Как поменять архитектуру облака и не поломать пользовательский опыт

Каждой компании важно оправдать ожидания клиентов, особенно публичному сервису. В случае облачных провайдеров клиенты приходят, чтобы быстро и привычным способом получить, например, виртуальную машину. Их мало волнует, что бывает взрывной рост запросов, в ЦОД приезжает новое железо, а инженеры заняты масштабной миграцией другого пользователя. Клиентам важно быстро получить услуги и отказоустойчивость сервиса. Любое, даже незначительное изменение во внутреннем пространстве сервиса может привести к проблемам на стороне клиентов, как минимум к увеличению времени создания машины.
Константин Еремин, старший системный администратор дежурной службы «Облачной платформы Selectel», рассказал, как поменять архитектуру облака на OpenStack и не поломать пользовательский опыт. На примере выдуманного провайдера Vanilla cloud solutions он объяснил, как определить масштаб проблемы. Почему, перебрав различные варианты, разработчики пришли к Apache Airflow? Какую схему использовали для реализации своих задач и что им удалось сделать с облачным сервисом с помощью выбранного инструмента? Рассказываем под катом.
Selectel — IaaS-провайдер с 6 собственными дата-центрами в 3 регионах России. Компания не только предоставляет услуги по аренде и размещению выделенных серверов, но и развивает облачную платформу на базе OpenStack. На упрощенной схеме взаимоотношения отдельных частей облака Selectel выглядят так:
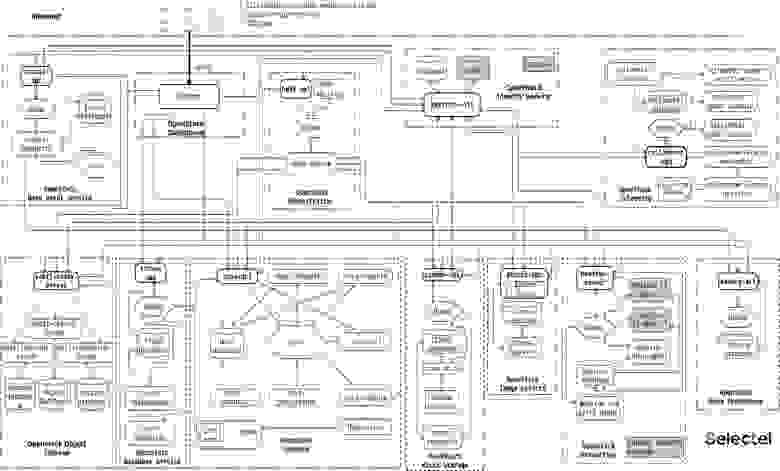
Это неупорядоченный flow зависимости всех сервисов между собой, но мы рассмотрим только три сервиса, которые ответственны за:
Виртуальные машины;
Образы;
Диски.
Клиент приходит в облако за виртуальной машиной. Для ее запуска нужны диски. Если клиент уже есть в системе, от его прошлой виртуальной машины остался диск и его надо просто подключить к виртуальной машине. Если диска нет, то клиенту достаточно создать его из образа для получения новой виртуальной машины. Образы живут в хранилище.
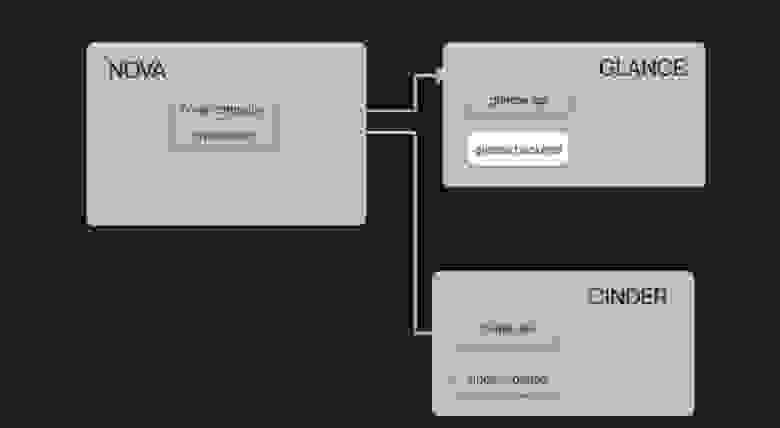
Vanilla cloud solutions
В сервисе есть два вида образов. Первый — клиентский образ, заранее подготовленный и загруженный со стороны, либо сделанный на основе старого диска. Второй — публичный образ, который распространяется облачной платформой. Чтобы дальше не погружаться в OpenStack, всевозможные сервисы и их зависимости, давайте рассмотрим все на примере сферического cloud-провайдера в вакууме. Назовем его Vanilla cloud solutions. У него будет типичная конфигурация одного региона облака.

