Как оценка актуальности резюме помогла работодателям эффективнее находить кандидатов
Привет! Меня зовут Владислав Урих, я продуктовый аналитик в Авито Работе. Мы с командой занимаемся улучшением опыта работодателей, которые ищут сотрудников на Авито, и качеством пользовательских резюме. В статье объясню, как мы придумали новый подход для оценки актуальности таких объявлений.

Увидели потребность в том, чтобы изменить механику работы с резюме
На Авито Работе можно публиковать резюме и искать сотрудников. Когда компании или частные лица ищут работников, мы предлагаем им анкеты подходящих людей из базы. Но чтобы увидеть телефон, или получить возможность написать соискателю, работодателям нужно оплатить пакет контактов.
Мы регулярно исследуем обратную связь соискателей и работодателей, благодаря этому выявили несколько важных точек роста:
Сложности на стороне работодателей:
~71% работодателей покупали контакт с соискателем, но не получали ответа. Это могло происходить по разным причинам, например, если человек удалил наше приложение и не видел уведомлений.
~40% работодателей сталкивались с неактуальными резюме. Такое может происходить, например, когда соискатели находят работу, но не удаляют свою анкету. Из-за этого мы считали, что они всё ещё в поиске, и показывали их работодателям. Те покупали контакт, связывались с человеком, но оказывалось, что пользователь просто забыл удалить резюме.
Сложности на стороне соискателей. Помимо того, что работодатели не были удовлетворены качеством резюме, мы заметили, что не все соискатели получают контакты: у 62% их не было вовсе, но при этом 7% получали 5 и более контактов.
Чтобы решить эти проблемы, мы решили архивировать все неактуальные резюме, и оставить в базе только тех, кто действительно ищет работу.
Решили архивировать неактуальные резюме, но столкнулись с проблемами
Мы отправляли пользователям пуш-уведомления и звонили, чтобы узнать, ищут ли они работу. Если ответа не было — резюме архивировали. Так мы удалили часть неактуальных анкет, но это привело к проблемам:
На одно резюме стало приходиться на 30% больше контактов. При этом доля резюме, на которых есть хотя бы один контакт, не выросла. То есть мы стали чаще предлагать одни и те же резюме.
Резюме стало не хватать: спрос работодателей не покрывался предложениями соискателей.
Мы проанализировали результаты и поняли, что нужно отключить архивацию и выбрать другой подход.
Чтобы Авито помогал соискателям найти работу, а работодателям — сотрудников, мы решили разработать и внедрить модель оценки актуальности резюме. Тогда работодатели видели бы больше релевантных анкет, а соискатели получали больше целевых контактов. Но, прежде чем разрабатывать модель, нужно было проверить, влияет ли актуальность объявлений на метрики бизнеса.
Стали разрабатывать ML-модель для определения актуальности объявлений
Определили целевую метрику. Мы провели исследование с помощью теста Грэнджера и увидели, что коннектность резюме влияет на retention работодателей. То есть если они пишут и звонят соискателям и получают ответы, то с большей вероятностью закроют свою потребность и затем снова придут искать сотрудников на Авито.
Также мы выяснили, что, если будем выводить актуальные резюме выше в поиске — вероятность получить подходящее предложение для соискателя вырастет. И количество случаев, когда его наймут, тоже вырастет.
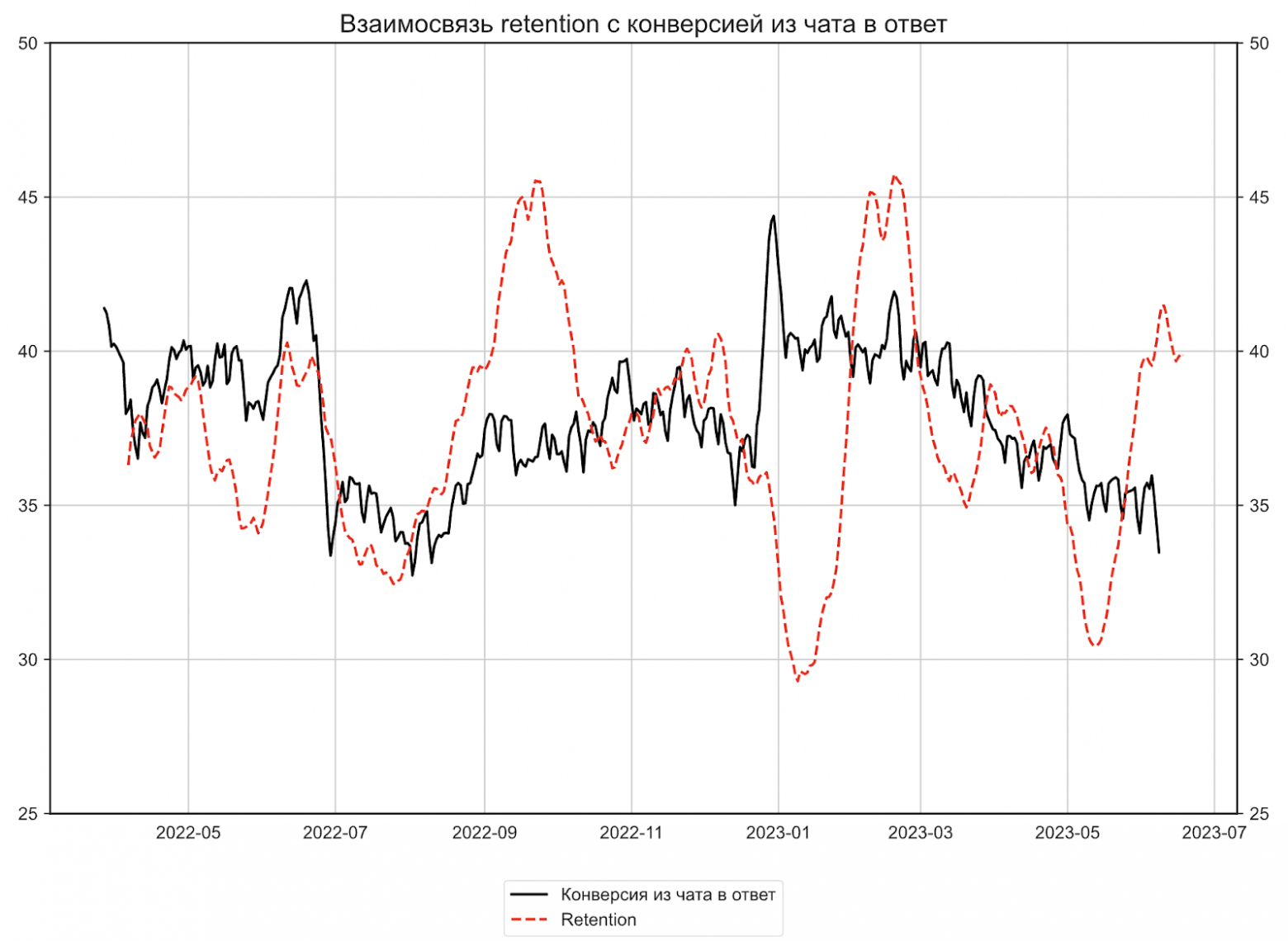
График взаимосвязи метрики retention с долей отвеченных чатов
Основной метрикой мы выбрали долю отвеченных сообщений, так как её увеличение влияет на retention работодателей в повторную покупку резюме.
