Как мы лечили раздвоение встреч в конференциях на базе Jitsi
Привет! Меня зовут Дима. Я из команды бэкенда Яндекс Телемоста — сервиса для проведения видеовстреч, который входит в Яндекс 360. Перед нами стоит задача не просто предоставить сервис, а предоставить отказоустойчивый и надёжный сервис, который работает 24/7 и обслуживает весь мир.
Телемост создан на основе open source решения Jitsi meet — оно постоянно развивается благодаря вкладу комьюнити, но при этом имеет свои ограничения. В статье расскажу, как мы встретили один редкий, но интересный плавающий баг. И конечно, как его лечили.

Всё началось с того, что участники не встретились в конференции
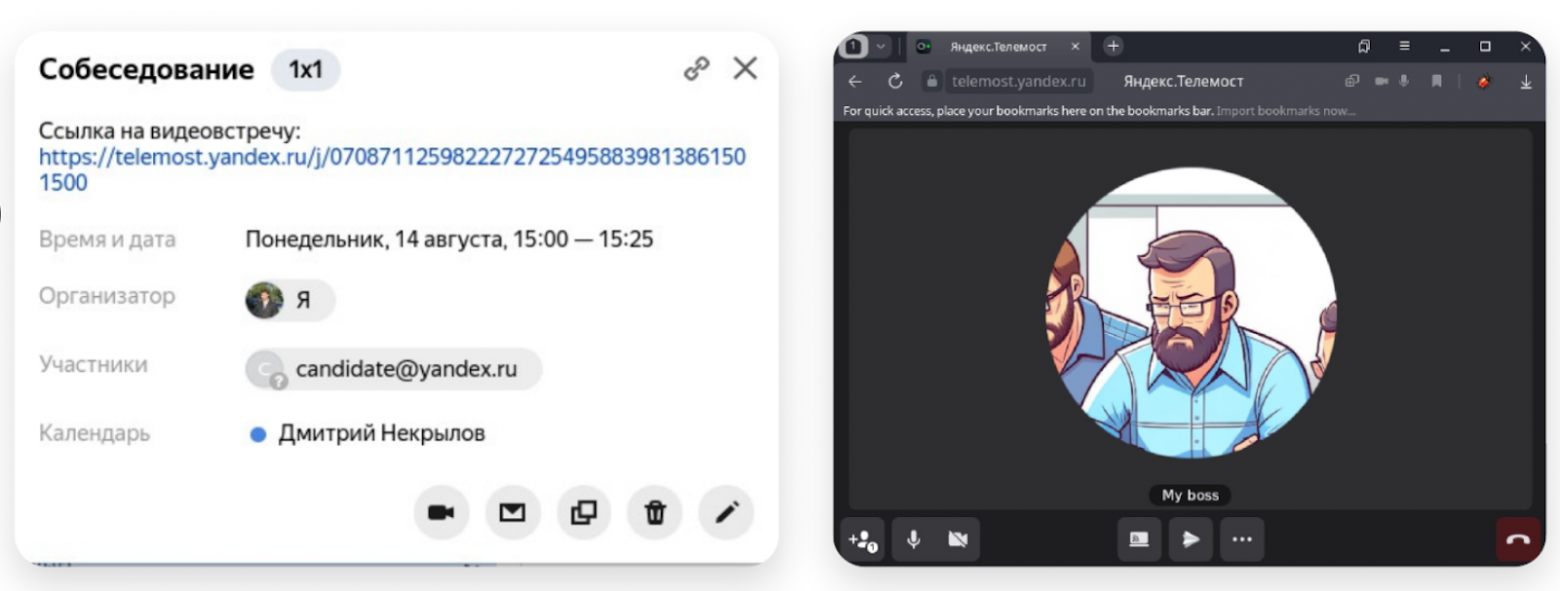
При создании видеовстречи в Яндекс Календаре ссылка генерируется автоматически. Обычно ей делятся заранее и поменять её потом сложно.
Представим себе собеседование. В календаре у кандидата и нанимающего менеджера ссылка в Телемост: в назначенное время они оба должны её нажать и созвониться. Но почему-то подключения не произошло: каждый увидел себя и не увидел собеседника.
То, что наблюдали эти два участника, — серьёзное нарушение базовой функциональности. Мы следим, чтобы фон таких ошибок был исчезающе мал и чтобы причины их возникновения были нам понятны. Но на этот раз мы увидели что-то новое. Об этом и пойдёт речь ниже.
Как устроен процесс подключения к встрече
В процессе участвуют: Media Server —SFU-юнит, который перенаправляет видео говорящего тем, кто его смотрит, Media Server Manager —набор компонентов бэкенда, отвечающих за выбор медиасервера для проведения конференции и Peer — клиент Телемоста, которому нужно подключиться.
При подключении к встрече между клиентом и бэкендом Телемоста происходит следующее взаимодействие:
Peer запрашивает у Media Server Manager параметры подключения.
Media Server Manager находит либо выделяет Media Server.
Media Server находит либо создаёт виртуальный объект Room Session — он отражает комнату, в которой будут совещаться участники.
Media Server создаёт Offer — приглашение для Peer во встречу. В Offer содержатся данные о IP медиасервера, участниках встречи и ID их аудио и видео (медиа) треков.
Peer отвечает на Offer специальным сообщением типа Answer.
Между Client и Media Server устанавливается WebRTC-соединение. Подробнее о WebRTC читайте по ссылке.
