Как померить Node.js-приложение, если у тебя лапки. Доклад Яндекса
Что нужно, чтобы заглянуть в этот чёрный ящик? Ответ — опенсорс, все бесплатно, бери и внедряй.
— Всем привет. Немножко про то, кто я такой. Меня зовут Лёша, я разрабатываю внутренние сервисы Яндекса. Уже третий год делаю всякие Node.js-приложения, менторю разработчиков в Яндекс.Практикуме и измеряю все, до чего дотягиваются руки, потому что это весело.
Мы сегодня поговорим о том, зачем нам нужно мерить наше приложение, что мы можем померить, чем именно мы можем измерить наше приложение и куда смотреть во всех этих странных методах.
Зачем мерить?
Кажется, что это банальный вопрос. Если другой разработчик, который делает систему на Node.js, спросит: «Зачем мне мерить свое приложение?» — то вы ответите: это же логично!
Это необходимо, чтобы спасти свой сервис от падения. Если вы его уже спасли от падения, то можно спасти свой сервис от проблем, которые потом приведут к падению. 
Но если без сарказма и серьезно, то есть несколько причин, зачем это стоит делать. 
В первую очередь — чтобы успеть добавить мощности, потому что все наши приложения работают на реальном железе.
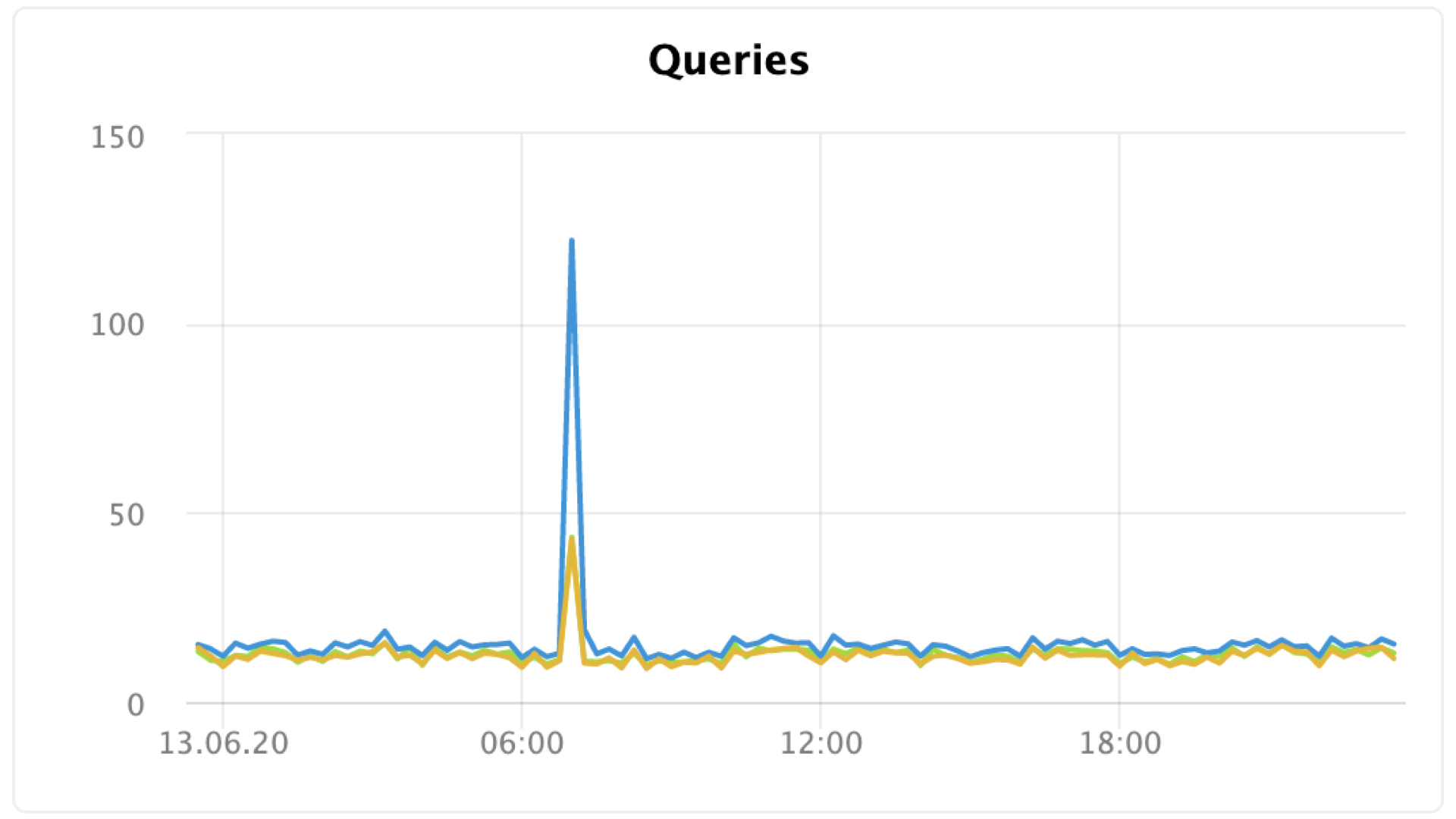
Например, вы, всё померив, видите на графиках странный всплеск и смотрите в этом моменте, что произошло с вашим приложением. Возможно, именно сейчас нужно добавить железо к базе или что-нибудь подобное.
Вторая причина мерить приложения: это способ найти узкие места сервиса. Всем известно, что когда какие-то проблемы могут не происходить на ваших машинах, на тестовых стендах, даже на препродакшене. А как только вы выкатили его в продакшен — все, туши свет.
Например, в предыдущем моем проекте был такой график, который показывал по каждому куску каждого endpoint внутри приложения, насколько медленно он работает.
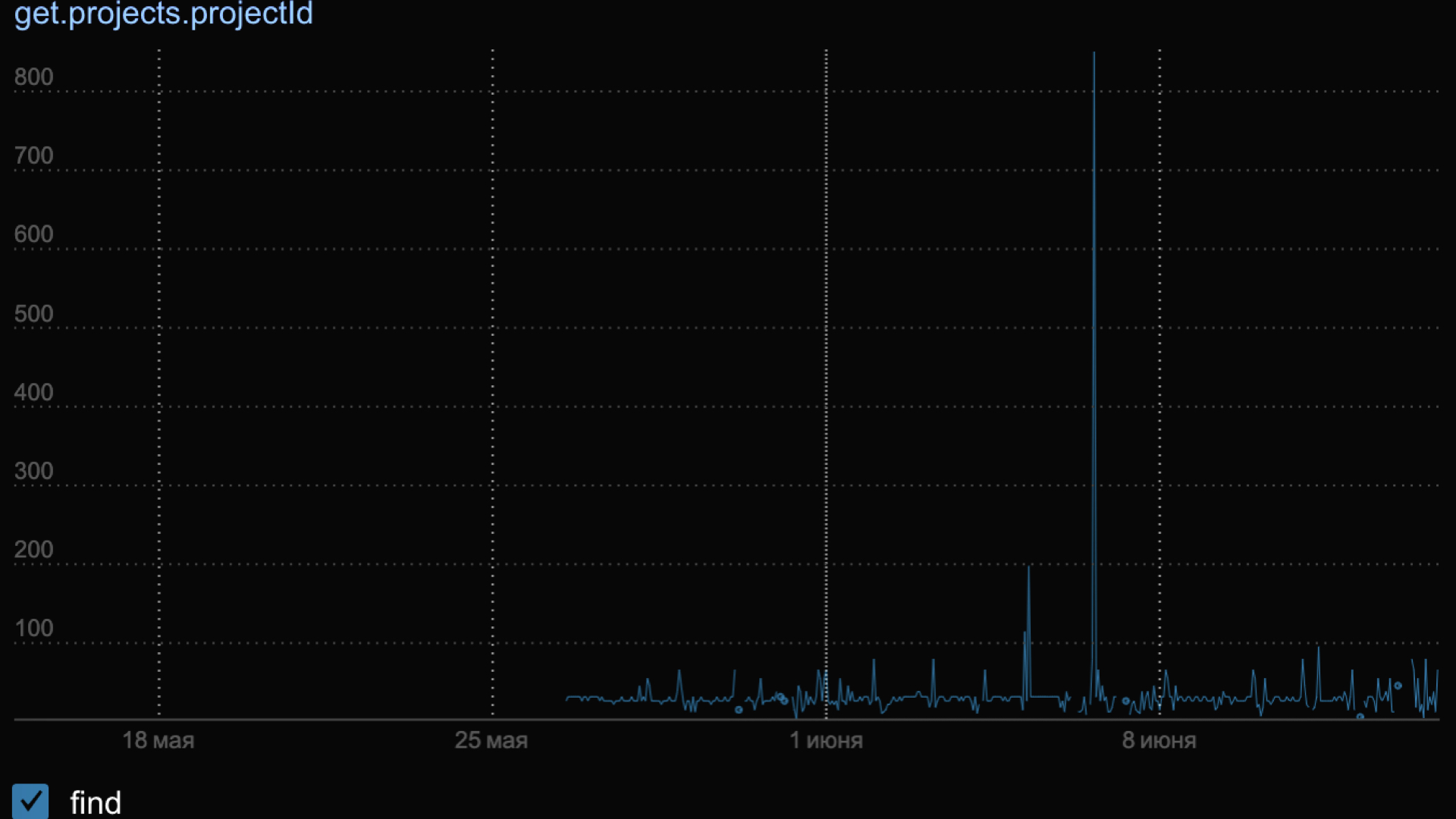
Когда мы видели такой странный всплеск, то шли и смотрели, что произошло. Перед всплеском, который был примерно 7 июня, к нам просто пришел робот и немножко заDDoSил наш сервис. Поэтому база перегрузилась и запросы отрабатывали дольше, чем обычно.
Третья причина — это метрики как быстрый способ дебага проблем. Когда вы смотрите на хорошие, правильно составленные метрики, то примерно представляете, как работают все части вашего приложения. Можете определить, куда пойти, где воткнуть debugger, куда подключиться профайлерам, чтобы подробнее выяснить, что в приложении пошло не так, вместо того, чтобы сидеть и штырить в странные логи, которые могут выглядеть примерно вот так.