Отобрали признаки, по которым можно сказать, что пользователь ищет работу. Мы решили обучать ML-модель на данных о чатах соискателей с потенциальными работодателями. Использовали модель бинарной классификации: 1 — соискатель ответил работодателю в течение трёх дней, 0 — не ответил.
Таким образом мы хотели обучить модель определять вероятность того, что резюме соискателя актуально. Этот параметр складывался из множества характеристик самих резюме и поведения соискателей на площадке:
факторы активности соискателей: как человек контактирует по вакансиям и отвечает работодателям, когда они пишут ему;
факторы наполненности резюме: как много информации о соискателе есть в объявлении, указан ли подходящий тип занятости, насколько человек активен в поиске работы, готов ли выйти завтра;
факторы взаимодействия с резюме: как часто соискатель обновляет данные в резюме.
Определили значимость признаков для первого контакта и последующих. После того как мы описали показатели актуальности, мы стали проверять, как разные поведенческие признаки влияют на конверсию в отвеченный чат.
Если влияние прямое, значит, поведение пользователя указывает на актуальность резюме. Обратное — значит, это действие увеличивает вероятность, что резюме неактуальное, а пользователь не ответит.
Признаки мы разделили на 2 таблицы: значимость для первого контакта и для последующих. Это нужно, чтобы одинаково качественно определять актуальность новых резюме, по которым ещё не было контактов от работодателей, и тех, по которым они уже успели написать или позвонить.
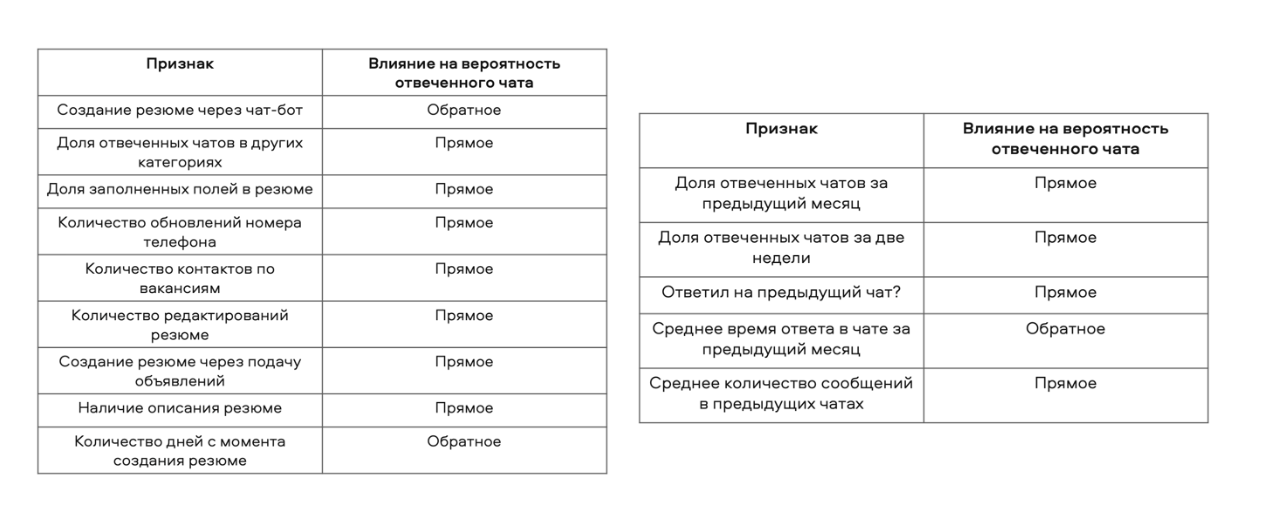
Таблицы поведенческих признаков соискателей на площадке
Выбрали модель и проверили, как она соотносится с реальностью. Мы перебрали несколько алгоритмов классификации и остановились на случайном лесе (Random Forest Classifier). Этот алгоритм показал лучший результат по метрике ROC-AUC — 0.751.