Подключение Peer к Room Session установлено.
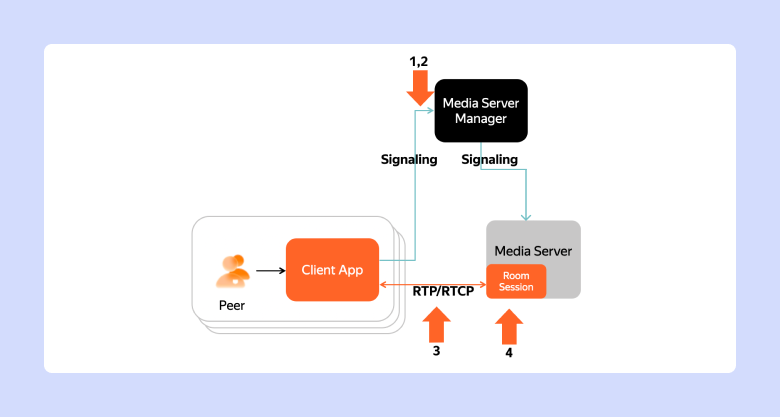
Подключение Peer к Room Session
Следует заметить, что в архитектуре Jitsi и Media Server Manager, и Media Server держат своё состояние In-Memory. Если кто-то из них упадёт, то встречу придётся пересобирать. То есть каждый клиент будет проходить процесс подключения заново.
Как можно не встретиться по ссылке
В высоконагруженных бэкендах приходится много думать о Design for Failure. По условию задачи и на больших объёмах всё, что может пойти не так, обязательно пойдёт не так. И даст фон ошибок. Развернутые в облаке компоненты Jitsi — не исключение. Поэтому в стеке Media Server Manager есть компонент, который каждые 10 секунд проверяет здоровье Media Server. Это делается специальным вызовом типа healthcheck. Если healthcheck несколько раз не прошёл, Media Server признаётся сломавшимся и подлежит немедленной замене.
Мы предположили, что дело в поломке Media Server. Собрались с командой обсудить проблему — конечно, в Телемосте (команда Яндекс Телемоста очень не любит, когда кто-то ставит им встречи в других решениях ВКС — Примеч. ред.).

Media Server Manager проверяет, жив ли Media Server
Копать проблему с нами пошёл руководитель нашей команды. И ему повезло словить именно этот баг. Конференция раздвоилась, и наш руководитель оказался один во встрече. Остальная часть команды собралась без него. Посмотрели по логам — оказалось, что он действительно был на старом медиасервере, а мы на новом.

Наш руководитель и другой Peer совещаются на разных медиасерверах по одной и той же ссылке
И соответственно, были созданы две Room Session: на новом и на старом сервере.
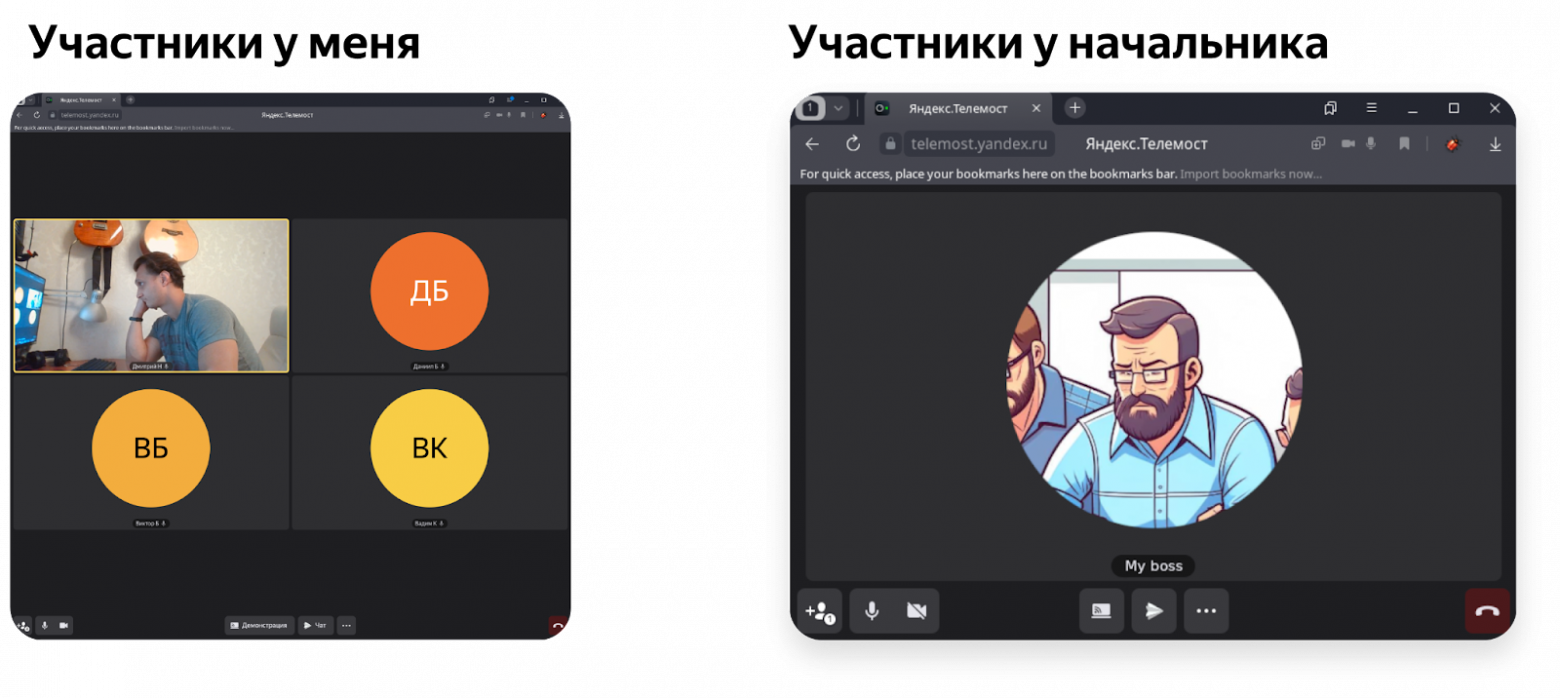
Вид из моего клиента Телемоста и из клиента Телемоста нашего руководителя
Дальше интереснее: постепенно участники моей части конференции стали переподключаться в Room Session руководителя.