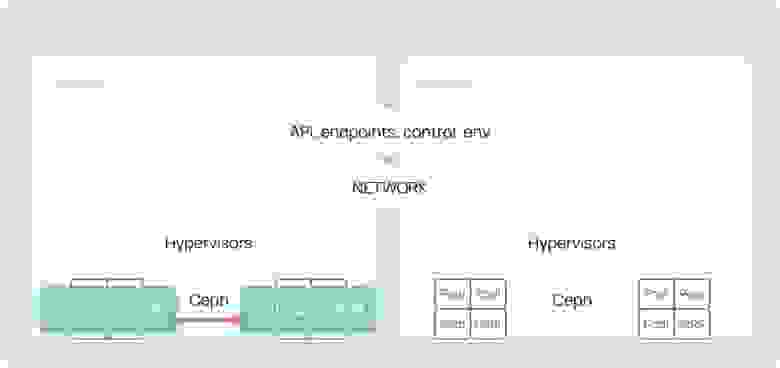
Если убрать все лишнее, регион состоит из четырех базовых сущностей:
Control Plane (API, endpoints, control, env) — служебная часть, которая не масштабируется. Некоторые сервисы могут выезжать в отдельные инсталляции, но, в целом, этот слой не трогаем.
Network
Hypervisors — часть, где крутятся виртуальные машины, она с большей вероятностью будет подвержена масштабированию.
Storage«s clusters — кластеры хранилищ, именно здесь хранятся служебные и пользовательские данные, включая диски и образы.
Когда происходит взрывной рост клиентов, облачному провайдеру необходимо масштабироваться. На первый взгляд кажется, что все это можно растянуть на соседнюю физическую локацию — в соседний машинный зал, на соседнем этаже, в соседнем здании. Если есть отдельная сетевая часть, отдельное питание, кондиционирование и резервирование, то почему бы нам не сделать так:
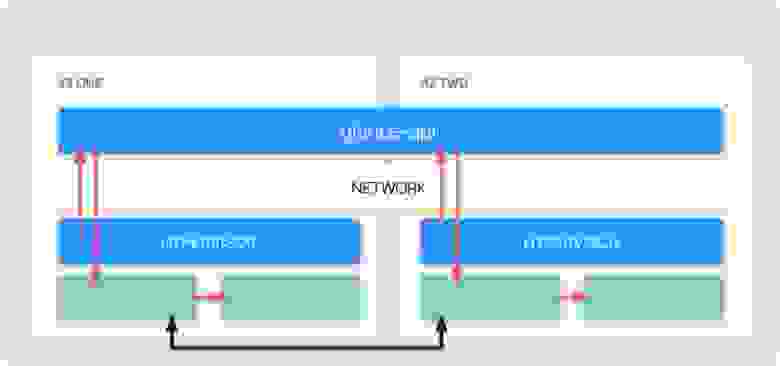
Поверх такой архитектуры клиенты смогут реализовать отказоустойчивость на уровне как минимум еще одной зоны доступности. А процесс создания диска будет происходить на уровне Ceph, когда данные льются с одного пула в другой по широченному каналу.
Но если у нас появляется вторая зона доступности, а хранилище с образами остается одно, то инициатор ходит в старый бэкенд и забирает оттуда образ к себе или в свой пул. В результате через Control Plane пойдут тысячи образов и дисков. Реализация OpenStack достаточно специфичная: если у вас есть 10 образов, из которых вы хотите создать 100 дисков, то нужно скачать 100 образов.
А хочется, чтобы инициатор ходил в общий Control Plane, в общий бэкенд и забирал оттуда метаинформацию. Чтобы создавались диски и происходило резервирование, а образ, независимо от того, где он был создан в первый раз, оказался в обеих зонах.