Также для нас было важно, чтобы оценки модели хорошо соотносились с фактической вероятностью ответа. Для проверки мы взяли полученные оценки по резюме, по которым был контакт в определённый день, и сравнили с фактическим количеством отвеченных контактов.
Например, 1 сентября тысяча пользователей ответила на сообщения работодателей. Мы брали все резюме, по которым был контакт, и складывали их оценки. В итоге мы хотели оценить, насколько оценки модели соотносятся с фактическим количеством ответов в чате.
Отдельно оценивали вероятность ответа для первого контакта и для последующих.
Провели тесты и увидели, что средняя разница между прогнозируемым и фактическим значениями равна 4,19% для первого контакта, и 4,01% — для последующих.
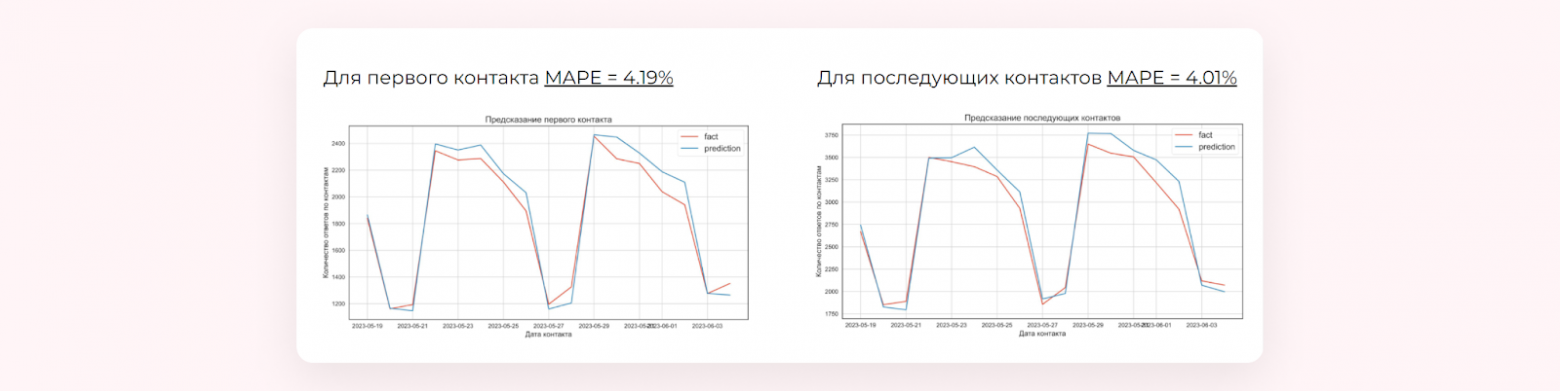
Результаты проверки качества модели
На генеральной совокупности мы можем достаточно точно определить все ответы по контактам резюме, если взвесим по оценкам модели.
Начали внедрять модель в поиск
Определили, в какую стадию ранжирования результатов поиска встроиться. На Авито в нём есть два этапа ранжирования объявлений, они называются L1 и L2.
Например, человек делает поисковый запрос — ищет дизайнера. На этапе L1 из всего массива объявлений мы отбираем ему топ из 300 подходящих. А на этапе L2 — сортируем их ещё раз, чтобы вверху были наиболее актуальные объявления.
Чтобы понять, в какой этап ранжирования нужно встраивать нашу модель, мы стали моделировать новые поисковые выдачи. Ранжировали объявления с помощью модели и смотрели, повышается актуальность объявлений или нет. Вот что мы выяснили:
В выдачах, где меньше 300 объявлений (их доля — 48%), L1-ранжирование никак не влияет на увеличение видимой актуальности объявлений. А вот если встроим модель в L2 ранжирование — сможем получить аплифт отвеченных чатов на 12–14%.
В выдачах, где больше 300 объявлений (доля — 52%), мы не можем аналитически оценить внедрение модели на этапе L1. Но на L2 так же получим аплифт отвеченных чатов на 12–14%.
Оценили, как актуальность должна влиять на результаты поиска. Ранжировать объявления только по актуальности мы не можем, нужно обязательно учитывать их релевантность. Иначе мы стали бы показывать работодателям пусть и актуальные, но неподходящие под запрос резюме. Например, те, кто ищут курьера, увидели бы первым в поиске свежую анкету бухгалтера.
Чтобы определить позицию объявления в поисковой выдаче (RankingScore), помимо актуальности (ActualityScore), мы ввели метрику Click Predict Score — она отражает кликабельность и релевантность резюме. Затем на исторических данных мы определили, что будем смешивать их вот в таких пропорциях:

Оптимальная формула расчёта позиции резюме в поисковой выдаче: доля вклада нашей новой модели актуальности — 45% доля вклада релевантности — 55%
Такие веса позволяют нам вырастить долю отвеченных контактов за счёт увеличения актуальности резюме в поисковой выдаче, и при этом не потерять в выручке из-за низкой релевантности анкет.
Оценили, как наша текущая выдача объявлений отличается от идеальной. Такой мы считаем выдачу, в которой работодатель пишет всего одному соискателю — и тот в итоге становится сотрудником.