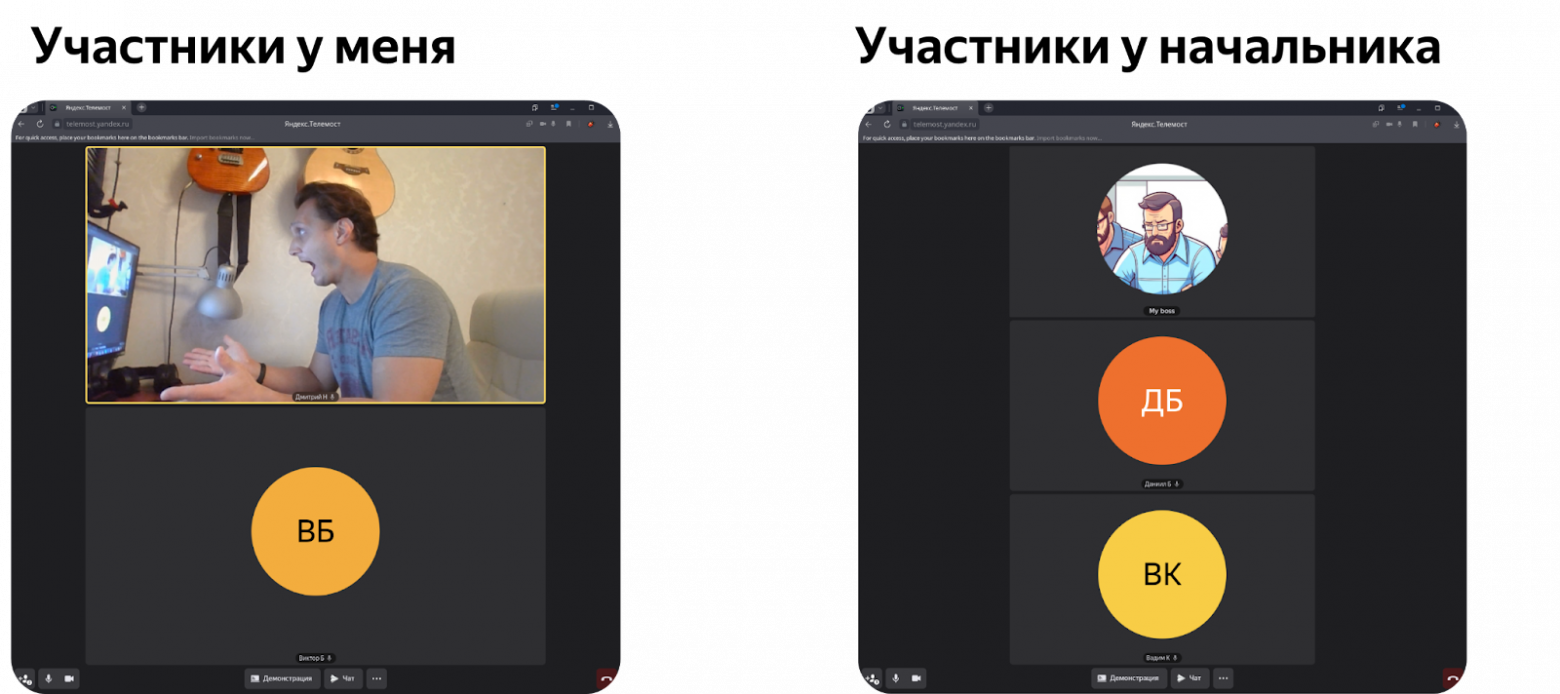
Участники перетекают в другую часть конференции
Давайте разберёмся, как такое может происходить. Мы знаем, что где-то раз в 10 секунд Peer тоже шлют в Media Server специальные сигналы типа keepalive. Таким образом они подтверждают, что у них всё ещё не разрядилась батарейка, они не в лифте и не в туннеле без связи. Если в течение минуты от Peer не приходит такой keepalive, Media Server признаёт его отключившимся. Всем остальным участникам необходимо сообщить о том, что Peer отключился, чтобы они убрали его из сетки и перестали ждать от него медиапотоки. Это делается рассылкой такого же сообщения, как и при подключении, — типа Offer.