К сожалению, такое возможно лишь в несуществующем Vanilla cloud solutions. До релиза Rocky в OpenStack нельзя было подключить два бэкенда. А раз нет второго бэкенда, то не будет репликации, синхронизации и взаимодействия с Control Plane. На момент решения проблемы добавление второго бэкенда не предвиделось, поэтому разработчики искали альтернативный путь. Посмотрим на примере Vanilla cloud solutions, к какой системе нужно было прийти:
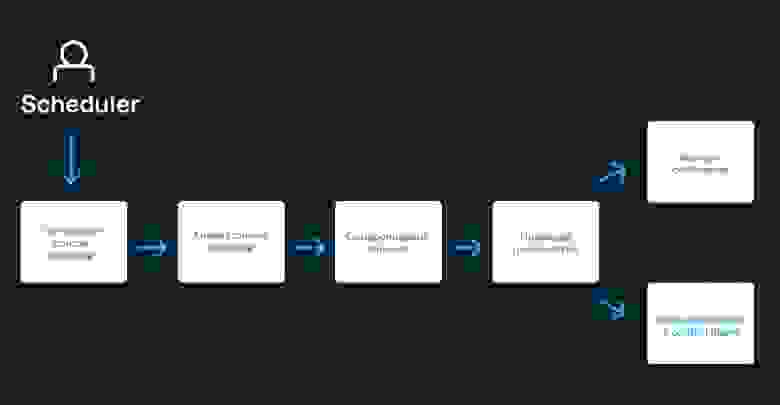
Естественно, все это должно быть автоматизировано. Необходим не просто планировщик, а система, управляющая всем процессом в фоне. После определения сути проблемы, остается выяснить ее масштабы. Для этого в Selectel проанализировали какое количество образов было создано за определенный период и какой средний размер этих образов. Оказалось, что у последних 3949 образов размер редко превышал 12 Гб. А еще 95% пользователей используют образ в первые 20 минут после его создания. Более того, в первый час большинство образов удаляется. Соответственно, клиенту этот образ необходим как можно быстрее.
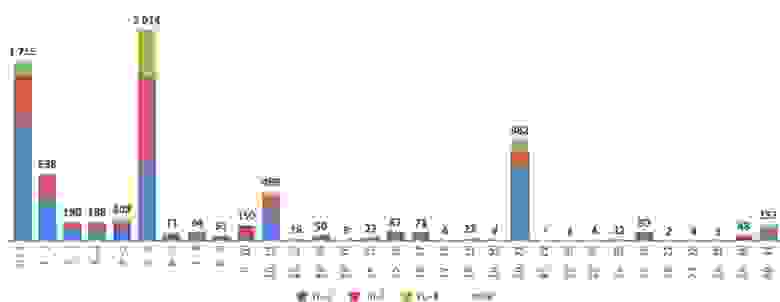 Images size distribution (ex. outliers), GB
Images size distribution (ex. outliers), GB
Ищем функциональное решение
Можно напилить скрипт на Bash, положить в Cron, и все будет работать. Но таким решением невозможно управлять. Его невозможно контролировать, мониторить и скалировать. Девелоп-решение тоже будет малоэффективно. Во-первых, у разработчиков Selectel уже был опыт использования Celery. Это был лишь движок, но все равно оставалась необходимость в планировщике, мониторинге и ручном администрировании, а это огромный объем кода и дополнительных работ. Во-вторых, нужно было решение, которое можно моментально внедрить и столь же молниеносно выпилить, в случае если этот функционал приехал бы в новом релизе OpenStack.
Если хотите узнать больше об архитектуре облака Selectel, рекомендуем эти видео:
— Обзор облачной платформы: как все работает
— Q&A: облако. Эксперты компании отвечают на вопросы пользователей

В этот момент в Selectel произошел DevOps: администраторы и разработчики решили покопать дальше и обратили внимание на Apache Airflow.
Apache Airflow
Apache Airflow позволяет не писать дополнительные обвязки вокруг Celery, чтобы создавать, редактировать, мониторить, а также скедулить таски. Его можно развернуть из коробки буквально одной командой — «docker compose up», получить веб-интерфейс со множеством примеров различного уровня сложности и всевозможными flow. Основная сущность Apache Airflow — DAG (Directed acyclic graph), набор задач, которые необходимо выполнить в строгом порядке и зависимости.

