Как появляются ресурсы для запуска проектов на базе машинного обучения

Еще в 2016 году инженеры IBM отмечали, что взаимосвязь между ИИ и облачными технологиями может стать симбиотической, когда одна технология помогает улучшить другую. Будущее наступило, и можно сказать, что коллеги оказались правы. Облачные вычисления упрощают работу с комплексными ML-моделями, стимулируют развитие нейросетей.
Обучение ML-моделей, проведение экспериментов, возможность вернуться к предыдущим версиям модели, сравнить результаты работы модели на шаге 3 и шаге 27 — это актуальные задачи, которые стоят перед командами. В #CloudMTS эти задачи разработчики и аналитики данных могут совместно решать в MLOps-платформе.
Сегодня расскажем, откуда еще (и зачем) берутся ресурсы для запуска сложных моделей, как ИИ и облачные вычисления переплетаются между собой.
Развитие искусственного интеллекта через призму облачных технологий
Термин artificial intelligence ввел основоположник функционального программирования Джон Маккарти в 1956 году. Хотя первые программы, способные играть в шашки и шахматы, появились как минимум пятью годами ранее. С тех пор системы искусственного интеллекта проделали огромный путь: AlphaGo обыграл корейского профессионала Ли Седоля в матче по Го, а компьютер Watson одержал победу в интеллектуальной викторине Jeopardy. Компании вкладывают средства в технологии машинного обучения, развивают и внедряют большие языковые модели вроде ChatGPT, встраивают их в BI-системы и другие аналитические решения.
Прогресс в области ИИ дает ощущение новой смены парадигм. Фундаментально меняется способ создания и доставки программного обеспечения. Облака в значительной степени расширили возможности компаний-разработчиков моделей машинного обучения. Некоторые из них вообще развивают собственные облачные платформы, чтобы предлагать клиентам системы ИИ в формате SaaS. В частности, технология расширенного обнаружения и реагирования (XDR) на рынке кибербезопасности в значительной степени опирается на облачный ИИ.
ИИ находится на пути к радикальному изменению большинства аспектов деятельности предприятия, не говоря уже о многих аспектах человеческой жизни. И постоянная масштабируемость облака будет играть в этом неотъемлемую, взаимосвязанную роль.
Точность моделей
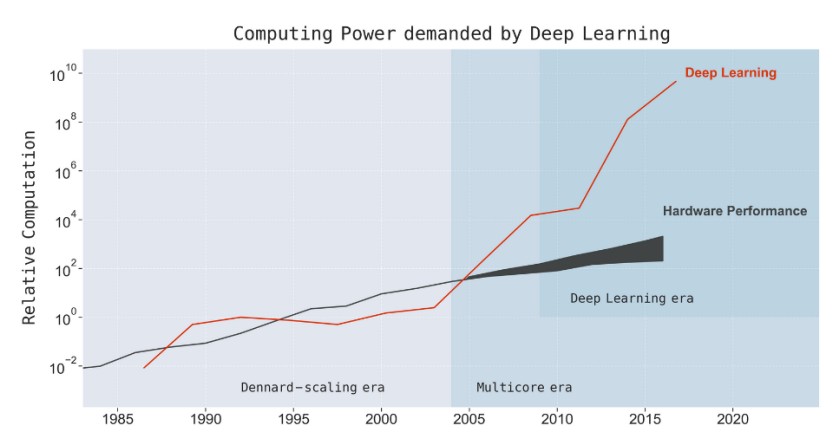
Вычислительная мощность, используемая в крупнейших моделях глубокого обучения. Сравнение с ростом производительности аппаратного обеспечения (за счет улучшения процессоров)
В прошлом году интернациональная группа инженеров проанализировала тысячу научных работ по машинному обучению. Они были посвящены системам искусственного интеллекта для классификации изображений, машинного перевода и распознавания объектов. В публикации «The Computational Limits of Deep Learning» специалисты сделали вывод, что прогресс в области развития нейросетей прямо пропорционален мощности компьютерных систем. Иными словами, расширение функциональности и повышение точности ML-моделей требует не только более эффективных вычислительных методов, но и больших вычислительных ресурсов. Это — одна из причин, почему машинное обучение и облако будут и далее работать в паре.