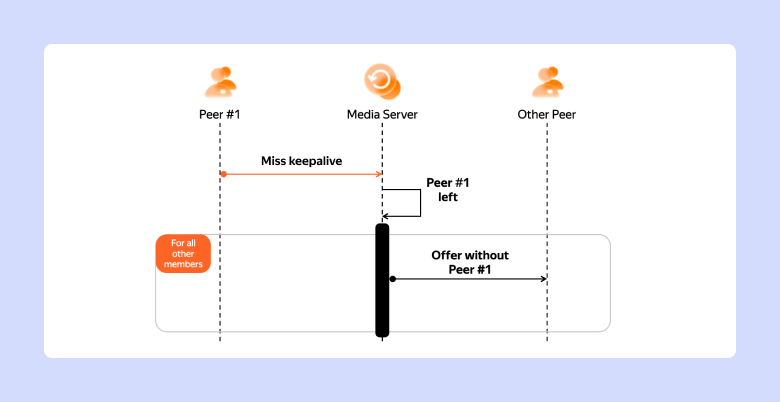
В нашем случае о старом Media Server стек Media Server Manager забыл. Keepalive от Peer«ов шли уже в новый медиасервер, а старый всё ещё считал, что на нём идёт встреча, и ожидал keepalive от участников. Не получив keepalive от первого участника (им посчастливилось оказаться мне), он разослал Offer всем остальным участникам встречи. Клиентское приложение других Peer, получив офер от бэкенда, применило параметры подключения и подключилось к старому медиасерверу.
На этом моменте мы разобрались, что происходит. Но перед тем как приступать к решению, стоит посмотреть статистику по логам и понять, насколько проблема серьёзна. Оказалось, что в некоторые дни от раздвоения пострадали до 0,2% всех конференций.

Процент конференций, так или иначе испытывающих раздвоения в разные дни
Проблема понятна. Переходим к решению
Требование к решению
Можем ли мы полностью исключить такой феномен? Похоже, что нет. По условию задачи Media Server может выключиться, не ответить или неожиданно проснуться. В случае его отказа сессии должны быть пересозданы на новых Media Server в максимально короткий срок. В случае замены внутри кластера Jitsi для этого удобно использовать встроенные в Jitsi механизмы, такие как Octo. Но, например, для реализации отказоустойчивости Jitsi Conference Focus — встроенного в Jitsi балансировщика нагрузки между медиасерверами — придётся пересобирать конференцию внешними средствами.
Если мы не можем полностью исключить феномен одновременного проведения встречи на двух медиасерверах, давайте сформулируем нефункциональные требования к тому, сколько это может продолжаться. Исходя из соображений удобства пользования мы решили, что конференция не должна раздваиваться больше чем на 5 секунд в 99-м перцентиле.
Идея решения
К сожалению, участить healthcheck в 10 раз мы не могли. И кратно увеличить требования к железу или сети тоже. Нам нужно было решение, которое не будет в корне менять архитектуру системы и не потребует перевыпуска всех мобильных и десктопных клиентов. К тому же механизм замены Media Server и пересоздания Room Session у нас уже есть.
Вот что нам нужно было:
Понимать, какая Room Session сейчас актуальна в конференции, и разрешить Offer только в неё.
Если открыта новая Room Session — позвать в неё всех участников.
То есть наше решение должно следить, чтобы все Peer собрались в одной и той же Room Session. Это можно сделать на базе трёх отчётов Media Server: о присоединении Peer, успешном установлении соединения Peer — Room Session и отсоединении Peer.
Начинаем отслеживать, в каких Room Session находятся участники. На этом этапе мы вводим дополнительное понятие Room Media Session (RMS). Она будет отвечать за подключение Peer к определённой Room Session:

Правильные Room Media Session — только в последней Room Session
Room Session — многопользовательская сессия на медиасервере. Координаты: room_session_id — назначается медиасервером.
Room Media Session — сессия пользователя внутри Room Session. Координаты: room_session_id — назначается медиасервером, peer_id — назначается бэкендом.
Чтобы убедиться, что все Peer общаются в одной и той же Room Session, наш сервис должен:
Знать, какой Media Server актуален для каждой конференции.
Знать, какая Room Session актуальна.
Звать всех Peer в актуальную Room Session.
Знать, какие Room Session больше не актуальны — оферы из них нельзя пропускать к клиенту.
Задачи механизма защиты от раздвоения
Добавляем новый компонент — Room Session Groomer. Он будет располагаться между Media Server Manager и Media Server. Через него будут проходить Offer клиентам, и он будет принимать отчёты медиасервера.
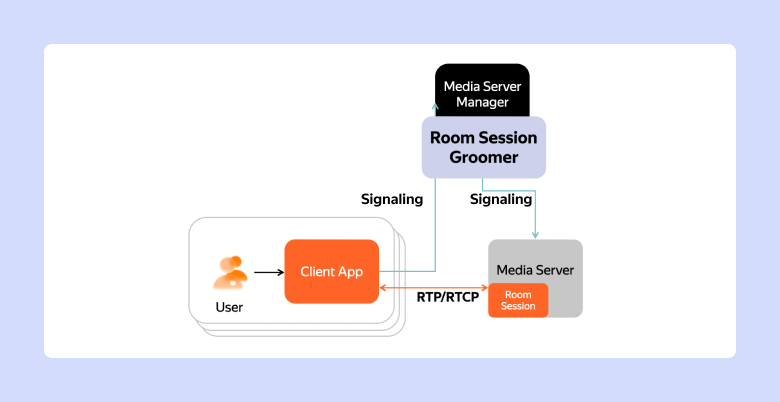
Добавляем Room Session Groomer
Фильтрация нелегитимных Offer
Первая задача, которую он должен выполнить, — отфильтровать нелегитимные Offer, то есть Offer в старые Room Session. Будем считать, что если была создана новая Room Session — она должна стать активной. Из остальных Room Session Offer проходить не должны. Чтобы отличать старые Room Session от новых, нам потребуется хранить всю историю ID Room Session, которые до этого встречались.