Даже ссылка есть. Правда, заходишь по ссылке, а там написано, что, наверное, у вас что-то с сетью, идите, дебажьте по логам. Получается замкнутый круг.
И четвертый пункт — почему стоит мерить ваши приложения. Для того чтобы узнать о проблемах в вашем релизе, в вашем коде, раньше ваших пользователей. Здесь речь идет о большинстве ваших пользователей: вы выкатили релиз и внимательно смотрите на метрики минут десять, чтобы увидеть аномалии.
Например, уменьшилась скорость запросов в базу. У вас есть красная кнопка «Откатить релиз», чтобы это не задело пользователей. Лучше если это произойдет в течение пяти-десяти минут после выкатки релиза, чем если к вам в саппорт прибегут пользователи, особенно во внутренних сервисах, и скажут: «А, вы снова чего-то выкатили! Все нам поломали! Перестаньте так делать, уже устали так работать!»
Примерно понятно, зачем нам это делать.
Что мерить?
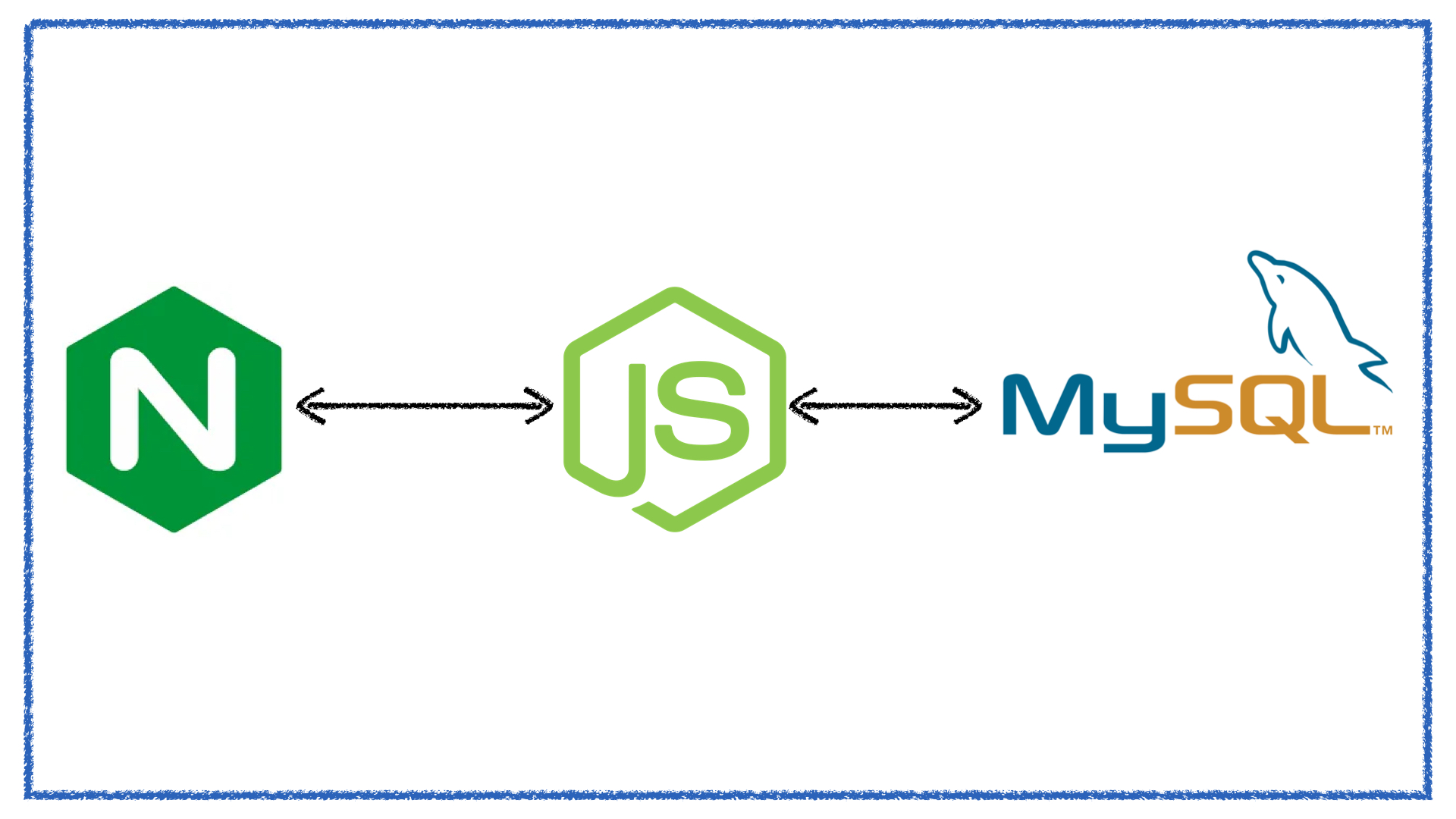
Типичные приложения, с которыми я сталкивался, выглядят примерно так.
У нас есть Node. К ней приходят запросы от балансера, и она работает с базой. Иногда этих баз может быть несколько, ничего нового. И все это работает в контейнере. У нас это были Docker-контейнеры, в вашем случае это может быть любой другой способ виртуализации или даже обычные железные машины. С этим я тоже сталкивался.
Сначала поговорим о том, что можно измерить в самом контейнере.
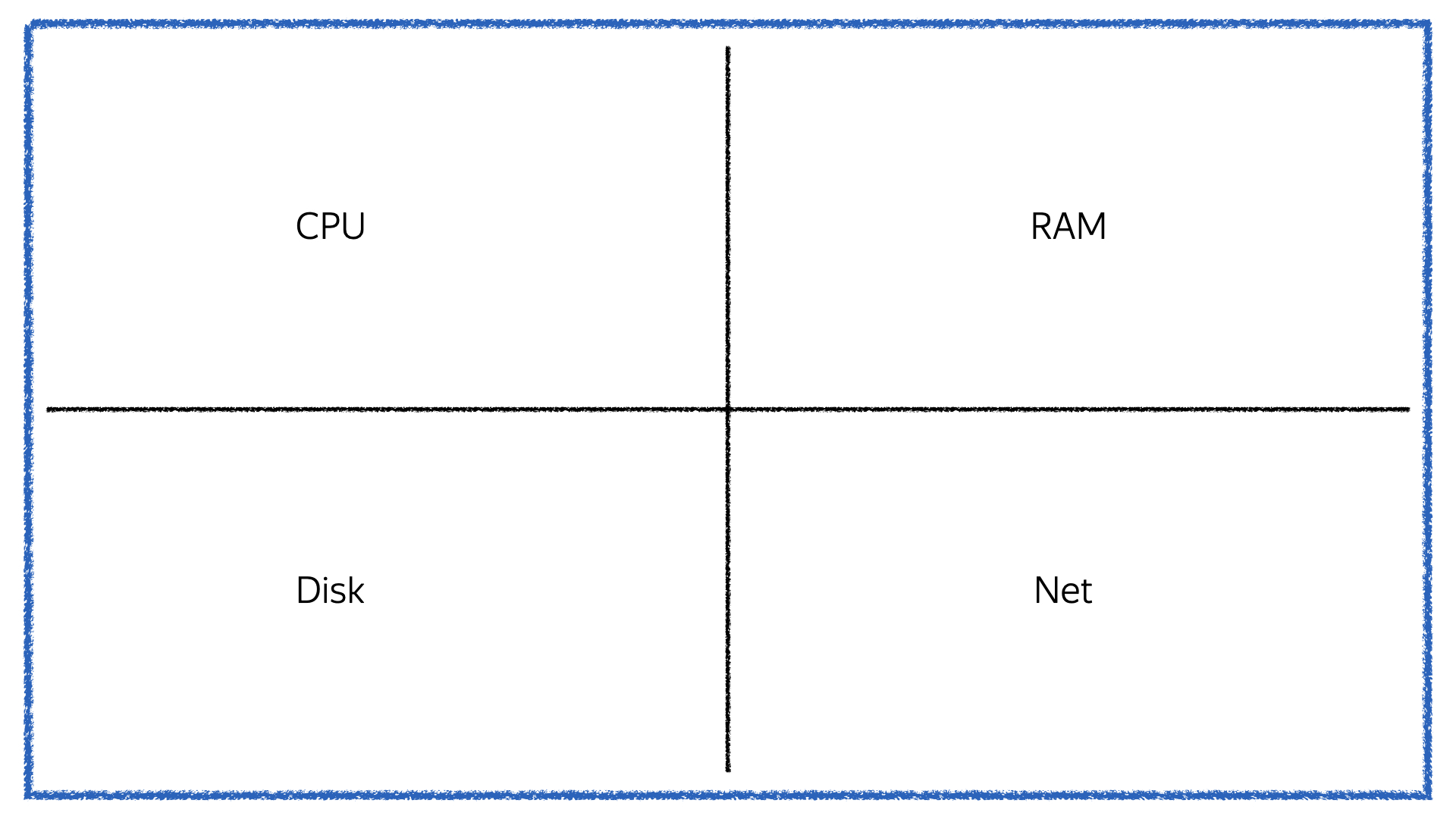
Здесь стоит обратить внимание на четыре основные метрики. Первые три из них все всегда помнят, а про четвертую почему-то забывают.
Первая — это процессор. Вторая — оперативная память. Третья — постоянная память, место на диске. Четвертая — сеть. Про три первые вы чаще всего помните, потому что вы за них платите вашему провайдеру — или у вас есть свои железные машины и вы заняты тем, чтобы доставать новое железо. А вот про сеть часто забывают, потому что она не тарифицируется.
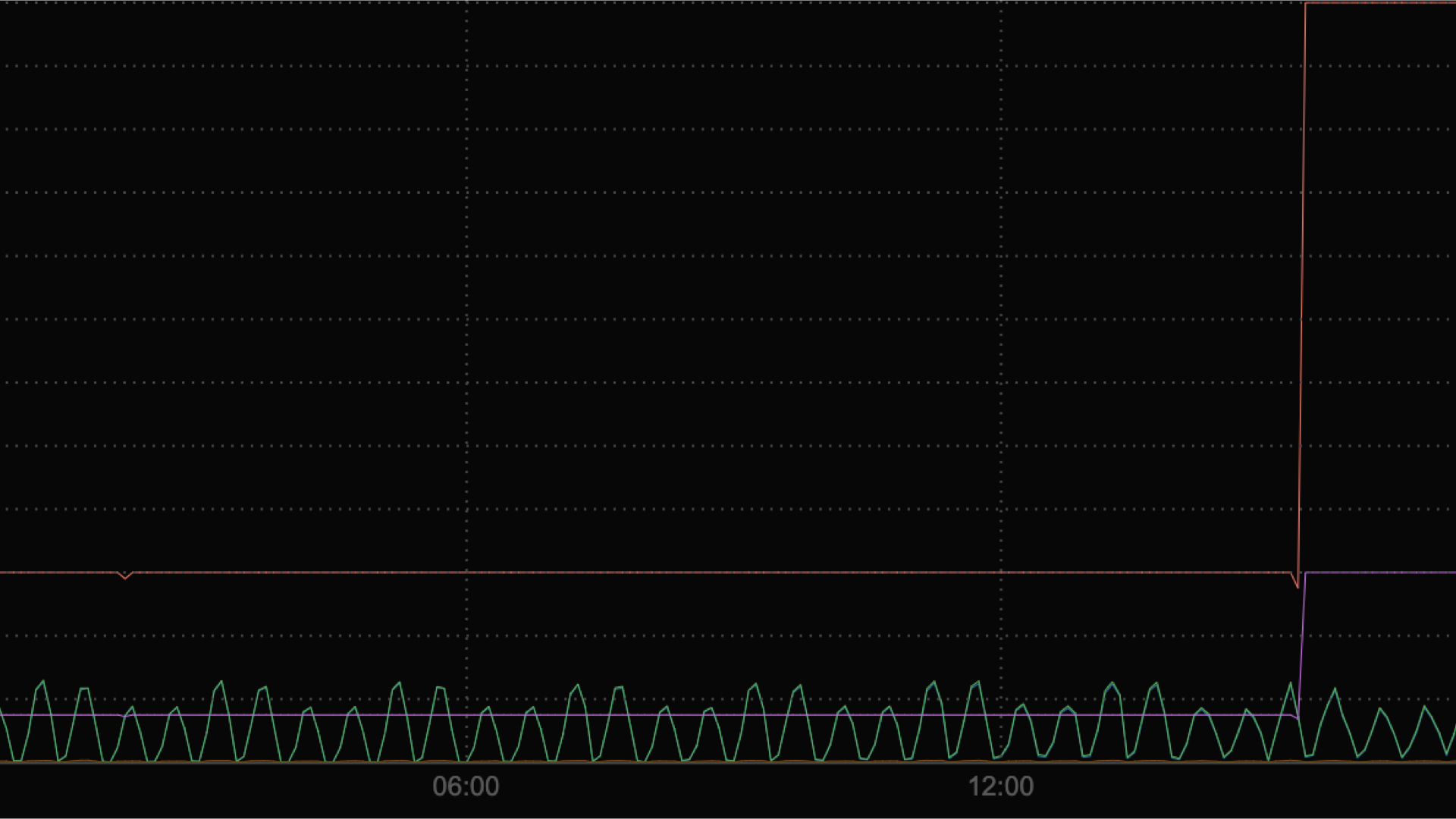
Но при этом бывают странные ситуации. Например, когда мы только втащили в наш последний проект метрику сети, то увидели вот такую штуку.
Зеленый график — это реальное потребление сети, то, сколько мы отправляем трафика и сколько принимаем. Фиолетовый — то, сколько сети нам может гарантировать наше железо. Очень часто зеленый график пересекает розово-фиолетовый, и мы выходим за границы.
Почему же мы не видели проблем в логах или где-то еще? Потому что у нас есть прекрасный красный график, который показывает максимальную границу нашего приложения. Если бы мы в нее уперлись, то в логах появились бы проблемы с сетью.
Когда мы все это увеличили, то начали жить-поживать и не знать никаких проблем.
Перейдем к нашей схеме. Что здесь можно померить, когда снаружи мы уже все померили? Между балансером и нашим Node.js-приложением стоит обратить внимание на две достаточно базовые метрики, которые очень удобно снимать с балансера: RPS, количество запросов в секунду, и время ответа. То есть вам не нужно делать это изнутри приложения. Очень удобно получать информацию об этом, например, из какого-нибудь базового модуля Nginx.