Виртуальная инфраструктура позволяет оперативно подключать дополнительные процессоры, графические карты и хранилища. Большие мощности означают новый качественный уровень моделей, в чем мы успели убедиться вместе с компанией VisionLabs, разрабатывающей технологии компьютерного зрения на базе моделей-трансформеров. Первое время специалисты обучали их на локальной инфраструктуре, но эффективность алгоритмов уперлась потолок. Тогда команда развернула инфраструктуру в облаке #CloudMTS. Дополнительные ресурсы увеличили точность нейросетей, и они стали допускать на 15% меньше ошибок.
Работа с данными

Увеличение данных — это процесс расширения входного набора данных путем незначительного изменения существующих (исходных) примеров. Типичные методы изменения изображений: обрезка, поворот, масштабирование, переворачивание и изменение цвета. Источник
Чтобы определить, насколько объемный свод данных необходим для обучения модели, используют »правило десяти». Количество обучающих примеров на входе должно быть в десять раз больше числа степеней свободы (параметров).
Так, например, если ваш алгоритм отличает изображения кошек от изображений собак на основе 1 000 параметров, то для обучения модели вам потребуется 10 000 изображений.
Но такой подход хорошо работает на компактных задачах. Крупные проекты вроде больших текстовых моделей требуют более значительных объемов данных. Их нужно где-то хранить и обрабатывать. Особенно в контексте, когда команды разработчиков и дата-сайентистов становятся все более распределёнными. Более сложные алгоритмы всегда требуют большего объема данных.
Здесь на помощь также приходит виртуальная инфраструктура. Специалисты консалтинговой компании TierPoint, помогающей с оптимизацией затрат на ИТ, подсчитали, что за исключением крупнейших корпоративных дата-центров, лишь облака способны предоставить разработчикам ML-моделей необходимые ресурсы для хранения и обработки данных.
По мере быстрого роста ИИ облачные хранилища будут расти вместе с ним. В облаке провайдера можно настроить data lake и складывать туда структурированные и неструктурированные данные, поступающие из различных источников. В целом хранить большие датасеты и модели можно в облачном объектном хранилище.
Управление и аналитика
В начале года компания Google опубликовала исследование «Data and AI Trends Report 2023», посвященное облаку и развитию интеллектуальных решений. По оценкам аналитиков, к 2025 году 90% корпоративных приложений будут иметь встроенные системы ИИ. Работать с ними будут через единый интерфейс. Речь о панели управления с данными, дашбордами, аналитическими инструментами. И облако — подходящая площадка для этой задачи.
- Например, Walgreens — крупнейшая в мире аптечная компания — использует облачную платформу ИИ для разработки новых моделей предоставления медицинских услуг.
- Как отметили аналитики консалтинговой компании Deloitte, один из крупнейших в мире судостроителей использует облачный инструментарий с элементами ИИ для разработки и управления автономными грузовыми судами.
- Американское онкологическое общество применяет облачные сервисы машинного обучения для автоматизированного анализа изображений тканей.
Системы управления в облаке развертывает и российская компания КСОР. Она разрабатывает продукт «Антисон», который с помощью моделей машинного обучения мониторит состояние водителя, его степень усталости. Команда обучает нейросети на миллионах изображений и сотнях часов видео, анализируя положение головы и век, изменения в мимике.
Одна из важных составляющих системы мониторинга для владельцев автопарков — персонализация нарушений и рейтинг водителей. Вся информация поступает в единый командный центр, развернутый в облаке #CloudMTS. Таким образом, формируется БД инцидентов для анализа опасных ситуаций на дороге. Опираясь на эту информацию, бизнес может управлять парком автомобилей, оптимизировать его работу. Так, «Антисон» уже помогает снизить количество ДТП по вине водителей на 26% за год.
Заключение
Системы искусственного интеллекта находятся на этапе молниеносного роста, который проходили облачные технологии в начале нулевых. Работа с API, управление с помощью кода — машинное обучение предлагает пользователям и компаниям возможности в формате «здесь и сейчас».
Облака дополнительно упрощают взаимодействие с ML-моделями. Облачные провайдеры предлагают серверы и инструменты, специально разработанные для поддержки задач ML, поэтому использование этих ресурсов может быть более эффективным, чем создание инфраструктуры с нуля.
Кроме того, с помощью облачных вычислений проще масштабировать ML-модели, повышать точность обучения и предоставлять данные удаленно пользователям.