За оценку идеальной выдачи отвечает метрика Normalized discounted cumulative gain (NDCG). Нам было важно, чтобы NDCG не просела по показателю целевых действий работодателей, а также чтобы повысилось количество отвеченных чатов (answered messages). Так и получилось:
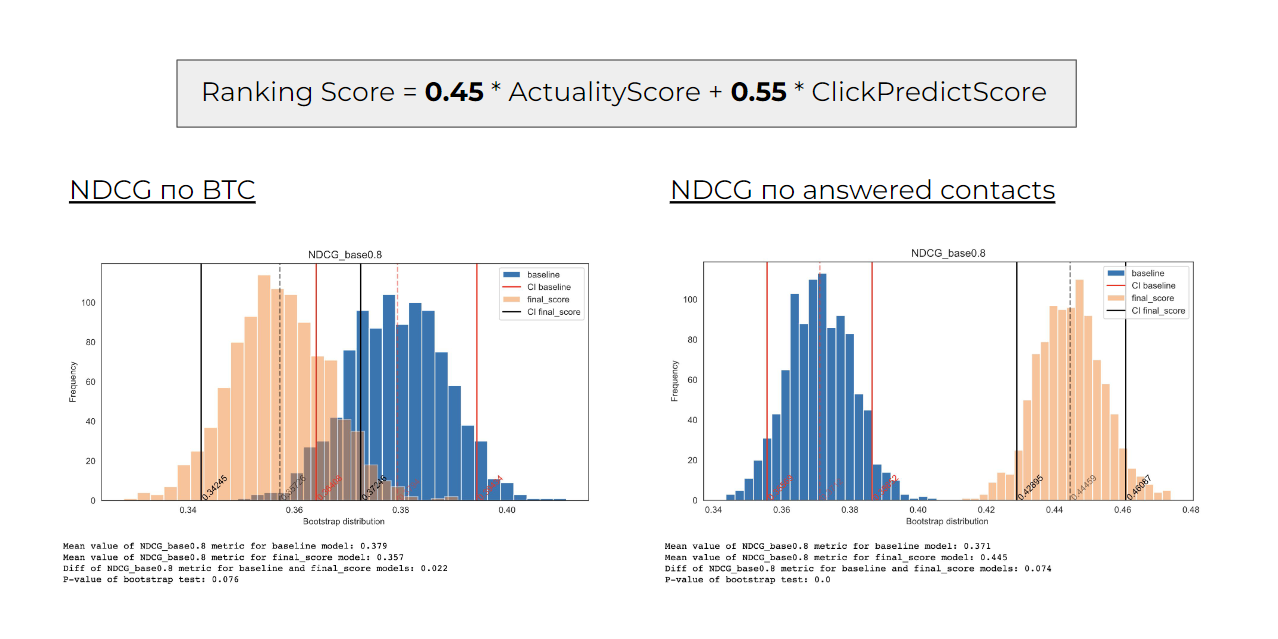
Данные сравнения модели с идеальной выдачей
Провели A/B-тесты для поиска и увидели, что количество отвеченных чатов выросло
Первый A/B. С первого же теста мы увидели, что значимые метрики выросли. Благодаря новой выдаче, которую формировала наша модель, количество отвеченных чатов увеличилось, то есть соискатели стали чаще отвечать работодателям, потому что мы стали выше выводить актуальные резюме.
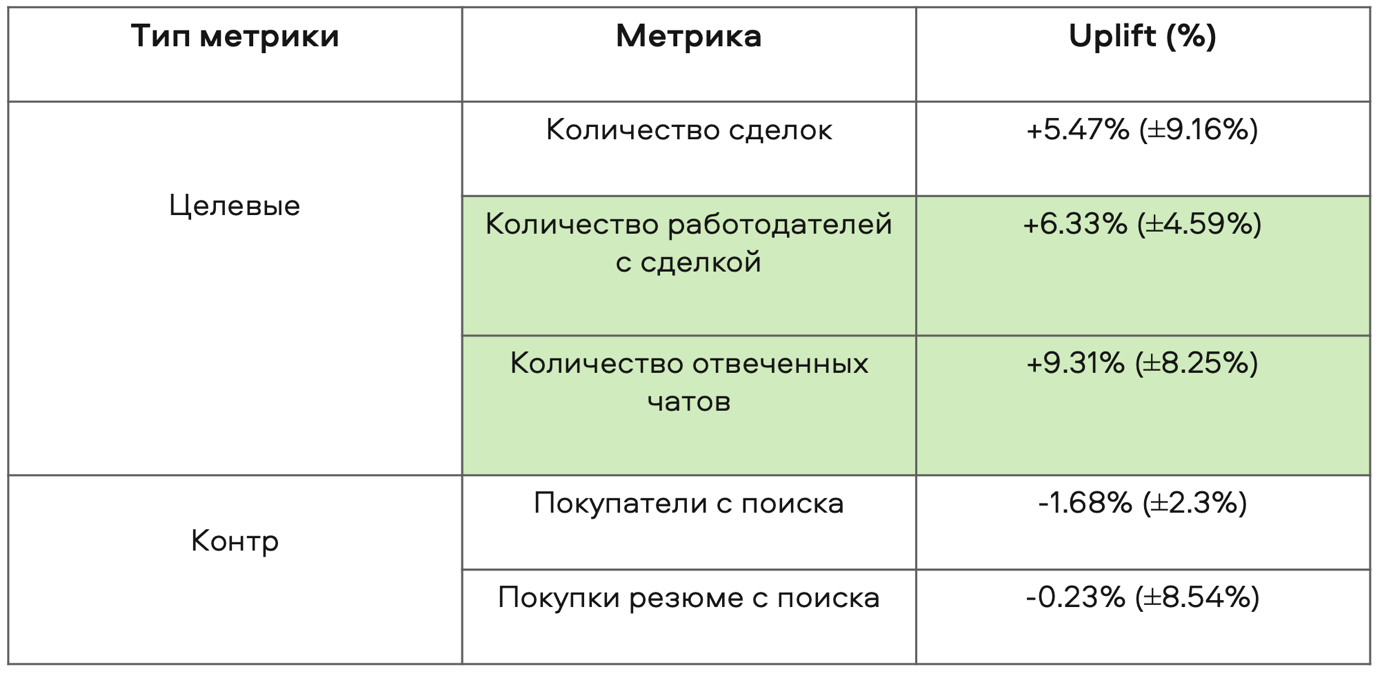