Приглашение Peer в новую Room Session
Когда создаётся новая Room Session, в старых, скорее всего, продолжают совещаться какие-то Peer«ы. Вторая задача Room Session Groomer — позвать их в новую Room Session. Послать сам сигнал по вебсокету нам не сложно, но важно при этом не засыпать клиентов одинаковыми сигналами.
Диаграмма состояний Room Media Session
Начнём с моделирования явлений, которые мы наблюдаем. От Media Server мы ждём трёх последовательных сообщений о состоянии Room Media Session.
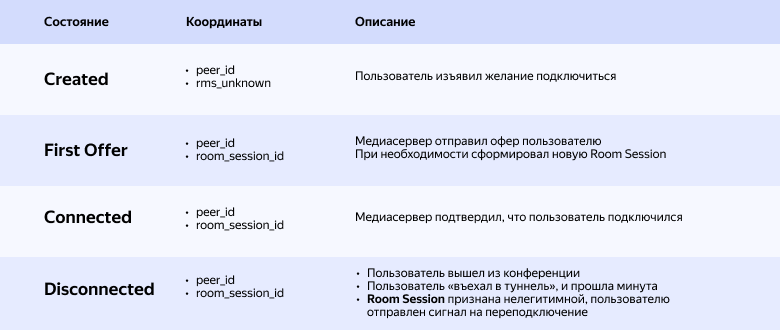
FIRST_OFFER: сообщение о том, что к Media Server пришёл Peer и Media Server начал согласование Room Media Session с этим Peer.
CONNECTED: сообщение об успешном установлении Room Media Session.
DISCONNECTED: сообщение о том, что Room Media Session с этим Peer была по каким-то причинам разорвана. Media Server забыл это соединение.
Эти три отчёта должны идти строго друг за другом. Вслед за ними можно ввести три одноимённых состояния: FIRST_OFFER, CONNECTED, DISCONNECTED. Но есть ещё четвёртое: когда стек Media Server Manager уже знает, что Peer изъявил желание подключиться. Запрос в Media Server на подключение уже в пути, но Media Server ещё не отреагировал. Назовём это состояние CREATED.
Важно отметить, что переходы между этими состояниями возможны только вперёд. Даже получив out-of-order отчёт FIRST_OFFER в состоянии CONNECTED, мы не должны откатывать назад состояние Room Media Session.
Переход из CREATED в любое другое состояние происходит по отчёту Media Server. В этом отчёте всегда содержится ID Room Session, который назначается на стороне Media Server. Этот ID как раз и можно проверить на «свежесть» и запретить отправку Offer для старой Room Session.
Первичный ключ Room Media Session
Если мы работаем с объектом Room Media Session, то его «естественным» первичным ключом будет комбинация peer_id + room_session_id. При получении первого отчёта от Media Server первичный ключ будет меняться. Опыт подсказывает, что с меняющимися Primary Key при обработке параллельных запросов нужно быть аккуратными — чуть ниже мы ещё раз увидим почему.
Флоу подключения и переподключения участника
Путь Room Media Session по получившейся диаграмме состояний тривиален:

Диаграмма состояний Room Media Session
Peer изъявляет желание подключиться (кликает по ссылке во встречу в календаре) → CREATED.
Media Server выделен, и Peer начинает подключение к Media Server → FIRST_OFFER.
WebRTC-соединение установлено → CONNECTED.
Peer вышел из конференции → DISCONNECTED.
Рассмотрим, как будет происходить процесс переподключения Peer при обнаружении новой Room Session.
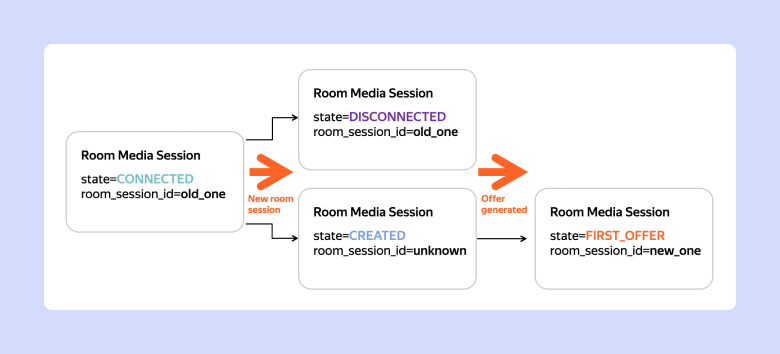
Состояния Room Media Session при подключении новой Room Media Session вместо старой
Получаем от Media Server отчёт, в котором присутствует до сих пор неизвестный room_session_id.
Переводим CONNECTED-сессию в состояние DISCONNECTED. В той же транзакции создаём CREATED-запись. Таким образом указываем, что Peer должен идти на переподключение.
Когда Peer дойдёт до Media Server и будет отправлен отчёт FIRST_OFFER, мы переведём CREATED-запись в состояние FIRST_OFFER и заполним ставший известным room_session_id.