С базой тоже достаточно простая метрика — скорость запросов в базу, то, насколько быстро ваши запросы отрабатываются. Опять же, ее удобнее снимать с базы, плюс профилировщик в базе может показать вам доли в долгих запросах, сложные запросы, где не хватает индексов или чего-то подобного. 
Переходя к тому, о чем мы сегодня говорим, к Node, есть четыре базовые метрики, на которые стоит обращать внимание.
Первая — это скорость работы event loop, время от того момента, как функция поместилась в event loop, до того, как она разрезолвилась. Время работы garbage collection, то, насколько часто он приходит и насколько долго отрабатывает. Возможно, у вас есть проблемы с памятью, и именно эта метрика поможет их найти.
Время работы с внешними системами, потому что все приложения, которые я разрабатывал, ходили во внешние системы, и это был кусок кода, где от вас практически ничего не зависит. Ваше дело — сделать запрос и ждать, пока он случится. Здесь в плане ускорения вам могут помочь только различные хаки, но при этом померить явно стоит, чтобы, например, подумать: возможно, стоит сменить конкретно этот кусок системы на какую-нибудь другую.
И ваша бизнес-логика, тот код, который вы пишете. Потому что если не мерить его, то смысла затаскивать метрики в Node вообще не очень много.
Чем мерить?
Какие инструменты есть в открытом доступе, что прямо сейчас можно попробовать?
В первую очередь предлагают померить скорость работы нашего приложения базово.

Мы запускаем наше приложение и начинаем обстреливать его в течение десяти секунд через 150 соединений. Смотрим, насколько производительно оно работает.
Я выбрал для этого достаточно простой endpoint, то есть не нужно было создавать полное мок-окружение, но при этом достаточно сложный, который внутри производит много операций перекладывания джейсончиков, маппинга данных. То есть это не простой Hello World.
И мы видим, что на моей машине в среднем это 1000 запросов за десять секунд, два мегабайта данных. Можно посмотреть базовые данные по запросам. Но видим, что, например, в среднем это одна секунда на запрос.
Перейдем к инструментам.
Первый инструмент — App Metrics. Важно: есть две версии App Metrics. Первая, которую вы найдете, если пойдете искать в интернетах, — это модуль для C#. Он нам по понятным причинам не подходит.
Но есть его альтернатива — node-app-metrics, которая хостится на базе IBM, и ее достаточно просто подключить. Поэтому если вдруг пойдете искать, ищите node-app-metrics.
Что это такое и как этим пользоваться? Это самая простая система, которая может вам помочь, если вы прямо сейчас хотите на пару-тройку ваших серверов раскатить хоть какие-то метрики, чтобы понять, что происходит внутри вашего приложения.

Потому что App Metrics работает через две команды. Вы устанавливаете и запускаете ваши приложения. Все остальные штуки по поводу запуска, дополнительного worker или child-процесса, по поводу сбора метрик и вывода на дашборд для вас сделает пакет App Metrics-dash.