Так выглядит один из стандартных примеров, который входит в базовый набор. Он более или менее похож на то, что было нужно Selectel: цикл, задача, которая выполняется после цикла и финишная таска с условиями ее успешного выполнения. По каждой задаче можно посмотреть, когда она была выполнена, и статус ее выполнения. Все это пишется на Python, также есть выбор для движка, который занимается непосредственным выполнением задач. В Selectel выбрали привычный разработчикам Celery.
Достаточно импортнуть несколько библиотек, чтобы на выходе получить верхнеуровневый код. В основе Apache Airflow лежат операторы Bash, Python, Docker, Http, SQL и Slack. То есть это универсальный инструмент для любителей писать на Bash поверх Python или на Python поверх Python. А для поклонников Slack даже есть нативный оператор, который позволяет общаться напрямую. Киллер-фичей этого решения разработчики посчитали сенсоры, которые позволяют выполнять задачи без cron«а и цикличных расписаний. Они просто реагируют на изменение конкретных параметров.
Пример кода DAG
from datetime import timedelta
from airflow import DAG
from airflow.operators.bash import BashOperator
from airflow.operators.dummy import DummyOperator
from airflow.utils.dates import days_ago
args = {
'owner': 'airflow',
}
with DAG(
dag_id='example_bash_operator',
default_args=args,
schedule_interval='*/1 * * * *',
start_date=days_ago(2),
dagrun_timeout=timedelta(minutes=60) ,
tags=['example', 'example2'],
params={"example_key": "example_value"},
) as dag:
run_this_last = DummyOperator(
task_id='run_this_last',
)
# [START howto_operator_bash]
run_this = BashOperator(
task_id='run_after_loop',
bash_command='echo 1',
)
# [END howto_operator_bash]
run_this >> run_this_lastНа выходе получается следующее:
Одна из основных функций Airflow — возможность визуально отследить процесс выполнения задач. Понять, выполнение каких задач завершилось успехом, каких — ошибкой, а какие даже не были выполнены, из-за несоблюдения условий и/или зависимостей. На этом примере видно, что выполнение одной из задач завершилось ошибкой, поэтому финишная задача не запустилась. Такой подход позволит вам производить тонкую настройку продуктовых окружений, путем точного построения графов задач. Если что-то ни в коем случае не должно доехать до прода и реализации, просто добавьте сверху дополнительные таски, которые должны выполниться, и получите такой результат.
Если вы любите смотреть в консоль, когда задача сфейлится, то в поисках логов вам придется бегать по всем воркерам и экзекьюторам. Airflow же позволит вам проверить результат и узнать все подробности прямо в веб-интерфейсе: на какой ноде это произошло, что не взлетело и почему.