Возможно, внимательный читатель заметит: почему бы на втором шаге сразу не запомнить требуемый room_session_id? Пустой room_session_id нам нужен, чтобы консистентно регистрировать изъявление желания подключиться. На этом этапе мы не знаем, будет ли ещё одна смена Media Server между CREATED и FIRST_OFFER в этом моменте.
ACID-запросы для применения отчётов
Получив отчёт от медиасервера, мы, конечно же, хотим применить его к состоянию в БД. Так как отчёты могут теряться и, возможно, даже перемешиваться из-за сбоев в retry policy, отчёт может быть встречен в одной из трёх ситуаций:
Room Media Session с координатами (peer_id, rs_id) в БД уже есть.
В БД отсутствует Room Media Session с точным совпадением координат (peer_id, rs_id) и присутствует CREATED Room Media Session с координатами (peer_id, RMS_UNKNOWN).
В БД отсутствуют оба варианта Room Media Session.
Для применения отчёта Media Server в один запрос в каждой из перечисленных ситуаций делаем вызовы:
Update записи по (peer_id, rs_id).
Если записи не нашлось, то Update Created-записи (peer_id, RMS_UNKNOWN) rs_id).
Если запрос снова не успешен или on conflict, то Insert записи (peer_id, rs_id).
Очевидно, в однопоточном окружении выполненные в этом порядке запросы всегда приведут состояние Room Media Session в состояние, соответствующее отчёту Media Server.
Реализуем MVP
Начнём сначала. Делаем табличку:
create table room_media_sessions
(
room_id uuid not null,
peer_id uuid not null,
room_session_id uuid not null,
created_at timestamptz(3) not null,
first_offer_at timestamptz(3),
connected_at timestamptz(3),
disconnected_at timestamptz(3),
state room_media_session_state not null,
);Указываем констрейны на состояния:
CONSTRAINT check_room_media_sessions_state_requirements CHECK (
(state = 'CREATED' and room_session_id = 'rms_unknown') or
(state = 'FIRST_OFFER_RECEIVED' and room_session_id <> 'rms_unknown') or
(state = 'CONNECTED' and room_session_id <> 'rms_unknown') or
(state = 'DISCONNECTED' and room_session_id <> 'rms_unknown') or
state = 'ARCHIVED'
)Мы заранее побеспокоились о retention policy и ввели состояние archived для исключения устаревших записей из индексов.
Регистрация статуса Room Media Session по отчёту
Управляющая команда на Java, которую мы генерируем по отчёту медиасервера, выглядит так:
@Data
@Builder
public static class UpsertRMSRequest {
@Nonnull
String roomId;
@Nonnull
String roomSessionId;
@Nonnull
String peerId;
//CREATED, FIRST_OFFER_RECEIVED, CONNECTED, DISCONNECTED, ARCHIVED
List updatedStates;
RoomMediaSessionState newState;
} Кроме параметров, которые нужно добавить в базу, в команде также есть показатель updated States. Он помогает определить, когда с записью можно взаимодействовать — менять статус или удалять:
Если приходит отчёт CONNECTED, а запись в статусе DISCONNECTED — трогать нельзя.
Если приходит отчёт CONNECTED, а запись в статусе FIRST_OFFER — трогать можно. Нужно поменять статус записи на CONNECTED.
SQL-запрос, который обрабатывает такую команду, будет выглядеть так:
@Language("SQL")
public static final String UPDATE_BASE_SQL = """
update room_media_sessions
set state = case when state in (:updated_states)
then :state else state end,
room_session_id = :room_session_id
where peer_id = :peer_id
""";
@Language("SQL")
public static final String UPDATE_BY_ROOM_SESSION_ID = UPDATE_BASE_SQL + """
/*-RoomMediaSessionPgDaoImpl-UPDATE_BY_ROOM_SESSION_ID-*/
and room_session_id = :room_session_id
""";
@Language("SQL")
public static final String UPDATE_CREATED_ROOM_SESSION = UPDATE_BASE_SQL + String.format("""
/*-RoomMediaSessionPgDaoImpl-UPDATE_СREATED_ROOM_SESSION-*/
and state = 'CREATED'
and room_session_id = '%s'
""", UNKNOWN_ROOM_SESSION_ID);Это общая база + два варианта исполнения: для апдейта CREATED-записей и записей с полным совпадением room_session_id + peer_id.
Best Practice: помечаем SQL-запросы уникальными человекочитаемыми ключами
Зачем здесь лирическое отступление про то, как мы клеим SQL-запросы плюсиками? А вот зачем: в следующий раз, когда они начнут тормозить, мы возможно будем искать их в таком окошке. Знакомьтесь, Postgres Work Analyzer.

PoWA
Он не единственный в своём роде. Почти все базы данных умеют так или иначе давать статистику по запросам. И почти все из них показывают текст запроса. Вставки с уникальными человекочитаемыми айдишниками в комментариях к запросам помогут нам быстро найти место в коде, откуда запрос вызывался.
Но вернёмся к нашей теме.
Приглашение Peer из старых Room Session в новую
При обнаружении новой Room Session мы должны закрыть все старые Room Media Session и создать для них Created-записи.

Ищем Room Media Session по peer_id и room_session_id
Для поиска Room Media Session в старых Room Session при обнаружении новой делаем запрос:
@Override
public Collection findOtherActiveRoomSessions(@Nonnull String roomId, @Nonnull String roomSessionId) {
return jdbcTemplate.queryForList("""
select distinct room_session_id
from room_media_sessions
where room_id = ?
and state in ('FIRST_OFFER_RECEIVED', 'CONNECTED')
and disconnected_at is null
and room_session_id <> ?