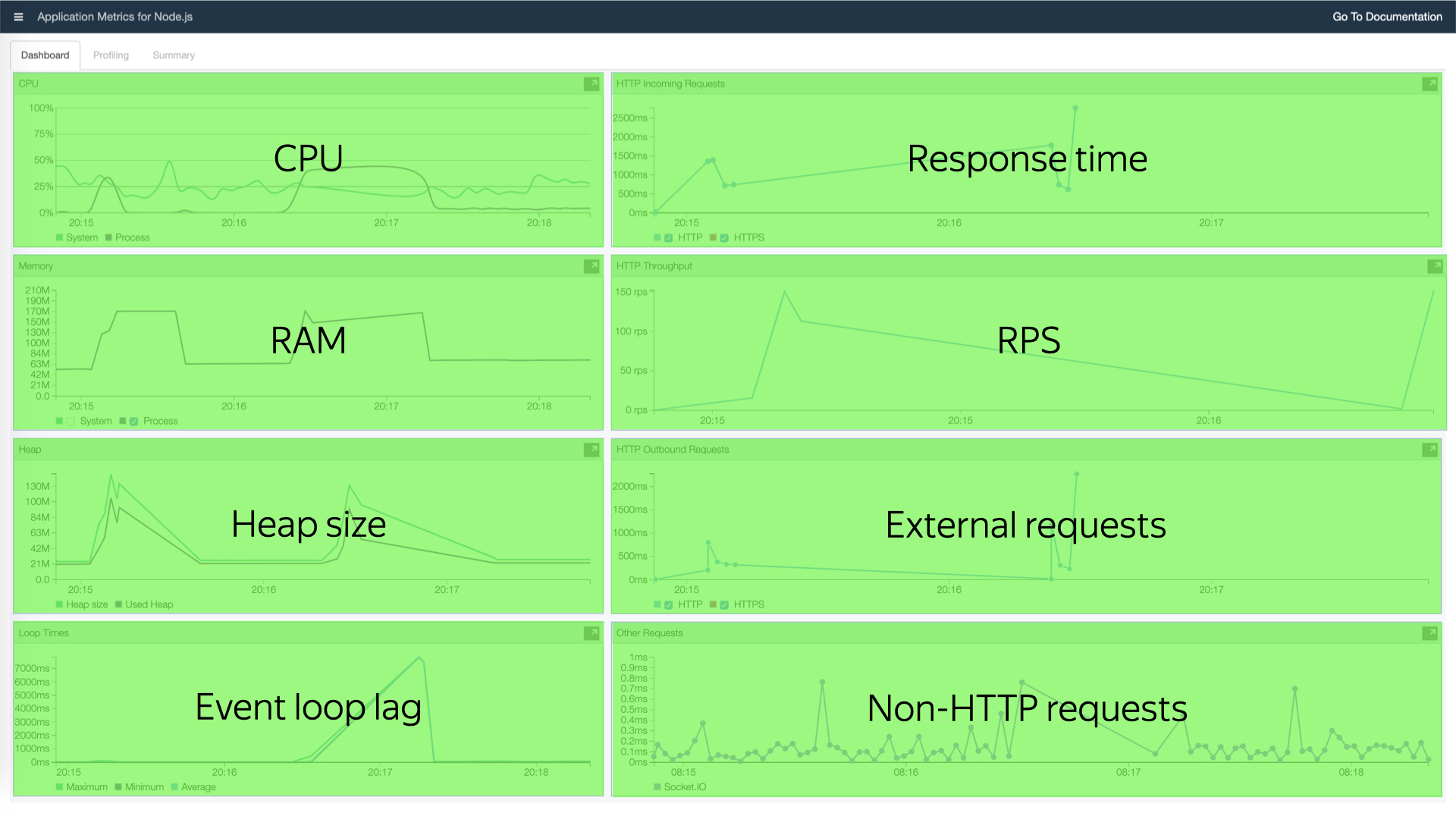
Что мы получим, если выполним эти две команды? Вот такой дашбордик, на котором куча мелких циферок. Но если обобщать, что мы тут увидим? Увидим все метрики, которые нам нужны: CPU, потребление памяти, размер кучи, скорость работы event loop, время ответа ваших ручек, RPS, время работы внешних запросов и non-HTTP-запросов. В нашем случае это запросы через socket.io, сообщения, которые летают туда-сюда для работы этого дашборда.
Плюс у нас есть еще пара вкладочек, которые могут показать нам Flame Graph работы приложения. Он достаточно неудобный, чтобы на нем что-то выяснять, но при этом зачем-то тут присутствует.
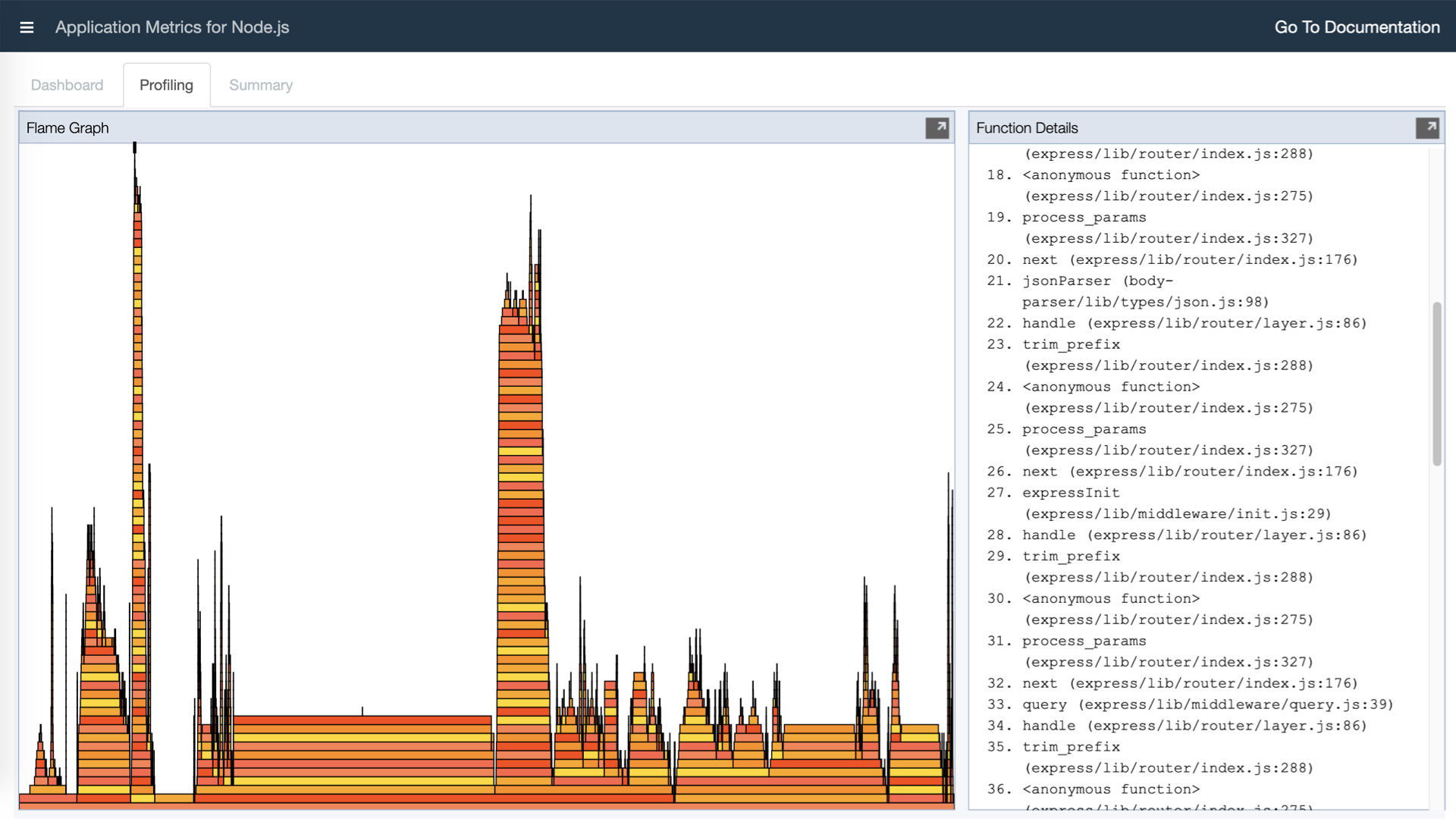
И какое-то саммари с описанием нашего окружения, пришедших запросов и дополнительные опции, которые присутствуют в App Metrics.

Есть снятие heap dump, позволяющее рассмотреть его в вашем любимом профилировщике. Создание Node Report, включение/выключение profiling, которое начинает или приостанавливает снятие Flame Graph из вашего приложения, и очистка profiling-данных. Достаточно логично.
Посмотрим, насколько это решение производительно или не производительно, то есть сможем ли мы его прямо сейчас затащить на наши сервера.
Если мы просто подключим App Metrics и не будем запускать профилирование, не будем снимать Flame Graph, то скажу заранее: это достаточно производительное решение. Оно немного снизит скорость работы нашего приложения. Мы получим те же самые 1000 запросов за десять секунд.

Увидим, что на 20% выросло среднее время работы одного запроса. Но при этом особо большого влияния мы не получили именно из-за того, что App Metrics построен таким образом, чтобы не сильно влиять на ваше продакшен-приложение.
Если же мы включим профилирование, то здесь все будет плохо.