Результаты первого A/B-теста модели в поиске. Метрика целевых контактов — это приблизительная оценка сделок через анализ чатов/звонков (сделка — ситуация, когда соискатель и работодатель договорились о выходе на работу)
Второй A/B. Во второй раз мы решили увеличить долю актуальности в итоговом скоре — взяли 80% на 20%:
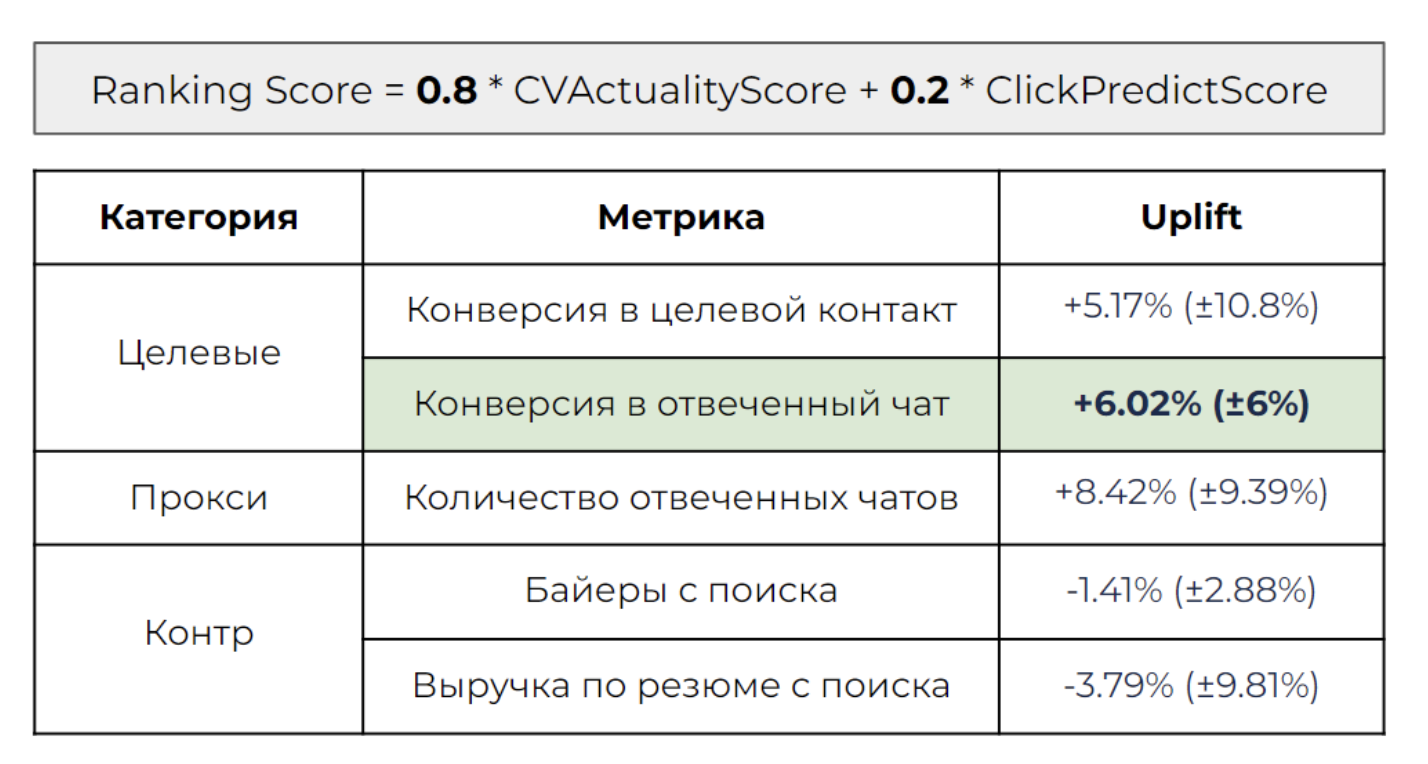
Формула расчёта позиции резюме в поисковой выдаче
Увидели, что конверсия в отвеченный чат подросла, а количество отвеченных чатов и конверсия в целевой контакт не упали.
Результаты второго A/B-теста модели в поиске
Стали внедрять модель в блоке рекомендаций
Как я писал выше, мы внедрили модель на этапе поиска, чтобы она ранжировала резюме и показывала самые актуальные вверху, а неактуальные уводила вниз выдачи. Так как 2 предыдущих A/B-теста показали хорошие результаты, мы решили не останавливаться на достигнутом, и стали внедрять модель в блок рекомендаций.