""",
String.class,
roomId,
roomSessionId
);
} В индекс для этого запроса, конечно же, внесём только активные Room Media Session.
CREATE INDEX if not exists idx_room_media_sessions_active_sessions
ON room_media_sessions (room_id, room_session_id)
where disconnected_at is null
and state in ('CREATED', 'FIRST_OFFER_RECEIVED', 'CONNECTED')
Реализация с глобальным локом
При поиске нам нужно обновить информацию о Peer в базе: выставить новое состояние state по peer_id и room_session_id. Самый простой способ это сделать — взять лок на всю конференцию.
Попробуем так:
transactionTemplate.executeWithoutResult((action) -> {
roomMediaSessionDao.lockRoomId(upsertRMSRequest.getRoomId());
int updated;
updated = roomMediaSessionDao.updateByRoomSessionId(upsertRMSRequest);
if (updated == 0) {
updated = roomMediaSessionDao.updateCreatedRoomSession(upsertRMSRequest);
if (updated == 0) {
updated = roomMediaSessionDao.insertOrDoNothing(upsertRMSRequest);
}
}
if (updated == 0) {
throw new RuntimeException(String.format(
"Failed to update info on room media sessions. 0 rows updated. request: %s",
upsertRMSRequest
));
}
});Результаты замеров показали, что такой подход даёт нам производительность 125 СPS (connections per second) на нашем тестовом стенде с 4 CPU постгреса.

На этом можно было бы закончить: решение найдено, пользователи не страдают. Мы использовали Partial Index и почистили индексы исторических данных, подготовились к анализу запросов с помощью разметки для поиска в POWA. Но мы пошли чуть дальше и стали работать над производительностью решения.
Работаем над производительностью
Чтобы пристреляться, насколько дорого нам обходятся локи на всю конференцию, давайте попробуем произвести замер без них:
int updated;
//point.1
updated = roomMediaSessionDao.updateByRoomSessionId(upsertRMSRequest);
if (updated == 0) {
//point.2
updated = roomMediaSessionDao.updateCreatedRoomSession(upsertRMSRequest);
if (updated == 0) {
//point.3
updated = roomMediaSessionDao.insertOrDoNothing(upsertRMSRequest);
}
}
if (updated == 0) {
throw new RuntimeException(String.format(
"Failed to update info on room media sessions. 0 rows updated. request: %s",
upsertRMSRequest
));
}Видим, что CPS получается в 1,5 раза больше.

Но просто так выкидывать критическую секцию нельзя. Иначе гонка двух параллельных обработок отчётов даст нам неверное состояние. Например, если поток 1 находится в точке 3 с отчётом CONNECTED и параллельно прилетает out of order отчёт FIRST_OFFER, то обработка первого отчёта закончится с ошибкой duplicate key. В результате в базе будет лежать состояние FIRST_OFFER.
Давайте попробуем просчитать, какие запросы и в какой последовательности требуется делать в базу, чтобы выполнить простые условия:
Движение по диаграмме состояний только вперёд.
Отчёт медиасервера должен быть применён всегда.
При обработке отчёта от Media Server по отношению к координатам (peer_id, rs_id) возможны 4 ситуации (состояния):

Соберём модель конечного автомата, в котором будут наши четыре состояния, а при переходах будут выполняться атомарные запросы в базу:
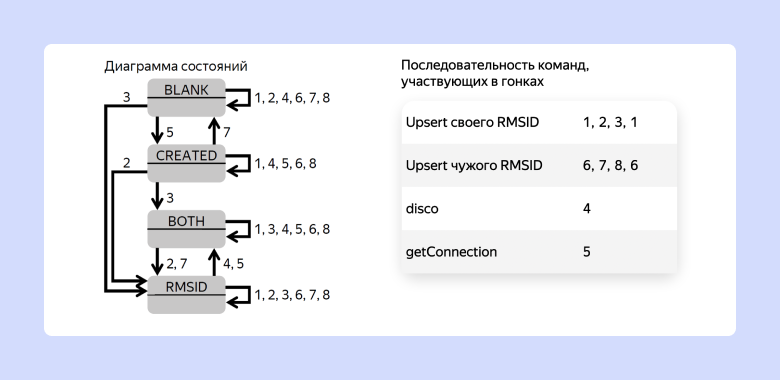
Схема переходов в конечном автомате

Описание переходов между состояниями
Несложно убедиться, что последовательность запросов 1,2,3,1 будет удовлетворять нашим ограничениям, потому что:
В команде от медиасервера всегда есть Room Session ID.
За один шаг всегда можно досоздать запись или перевести её из CREATED.
Эволюция положения в обратном порядке невозможна. Update компенсируется последним шагом.
Разбираемся, откуда берётся выигрыш в производительности
Интересно заметить, что, если собрать в docker-compose аналогичный по параметрам стенд и выделить под PG те же самые 4 ядра, количество CPS с локами и без локов отличаться не будет.