Посмотрим, насколько плохо. Но запускать профилирование в production я категорически не рекомендую. Здесь мы получим двукратную просадку по производительности в плане количества ответов за десять секунд, и время ответа на один запрос вырастет в полтора раза.
Когда же использовать App Metrics? Зачем его подключать? Зачем существует такой инструмент? Я считаю, это очень хороший инструмент для старта.
Если бы мне, когда я разрабатывал свое первое Node.js-приложение, сказали: смотри, есть App Metrics, две команды и ты получишь хорошие данные и сможешь следить за своим приложением, — то я бы этой классной штукой обязательно воспользовался. 
За счет того, что вам не нужно поднимать дополнительные окружения, App Metrics работает как часть вашего приложения, хорошо подходит для того, чтобы валидировать изменения внутри него. Например, вы где-то заоптимизировали, где-то получили утечку памяти. Быстро запустили на своей же машине, не раскатывая ни на какие стенды, обстреляли, увидели, что все хорошо. Значит, можно катить в продакшен.
Давайте сделаем такую табличку, в которой будем оценивать инструменты по трем критериям. Первый — простота настройки и установки. Второй — мощь и сила, то, насколько инструмент может помочь в вашем приложении и померить все. Третье — его влияние на скорость работы приложения в продакшене.
Если оценивать App Metrics, то в плане простоты это пять из пяти: две команды, и вы получили метрики. В плане его возможностей это только три из пяти. Почему? Если вы хотите померить стандартные метрики, то две команды и поехали. Если вы хотите померить отдельные куски вашего приложения, то здесь не все так просто. Готовых модулей под это нет, вам нужно брать чистый App Metrics и отправлять метрики с его помощью, а потом использовать App Metrics-IDE, у которой не очень много документации, чтобы эти метрики просматривать. Решение, по моему мнению, так себе, поэтому, только три из пяти. 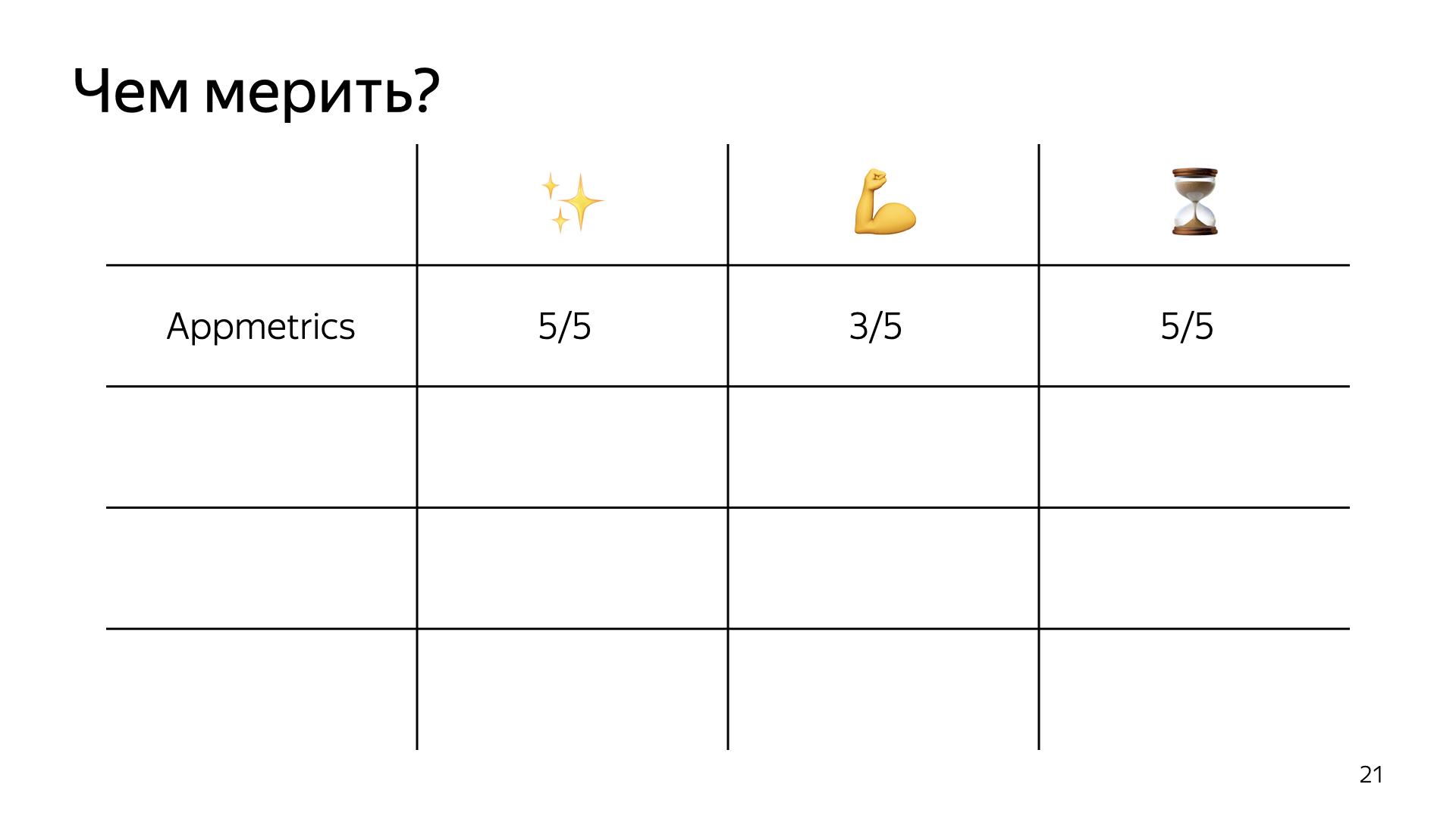
Влияние на скорость — конечно, пять из пяти, можно катить в прод, особенно если у вас небольшое и сильно нагруженное приложение и вы хотите получить метрики прямо сейчас.
Дальше мы поговорим про золотой треугольник. Потому что в документации к настройке этой системы один разработчик написал, что это прямо «golden triangle of system monitoring».
И это действительно очень классная штука. Если среди вас есть прожженные бэкендеры, которые не только пишут на Node, а еще и любят всякие другие языки и продакшен больших размеров, то вы наверняка про эту систему знаете.

Эта система состоит из трех кусков. Первый — Prometheus, система для сбора метрик. Второй — Grafana, система для отображения метрик. И PUSH gateway. У него нет логотипчика, поэтому пусть будет такой. Это система для того, чтобы довозить ваши метрики от любой вашей системы до Prometheus.
Разберем, как эта странная штука работает. У вас есть Node, и вы можете настроить работу этого золотого треугольника двумя способами. Первый — как треугольник. Вы отправляете в PUSH gateway свои метрики: собственно, пушите. Для этого вы запускаете какой-нибудь клиент: например, есть официальный prom-client от разработчика Prometheus для Node.js, который устанавливается как пакет и начинает сливать ваши метрики. 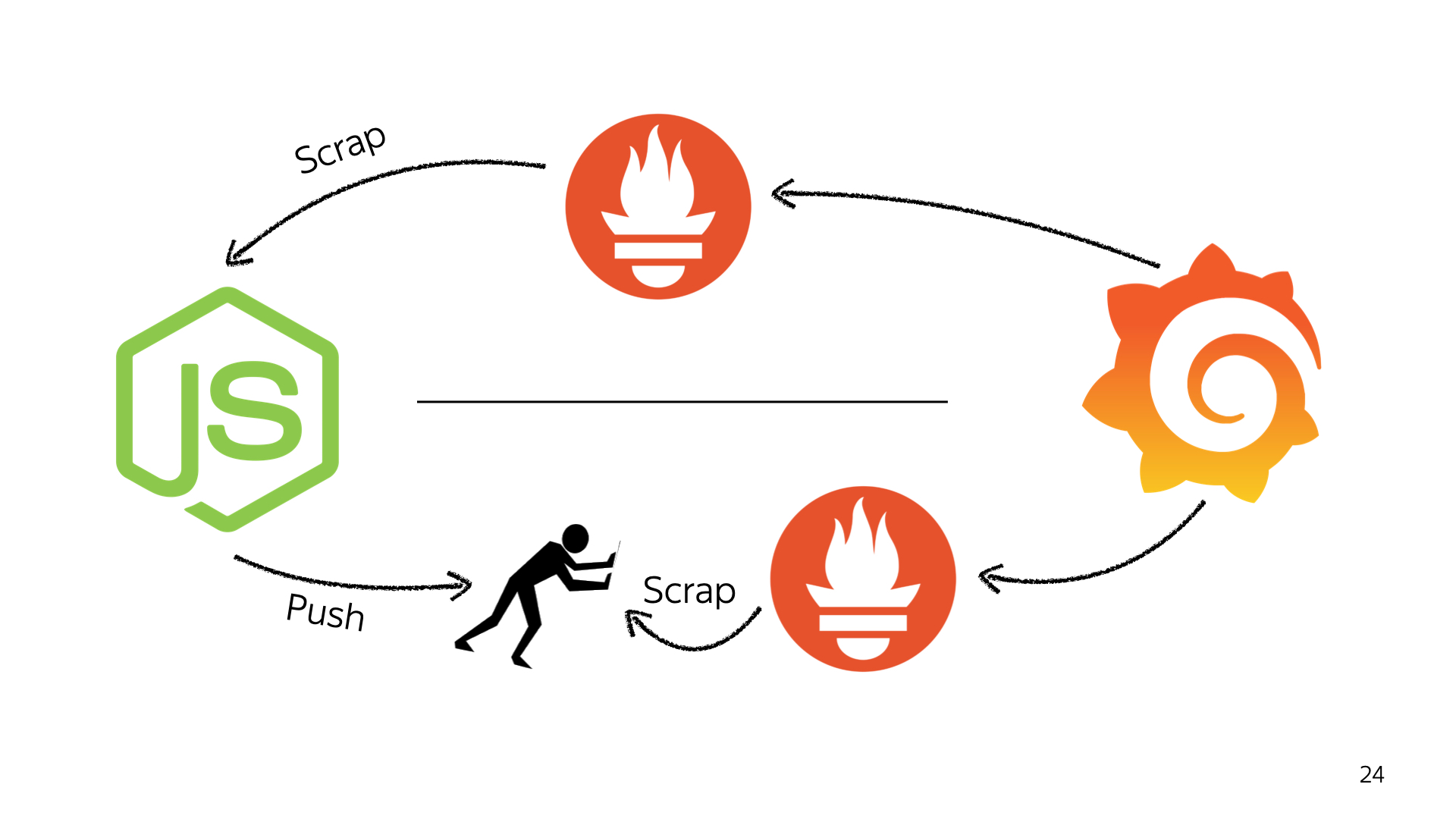
Потом настраиваете Prometheus на сбор данных с PUSH gateway, потому что в основе Prometheus лежит именно логика сбора данных по источникам. То есть вы не пушите свои метрики, а подготавливаете их у себя, имея endpoint, который будет их отдавать в Prometheus в нужном формате. И натравливаете Grafana на Prometheus, говорите — здесь лежат мои метрики, давай будем рисовать красивый графичек.
Есть второй способ настройки — без PUSH gateway. Он займет немного больше времени, потому что внутри Node вам нужно настроить те самые endpoint, которые будут подавать ваши метрики. А Grafana вы точно так же настраиваете на Prometheus, и она отдает те же данные. Можно переключаться между этими схемами, со стороны Grafana это достаточно легко.
Когда эта система может пригодиться? Кажется, что для одного Node.js это достаточно сложный механизм, чтобы разворачивать на отдельных машинах Prometheus для сбора метрик, а сверху поднимать Grafana для отображения.