Как и в прошлый раз, прежде чем внедрять модель в рекомендации, мы проверили, какие данные показывает наша модель в сравнении с идеальной выдачей. У нас были тестовая и контрольная группы и после проверки, мы убедились, что результаты тестовой группы значимо выше результатов контрольной:

Результаты сравнения нашей модели с метрикой NDСG. NDCG@k — показатель того, насколько выдача хороша относительно идеальной на топ-k позиций (мера того, насколько мы приблизились к идеальной выдаче)
Провели A/B-тесты для рекомендаций
Мы решили взять тот же подход, что и в поиске, и ранжировать объявления по формуле с теми же значениями:

Формула расчёта позиции резюме в рекомендательной выдаче
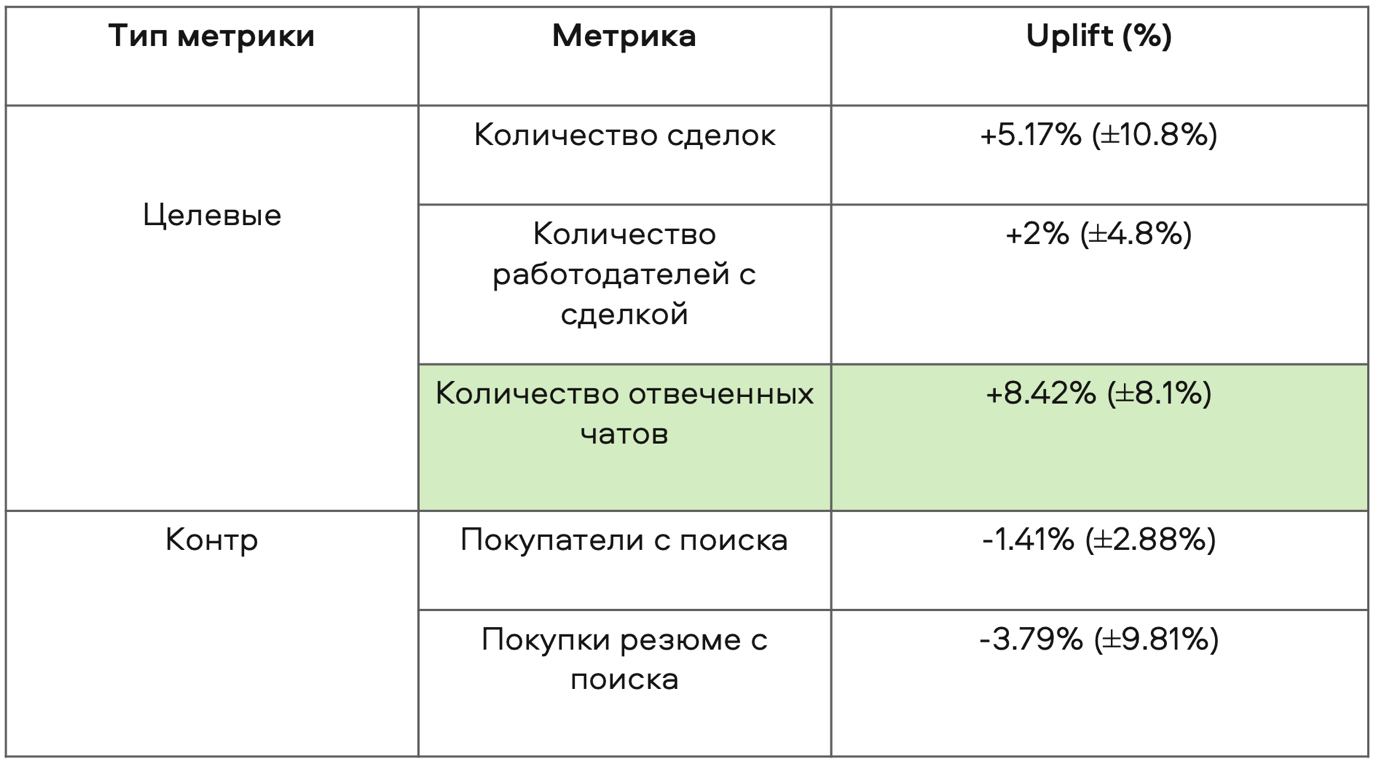
Провели первый A/B-тест и получили такие результаты:
Результаты первого A/B-теста модели в блоке с рекомендациями
Тест оказался неудачным — все значимые метрики упали. Мы обнаружили, что в рекомендациях оценки релевантности и актуальности объявлений имеют разное математическое ожидание и дисперсию, в отличие от тех же показателей в поиске.
На картинке ниже видно, что итоговое ранжирование было идентично ранжированию по актуальности. Это значит, что мы просадили релевантность рекомендаций — например, начали советовать резюме бухгалтеров или SMM-менеджеров тем, кто раньше искал водителей.
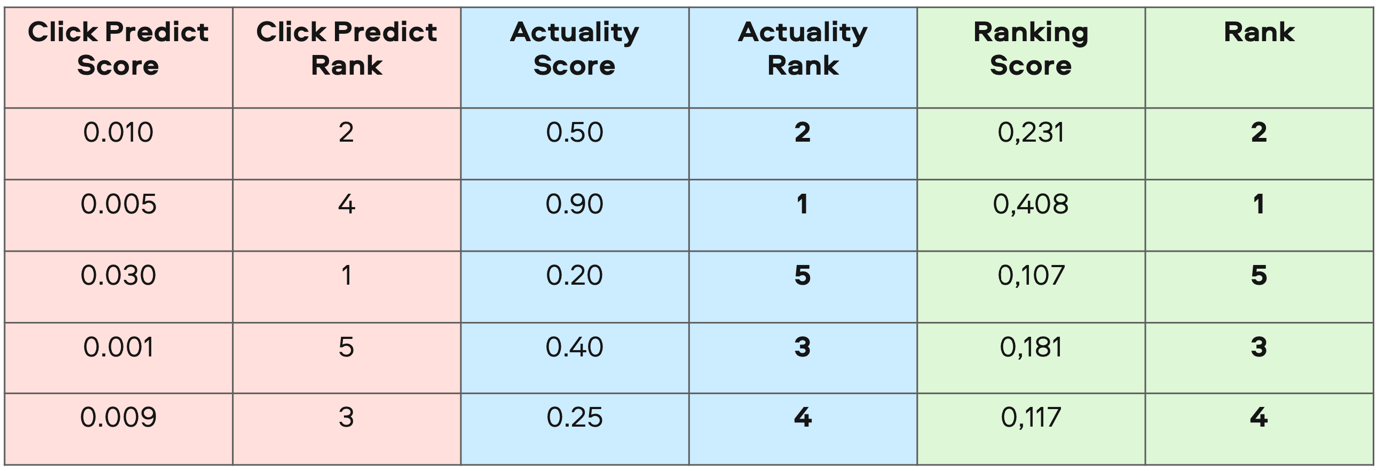
Логика ранжирования в первом A/B-тесте
Мы поняли, что если оставим старые веса для актуальности и релевантности — 45% на 55%, то оценки релевантности не будут вносить вклад в ранжирование. Поэтому с помощью обычной эвристики перешли от скоров к рангам и стали ранжировать по их комбинации:

Формула расчёта позиции резюме в рекомендациях
Теперь итоговое ранжирование рекомендаций не было равно ранжированию по актуальности. В новом ранжировании в равной степени учитывались кликабельность, то есть релевантность, и вероятность того, что соискатель ответит работодателю.
