, что каждые несколько месяцев мы должны либо ставить новые серверы, либо улучшать архитектуру сервиса (либо и то, и другое вместе).
Но основная причина, по которой необходимо иметь солидный запас по нагрузке — это ошибки. Некоторые ошибки появляются на продакшн площадке вместе с обновлениями. Больше всего запомнилась экзотическая проблема, когда не особенно интенсивная печать стек трейсов в логе катастрофически тормозила приложение на сервере с процессорами AMD. (На серверах с Intel все работало отлично.)
Другие ошибки терпеливо дожидаются своего шанса. На практике больше всего проблем нам доставили экзотические шаблоны, которые зацикливали код печати документов. Поэтому мы определили минимальный запас по производительности для всех серверов и компонентов — в 2–3 раза. В большинстве случаев он позволяет пользователям нормально работать, даже если внутри возникли какие-то проблемы.
На мой взгляд, нет необходимости сразу готовить архитектуру на супервысокие нагрузки. В мире B2B ничего не происходит мгновенно, и при плавном росте есть время постепенно адаптировать архитектуру под растущую нагрузку.
МойСклад запустился в виде одного монолитного Java EE приложения и одной базы данных. Через несколько лет после запуска единственный сервер БД перестал справляться с нагрузкой. Мы сказали «ок» и разделили базу на несколько физических серверов. Через некоторое время к пределу нагрузки подошло само приложение. Мы сказали «ок» и вынесли на отдельный сервер длительные и тяжелые задачи — импорт и экспорт данных, API. Еще через некоторое время мы разнесли на несколько серверов уже основное приложение.
Не надо тратить слишком много времени на то, чтобы подготовиться к будущим сверхвысоким нагрузкам. Скорее всего, потом все равно все придется переделывать.
Технологии Развитию архитектуры больше всего помогают или мешают технологии. Правильные технологии делают жизнь простой и приятной. Неправильные приносят боль и страдание.Приведу пример. Для объединения нескольких JVM в кластер мы использовали встроенный в JBoss распределенный кеш Infinispan. До какого-то момента все шло хорошо, но затем (возможно, из-за увеличения нагрузки) начались регулярные сбои. Проблема заключалась в том, что примерно раз в неделю Infinispan терял связь между отдельными Java-машинами.
В Infinispan есть огромное количество настроек, а в интернете — советов, как подкрутить эти настройки, чтобы решить такие же или сходные проблемы. Мы потратили несколько месяцев на то, чтобы перепробовать разумные варианты. Кеш продолжал регулярно отваливаться.
Решение проблемы оказалось простым. За одну неделю мы перенесли реализацию кеша с Infinispan на Hazelcast. Эта реализация заработала сразу.
Если технология не работает, лучше всего заменить ее как можно раньше.
Релизы Важная задача развития продукта — поддерживать его сбалансированым. Что это значит? Как у любого достаточно зрелого продукта, у МоегоСклада есть здоровенный беклог вещей, которые уже давно надо было бы сделать. Настолько объемный, что работать с ним достаточно сложно. В очередной релиз можно надергать новых фич более или менее случайным образом, но насколько это оптимальный подход?
Серьезно уменьшить хаос помогает понимание, что все фичи четко делятся на три группы.
1) Платформенные фичи. Внешне они ничего не дают пользователям, а часто мешают, потому что их выпуск потенциально связан с самыми суровыми глюками и тормозами. Тем не менее, если постоянно не реализовывать улучшения платформы, достаточно скоро продукт зашатается на тонких ножках и грузно обвалится под постоянно растущей нагрузкой.
2) Переработки функциональности. Не дают новых возможностей, но приводят в порядок то, что было сделано криво. Переработки вызывают массовое страдание у пользователей, которые привыкли работать по-старому. Делать их все-таки нужно, поскольку без них продукт быстро станет безнадежно запутанным и доступным для освоения только для избранных — гиков.
3) Действительно новые фичи. Да, less is more, minimum viable product рулит, пользователи покупают решение своих задач, а не набор фичи так далее. Но в конечном итоге конкретный продукт выбирают именно из-за набора возможностей, которые более или менее точно соответствуют задачам пользователя. Новые фичи должны появляться непрерывно.
Эти три группы фич уже проще балансировать. Нужно просто организовать разработку в три параллельных потока. Каким образом их лучше группировать в релизы?
Главный совет из нашего опыта — никогда не объединять в одном обновлении новые фичи и платформенные изменения. Такие объединенные релизы получаются слишком сложными, их сложно готовить и сложно тестировать. Поэтому мы делим релизы на платформенные и функциональные.
Особенность платформенных релизов — под большой нагрузкой, на реальных данных пользователей, что-то может пойти не так. Поэтому мы делаем их откатываемыми. Если возникают проблемы, за несколько минут возвращается старая версия и команда разработки начинает готовить вторую попытку.
Функциональные релизы сложнее делать откатываемыми. Как правило, они требуют изменений в схеме БД и конверсий данных, поэтому вернуть старую версию так просто уже не получится. Но в этом нет необходимости — функциональный релиз проще качественно протестировать.
Небольшой лайфхак: массивные обновления лучше выкатывать на выходных. В субботу и особенно воскресенье в сервисе работает в несколько раз меньше пользователей.
Итоги Мы показали свои подходы и методики непрерывного развития успешно работающего облачного сервиса. Еще раз повторю три важных правила работы в условиях постоянных обновлений:1. Главная причина, по которой необходимо иметь солидный запас ресурсов при нагрузке — это возможные ошибки разработки, а не гипотетический будущий рост числа пользователей. Не стоит тратить время на то, чтобы проактивно готовиться к будущим сверхвысоким нагрузкам.2. Нет смысла слишком долго пытаться заставить работать внешние библиотеки и компоненты: если технология не работает, лучше всего заменить ее как можно раньше.3. Если вы уже всё сделали и готовы к обновлениям, никогда не объединяйте в одном релизе новые фичи и платформенные изменения.