Но если помимо Node у вас есть база, балансер, еще одна база, кэш, парни, которые пишут кровавый энтерпрайз, и парни с хомяком под мышкой, то развертывание такой системы принесет пользу всем им и поможет собирать метрики со всех них.
Потому что вы заходите на официальный сайт Prometheus и видите там неофициальные клиентские библиотечки почти для всего. Это первый шаг, который вам нужно сделать, чтобы замониторить какую-нибудь систему.
Взяв эту библиотечку и настроив ее для работы в вашей системе, вы идете в поисковик и вбиваете: Grafana — название вашей системы — дашборд.
И, скорее всего, попадаете на официальный сайт Grafana, где так же, как в Docker Hub, лежат выложенные образы систем. Также на сайте Grafana лежат дашбордики для официальных клиентов.

Например, здесь прямо в Quick Start описывается установка prom-client и его настройка.
Нас здесь интересует, собственно, ID дашбордика, который вы просто можете указать в Grafana. Она сама его скачает и даст вам все графички.
Насколько производительно это решение? Здесь все зависит от того, как вы будете обустраивать вашу схему сбора метрик. Потому что если вы просто возьмете prom-client, подключите его, настроите, то получите где-то десятипроцентную просадку по количеству запросов и плюс 40% ко времени обработки одного запроса.

Здесь стоит учитывать, что prom-client автоматически запускается в том же треке, что и приложение. Поэтому он кушает ресурсы приложения. Приложение работает медленнее, и prom-client тоже грустно. Выносим его в отдельный тред, получаем примерную производительность предыдущей системы.
Что мы получим за такие достаточно тяжелые просадки производительности?

Мы получим такой красивый дашбордик, который по умолчанию уже настроен под наши требования, под все метрики, которые мы собираем. И отображает примерно все, что нам нужно: все данные, которые у нас были в App Metrics. Важное условие: мы можем настроить любые другие графики прямо из этой системы.
Когда стоит использовать такую сложную связку? Ее объективно сложнее поднять и настроить по сравнению с App Metrics.
Первый случай — когда вы понимаете, что и как вы будете мерить. Потому что App Metrics хорош, когда вы взяли систему, обмазали ее метриками и что-то смотрите. Оно работает — окей, уже хорошо. Процессор не сильно загружен, значит код мы в целом умеем писать и так далее.
Если вы понимаете, что вам нужно померить этот кусок, этот большой кусок и еще вот тут время работы, то, конечно, стоит использовать что-то посложнее.
У вас обязательно должны быть ресурсы, причем как железные, так и человеческие, чтобы поднимать это решение и поддерживать. Это не штука, которая запустилась внутри вашего приложения и работает, не пакетик из NPM. Это цельная система, которая умеет падать, глючить, иногда ее надо настраивать. 
Когда ваш продакшен жив не одним Node.js, а есть много систем, с которых нужно собрать метрики, и еще желательно иметь единый дашбордик для всех систем, видеть проблемы прямо сразу, то, конечно, это лучший выбор.
Добавим Prometheus в нашу табличку. В плане простоты настройки это два из пяти — просто потому, что вам нужно настроить не только работу самого пакета и отправки метрик, а еще и всю систему, если у вас ее нет.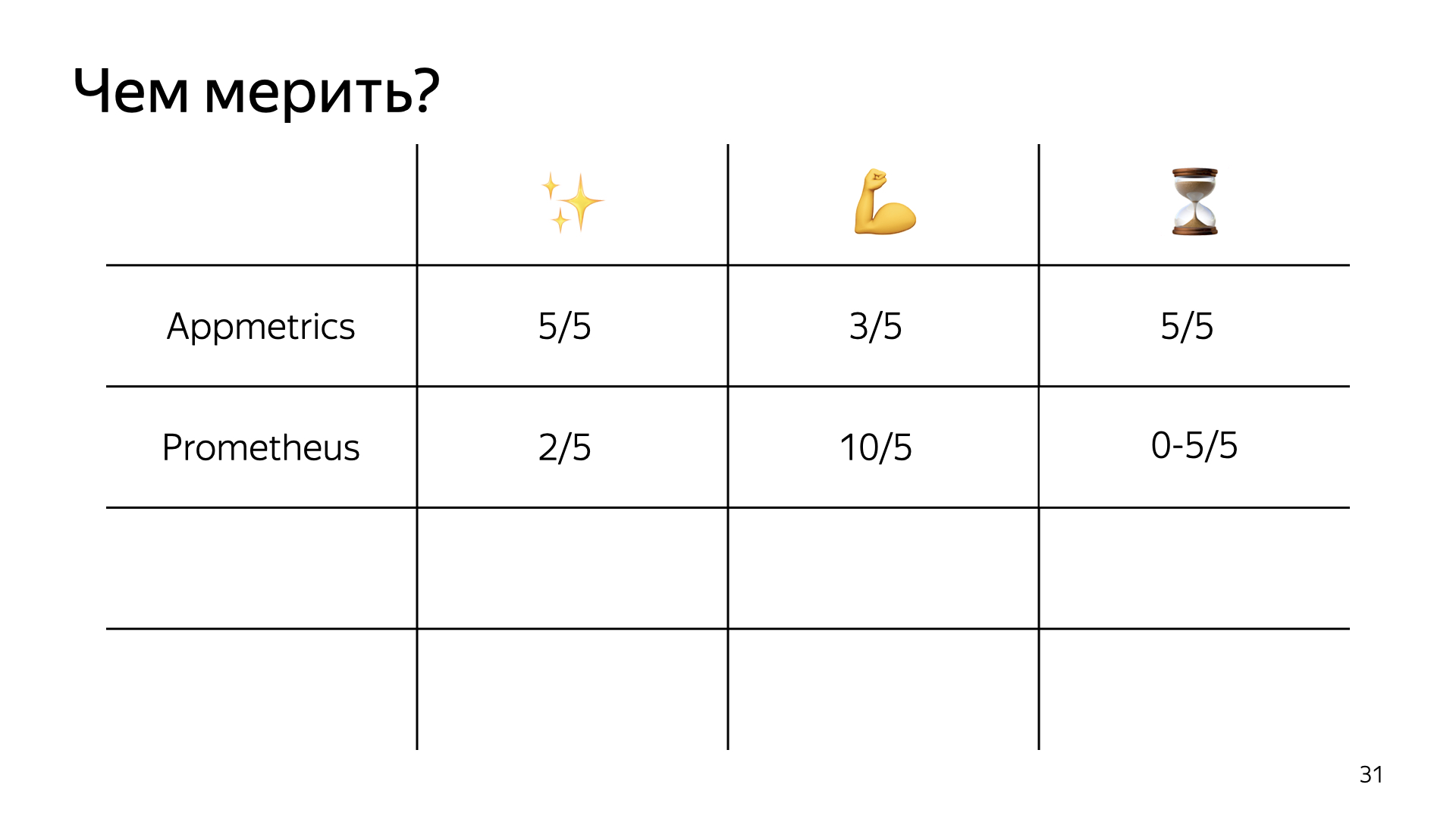
По поводу возможностей это абсолютный фаворит, потому что Prometheus позволяет вам померить абсолютно все, а Grafana позволяет отобразить это так, как вам нужно, любыми способами, которые вы только можете себе представить. Если вдруг вы упарываетесь по статистике, то Grafana вам, скорее всего, знакома.
Что касается скорости работы, все зависит от того, как вы реализуете отправку метрик. Если брать prom-client в чистом виде и встраивать его в main thread приложения — это, конечно, ноль из пяти. Просадку в десять процентов запросов достаточно легко ощутить. Если же вы все сделаете сами и аккуратненько, то пять баллов из пяти вполне достижимы.
Дальше мы поговорим про чуть более глубокое измерение приложения. Возможно, кому-то из вас знаком этот логотип. Он представляет собой объединение трех систем.

Это Clinic.js Doctor, Clinic.js Flame и Clinic.js Bubbleprof. Тройка инструментов, еще один треугольник. Если тот был золотым, то этот, по-моему, должен быть платиновым, потому что перед вами инструменты, которые позволяют очень глубоко залезть в ваши приложения и померить глубокие штуки просто из коробки.
Посмотрим, как это работает. Все достаточно просто, примерно как с первой системой, только вторая команда получилось сложная. Мы устанавливаем сам Clinic.js и говорим — для начала запусти сам Doctor. Попутно мы запускаем обстрел нашего приложения все той же командой в отдельном окне консоли и стартуем наше приложение. 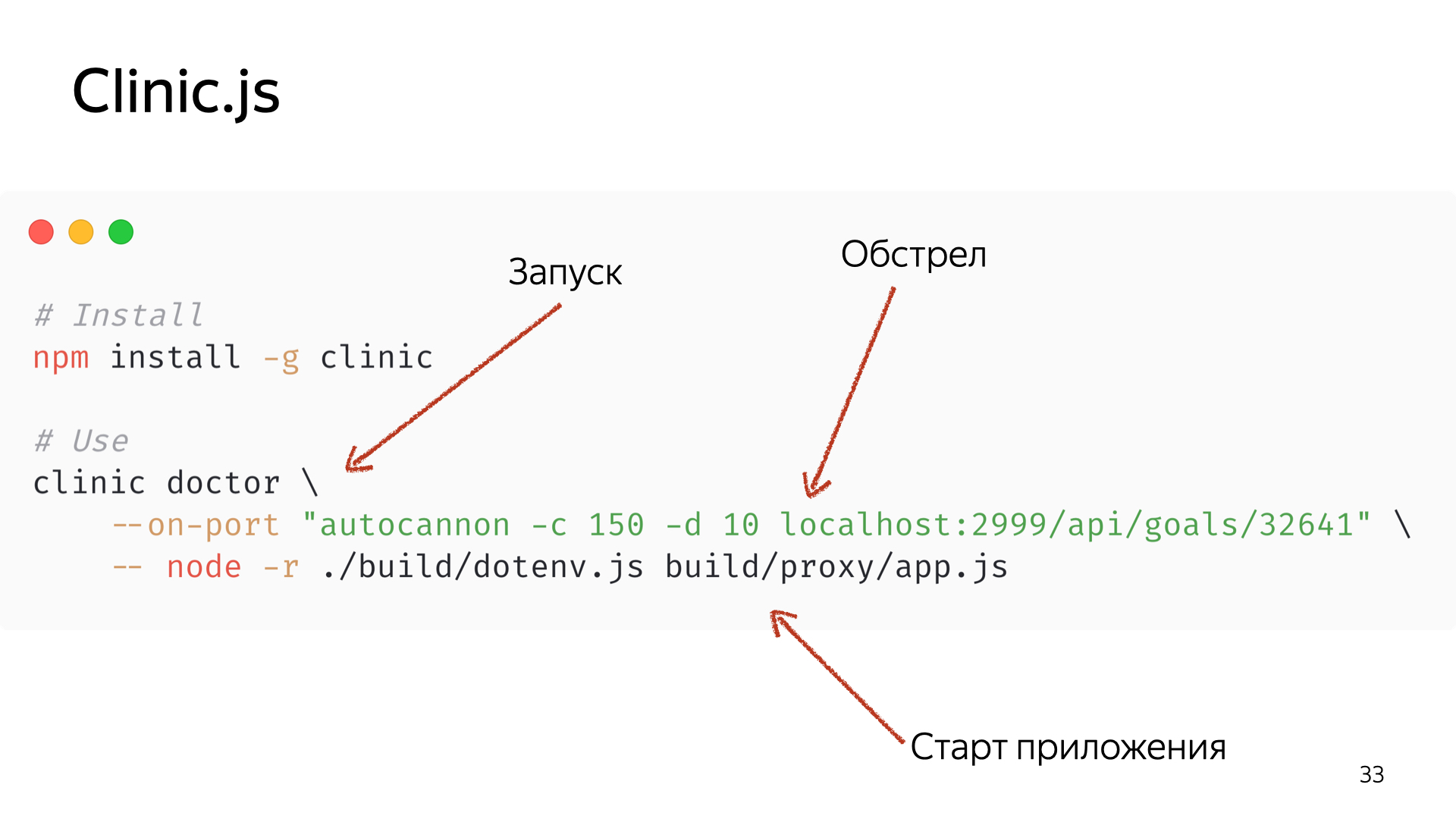
Запускаем.