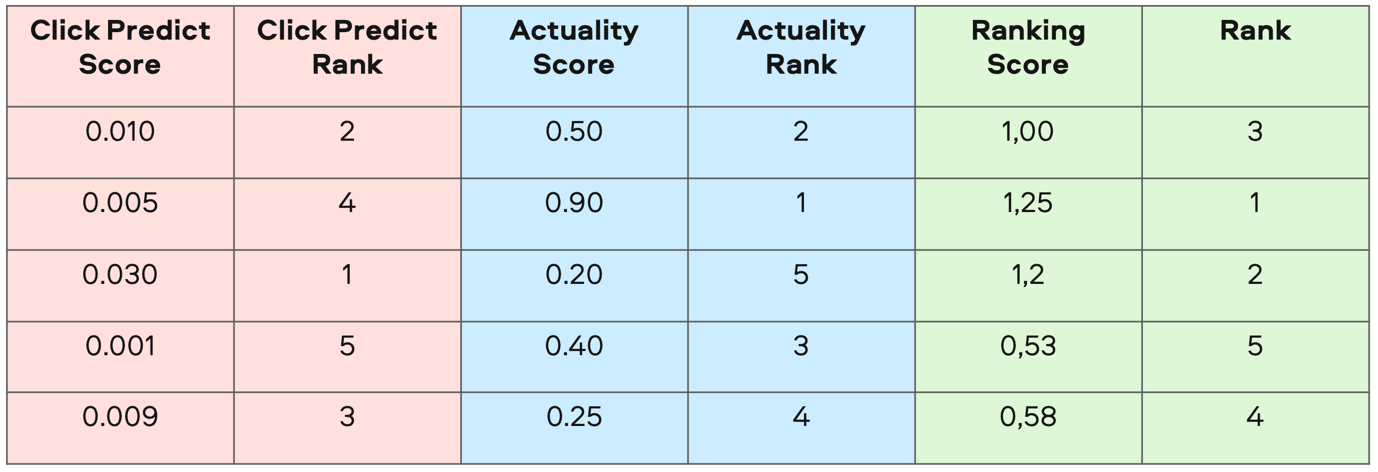
Логика ранжирования объявлений с резюме во втором A/B-тесте
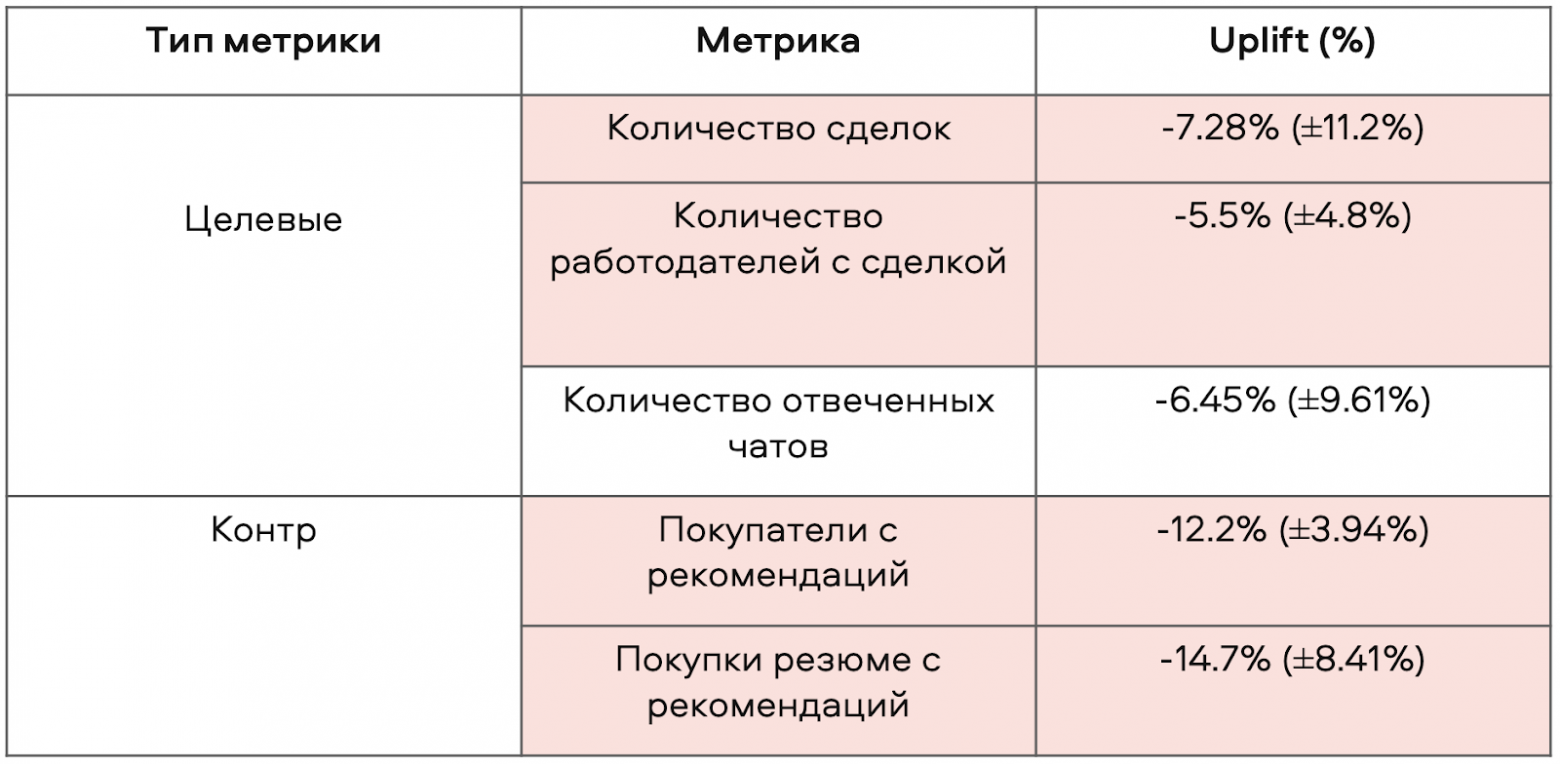
Второй тест оказался успешным. Мы увеличили конверсию в отвеченный чат, при этом контрметрики упали незначительно, что для нас было хорошим показателем.