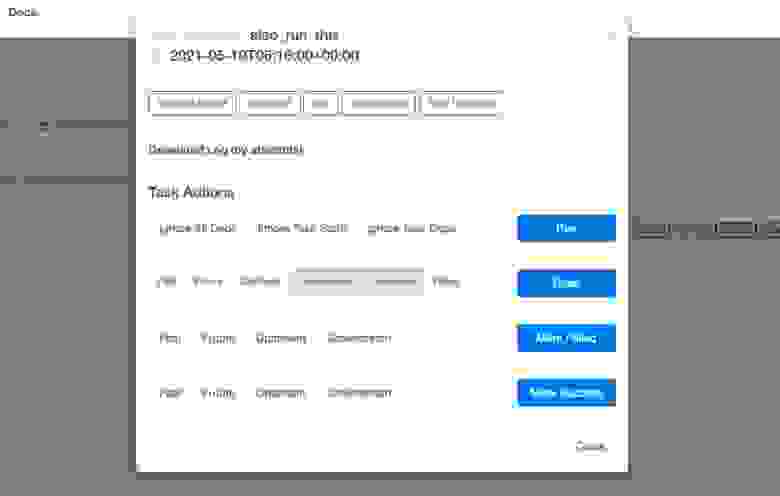
Вы увидите, например, что какой-то цикл бесконечно выполняется. В результате получается вот такой наглядный отчет:

По нему сразу видно, какой DAG не выполнился и почему, что вообще не было запущено и что надо поправить. Вы сможете мониторить каждую задачу отдельно и видеть, почему не выполняется конкретный скрипт. Проанализировать ее, сопоставить с другими задачами, которые происходят в вашей инфраструктуре, и получить на выходе следующую схему:
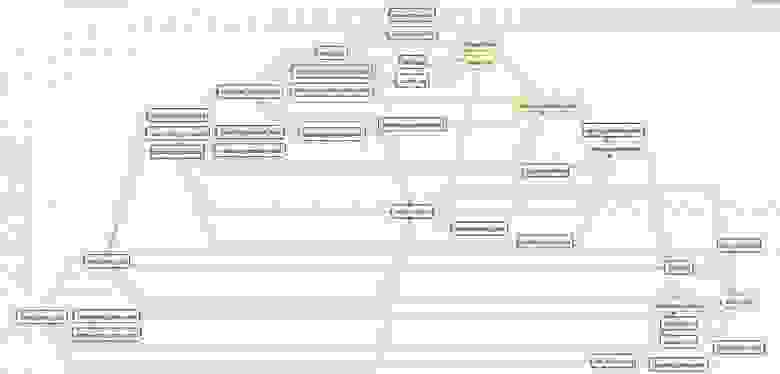
С решением разработчики определились. Следующим вопросом стала подготовка окружения. Для внедрения Apache Airflow нужны: хосты, на которых вы запустите веб-сервер со скедулером; воркер; БД; очередь сообщений. Отличительная особенность Airflow в том, что при выборе движка для каждой из перечисленных сущностей всегда есть выбор. Например, специалисты Selectel выбирали между Celery, MySQL и RabbitMQ, потому что в OpenStack это все есть. Вы можете выбрать Kubernetes, PostgreSQL и Redis. Поэтому задача заключается в том, чтобы превратить абстрактный вариант того, что вы хотите в конкретные DAG:
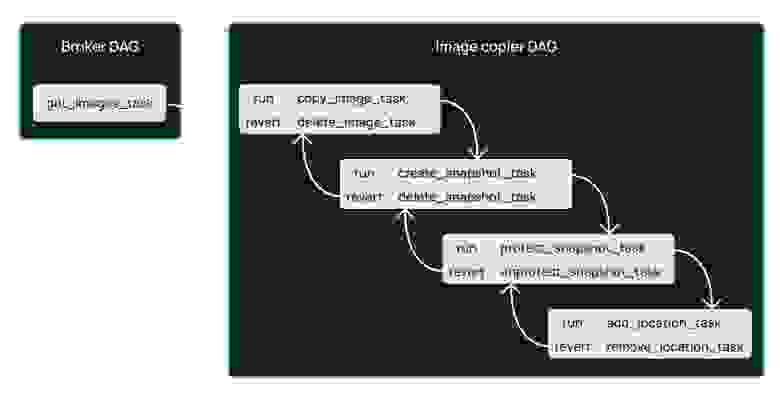
У Selectel получилась следующая схема с необходимым порядком выполнения коллбэков и ревертов. Например, если таска сфейлилась, надо не только остановить выполнение, но и откатиться к предыдущей задаче и выполнить ее с другими параметрами.
Заключение
В Selectel запустили всего два контейнера на каждый регион в каждом пуле и написали один DAG, чтобы решить свою проблему. Им понадобились только скедулер, веб-сервер и сам воркер. В результате они получили отказоустойчивые зоны доступности и высокую скорость запуска инстансов.
Благодаря новому инструменту теперь они могут легко масштабироваться, а их клиенты получают высокую скорость запуска виртуальных машин. У них получилось добавить вариативности, способствующей отказоустойчивости клиентской архитектуры поверх облака. Учитывая рост и темпы развития облака компании, было критически важно вносить изменения в архитектуру облака в том время, как клиенты продолжают пользоваться сервисами «Облачной платформы». Сейчас разработчики Selectel могут выкатывать новый сервис, фичу или обновление, а виртуальные машины клиентов продолжают работать.
Опыт работы с универсальным инструментом оказался настолько успешным, что его планируется применять в других задачах.
Видео выступления Константина на DevOps Conf 2021 можно посмотреть здесь.
Для тех, кто соскучился по профессиональному нетворкингу и хочет быть в курсе всех передовых решений — бандл из двух конференций Saint HighLoad и HighLoad++ 2021 c 20% cкидкой. Предложение действительно до 19 сентября 2021 года.