Видим вот такой графичек. Что здесь есть? Потенциальные проблемы, которые выявил сам Doctor и рекомендации, как их исправить.
В рекомендациях написано: у нас где-то тут есть длинные синхронные операции, но непонятно где, поэтому иди и посмотри Flame Graph, потому что здесь есть базовые метрики — те же самые, что мы собирали предыдущими двумя системами из коробки.
Нам это не сложно, мы пойдем и сделаем себе Flame Graph примерно той же самой командой, которой запускали Doctor. Просто меняем на Flame и получаем вот такую непонятную штуку.

Что здесь происходит? Снизу — выбор отображения разных кусков нашего приложения. Например, здесь есть вызовы V8, отдельная работа WebAssembly, отдельная работа Node.js, зависимостей и самого приложения.
Мы можем поискать метод, который, как мы думаем, достаточно долго работает. Например, мы предполагаем, что вот эта штука, которая перемалывает джейсоны, очень долгая. Надо посмотреть внимательно. Можем поискать здесь. Или глянуть на самые горячие функции, которые вызываются нашим приложением:
Мы отключим WebAssembly, отключим Node.js, потому что нас это не интересует, их мы не можем заоптимизировать. Посмотрим на топ самых горячих функций. Внимательно щелкаем, смотрим, откуда что вызывается. И делаем умный вид. Если вдруг вы не заметили закономерность, то я ее вынес на отдельный слайд.Видим, что из первого топа функций всего две принадлежат express, а все остальные подозрительно принадлежат библиотеке got, которая используется для асинхронных запросов в нашем коде. 
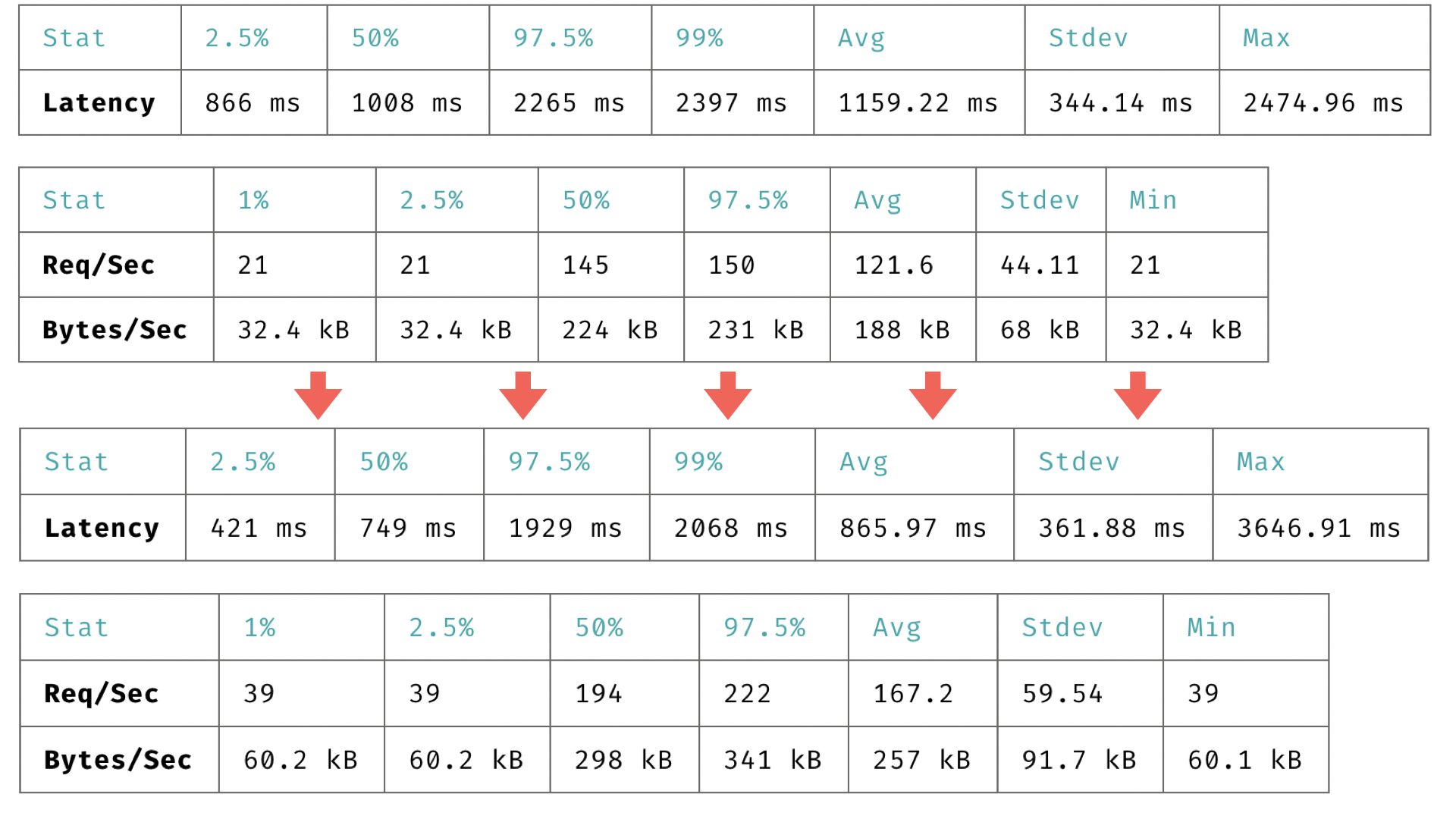
Мы внимательно посмотрели, подумали и решили —, а что будет, если мы возьмем и got поменяем на Node fetch, на что-нибудь попроще. Мы помним наши предыдущие обстрелы. Самый первый — эталонный.
Мы потратили 15 минут на замену got на Node fetch. Ничего особо сложного там не произошло, и даже все штуки, которые мы использовали, остались. И мы получаем практически бесплатный прирост в RPS, в скорости обработки ответов. Например, мы видим, что средний запрос теперь обрабатывается не за 1 с, а за 0,8 с. Неожиданно приятно. Пятнадцать минут работы!
Это классная штука, которая позволяет вам внимательно посмотреть, как работает ваш код, и заглянуть поглубже.
Помним, что есть еще Bubbleprof. Я оставлю его для вашего домашнего изучения, потому что это штука, которая больше не про метрики, а именно про профилирование вашего приложения. Вот вам логотип.
Для чего нужен Clinic.js и весь этот набор инструментов? Чтобы погрузиться глубже. Когда вы уже поняли, что в вашем коде в каком-то кейсе есть проблема, но ваши метрики не позволяют заглянуть настолько глубоко, вы эмулируете найденную проблему на вашем стенде и заглядываете туда с использованием этих инструментов.
С учетом того, что Doctor теперь работает на основе TensorFlow.js и туда завезли достаточно умные алгоритмы определения проблем, он сразу может дать вам полезные советы, куда посмотреть и что сделать. 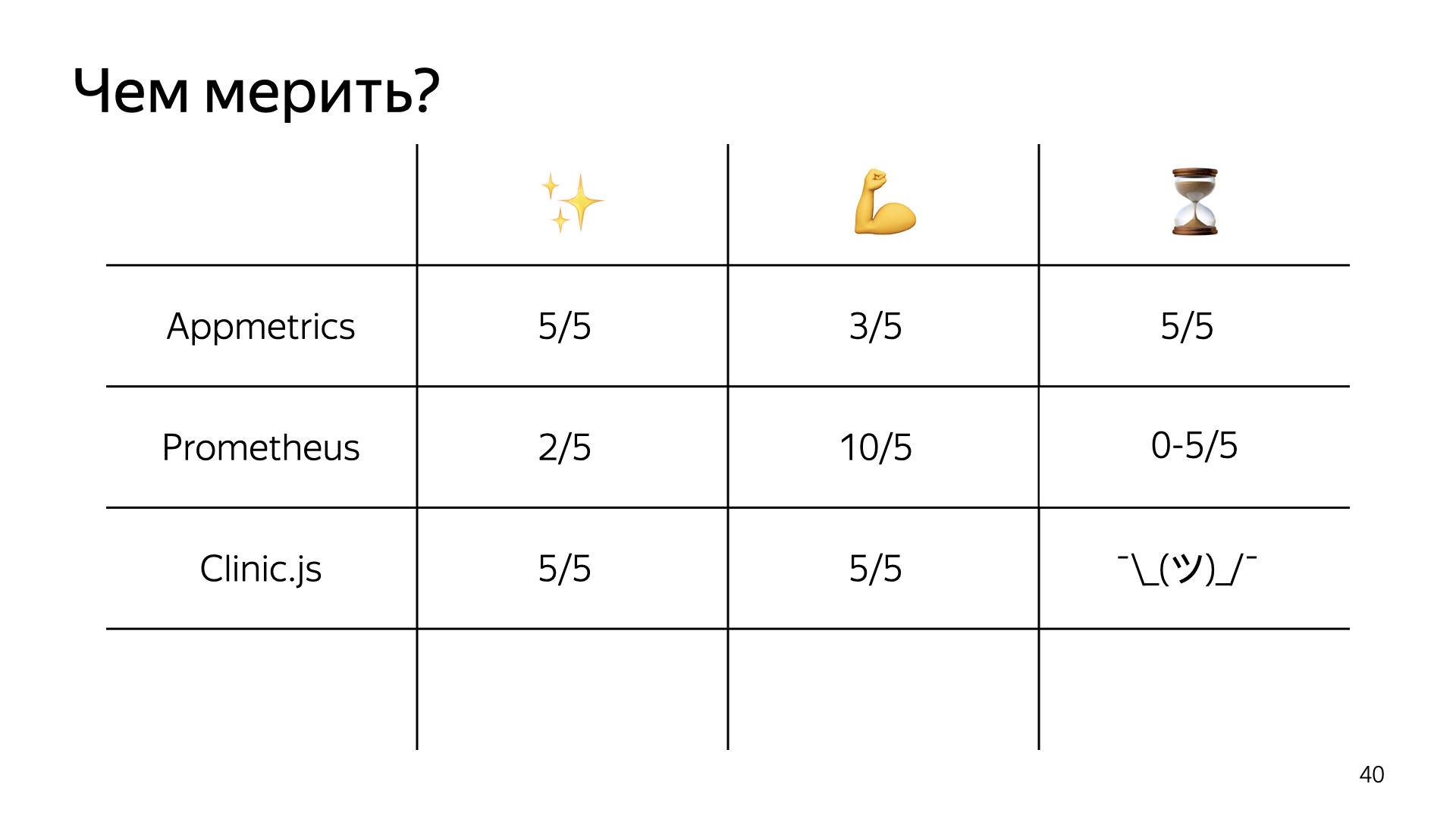