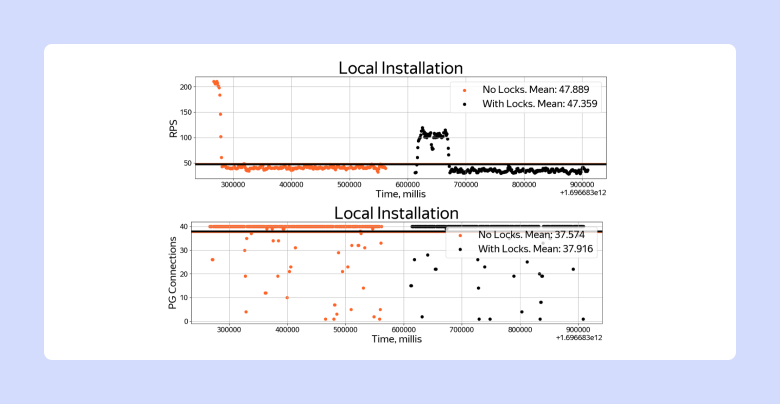
Connections per Second с локами и без локов на стенде
Почему так происходит? Решение с локами страдает не от самих локов, а от round trip time между БД и приложением.
#Docker-compose.yml
services:
postgres:
container_name: postgres
cap_add:
- NET_ADMINНапример, если ввести в docker-compose задержки пакетов 1 мс, то мы увидим выигрыш решения без локов в 2,5 раза.
#!/bin/bash
echo "setting PG delay to $1"
docker exec postgres tc qdisc del dev eth0 root netem delay 1ms
docker exec postgres tc qdisc add dev eth0 root netem delay "$1"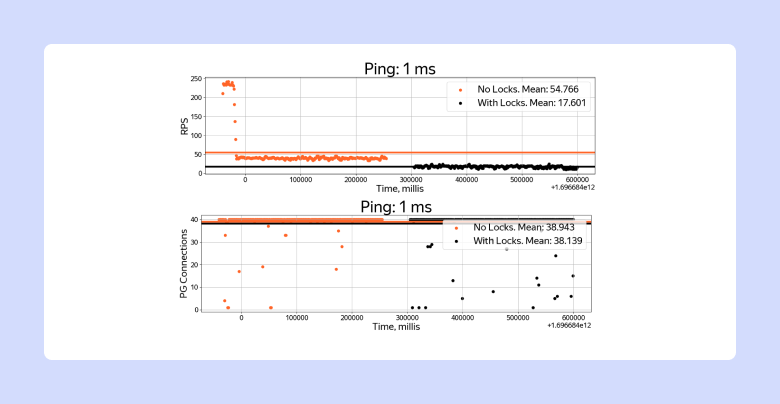
Замеры Connections per Second с пингом 1ms
А при пинге в 30 мс, который можно встретить, если сработал failover PG мастера в другой DC, результаты будут различаться уже в 20 раз.
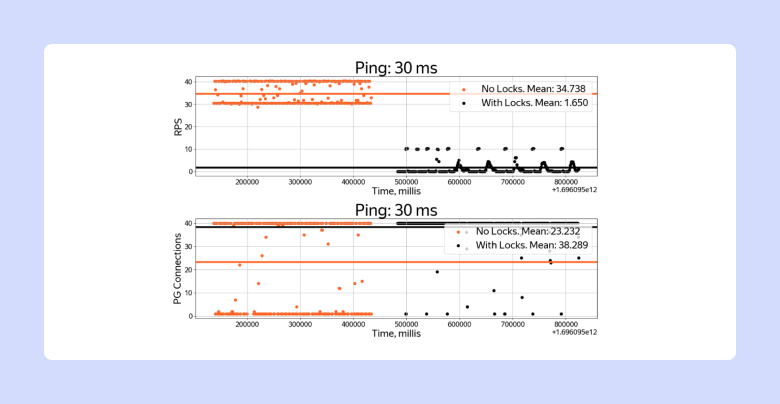
Замеры Connections per Second с пингом 30ms
Что является ресурсом, который мы хотим оптимизировать
Подводя итоги исследования, отметим, что нагрузка «в полку» — не совсем наш кейс. Настраивая систему под real-time нагрузку, мы хотим оставить небольшой запас по всем возможным потребляемым ресурсам. В случае работы с Postgres таким ресурсом часто являются соединения с базой в пуле.
Давайте сравним, как решения с локами и без локов влияют на потребление PG-конекшенов при разных пингах. Для этого подадим приблизительно одинаковый CPS и сравним потребление при пинге 1 мс. Как видим, в нашем случае большее число более коротких транзакций нам сильно на руку: потребление PG-конекшенов уменьшается чуть ли не в 10 раз.

Потребление PG Connections с 1ms задержки: с локами и без локов
Конечно, компромисс в пользу большего количества более коротких транзакций не всегда будет оптимален. Например, если для коммита транзакции требуется тяжёлая синхронная репликация, снижать в таком решении мы захотим именно количество транзакций.
Подводим итоги
Design for failure на больших масштабах — это не опционально. Нет Design for failure — страдают пользователи.
Смена Primary Key в многопоточных окружениях может приводить к race condition.
Проектируя решения взаимодействия с базой данных, мы обладаем степенью свободы: количество транзакций vs выполнение операций в одной крупной транзакции. Часто оказывается, что много маленьких транзакций может быть выгоднее, чем одна большая.
Бэкендеры, если у вас на графиках приложения нет количества потребляемых PG-конекшенов, добавьте.
А если нужен сам стенд, например для копипасты связки docker-compose + java проекта + ipnb шаблончиков с графиками, пользуйтесь: https://github.com/topright007/tmost_state_machine_bench