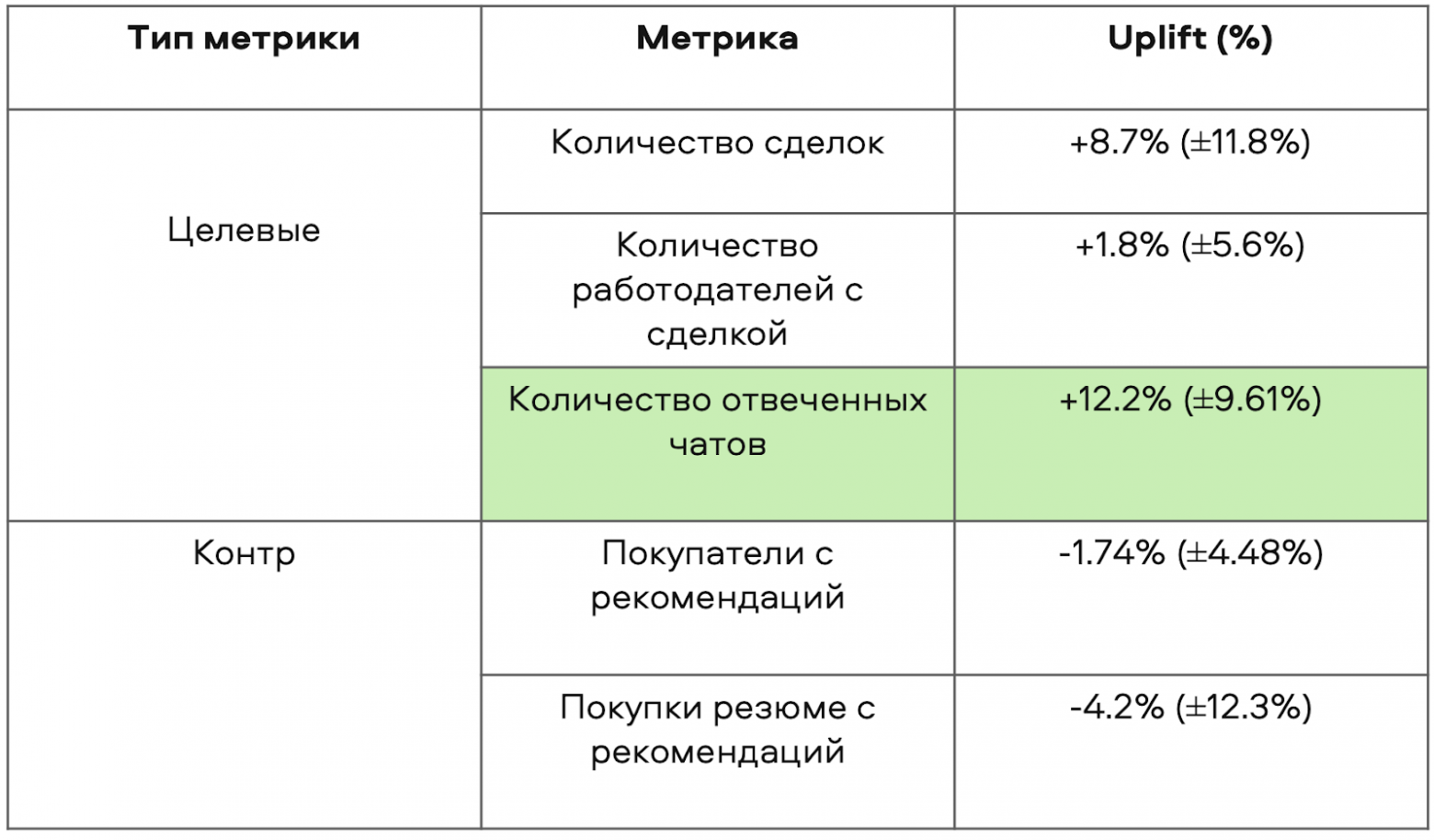
Результаты второго A/B-теста модели в блоке с рекомендациями
В реальности это значит, что мы стали показывать более релевантные и актуальные резюме соискателей.
Итоговые результаты: как мы повлияли на актуальность поисковой выдачи резюме
Увеличили количество сделок в категории «Резюме» на 12–15%;
Повысили retention работодателей в повторную покупку на 12–13%;
Выросли в выручке категории «Резюме» на 5–6%.