Если приложить это к нашим метрикам — простоте, мощности и скорости работы, — то простота, конечно, пять из пяти. Все это дополняется возможностями и советами Clinic.js вида: «Кажется, я тут не понял, сделай вот так. А еще ты можешь отправить нам отчет о работе твоего приложения, и мы тебе что-нибудь посоветуем».
В плане возможностей — пять из пяти, но важно понимать, что эта система — она не для мониторинга в привычном понимании, а больше для того, чтобы копать глубокие проблемы. И, конечно, не запускайте ее на продакшене. Прямо совсем не стоит.
Куда смотреть?
Куда смотреть, когда вы все это дело померили? В первую очередь, конечно, стоит смотреть на ресурсы, потому что если приложение упирается в какой-то ресурс, это его замедляет, ухудшает пользовательский опыт, нивелирует весь ваш труд по написанию кода.
Стоит смотреть на скорость работы отдельных кусков кода, потому что важно быстро заметить валенок в коде. Если вы его не заметили, пропустили на продакшен и с этим живете, то можете даже не знать, насколько все может быть плохо.
И, конечно, стоит отслеживать внутренние метрики на JS. Не зря они есть, не зря мы их собираем. Почему бы на них просто не взглянуть? Возможно, вы найдете банальные проблемы, которые очень просто порешать.
И всё?
Вы можете спросить — и что, всё? Вот мы на три инструмента посмотрели, поняли, куда их воткнуть, и на этом все? На самом деле примерно да. Но у меня есть небольшой постскриптум.
Как выглядит сервис, который никто не меряет? Просто запустили, и он где-то там работает? Это просто набор кода, контейнер с вашим кодом.
Как только вы наберете метрики, обмажете каждую строчечку кода отличными метриками, которые складываются куда нужно, и красивенько отображаются в ваших корпоративных цветах, то…
На самом деле ваш сервис не изменится. Это будет такой же контейнер с кучей кода.
А все почему? Потому что здесь важно соблюдать баланс между тремя вещами.
Первая — это ваш код. Вы его пишите и примерно представляете, как написать хороший код. Вы даже знаете предметную область и можете предположить, как сделать код поддерживаемым, масштабируемым и так далее.
После того, как вы его написали, его стоит померить. Действительно ли вы сделали все настолько хорошо, насколько возможно? Когда вы его померили, стоит настроить алерты, которые будут вам говорить, если что-то поменяется. Например, потребление памяти у базы приближается к 90%. Нужно позвонить в колокол сейчас, а не подождать, пока придет рандомный человек, взглянет на график и спросит — почему полоса зелененького с красненьким сходится, так разве должно быть?
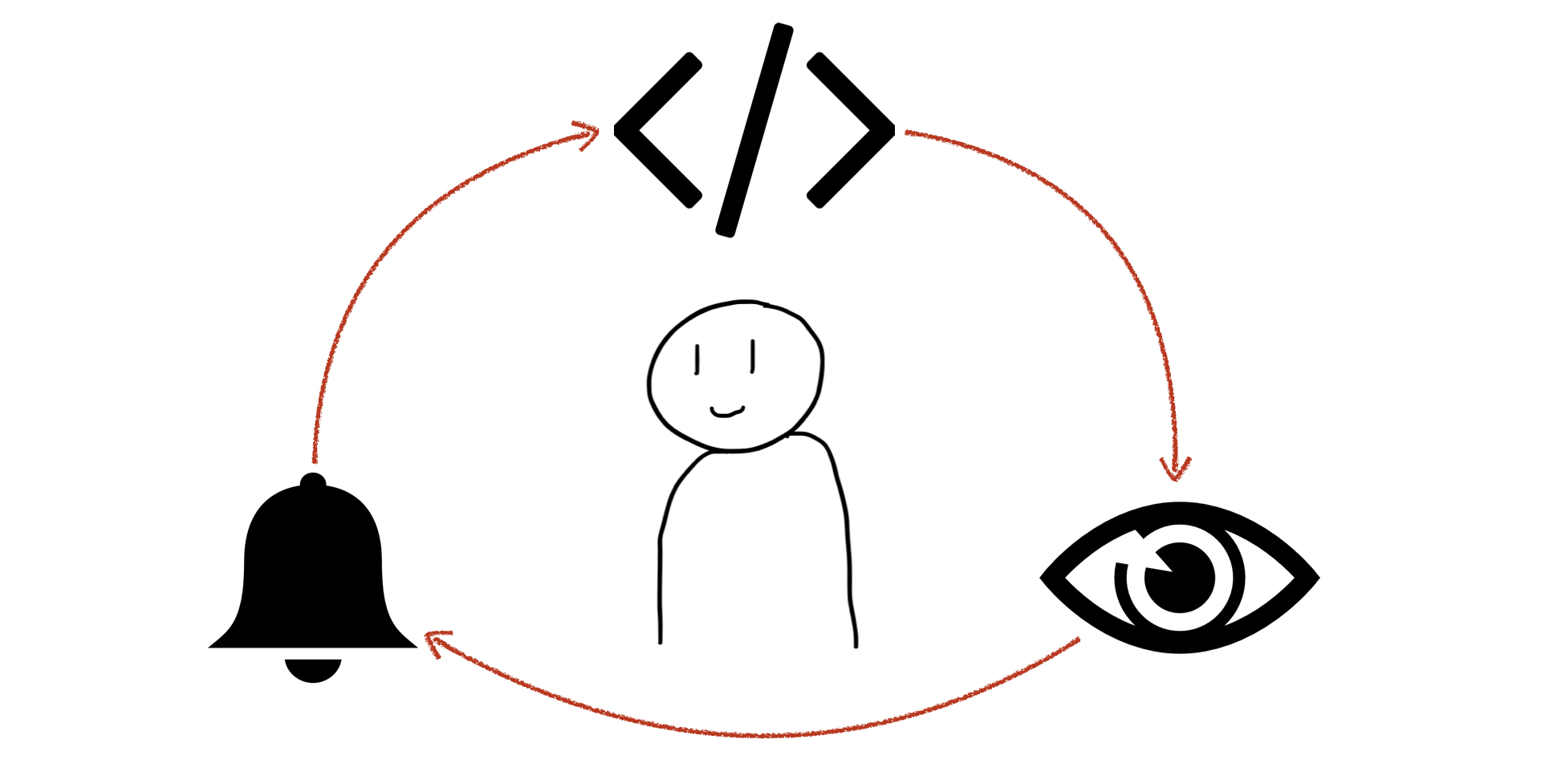
Не должно. И именно эти алерты позволят вам прийти в ваш код и сделать его чуть лучше, что-то поправить внутри него, что-то поправить снаружи, в окружении и так далее.
И, конечно, самое главное во всей системе — это вы, потому что только вы сможете выявить проблемы и найти пути их решения.
